通过mongo-hadoop(pymongo_spark)从PySpark保存数据到MongoDB
一、背景
PySpark to connect to MongoDB via mongo-hadoop
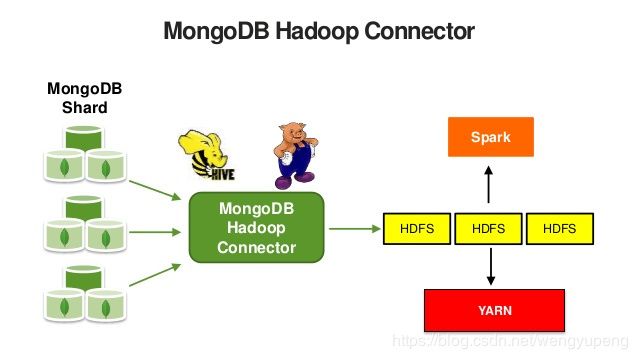
二、配置步骤
(注意版本作相应调整,spark-2.4.3,hadoop2.7,Scala2.11)
1. # Get the MongoDB Java Driver
#PROJECT_HOME 自定义的项目根目录,下面存放spark等
mkdir -p $PROJECT_HOME/lib
cd $PROJECT_HOME
echo "Fetching the MongoDB Java Driver to $PROJECT_HOME/lib/ ..."
curl -Lko lib/mongo-java-driver-3.9.0.jar http://central.maven.org/maven2/org/mongodb/mongo-java-driver/3.9.0/mongo-java-driver-3.9.0.jar
2. # Install the mongo-hadoop project in the mongo-hadoop directory in the root of our project.
echo "Installing the mongo-hadoop project in $PROJECT_HOME/mongo-hadoop ..."
#https://github.com/mongodb/mongo-hadoop.git
curl -Lko /tmp/mongo-hadoop-r2.0.2.tar.gz https://github.com/mongodb/mongo-hadoop/archive/r2.0.2.tar.gz
mkdir mongo-hadoop
tar -xvzf /tmp/mongo-hadoop-r2.0.2.tar.gz -C mongo-hadoop --strip-components=1
3. # build the mongo-hadoop-spark jars
echo "Building mongo-hadoop..."
cd mongo-hadoop
./gradlew jar
cd ..
cp mongo-hadoop/spark/build/libs/mongo-hadoop-spark-*.jar lib/
cp mongo-hadoop/build/libs/mongo-hadoop-*.jar lib/
cp mongo-hadoop/core/build/libs/mongo-hadoop-*.jar lib/
4. # Now build the pymongo_spark package
# pip install py4j # add sudo if needed
# pip install pymongo # add sudo if needed
# pip install pymongo-spark # add sudo if needed
cd mongo-hadoop/spark/src/main/python
python setup.py install
cd $PROJECT_HOME# to $PROJECT_HOME
cp mongo-hadoop/spark/src/main/python/pymongo_spark.py lib/
export PYTHONPATH=$PYTHONPATH:$PROJECT_HOME/lib
echo 'export PYTHONPATH=$PYTHONPATH:$PROJECT_HOME/lib' >> ~/.bashrc
5.# Install and add snappy-java and lzo-java to our classpath below via spark.jars
echo "Installing snappy-java and lzo-hadoop to $PROJECT_HOME/lib ..."
curl -Lko lib/snappy-java-1.1.2.6.jar http://central.maven.org/maven2/org/xerial/snappy/snappy-java/1.1.2.6/snappy-java-1.1.2.6.jar
curl -Lko lib/lzo-hadoop-1.0.5.jar http://central.maven.org/maven2/org/anarres/lzo/lzo-hadoop/1.0.5/lzo-hadoop-1.0.5.jar
6.# Setup mongo jars for Spark
echo "spark.jars $PROJECT_HOME/lib/mongo-hadoop-spark-2.0.0-rc0.jar,\
$PROJECT_HOME/lib/mongo-java-driver-3.9.0.jar,\
$PROJECT_HOME/lib/mongo-hadoop-2.0.2.jar,\
$PROJECT_HOME/lib/mongo-hadoop-core-2.0.2.jar,\
$PROJECT_HOME/lib/snappy-java-1.1.2.6.jar,\
$PROJECT_HOME/lib/lzo-hadoop-1.0.5.jar" \
>> spark/conf/spark-defaults.conf
三、测试结果
运行 pyspark
import pymongo_spark
# Important: activate pymongo_spark.
pymongo_spark.activate()
csv_lines = sc.textFile("data/example.csv")
data = csv_lines.map(lambda line: line.split(","))
schema_data = data.map(lambda x: {'name': x[0], 'company': x[1], 'title': x[2]})
schema_data.saveToMongoDB('mongodb://localhost:27017/company.employees'
> db.employees.find().pretty()
{
"_id" : ObjectId("5d282970dc833e5c55b397c7"),
"name" : "Donald Trump",
"company" : "The Trump Organization",
"title" : "CEO"
}
{
"_id" : ObjectId("5d282970dc833e5c55b397c9"),
"name" : "Russell Jurney",
"company" : "Data Syndrome",
"title" : "Principal Consultant"
}
{
"_id" : ObjectId("5d282970dc833e5c55b397c6"),
"name" : "Russell Jurney",
"company" : "Relato",
"title" : "CEO"
}
{
"_id" : ObjectId("5d282970dc833e5c55b397c8"),
"name" : "Florian Liebert",
"company" : "Mesosphere",
"title" : "CEO"
}
{
"_id" : ObjectId("5d282970dc833e5c55b397ca"),
"name" : "Don Brown",
"company" : "Rocana",
"title" : "CIO"
}
{
"_id" : ObjectId("5d282970dc833e5c55b397cb"),
"name" : "Steve Jobs",
"company" : "Apple",
"title" : "CEO"
}