Kubernetes集群实战——Kubernetes集群部署、故障模拟及处理、pod管理
0.Borg概述
Borg是谷歌内部的大规模集群管理系统,负责对谷歌内部很多核心服务的调度和管理,Borg的目的是让用户能够不必操心资源管理问题,让他们专注于自己的核心业务,并且做到跨多个数据中心的资源利用率最大化
Borg主要由BorgMaster、Borglet、borcfg和Scheduler组成
BorgMaster是整个集群的大脑,负责维护整个集群的状态,并将数据持久化到Paxos存储中;
Scheduler负责任务的调度,根据应用的特点将其调度到具体的机器上去;
Borglet负责真正运行任务(在容器中);
borcfg是Borg的命令行工具,用于根Borg系统交互,一般通过一个配置文件来提交任务
1.Kubernetes简介
在Docker 作为高级容器引擎快速发展的同时,在Google内部,容器技术已经应
用了很多年,Borg系统运行管理着成千上万的容器应用。
Kubernetes项目来源于Borg,可以说是集结了Borg设计思想的精华,并且吸收了
Borg系统中的经验和教训。
Kubernetes对计算资源进行了更高层次的抽象,通过将容器进行细致的组合,将
最终的应用服务交给用户。
Kubernetes的好处:
• 隐藏资源管理和错误处理,用户仅需要关注应用的开发。
• 服务高可用、高可靠。
• 可将负载运行在由成千上万的机器联合而成的集群中。
2. kubernetes设计架构
Kubernetes集群包含有节点代理kubelet和Master组件(APIs, scheduler, etc),一
切都基于分布式的存储系统。
Kubernetes主要由以下几个核心组件组成:
etcd:保存了整个集群的状态
apiserver:提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现
等机制
controller manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等
scheduler:负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上
kubelet:负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理
Container runtime:负责镜像管理以及Pod和容器的真正运行(CRI)
kube-proxy:负责为Service提供cluster内部的服务发现和负载均衡
除了核心组件,还有一些推荐的Add-ons:
kube-dns:负责为整个集群提供DNS服务
Ingress Controller:为服务提供外网入口
Heapster:提供资源监控
Dashboard:提供GUI
Federation:提供跨可用区的集群
Fluentd-elasticsearch:提供集群日志采集、存储与查询
Kubernetes设计理念和功能其实就是一个类似Linux的分层架构
核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件
式应用执行环境
• 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服
务发现、DNS解析等)
• 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动
态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
• 接口层:kubectl命令行工具、客户端SDK以及集群联邦
• 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范
畴
• Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS
应用、ChatOps等
• Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的
配置和管理等
3.Kubernetes集群部署
实验环境:
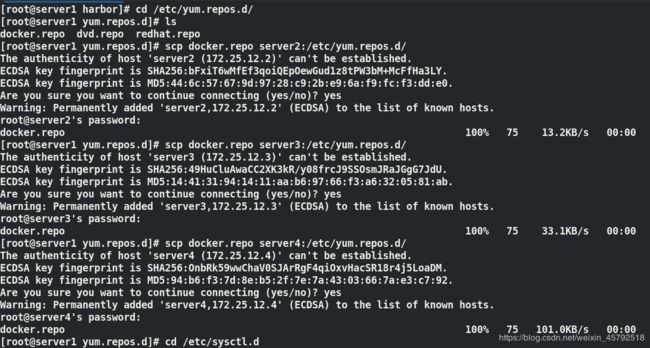
server1(172.25.12.1) 作harbor私有仓库(内存2G)
server2(172.25.12.2) 作k8skube-Master(cpu采用2核、内存4G)
server3(172.25.12.3) 作k8skube-proxy(cpu采用2核、内存1G,官网上说2G,这里是实验环境,相对可以小一点)
server4(172.25.12.4) 作k8skube-proxy(cpu采用2核、内存1G)
实验
(1)关闭所有节点的selinux和iptables防火墙
所有节点部署docker引擎
yum install -y docker-ce docker-ce
vim /etc/sysctl.d/k8s.conf ##设置内核参数,内核支持打开(不设置会影响docker网络)
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
sysctl --system ##使生效
systemctl enable --enable docker

![]()
![]()
![]()

(2)修改docker的runtime以配合k8s的运行
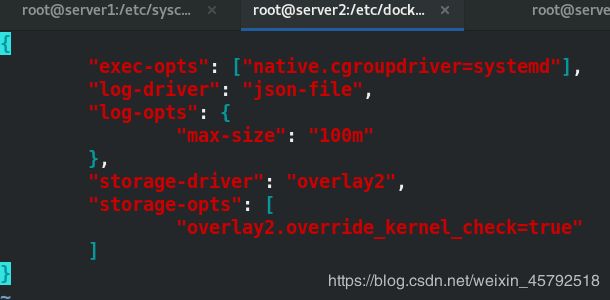
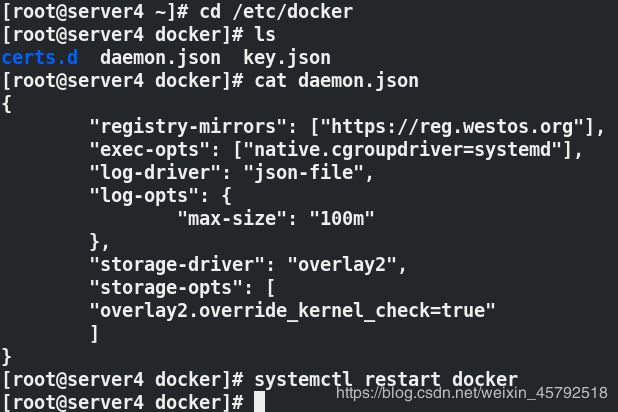
vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"], ##设置cgroup启动方式为systemd
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}
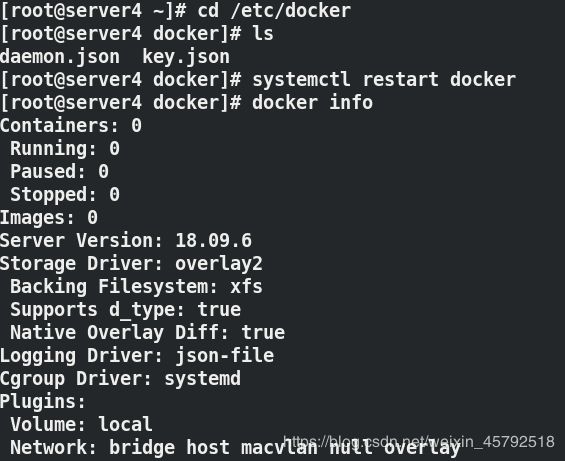
systemctl restart docker ##重启docker
docker info ##cgroup驱动是systemd方式
在主节点(server2 master)改好后,传给集群其它节点server3和server4,做相同操作



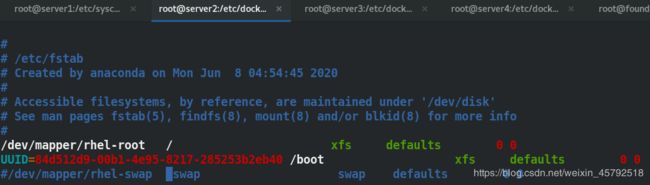
(3)所有节点禁用swap分区,直接使用物理内存
swapoff -a
注释掉/etc/fstab文件中的swap定义

(4)安装部署软件kubeadm
需要在server2、server3和server4搭建k8s.repo仓库
在每台机器上安装kubeadm、kubelet 和 kubectl软件包:
kubeadm:用来初始化集群的指令。
kubelet:在集群中的每个节点上用来启动 pod 和容器等。
kubectl:用来与集群通信的命令行工具。
kubeadm 不能安装或者管理 kubelet 或 kubectl,所以需要确保它们与通过 kubeadm 安装的控制平面的版本相匹配。 如果不这样做,则存在发生版本偏差的风险,可能会导致一些预料之外的错误和问题。 然而,控制平面与 kubelet 间的相差一个次要版本不一致是支持的,但 kubelet 的版本不可以超过 API 服务器的版本。 例如,1.7.0 版本的 kubelet 可以完全兼容 1.8.0 版本的 API 服务器,反之则不可以。
vim /etc/yum.repos.d/k8s.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
yum install -y kubelet kubeadm kubectl ##安装kubeadm工具
systemctl enable --now kubelet ##设置为开机自启


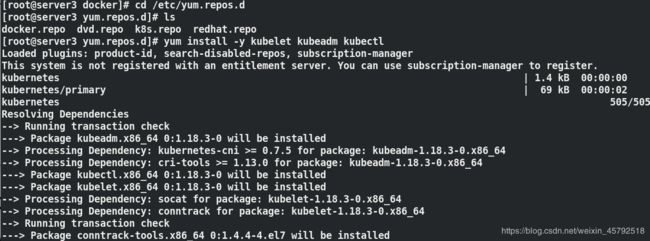



(5)在server2上从aliyun官网拉取kubernetes镜像,之后再上传到我们私有仓库,其它节点直接指向我们私有仓库去下载
kubeadm config images list ##列出所需镜像
kubeadm config images pull --image-repository registry.aliyuncs.com/google_containers ##拉取镜像

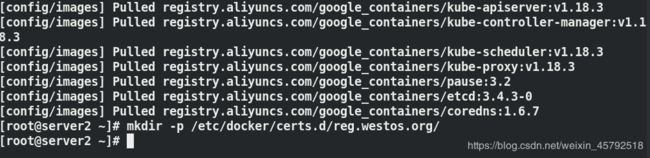
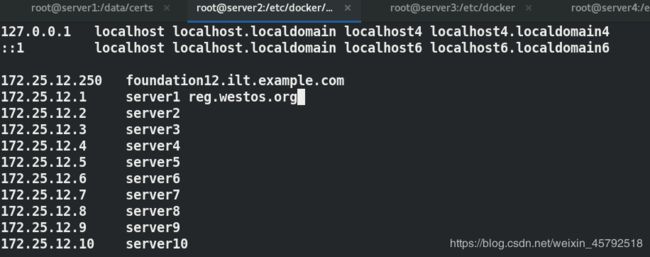
(6)在server1上把私有仓库认证证书复制给server2,在server2上添加私有仓库的解析


![]()
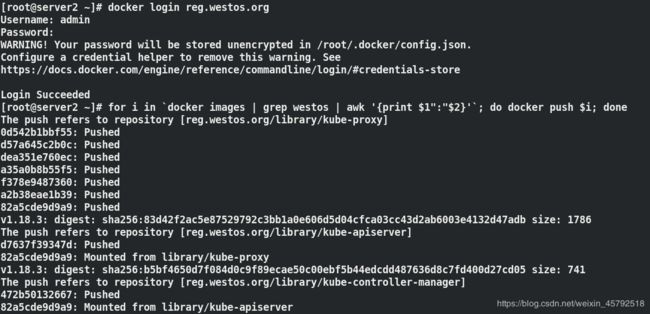
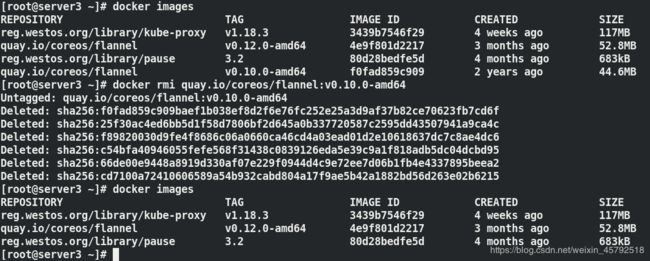
(7)给镜像打标签,把从aliyun上下载的镜像位置改为私有仓库的位置,然后再登陆仓库进行上传
for i in `docker images | grep aliyuncs | awk '{print $1":"$2}' | awk -F / '{print $3}'`; do docker tag registry.aliyuncs.com/google_containers/$i reg.westos.org/library/$i; done ##改标签
for i in `docker images | grep westos | awk '{print $1":"$2}'`; do docker push $i; done ##上传
for i in `docker images | grep aliyuncs | awk '{print $1":"$2}'`; do docker rmi $i; done ##删除aliyun上下载的镜像

![]()

(8)将证书拷贝到server3和server4上,其它节点可以自己拉取
server2在部署之前把镜像拉取到本地,主要的进程都在master上运行,其他节点不用拉取,其他节点会有其他节点的镜像



(9)在server2上初始化
部署时使用的是我们下载的镜像,其他节点等这个节点运行起来后可以直接进行添加
kubeadm init --pod-network-cidr=10.244.0.0/16 --image-repository reg.westos.org/library --kubernetes-version v1.18.3 ##初始化集群

在交互集群时需要证书,所有的证书都在$HOME/.kube/config文件里面,它是用来连接apiserver的

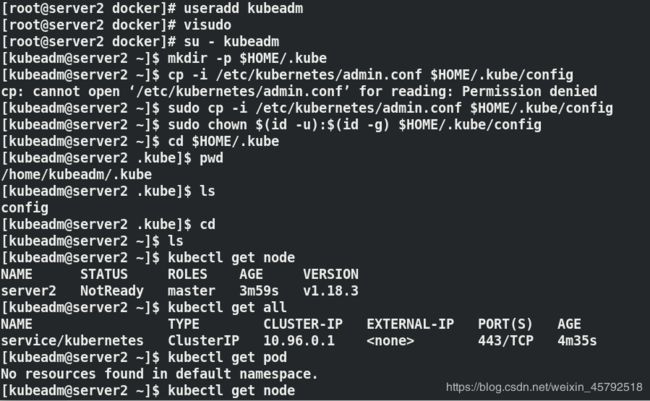
(10) 配置kubectl
useradd kubeadm ##创建用户kubeadm
vim /etc/sudoers
kubeadm ALL=(ALL) NOPASSWD: ALL ##权限下放到kubeadm
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Master查看状态命令:
kubectl get node ##查看节点
kubectl get pod -n kube-system ##查看kube集群的pod
kubectl命令指南:
https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands

节点扩容:在server3和4上执行
token是用来验证客户端的,只要持有未过期的token就允许他连接6443
discover-token是客户端用来验证master端的
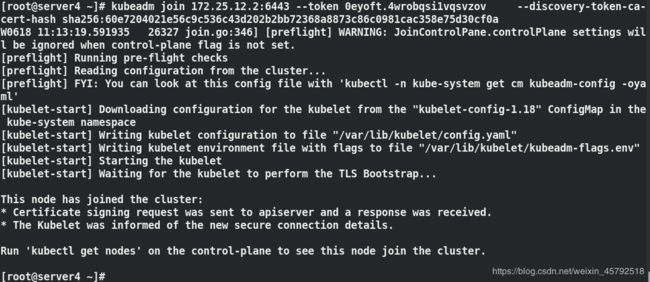
kubeadm join --token b3a32e.7cef20447b55261e 172.25.12.2:6443 --discovery-token-ca-cert-hash
sha256:bc718df41fdceb0db6c5380c7e27c204589b41dcb5f9a3bc52c254b707377f2f

(11) 安装flannel网络组件,使网络连通(不安装会影响节点状态)
kubectl apply -f kube-flannel.yml
配置kubectl命令补齐功能:
echo "source <(kubectl completion bash)" >> ~/.bashrc



(12)在server3和4上加载flannel网络插件



4.集群故障模拟及处理
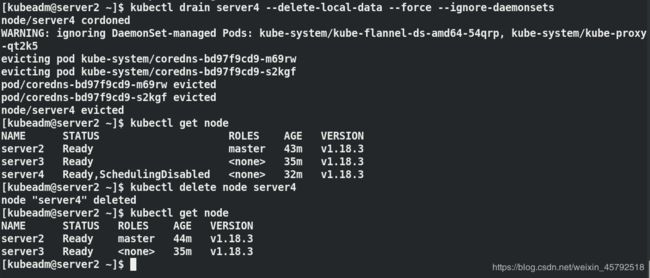
问题模拟:在master上清除节点server4,对这个节点上的容器下线
在server2上:
kubectl drain server4 --delete-local-data --force --ignore-daemonsets ##使server4节点下线
kubectl get node ##节点4已经被disable掉,之后在调用任何pod时都不会到server4节点上
kubectl delete node server4
通过这种方式可以把已经在集群中的节点删除掉,这种方式比较适合删除一个现存的工作节点(server4已经正常加到集群中去了);如果是非正常加入集群,就是加到一半报错了,此时它上面没有启动任何容器,只需要在添加的这个节点做kubeadm reset 动作(清楚刚才join的信息),再次join即可
注意token过期问题
kubeadm token create ##创建token
kubeadm token list ##列出token信息

 reset后,用重新创建的token去join,这里如果不记得hash值,可在官网查找有一条命令,将这条命令在master节点输入就会得到你的–discover-token-ca-crt-hash值
reset后,用重新创建的token去join,这里如果不记得hash值,可在官网查找有一条命令,将这条命令在master节点输入就会得到你的–discover-token-ca-crt-hash值
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
成功加入集群
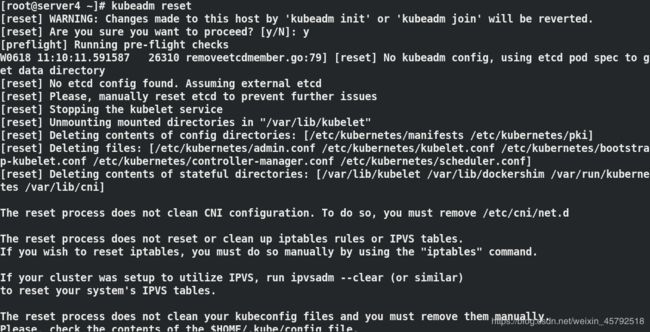

模拟问题:在server4节点删除镜像flannel
docker rm -f 300060cabc42 ##先删除正在运行此镜像的容器
docker rmi quay.io/cores/flannel:v0.12.0-adm64 ##再把镜像删除

在server2上:
运行一个demo,镜像是nginx
kubectl run demo --image=nginx
kubectl get pod ##正在建立状态
kubectl logs demo ##查看日志,容器正在启动中
kubectl describe pod demo ##查看pod信息,创建时网络失败


在server3上安装bridge-utils,cni0是pod的桥接地址,vethb134e977这个网卡就是我们的pod

查看pod,被分配到了server4节点上,容器实际上是通过cnio接口来通信的,server4节点上根本就没有镜像,所以说它不能启动容器,这里pod被分配到server4节点上,是因为刚才没有清理干净,重启server4节点

设置所有节点从我的私有仓库上去下载
server2(master)默认情况下不参加工作调度,
在server3和4上编辑docker,编辑daemon.json,设置从私有仓库reg.westos.org上下载
重启docker

删除pod

查看server4上的镜像

问题解决后,server4可以正常拉取镜像


5.pod管理
Pod是可以创建和管理Kubernetes计算的最小可部署单元,一个Pod代表着集群
中运行的一个进程,每个pod都有一个唯一的ip。
一个pod类似一个豌豆荚,包含一个或多个容器(通常是docker),多个容器间
共享IPC、Network和UTC namespace。
5.1 pod创建:自主式pod、控制器控制的pod
自主式pod:
kubectl run nginx --image=nginx ##创建pod
kubectl get pod ##获取当前namespace的信息
kubectl get pod -o wide ##查看pod运行在哪个节点

控制器控制的pod:
先删除上边自主式创建的pod,再创建控制器控制的pod
kubectl create deployment myapp --image=nginx ##使用控制器部署pod
kubectl delete pod myapp-687598b8b4-xgxp7 ##删除pod,删除服务
pod的名字是控制器名+RS+容器名称
删除后,pod还在,ID变了,它会在同一个RS下拉取一个副本,有这个控制器存在,它会自动修复pod

关闭server4节点,再删除pod,pod会调度到server3节点上

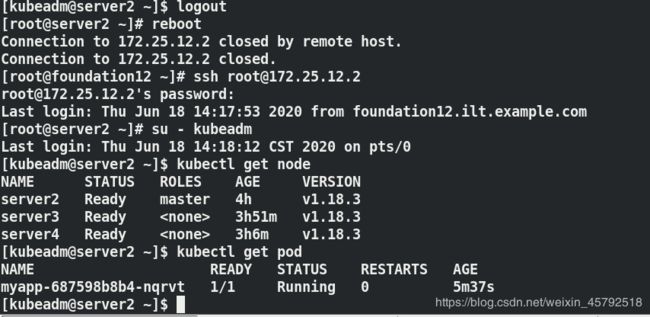
如果想要删除控制器控制的pod,直接把它的控制器删掉
kubectl delete deployment.apps myapp ##删除运行应用的Deployment、ReplicaSet 和 Pod(彻底删除)
kubectl get pod ##获取不到当前namespace的任何信息

5.2 Pod扩容与缩容
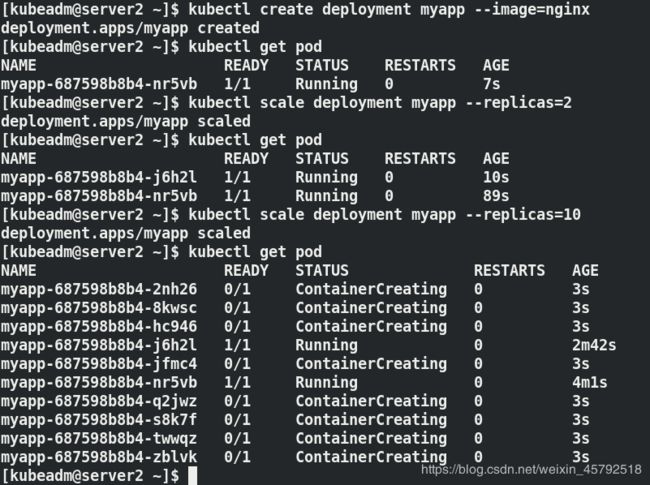
kubectl create deployment myapp --image=nginx
kubectl scale deployment myapp --replicas=2
kubectl scale deployment myapp --replicas=10 ##扩容到10个pod
kubectl scale deployment myapp --replicas=3 ##缩容到3个pod

5.3 service设定
service是一个抽象概念,定义了一个服务的多个pod逻辑合集和访问pod的策略,一般把service称为微服务。
ClusterIP: 默认类型,自动分配一个仅集群内部可以访问的虚拟IP
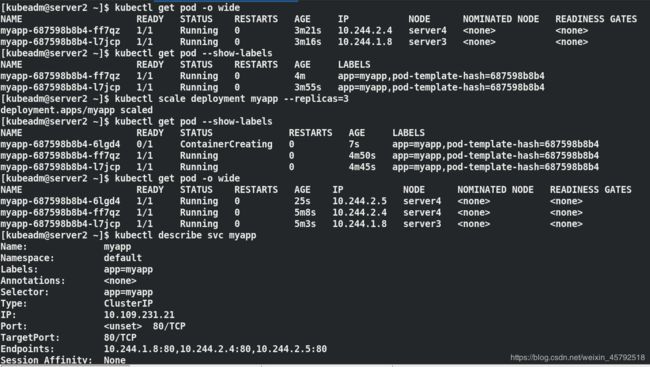
kubectl expose deployment myapp --port=80 --target-port=80 ##创建service,暴露端口,此时pod客户端可以通过service的名称访问后端的两个Pod
kubectl get svc ##查看service
kubectl describe svc myapp ##查看myapp详细信息

kubectl get pod -o wide ##查看pod在那个节点
kubectl get pod --show-labels ##列出pod标签
kubectl scale deployment myapp --replicas=3 ##对pod扩容
kubectl get pod --show-labels ##扩容的pod也会加上标签
kubectl get pod -o wide ##对扩容的pod分配ClusterIP
kubectl describe svc myapp
测试:
给私有仓库上推送busyboxplus镜像
kubectl run demo --image=busyboxplus -it ##i表示交互 t表示终端,在集群内部访问pod的ip,可以访问到




5.4. 使用NodePort类型暴露端口,实现集群外部访问Pod
NodePort: 在ClusterIP基础上为Service在每台机器上绑定一个端口,这样就可以通过 NodeIP:NodePort 来访问该服务
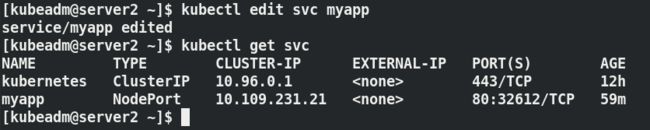
kubectl edit svc nginx ##修改service的type为NodePort
kubectl expose deployment nginx --port=80 --target-port=80 --type=NodePort ##也可以在创建service时指定类型

NodePort类型:自动给工作节点分配端口:32612

测试:
物理机访问工作节点的ip和pod端口
curl 172.25.12.4:32612
