DSSD理论+源码学习(1)
DSSD理论+源码学习(1)
前段时候开始踏坑detection。因为项目需要,所以也开始摸爬滚打地一点一点学。昨晚结识了一位类脑实验室的前辈,他对学术的态度以及在csdn上的学习记录很是shock到我。所以自己也开始尝试去记录一些笔记,其一加深自己的理解,其二可以互相交流学习。
- DSSD理论+源码学习(1)
- 什么是DSSD
- 整体代码结构
- ssh.py源码
- 参考文献
什么是DSSD
DSSD是在SSD的基础,第一篇做改进的论文。它的改进背景是基于SSD对于小物体检测的效果并不好。
在引出背景前,先借用下CSDN某大神说过的一段话。

背景:
所以检测小目标物体不够鲁棒有什么解决办法呢?作者就想到给检测网络添加上下文信息。因为在SSD中第一个feature map(FM)取的是con4_3层,这层属于偏浅的层,固然它的感受野也不是那么的大。该层所包含的边缘信息较多,语义信息较少。(具体原因不详,目前普遍认为深层FM所带有的语义信息更丰富)
那作者就思考能不能把浅层的FM和深层的FM结合在一起,这样送到检测网络中的特征就既有语义信息又有边缘信息。 和该论文很类似的一个工作是FSSD(Feature Fusion Single Shot Multibox Detector ),它的方法也是类似于利用将深浅层信息融合,属于SSD+FPN的结合版。这里就不赘述了~
创新点
(1)预测模块
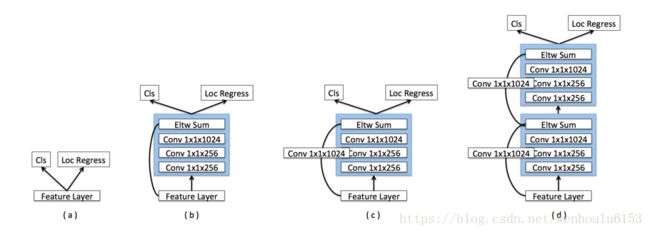
ssd中的预测模块用的是上图中的(a),本论文中用的是(c)。
作者的理由是:在MS-CNN工作中提到,改进每个任务的子网络可以提高准确率。其实这里就类似于残差网络。具体这样添加的真实意义其实不太清楚,但从结果上来看确实得到了提升。
(2)反卷积模块
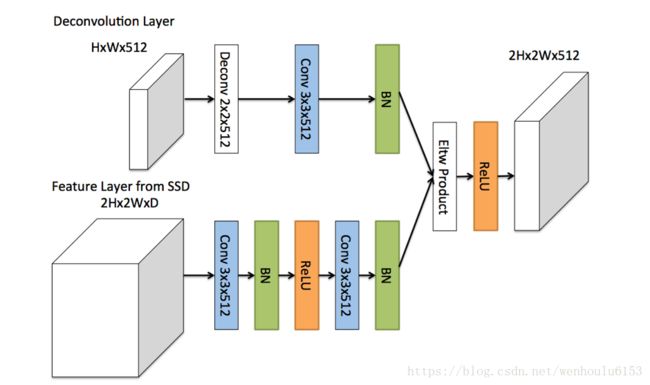
为了整合浅层特征图和反卷积层的信息,作者引入了如上图所示的反卷积模块,该模块可以适合整个DSSD架构(figure1 底部实心圆圈)。作者受到论文Learning to Refine Object Segments的启发,认为用于精细网络的反卷积模块的分解结构达到的精度可以和复杂网络一样,并且更有效率。作者对其进行了一定的修改,如上图所示:其一,在每个卷积层后添加批归一化层;其二,使用基于学习的反卷积层而不是简单地双线性上采样;其三,作者测试了不同的结合方式,元素求和(element-wise sum)与元素点积(element-wise product)方式,实验证明点积计算能得到更好的精度。
(3)基本网络:将VGG网络换为Resnet网络 目的是为了改善Accuracy。现在许多工作把基本网络从以往的VGG换成resnet后准确率的点多少都会提高。SSD核心架构
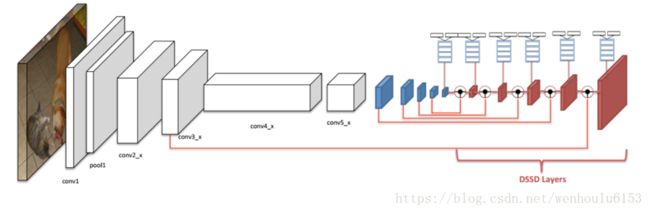
对于最底层的FM,一层一层往上反卷积,并将反卷积的结果和之前下采样的结果通过点积结合在一起。得到新的融合FM放到预测模块中去获得分类及检测结果。
整体代码结构
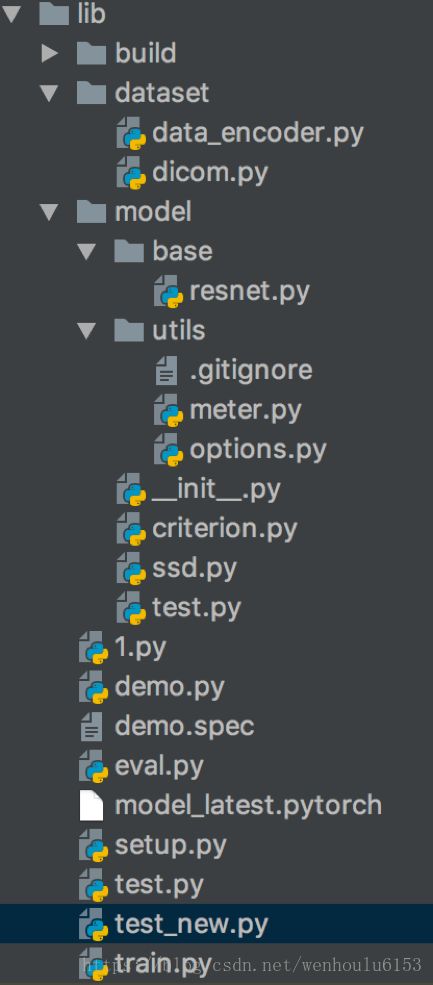
lib文件夹:
1. dataset文件夹
dicom.py:读图,并返回bbox(个数、置信值、位置)、图片等;
data_encoder.py:产生anchor的标签,在测试阶段会对偏移的location进行还原,并NMS(非极大值抑制)
2. model文件夹
resent.py:残差网络的基本网络,用的是resnet50
meter.py:存储参数,更新参数
options.py:超参数的定义
criterion.py:计算每个proposal box的loss
ssd.py:dssd主要网络的构建
ssh.py源码
import torch
import ipdb
import torch.nn as nn
import torch.nn.init as init
import torch.nn.functional as func
from copy import deepcopy
from model.base.resnet import _resnet
from model import criterion
Args = {
'Base': 'resnext101-32x4d',
'Base_FN': 6,
'Base_Extra_FN': 1,
'Base_Extra_Channels': 1024,
'Groups': 4,
'Classes': 1,
'Anchors': [4, 6, 6, 6, 4, 4],
'Feature_Channels': [256, 256, 256, 256, 256, 256]
}
#正则化
class L2Norm(nn.Module):
def __init__(self, n_channels, scale):
super(L2Norm, self).__init__()
self.n_channels = n_channels
self.gamma = scale or None
self.eps = 1e-10
self.weight = nn.Parameter(torch.Tensor(self.n_channels))
self.reset_parameters()
def reset_parameters(self):
init.constant(self.weight, self.gamma)
def forward(self, x):
norm = x.pow(2).sum(dim=1, keepdim=True).sqrt() + self.eps
x = x/norm
out = self.weight.unsqueeze(0).unsqueeze(2).unsqueeze(3).expand_as(x) * x
return out
#求每一个feture map对应的卷积结果 返回anchor的bbox预测值和得分
#备注:这里没有加dssd中的预测模块,太繁琐,有机会加一下。
class MultiBox(nn.Module):
def __init__(self):
super(MultiBox, self).__init__()
self.conv_loc = nn.ModuleList()#定义模块的列表
self.conv_conf = nn.ModuleList()
#对6个FM都过3*3的卷积,loc得到4个结果,conf得到1个置信结果
for i in range(len(Args['Feature_Channels'])):
self.conv_loc.append(nn.Conv2d(Args['Feature_Channels'][i], Args['Anchors'][i] * 4,
kernel_size=3, padding=1))
self.conv_conf.append(nn.Conv2d(Args['Feature_Channels'][i],
Args['Anchors'][i] * Args['Classes'], kernel_size=3, padding=1))
self.init_parameters()
def init_parameters(self):
cls_num = Args['Classes'] // 2
for i in range(len(Args['Feature_Channels'])):
weight = self.conv_conf[i].weight.data
weight = weight.view(-1, Args['Classes'], Args['Feature_Channels'][i], 3, 3)
weight[:, 1:cls_num + 1, ...].copy_(weight[:, cls_num + 1:, ...])#关于pytorch的初始化原理现在也还在学习,后续补上
self.conv_conf[i].weight.data.copy_(weight.view_as(self.conv_conf[i].weight))
bias = self.conv_conf[i].bias.data
bias = bias.view(-1, Args['Classes'])
bias[:, 1:cls_num + 1].copy_(bias[:, cls_num + 1:]+1)
self.conv_conf[i].bias.data.copy_(bias.view_as(self.conv_conf[i].bias))
def forward(self, xs):
y_locs = []
y_confs = []
for i, x in enumerate(xs):
y_loc = self.conv_loc[i](x)
batch_size = y_loc.size(0)
y_loc = y_loc.permute(0, 2, 3, 1).contiguous()
y_loc = y_loc.view(batch_size, -1, 4)
y_locs.append(y_loc)
y_conf = self.conv_conf[i](x)
y_conf = y_conf.permute(0, 2, 3, 1).contiguous()
y_conf = y_conf.view(batch_size, -1, Args['Classes'])
y_confs.append(y_conf)
loc_preds = torch.cat(y_locs, 1)
conf_preds = torch.cat(y_confs, 1)
return loc_preds, conf_preds
#ssd核心架构
class ModelSSD(nn.Module):
def __init__(self):
super(ModelSSD, self).__init__()
base = _resnet()
self.base_feature_38 = base.feature_8x
self.base_feature_19 = base.feature_16x
self.base_feature_10 = base.feature_32x
# base = resnext.resnext101_32x4d()
# self.base_feature_38 = nn.Sequential(*list(base.features.children())[:6])
# self.base_feature_19 = nn.Sequential(*list(base.features.children())[6])
# self.base_feature_10 = nn.Sequential(*list(base.features.children())[7])
self.norm4 = L2Norm(512, 20)
self.down_feature_38 = self.conv_bn_layer(512, 256)
self.down_feature_19 = self.conv_bn_layer(1024, 256)
self.down_feature_10 = self.conv_bn_layer(2048, 256)
self.down_feature_5 = self.conv_bn_layer(2048, 256, stride=2)
self.down_feature_3 = self.conv_bn_layer(256, 256, resize=False)
self.down_feature_1 = self.conv_bn_layer(256, 256, resize=False)
self.up_feature_3 = self.conv_bn_layer(256, 256)
self.up_feature_5 = self.conv_bn_layer(256, 256)
self.up_feature_10 = self.conv_bn_layer(256, 256)
self.up_feature_19 = self.conv_bn_layer(256, 256)
self.up_feature_38 = self.conv_bn_layer(256, 256)
#1*1的卷积层
self.bypass_1 = self.bypass_layer(256, 256)
self.bypass_3 = self.bypass_layer(256, 256)
self.bypass_5 = self.bypass_layer(256, 256)
self.bypass_10 = self.bypass_layer(256, 256)
self.bypass_19 = self.bypass_layer(256, 256)
self.bypass_38 = self.bypass_layer(256, 256)
self.down_feature = nn.ModuleList([self.down_feature_1, self.down_feature_3, self.down_feature_5,
self.down_feature_10, self.down_feature_19, self.down_feature_38])
self.up_feature = nn.ModuleList([self.up_feature_3, self.up_feature_5,
self.up_feature_10, self.up_feature_19, self.up_feature_38])
self.bypass = nn.ModuleList([self.bypass_1, self.bypass_3, self.bypass_5, self.bypass_10,
self.bypass_19, self.bypass_38])
self.mbox_multi = MultiBox()#获得bbox的预测框以及置信得分
self.ssd_stack = nn.ModuleList([self.up_feature, self.down_feature, self.norm4,
self.bypass, self.mbox_multi])
self.init_parameters([self.up_feature, self.down_feature, self.norm4, self.bypass])
self.criterion_multi = criterion.MultiBoxLoss(1, 1)
@staticmethod
def bypass_layer(fn_conv, fn_deconv):
shortcut = nn.Sequential()
shortcut.add_module('shortcut_conv',
nn.Conv2d(fn_conv, fn_deconv, kernel_size=1, padding=0))
shortcut.add_module('shortcut_bn', nn.BatchNorm2d(fn_deconv))
return shortcut
@staticmethod
def upsample_layer(size=None):
upsample = nn.Upsample(size=size, mode='bilinear')
return upsample
@staticmethod
#==========================
def conv_bn_layer(feature_in, feature_out, reduce=1, stride=1, resize=True):
block = nn.Sequential()
feature_mid = feature_out // reduce
block.add_module('conv_reduce', nn.Conv2d(feature_in, feature_mid, kernel_size=1))
block.add_module('bn_reduce', nn.BatchNorm2d(feature_mid))
block.add_module('relu_reduce', nn.ReLU())
block.add_module('conv_expand', nn.Conv2d(feature_mid, feature_out, kernel_size=3,
stride=stride, padding=1 if resize else 0))
block.add_module('bn_expand', nn.BatchNorm2d(feature_out))
return block
@staticmethod
def init_parameters(layers):
for layer in layers:
for key in layer.state_dict():
if key.split('.')[-1] == 'weight':
if 'bn' in key:
layer.state_dict()[key][...] = 1
elif key.split('.')[-1] == 'bias':
layer.state_dict()[key][...] = 0
def forward(self, x, target_locs, target_confs, training=True):
down_features = []
up_features = []
# Down Feature
y = self.base_feature_38(x)
fn = self.norm4.forward(y)
fn = func.relu(self.down_feature_38(fn))
down_features.append(fn)#保存所有的下采样结果
y = self.base_feature_19(y)
fn = func.relu(self.down_feature_19(y))
down_features.append(fn)
y = self.base_feature_10(y)
fn = func.relu(self.down_feature_10(y))
down_features.append(fn)
y = func.relu(self.down_feature_5(y))
down_features.append(y)
y = func.relu(self.down_feature_3(y))
down_features.append(y)
y = func.relu(self.down_feature_1(y))
down_features.append(y)
# Up Feature
y = func.relu(self.bypass_1(y))
up_features.append(y)
#将上下采样的FM结果融合在一起
#将下采样的结果过一个1*1的卷积核,保证两个FM融合时channel一样
y = self.bypass_3(down_features[-2]) + func.upsample(y, size=3, mode='bilinear')#这里用的是双线性差值上采样,没有用deconv
y = func.relu(self.up_feature_3(y))
up_features.append(y)
y = self.bypass_5(down_features[-3]) + func.upsample(y, size=5, mode='bilinear')
y = func.relu(self.up_feature_5(y))
up_features.append(y)
y = self.bypass_10(down_features[-4]) + func.upsample(y, size=10, mode='bilinear')
y = func.relu(self.up_feature_10(y))
up_features.append(y)
y = self.bypass_19(down_features[-5]) + func.upsample(y, size=19, mode='bilinear')
y = func.relu(self.up_feature_19(y))
up_features.append(y)
y = self.bypass_38(down_features[-6]) + func.upsample(y, size=38, mode='bilinear')
y = func.relu(self.up_feature_38(y))
up_features.append(y)
up_features.reverse()
# Bounding Box 将融合的特征放入multibox函数算loc值以及conf值
loc_preds, conf_preds = self.mbox_multi(up_features)
if not training:
return loc_preds, conf_preds
#计算预测值与实际值的偏差。利用softmax计算conf的loss,利用smooth L1 计算locatin的loss
loc_loss, actp_loss, actn_loss = self.criterion_multi(loc_preds, target_locs, conf_preds, target_confs)
return loc_preds, conf_preds, loc_loss.unsqueeze(0), actp_loss.unsqueeze(0), actn_loss.unsqueeze(0)
下一篇将继续剖析源码,等有空的时候写下。
未完待续…
参考文献
[1] SSD目标检测算法改进DSSD(反卷积)
[2]Face Paper:DSSD目标检测