Face Paper:SeNet论文详解
github: https://github.com/hujie-frank/SENet
我是 Momenta 的高级研发工程师胡杰,很高兴可以和大家分享我们的 SENet。借助我们提出的 SENet,我们团队(WMW)以极大的优势获得了最后一届 ImageNet 2017 竞赛 Image Classification 任务的冠军,并被邀请在 CVPR 2017 的 workshop(Beyond ImageNet)中给出算法介绍。下面我将介绍我们提出的 SENet,论文和代码会在近期公布在 arXiv 上,欢迎大家 follow 我们的工作,并给出宝贵的建议和意见。
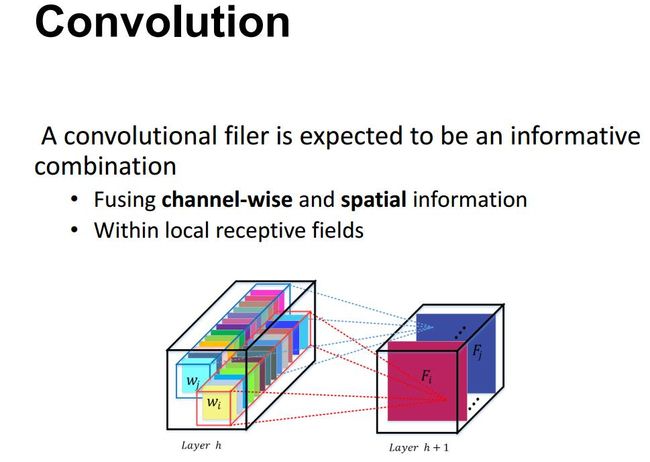
我们从最基本的卷积操作开始说起。近些年来,卷积神经网络在很多领域上都取得了巨大的突破。而卷积核作为卷积神经网络的核心,通常被看做是在局部感受野上,将空间上(spatial)的信息和特征维度上(channel-wise)的信息进行聚合的信息聚合体。卷积神经网络由一系列卷积层、非线性层和下采样层构成,这样它们能够从全局感受野上去捕获图像的特征来进行图像的描述。
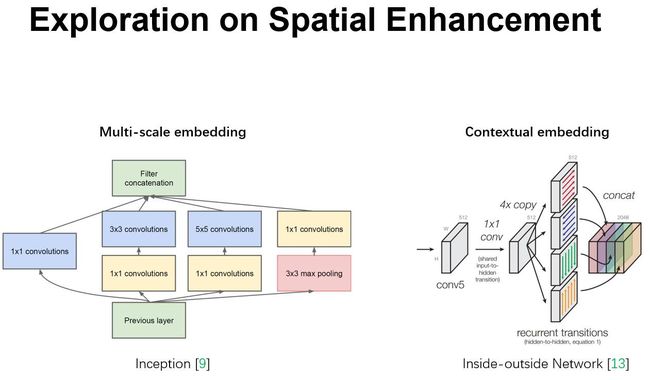
然而去学到一个性能非常强劲的网络是相当困难的,其难点来自于很多方面。最近很多工作被提出来从空间维度层面来提升网络的性能,如 Inception 结构中嵌入了多尺度信息,聚合多种不同感受野上的特征来获得性能增益;在 Inside-Outside 网络中考虑了空间中的上下文信息;还有将 Attention 机制引入到空间维度上,等等。这些工作都获得了相当不错的成果。

我们可以看到,已经有很多工作在空间维度上来提升网络的性能。那么很自然想到,网络是否可以从其他层面来考虑去提升性能,比如考虑特征通道之间的关系?我们的工作就是基于这一点并提出了 Squeeze-and-Excitation Networks(简称 SENet)。在我们提出的结构中,Squeeze 和 Excitation 是两个非常关键的操作,所以我们以此来命名。我们的动机是希望显式地建模特征通道之间的相互依赖关系。另外,我们并不打算引入一个新的空间维度来进行特征通道间的融合,而是采用了一种全新的「特征重标定」策略。具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
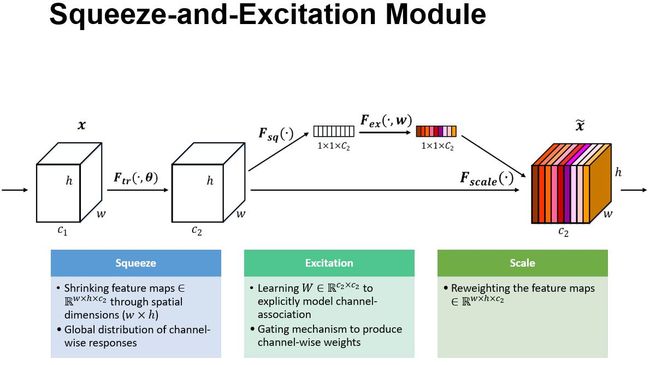
上图是我们提出的 SE 模块的示意图。给定一个输入 x,其特征通道数为 c_1,通过一系列卷积等一般变换后得到一个特征通道数为 c_2 的特征。与传统的 CNN 不一样的是,接下来我们通过三个操作来重标定前面得到的特征。
首先是 Squeeze 操作,我们顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
其次是 Excitation 操作,它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。
最后是一个 Reweight 的操作,我们将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
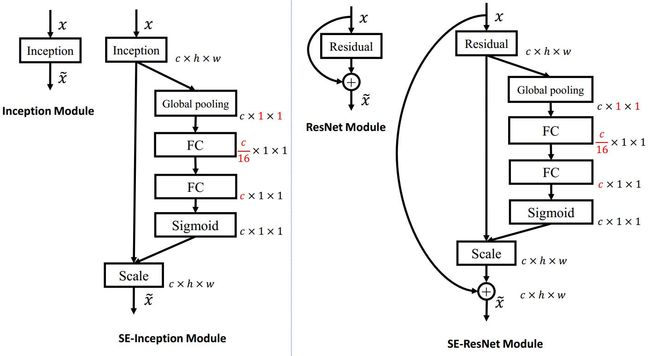
上左图是将 SE 模块嵌入到 Inception 结构的一个示例。方框旁边的维度信息代表该层的输出。
这里我们使用 global average pooling 作为 Squeeze 操作。紧接着两个 Fully Connected 层组成一个 Bottleneck 结构去建模通道间的相关性,并输出和输入特征同样数目的权重。我们首先将特征维度降低到输入的 1/16,然后经过 ReLu 激活后再通过一个 Fully Connected 层升回到原来的维度。这样做比直接用一个 Fully Connected 层的好处在于:1)具有更多的非线性,可以更好地拟合通道间复杂的相关性;2)极大地减少了参数量和计算量。然后通过一个 Sigmoid 的门获得 0~1 之间归一化的权重,最后通过一个 Scale 的操作来将归一化后的权重加权到每个通道的特征上。
除此之外,SE 模块还可以嵌入到含有 skip-connections 的模块中。上右图是将 SE 嵌入到 ResNet 模块中的一个例子,操作过程基本和 SE-Inception 一样,只不过是在 Addition 前对分支上 Residual 的特征进行了特征重标定。如果对 Addition 后主支上的特征进行重标定,由于在主干上存在 0~1 的 scale 操作,在网络较深 BP 优化时就会在靠近输入层容易出现梯度消散的情况,导致模型难以优化。
目前大多数的主流网络都是基于这两种类似的单元通过 repeat 方式叠加来构造的。由此可见,SE 模块可以嵌入到现在几乎所有的网络结构中。通过在原始网络结构的 building block 单元中嵌入 SE 模块,我们可以获得不同种类的 SENet。如 SE-BN-Inception、SE-ResNet、SE-ReNeXt、SE-Inception-ResNet-v2 等等。

从上面的介绍中可以发现,SENet 构造非常简单,而且很容易被部署,不需要引入新的函数或者层。除此之外,它还在模型和计算复杂度上具有良好的特性。拿 ResNet-50 和 SE-ResNet-50 对比举例来说,SE-ResNet-50 相对于 ResNet-50 有着 10% 模型参数的增长。额外的模型参数都存在于 Bottleneck 设计的两个 Fully Connected 中,由于 ResNet 结构中最后一个 stage 的特征通道数目为 2048,导致模型参数有着较大的增长,实验发现移除掉最后一个 stage 中 3 个 build block 上的 SE 设定,可以将 10% 参数量的增长减少到 2%。此时模型的精度几乎无损失。
另外,由于在现有的 GPU 实现中,都没有对 global pooling 和较小计算量的 Fully Connected 进行优化,这导致了在 GPU 上的运行时间 SE-ResNet-50 相对于 ResNet-50 有着约 10% 的增长。尽管如此,其理论增长的额外计算量仅仅不到 1%,这与其在 CPU 运行时间上的增长相匹配(~2%)。可以看出,在现有网络架构中嵌入 SE 模块而导致额外的参数和计算量的增长微乎其微。

在训练中,我们使用了一些常见的数据增强方法和 Li Shen 提出的均衡数据策略。为了提高训练效率,我们使用了我们自己优化的分布式训练系统 ROCS, 并采用了更大的 batch-size 和初始学习率。所有的模型都是从头开始训练的。

接下来,为了验证 SENets 的有效性,我们将在 ImageNet 数据集上进行实验,并从两个方面来进行论证。一个是性能的增益 vs. 网络的深度; 另一个是将 SE 嵌入到现有的不同网络中进行结果对比。另外,我们也会展示在 ImageNet 竞赛中的结果。
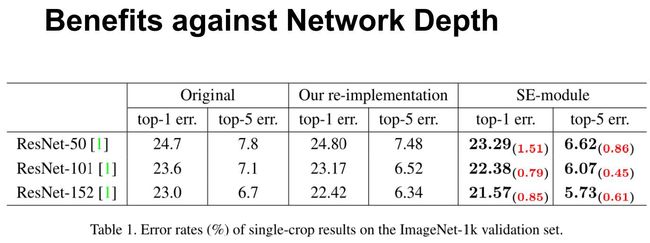
首先我们来看一下网络的深度对 SE 的影响。上表分别展示了 ResNet-50、ResNet-101、ResNet-152 和嵌入 SE 模型的结果。第一栏 Original 是原作者实现的结果,为了进行公平的比较,我们在 ROCS 上重新进行了实验得到 Our re-implementation 的结果(ps. 我们重实现的精度往往比原 paper 中要高一些)。最后一栏 SE-module 是指嵌入了 SE 模块的结果,它的训练参数和第二栏 Our re-implementation 一致。括号中的红色数值是指相对于 Our re-implementation 的精度提升的幅值。
从上表可以看出,SE-ResNets 在各种深度上都远远超过了其对应的没有 SE 的结构版本的精度,这说明无论网络的深度如何,SE 模块都能够给网络带来性能上的增益。值得一提的是,SE-ResNet-50 可以达到和 ResNet-101 一样的精度;更甚,SE-ResNet-101 远远地超过了更深的 ResNet-152。

上图展示了 ResNet-50 和 ResNet-152 以及它们对应的嵌入 SE 模块的网络在 ImageNet 上的训练过程,可以明显地看出加入了 SE 模块的网络收敛到更低的错误率上。
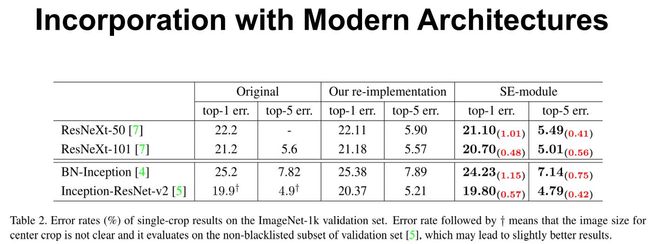
另外,为了验证 SE 模块的泛化能力,我们也在除 ResNet 以外的结构上进行了实验。从上表可以看出,将 SE 模块嵌入到 ResNeXt、BN-Inception、Inception-ResNet-v2 上均获得了不菲的增益效果。由此看出,SE 的增益效果不仅仅局限于某些特殊的网络结构,它具有很强的泛化性。
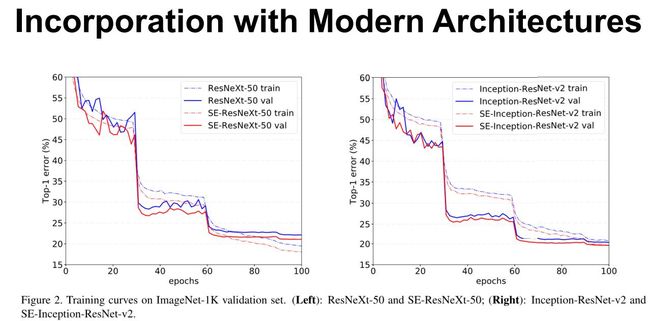
上图展示的是 SE 嵌入在 ResNeXt-50 和 Inception-ResNet-v2 的训练过程对比。
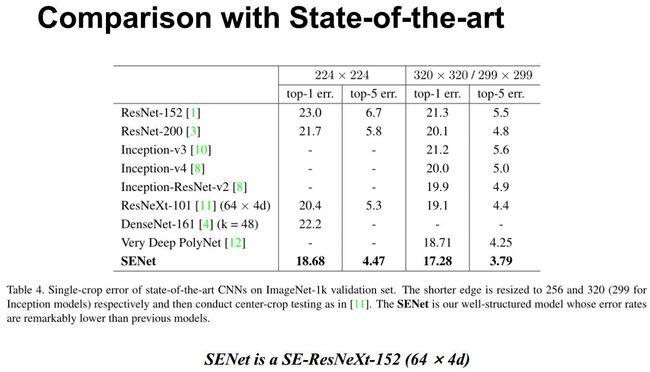
在上表中我们列出了一些最新的在 ImageNet 分类上的网络的结果。其中我们的 SENet 实质上是一个 SE-ResNeXt-152(64x4d),在 ResNeXt-152 上嵌入 SE 模块,并做了一些其他修改和训练优化上的小技巧,这些我们会在后续公开的论文中进行详细介绍。可以看出 SENet 获得了迄今为止在 single-crop 上最好的性能。
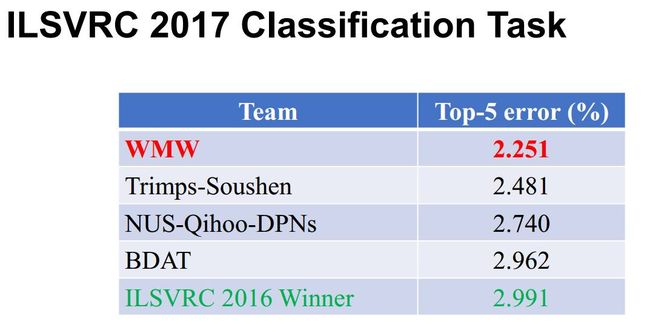
最后,在 ILSVRC 2017 竞赛中,我们的融合模型在测试集上获得了 2.251% Top-5 错误率。对比于去年第一名的结果 2.991%, 我们获得了将近 25% 的精度提升。
更多技术上和实验上的细节将会展示在即将公开的论文中。