scrapy爬取ssr链接
title: scrapy爬取ssr链接
date: 2019-08-23 15:53:58
categories: 爬虫
tags:
- scrapy
- selenium
cover: https://www.github.com/OneJane/blog/raw/master/小书匠/3d21604af4ece8292ae728500ce2c4f7_hd.jpg
基于scrapy爬取ssr链接
环境搭建
python3.5
虚拟环境virtualenv
pip install virtualenv 提示pip版本太低
python -m pip install --upgrade pip
pip install -i https://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com django 使用豆瓣源加速
pip uninstall django 卸载django
virtualenv scrapytest 默认环境创建虚拟环境
cd scrapytest/Scripts && activate.bat && python 进入3.5虚拟环境
virtualenv -p D:\Python27\python.exe scrapytest
cd scrapytest/Scripts && activate.bat && python 进入2.7虚拟环境
deactivate.bat 退出虚拟环境
apt-get install python-virtualenv 安装虚拟环境
virtualenv py2 && cd py2 && cd bin && source activate && python 进入2.7虚拟环境
virtualenv -p /usr/bin/python3 py3 && && cd py3 && cd bin && source activate && python 进入3.5虚拟环境
虚拟环境virtualenvwrapper
pip install virtualenvwrapper
pip install virtualenvwrapper-win 解决workon不是内部指令
workon 列出所有虚拟环境
新建环境变量 WORKON_HOME=E:\envs
mkvirtualenv py3scrapy 新建并进入虚拟环境
deactivate 退出虚拟环境
workon py3scrapy 进入指定虚拟环境
pip install -i https://pypi.douban.com/simple scrapy 安装scrapy源
若缺少lxml出错https://www.lfd.uci.edu/~gohlke/pythonlibs/寻找对应版本的lxml的whl源
python -m pip install --upgrade pip 更新pip
pip install lxml-4.1.1-cp35-cp35m-win_amd64.whl
若缺少Twisted出错http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml搜对应版本Twisted
pip install Twisted‑17.9.0‑cp35‑cp35m‑win_amd64.whl
mkvirtualenv --python=D:\Python27\python.exe py2scrapy 一般不会出问题
pip install -i https://pypi.douban.com/simple scrapy
pip install virtualenvwrapper
find / -name virualenvwrapper.sh
vim ~/.bashrc
export WORKON_HOME=$HOME/.virtualenvs
source /home/wj/.local/bin/virtualenvwrapper.sh
source ~/.bashrc
mkvirtualenv py2scrapy 指向生成~/.virtualenv
deactivate 退出虚拟环境
mkdirtualenv --python=/usr/bin/python3 py3scrapy
项目实战
项目搭建
pip install virtualenvwrapper-win
mkvirtualenv --python=F:\Python\Python35\python.exe ssr
pip install Twisted-17.9.0-cp35-cp35m-win_amd64.whl
pip install -i https://pypi.douban.com/simple/ scrapy
scrapy startproject ssr
cd ssr
scrapy genspider ssr https://free-ss.tk/category/technology/
scrapy genspider --list
scrapy genspider -t crawl lagou www.lagou.com 使用crawl模板
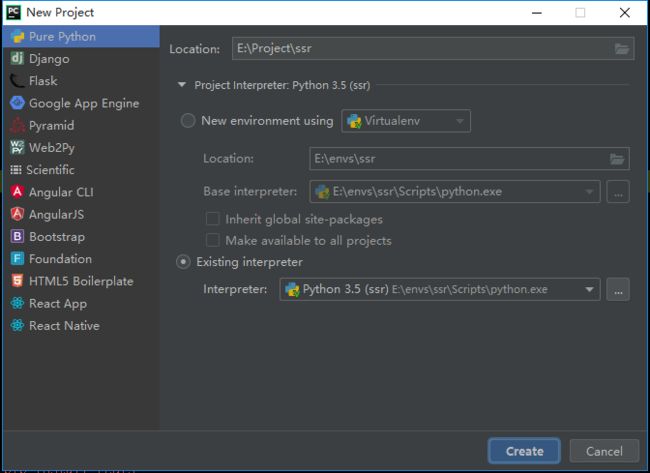
pycharm--新建项目---Pure Python---Interpreter为E:\envs\ssr\Scripts\python.exe
pycharm--打开---ssr,修改settings--project Interpreter为D:\Envs\ss
pip list
pip install -i https://pypi.douban.com/simple pypiwin32 pillow requests redis fake-useragent
pip install mysqlclient-1.4.4-cp35-cp35m-win_amd64.whl
或者pip install -i https://pypi.douban.com/simple mysqlclient
出错apt-get install libmysqlclient-dev
或者yum install python-devel mysql-devel
scrapy crawl jobbole
修改settings.py ROBOTSTXT_OBEY = False
scrapy shell http://blog.jobbole.com/ 可以在脚本中调试xpath或者chrome浏览器右键copy xpath,chrome浏览器右键copy selector
scrapy shell -s USER_AGENT="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0" https://www.zhihu.com/question/56320032
pip freeze > requirements.txt 生成依赖到文件
pip install -r requirements.txt 一键安装依赖
爬虫开发1
scrapy shell https://free-ss.tk/category/technology/ shell中查看节点
response.css(".posts-list .panel a::attr(href)").extract_first()
response.css(".posts-list .panel a img::attr(src)").extract_first()
response.xpath("//*[@id='container']/div/ul/li/article/a/img/@src").extract_first()
启动类main.py
from scrapy.cmdline import execute
import sys
import os
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy", "crawl", "free-ss.tk"])
基础配置ssr/settings.py
import os
BOT_NAME = 'ssr'
SPIDER_MODULES = ['ssr.spiders']
NEWSPIDER_MODULE = 'ssr.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'ssr (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
import sys
BASE_DIR = os.path.dirname(os.path.abspath(os.path.dirname(__file__)))
sys.path.insert(0, os.path.join(BASE_DIR, 'ssr'))
MYSQL_HOST = "127.0.0.1"
MYSQL_DBNAME = "scrapy"
MYSQL_USER = "root"
MYSQL_PASSWORD = ""
ITEM_PIPELINES = {
'ssr.pipelines.MysqlTwistedPipline': 2,#连接池异步插入
'ssr.pipelines.JsonExporterPipleline': 1,#连接池异步插入
}
ssr/pipelines.py
from scrapy.exporters import JsonItemExporter
from scrapy.pipelines.images import ImagesPipeline
import codecs
import json
import MySQLdb
import MySQLdb.cursors
from twisted.enterprise import adbapi
from ssr.utils.common import DateEncoder
class SsrPipeline(object):
def process_item(self, item, spider):
return item
class SsrImagePipeline(ImagesPipeline):
def item_completed(self, results, item, info):
if "front_image_url" in item:
for ok, value in results:
image_file_path = value["path"]
# 填充自定义路径
item["front_image_path"] = image_file_path
return item
class JsonWithEncodingPipeline(object):
# 自定义json文件的导出
def __init__(self):
self.file = codecs.open('article.json', 'w', encoding="utf-8")
def process_item(self, item, spider):
# 序列化,ensure_ascii利于中文,json没法序列化date格式,需要新写函数
lines = json.dumps(dict(item), ensure_ascii=False, cls=DateEncoder) + "\n"
self.file.write(lines)
return item
def spider_closed(self, spider):
self.file.close()
class JsonExporterPipleline(object):
# 调用scrapy提供的json export导出json文件
def __init__(self):
self.file = open('ssr.json', 'wb')
self.exporter = JsonItemExporter(self.file, encoding="utf-8", ensure_ascii=False)
self.exporter.start_exporting()
def close_spider(self, spider):
self.exporter.finish_exporting()
self.file.close()
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
class MysqlPipeline(object):
# 采用同步的机制写入mysql
def __init__(self):
self.conn = MySQLdb.connect('127.0.0.1', 'root', '123456', 'scrapy', charset="utf8", use_unicode=True)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
insert_sql = """
insert into ssr(url, ip,ssr, port,password,secret)
VALUES (%s, %s, %s, %s, %s)
"""
self.cursor.execute(insert_sql, (item["url"],item["ssr"], item["ip"], item["port"], item["password"], item["secret"]))
self.conn.commit()
class MysqlTwistedPipline(object):
# 异步连接池插入数据库,不会阻塞
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):# 初始化时即被调用静态方法
dbparms = dict(
host = settings["MYSQL_HOST"],#setttings中定义
db = settings["MYSQL_DBNAME"],
user = settings["MYSQL_USER"],
passwd = settings["MYSQL_PASSWORD"],
charset='utf8',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True,
)
dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms)
return cls(dbpool)
def process_item(self, item, spider):
#使用twisted将mysql插入变成异步执行
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error, item, spider) #处理异常
def handle_error(self, failure, item, spider):
#处理异步插入的异常
print (failure)
def do_insert(self, cursor, item):
#执行具体的插入,不具体的如MysqlPipeline.process_item()
#根据不同的item 构建不同的sql语句并插入到mysql中
insert_sql, params = item.get_insert_sql()
cursor.execute(insert_sql, params)
实体类ssr/items.py
import scrapy
from scrapy.loader import ItemLoader
from scrapy.loader.processors import MapCompose, TakeFirst, Join
import re
import datetime
from w3lib.html import remove_tags
def date_convert(value):
try:
create_date = datetime.datetime.strptime(value, "%Y/%m/%d").date()
except Exception as e:
create_date = datetime.datetime.now().date()
return create_date
def get_nums(value):
match_re = re.match(".*?(\d+).*", value)
if match_re:
nums = int(match_re.group(1))
else:
nums = 0
return nums
def return_value(value):
return value
class SsrItemLoader(ItemLoader):
# 自定义itemloader
default_output_processor = TakeFirst()
class SsrItem(scrapy.Item):
url = scrapy.Field()
ip = scrapy.Field(
input_processor=MapCompose(return_value),#传递进来可以预处理
)
port = scrapy.Field()
ssr = scrapy.Field()
front_image_url = scrapy.Field()
password = scrapy.Field()
secret = scrapy.Field()
def get_insert_sql(self):
insert_sql = """
insert into ssr(url,ssr, ip, port, password,secret)
VALUES (%s, %s,%s, %s, %s,%s)
ON DUPLICATE KEY UPDATE ssr=VALUES(ssr)
"""
params = (self["url"],self["ssr"], self["ip"],self["port"], self["password"],self["secret"])
return insert_sql, params
核心代码ssr/spiders/free_ss_tk.py
# -*- coding: utf-8 -*-
import time
from datetime import datetime
from urllib import parse
import scrapy
from scrapy.http import Request
from ssr.items import SsrItemLoader, SsrItem
class FreeSsTkSpider(scrapy.Spider):
name = 'free-ss.tk'
# 必须一级域名
allowed_domains = ['free-ss.tk']
start_urls = ['https://free-ss.tk/category/technology/']
custom_settings = { # 优先并覆盖项目,避免被重定向
"COOKIES_ENABLED": False, # 关闭cookies
"DOWNLOAD_DELAY": 1,
'DEFAULT_REQUEST_HEADERS': {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Cookie': '',
'Host': 'free-ss.tk',
'Origin': 'https://free-ss.tk/',
'Referer': 'https://free-ss.tk/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
}
def parse(self, response):
# post_nodes = response.css(".posts-list .panel>a")
# for post_node in post_nodes:
# image_url = post_node.css("img::attr(src)").extract_first("")
# post_url = post_node.css("::attr(href)").extract_first("")
# yield Request(url=parse.urljoin(response.url, post_url), meta={"front_image_url": image_url},callback=self.parse_detail) # response获取meta
#
# next_url = response.css(".next-page a::attr(href)").extract_first("")
# if next_url:
# print(next_url)
# yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse)
post_node = response.css(".posts-list .panel>a")[0]
image_url = post_node.css("img::attr(src)").extract_first("")
post_url = post_node.css("::attr(href)").extract_first("")
yield Request(url=parse.urljoin(response.url, post_url), meta={"front_image_url": image_url},
callback=self.parse_detail) # response获取meta
def parse_detail(self, response):
# 通过item loader加载item
front_image_url = response.meta.get("front_image_url", "") # 文章封面图
ssr_nodes = response.css("table tbody tr")
with open(datetime.now().strftime('%Y-%m-%d'), 'a') as file_object:
for ssr in ssr_nodes:
item_loader = SsrItemLoader(item=SsrItem(), response=response) # 默认ItemLoader是一个list,自定义TakeFirst()
print(ssr.xpath("td[4]/text()").extract_first(""))
item_loader.add_value("url", response.url)
item_loader.add_value("ssr", ssr.css("td:nth-child(1)>a::attr(href)").extract_first(""))
item_loader.add_value("ip", ssr.css("td:nth-child(2)::text").extract_first(""))
item_loader.add_value("front_image_url", front_image_url)
item_loader.add_value("port", ssr.xpath("td[3]/text()").extract_first(""))
item_loader.add_value("password", ssr.xpath("td[4]/text()").extract_first(""))
item_loader.add_value("secret", ssr.xpath("td[5]/text()").extract_first(""))
ssr_item = item_loader.load_item()
file_object.write(ssr.css("td:nth-child(1)>a::attr(href)").extract_first("")+"\n")
yield ssr_item # 将传到piplines中
爬虫开发2
# -*- coding: utf-8 -*-
import time
from datetime import datetime
from urllib import parse
import scrapy
from scrapy.http import Request
from ssr.items import SsrItemLoader, SsrItem
class FanQiangSpider(scrapy.Spider):
name = 'fanqiang.network'
# 必须一级域名
allowed_domains = ['fanqiang.network']
start_urls = ['https://fanqiang.network/免费ssr']
def parse(self, response):
post_nodes = response.css(".post-content table tbody tr")
item_loader = SsrItemLoader(item=SsrItem(), response=response)
with open(datetime.now().strftime('%Y-%m-%d'), 'a') as file_object:
for post_node in post_nodes:
item_loader.add_value("url", response.url)
item_loader.add_value("ssr", post_node.css("td:nth-child(1)>a::attr(href)").extract_first("").replace("http://free-ss.tk/", ""))
item_loader.add_value("ip", post_node.css("td:nth-child(2)::text").extract_first(""))
item_loader.add_value("port", post_node.xpath("td[3]/text()").extract_first(""))
item_loader.add_value("password", post_node.xpath("td[4]/text()").extract_first(""))
item_loader.add_value("secret", post_node.xpath("td[5]/text()").extract_first(""))
ssr_item = item_loader.load_item()
file_object.write(post_node.css("td:nth-child(1)>a::attr(href)").extract_first("").replace("http://free-ss.tk/", "") + "\n")
yield ssr_item # 将传到piplines中
多爬虫同时运行
settings.py
COMMANDS_MODULE = 'ssr'
ssr/crawlall.py
from scrapy.commands import ScrapyCommand
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return '[options]'
def short_desc(self):
return 'Runs all of the spiders'
def run(self, args, opts):
spider_list = self.crawler_process.spiders.list()
for name in spider_list:
self.crawler_process.crawl(name, **opts.__dict__)
self.crawler_process.start()
main.py
from scrapy import cmdline
from scrapy.cmdline import execute
import sys
import os
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
# execute(["scrapy", "crawl", "free-ss.tk"])
# execute(["scrapy", "crawl", "fanqiang.network"])
cmdline.execute("scrapy crawlall".split())
防反爬
随机ua
pip install -i https://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com scrapy-fake-useragent
DOWNLOADER_MIDDLEWARES = {
'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 1,
}
报错socket.timeout: timed out,查看F:/Anaconda3/Lib/site-packages/fake_useragent/settings.py
__version__ = '0.1.11'
DB = os.path.join(
tempfile.gettempdir(),
'fake_useragent_{version}.json'.format(
version=__version__,
),
)
CACHE_SERVER = 'https://fake-useragent.herokuapp.com/browsers/{version}'.format(
version=__version__,
)
BROWSERS_STATS_PAGE = 'https://www.w3schools.com/browsers/default.asp'
BROWSER_BASE_PAGE = 'http://useragentstring.com/pages/useragentstring.php?name={browser}' # noqa
BROWSERS_COUNT_LIMIT = 50
REPLACEMENTS = {
' ': '',
'_': '',
}
SHORTCUTS = {
'internet explorer': 'internetexplorer',
'ie': 'internetexplorer',
'msie': 'internetexplorer',
'edge': 'internetexplorer',
'google': 'chrome',
'googlechrome': 'chrome',
'ff': 'firefox',
}
OVERRIDES = {
'Edge/IE': 'Internet Explorer',
'IE/Edge': 'Internet Explorer',
}
HTTP_TIMEOUT = 5
HTTP_RETRIES = 2
HTTP_DELAY = 0.1
http://useragentstring.com/pages/useragentstring.php?name=Chrome 打开超时报错,其中CACHE_SERVER是存储了所有UserAgent的json数据,再次观察其中DB这个变量,结合fake_useragent\fake.py中的逻辑,判断这个变量应该是存储json数据的,所以大体逻辑应该是,首次初始化时,会自动爬取CACHE_SERVER中的json数据,然后将其存储到本地,所以我们直接将json存到指定路径下,再次初始化时,应该就不会报错
>>> import tempfile
>>> print(tempfile.gettempdir())
C:\Users\codewj\AppData\Local\Temp
将CACHE_SERVER的json数据保存为fake_useragent_0.1.11.json,并放到目录C:\Users\codewj\AppData\Local\Temp中
>>> import fake_useragent
>>> ua = fake_useragent.UserAgent()
>>> ua.data_browsers['chrome'][0]
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36'
注:如果CACHE_SERVER不是https://fake-useragent.herokuapp.com/browsers/0.1.11,请更新一下库pip install --upgrade fake_useragent