编程基础(四)——cache之一
目录
一、概述
二、原理
2.1 局部性原理(principle of locality)
2.2 Memory Hierarchy
2.3 性能评估
三、cache的基本要素
3.1 cache的组成
3.1.1 利用hash表理解cache参数和行为
3.2 cache的分类
3.3 cacheline size
3.4 cache hit & cache miss
3.5 replacement policy
3.6 write policy
3.7 split caches & unified caches
3.8 多级cache管理策略
四、cache coherency
4.1 cache coherency protocal
4.2 store buffer & store forwarding
五、参考
一、概述
本文主要是对缓存知识的梳理,备忘。
二、原理
2.1 局部性原理(principle of locality)
- Temporal if data is accessed, likely to be accessed again soon
- Spatial if data is accessed, likely to access nearby data
2.2 Memory Hierarchy
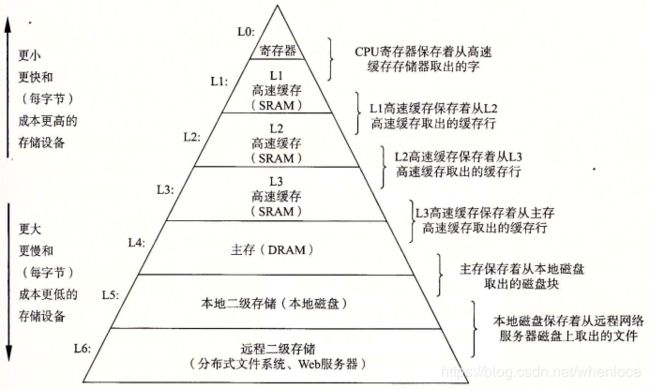
2.3 性能评估
- AMAT = hit time + miss rate * penalty
三、cache的基本要素
3.1 cache的组成
一个典型的cache如下图所示:

- 一个cache有2^(bits of index) set,每个set包括n个(n-ways) cacheline,每个cacheline 由 tag,data和一些标记位组成,。
- 一个cache 查找的过程使用地址中的index匹配set,在set中使用地址中的tag匹配cacheline,如果找到,称为cache hit,最后使用地址中的offset在cacheline中的相应偏移处取出数据
3.1.1 利用hash表理解cache参数和行为
可以把cache理解成软件上的hash表:

- s个slot, 使用链(set)解决冲突的hash结构,每个链有n个cacheline
- 利用hash_func定位hash slot:这里使用index来定位set
- 利用链表解决冲突:利用地址的中tag和set中每一个cacheline进行匹配
- 一般的,status bit 中比较重要的有V(valid)标识该cacheline是否有效,D(Dirty)标识该cacheline是否被修改过
3.2 cache的分类
在3.1 中,如果每个set只有一个cacheline,类比于hash冲突链最多允许有一个cacheline,称为直接相连(direct-mapped) cache,如果只有一个set,类比于只有一个hash slot,称为全相连(fully-associative) cache, 最后一种情况如上面图中显示的那样,称为n路组相连(n-way set-associative) cache
如我们有如下cpu 的缓存规格:
L1 Data cache = 32 KB, 64 B/line, 8-WAY. (https://www.7-cpu.com/cpu/Broadwell.html)
那么可以知道整个L1 data cache的大小:32K,每个set 8个cacheline,每个cacheline储存64Bytes数据,那么set大小就是32K/8/64=64,从而知道地址中index和offset都是log2(64) = 8bit
3.3 cacheline size
cache需要和位于下级的更大且更慢的存储交换数据(每次交换大小是一个cacheline,称为block),cacheline size的大小需要考量,如果很小,假如一个word大小,那么cacheline的metadata开销很高(tag & status),而且不能利用空间局部性。另一方面,cache和其下一级之间传递数据的速度相比访问cache的速率来说,每次传递很少的数据很低效。cacheline也不会太大,一般4-8 words。
3.4 cache hit & cache miss
如果在cacheline中通过tag匹配到数据,称为cache hit,否则称为cache miss,由于cache hit和cache miss都可以由读写触发,组合起来可以有四种:
- read hit
- read miss
- write hit
- write miss
cache miss种类有以下几种:
- compulsory (code) miss 首次访问
- conflict miss 和其他缓存表项冲突了
- capacity miss 缓存没有空间存放
- communication miss
3.5 replacement policy
当出现cache miss时,需要有一定的策略将victim entry替换。
- FIFO
- LRU
- Round-robin
- Random
- Pseudo-LRU
- Spatial
说明一下LRU,先看一张图:
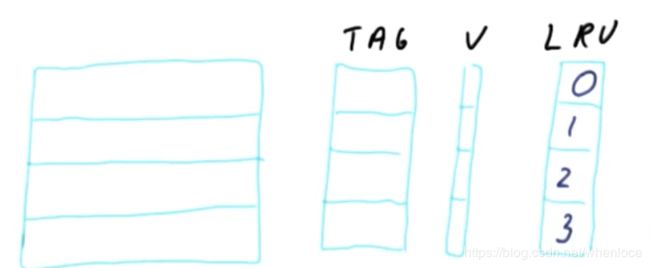
上述是一个set的示意,为了实现LRU,每个cacheline对应一个LRU counter,LRU counter中记录了cacheline的访问情况(假设从0-3,每个counter的值都不一样,3到0表示访问热度依次降低),当一个cacheline被访问,其热度(LRU counter bit)变为3,其余counter热度依次减一(如果已经是0了,仍保持0),当需要替换时,选择热度最低的0并kick out。
3.6 write policy
write miss
- write allocate 先把要写的数据载入到cache中,再写cache。
- no write allocate 直接把要写的数据写入到内存中
write hit
- write through 直写,将内容直接通过memory controller写到内存中,遵循严格的cache和memory的一致性,写入memory耗时,如果频繁的写入可能会导致性能瓶颈
- write back 写回,解决write through的方法,只写对应的cache,将cacheline的dirty标记置位,该行由于缓存替换策略被换出或者被刷新的时候,写回内存,这种方法会引起cache和memory数据的不一致,需要软件和OS方面的关注
对一个write back类型的cache来说,如果cache的内容被修改,需要在cache replacement的时候将cache内容写到内存上,这时候需要引入dirty bit。write back和write allocate设计上经常搭配使用。
3.7 split caches & unified caches
不同功能和cache可以组织在一起,称为unified caches,也可以互相分离,称为split caches,split cache可以提升系统的性能,如当前CPU中都有icache和dcache,以简单的五级流水线为例来解释,在IF和MEM阶段都会访问内存,如果是unified cache,会引起流水线结构冒险,造成流水线stall,将cache分离可以消除该冒险,从而提高流水线的效率
split cache也会造成问题,TODO
3.8 多级cache管理策略
- inclusive:every item in L1 also in L2 simple, but wastes cache space (multiple copies)
- exclusive:item cannot be in multiple levels at a time
exclusive方式可以存储更多数据。当然如果L2大大超过L1的大小,则这个优势也并不是很大了。exclusive要求如果L1 miss L2 hit,则需要把L2 hit的line和L1中的一条line交换。这就比inclusive直接从L2拷贝hit line到L1中的方式多些工作。
inclusive 方式的一个优点是,当外部设备或者处理器想要从处理器里删掉一条cache line时,处理器只需要检查下L2 cache即可。
inclusive 方式的另外一个优点是,越大的cache可以使用越大的cache line,这可能减小二级cache tags的大小。而Exclusive需要L1和L2的cache line大小相同,以便进行替换。如果二级cahce是远远大于一级cache,并且cache data部分远远大于tag,省下的tag部分可以存放数据。inclusive一个缺点是L2中被替换的line,如果L1中有映射,也需要从L1中替换出去,这可能会导致L1的高miss率。
四、cache coherency
4.1 cache coherency protocal
以MESI为例,按照我的理解:

- read/read response
- invalidate/ invalidate ack
- read invalidate/read response & invalidate ack
- write back
上面的图中,可以将M,E看作一个整体,他们的行为大体是一致的,当有write的动作时,状态会指向M/E
其中I->S发read,S->M/E 发invalidate(当然I->M/E 发read invalidate了,途中没有标出),返回也是一样,M->S 收到rcv read时转移,S->I rcv invalidate时转移
M/E的细微差别在于,如果不通过E状态直接转为M状态,是在atomic RMW下产生的。
4.2 store buffer & store forwarding
由于缓存一致性协议是通过消息来传递的,消息传递无法避免延迟,会造成cpu stall:
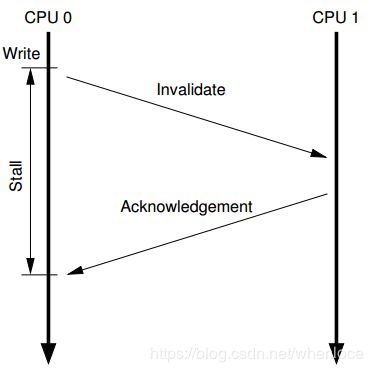
解决的方法时在cpu和cache之间添加store buffer,cpu可以不关注消息是否返回而直接写入,而这种方法也会引入问题
a = 1;
b = a + 1
可以看到,两条语句时指令相关的,但假如执行a = 1时发生cache miss,发送read invalide同时将1写到store buffer中,其他cpu通过read resp将cpu0的cacheline置为0,这时候执行b=a+1,取出cache中a的值(此时store buffer中改变的a的值还没有flush到对用的cache中)
五、参考
【1】A_survey_on_the_interaction_between_caching_transl.pdf