卷积神经网络之1:LeNet-5
一.模型简介
LeNet5诞生于1994年,由Yann LeCun提出,充分考虑图像的相关性。当时结构的特点如下:
1)每个卷积层包含三个部分:卷积(Conv)、池化(ave-pooling)、非线性激活函数(sigmoid)
2)MLP作为最终的分类器
3)层与层之间稀疏连接减少计算复杂度
在这里面为啥叫LeNet-5,是因为在里面有5层卷积层(3层卷积层和2层全连接层),再加上2个池化层,一共是7层网络
二.结构模型

三.网络层计算
Input Layer:1*32*32图像
Conv1 Layer:包含6个卷积核,kernal size:5*5,parameters:(5*5+1)*6=156个
Subsampling Layer:average pooling,size:2*2
Activation Function:tanh 步长:2
Conv3 Layer:包含16个卷积核,kernal size:5*5 ->16个Feature Map
Subsampling Layer:average pooling,size:2*2 步长:2
Conv5 Layer:包含120个卷积核,kernal size:5*5
Fully Connected Layer:Activation Function:sigmoid
Output Layer:Gaussian connection(RBF)径向基函数
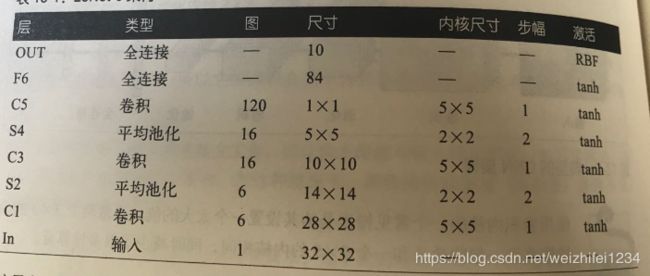
里面用的激活函数是tanh,里面使用的池化函数类型是平均池化函数
参数量的计算
其中K表示由L层到L+1层要产生的feature的数量,表示“卷积核”,表示偏置,也就是bias,令卷积核的大小为5*5,总共就有6*(5*5+1)=156个参数,对于卷积层C1,每个像素都与前一层的5*5个像素和1个bias有连接,所以总共有156*28*28=122304个连接(connection)。
对于LeNet5,S2这个pooling层是对C1中的2*2区域内的像素求和再加上一个偏置,然后将这个结果再做一次映射(sigmoid等函数),所以相当于对S1做了降维,此处共有6*2=12个参数。S2中的每个像素都与C1中的2*2个像素和1个偏置相连接,所以有6*5*14*14=5880个连接(connection)。
除此外,pooling层还有max-pooling和mean-pooling这两种实现,max-pooling即取2*2区域内最大的像素,而mean-pooling即取2*2区域内像素的均值。
LeNet5最复杂的就是S2到C3层,其连接如下图所示。
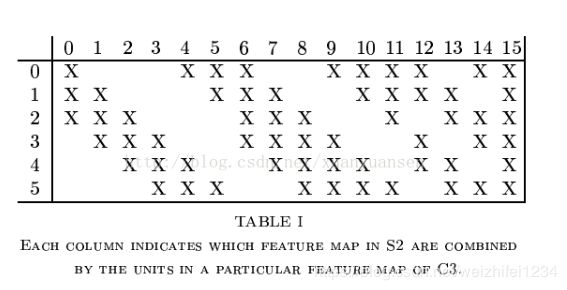
前6个feature map与S2层相连的3个feature map相连接,后面6个feature map与S2层相连的4个feature map相连接,后面3个feature map与S2层部分不相连的4个feature map相连接,最后一个与S2层的所有feature map相连。卷积核大小依然为5*5,所以总共有6*(3*5*5+1)+6*(4*5*5+1)+3*(4*5*5+1)+1*(6*5*5+1)=1516个参数。而图像大小为10*10,所以共有151600个连接。
S4是pooling层,窗口大小仍然是2*2,共计16个feature map,所以32个参数,16*(25*4+25)=2000个连接。
C5是卷积层,总共120个feature map,每个feature map与S4层所有的feature map相连接,卷积核大小是5*5,而S4层的feature map的大小也是5*5,所以C5的feature map就变成了1个点,共计有120(25*16+1)=48120个参数。
F6相当于MLP中的隐含层,有84个节点,所以有84*(120+1)=10164个参数。F6层采用了正切函数,![]()
输出层采用RBF函数,计算公式:
![]()
四.细节注意
MNIST原来的图像的大小是28*28像素的,但是它们被零填充到了32*32,并在输入到网络之前进行了归一化处理。网络的其余部分都不再使用任何填充,所以再网络中尺寸不断减小。
其中的卷积层中C3大多数神经元只是连接S2途中的三到四个神经元并没有全部连接
输出层有一些特殊:每个神经元输出其输入向量和权值之间的欧几里得距离(2-范数)的平方,而不是计算输入和权值向量之间的点乘。每个输出衡量该图片输入特定数字类的可能性。在这里交叉熵损失函数很重要,因为可以很大的程度上减小不良预测,同时产生大的梯度并且更快的收敛。
五.代码实现
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot = True)
sess = tf.InteractiveSession()
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1,shape = shape)
return tf.Variable(initial)
def conv2d(x,W):
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
x = tf.placeholder(tf.float32,[None,784])
y_ = tf.placeholder(tf.float32,[None,10])
x_image = tf.reshape(x,[-1,28,28,1])
# Conv1 Layer
W_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image,W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# Conv2 Layer
W_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1,W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
W_fc1 = weight_variable([7*7*64,1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1) + b_fc1)
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1,keep_prob)
W_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2) + b_fc2)
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv),reduction_indices=[1]))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1),tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
tf.global_variables_initializer().run()
for i in range(20000):
batch = mnist.train.next_batch(50)
if i % 1000 == 0:
train_accuracy = accuracy.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0})
print("step %d, training accuracy %g"%(i,train_accuracy))
train_step.run(feed_dict={x:batch[0],y_:batch[1],keep_prob:0.5})
print("test accuracy %g"%accuracy.eval(feed_dict={x:mnist.test.images,y_:mnist.test.labels,keep_prob:1.0}))