Gitlab CI/CD自动化部署的实现 (二)
此篇博客大多以官方文档翻译得来:通过 .gitlab-ci.yml配置CI/CD任务
相信熟悉dockerfile和ansible的应该对这个熟悉很快!
此文档用于描述.gitlab-ci.yml语法,.gitlab-ci.yml文件被用来管理项目的runner 任务。
.gitlab-ci.yml 从7.12版本开始,GitLab CI使用YAML文件(.gitlab-ci.yml)来管理项目配置。该文件存放于项目仓库的根目录,它定义该项目如何构建。
开始构建之前YAML文件定义了一系列带有约束说明的任务。这些任务都是以任务名开始并且至少要包含script部分:
job1:
script: "execute-script-for-job1"
job2:
script: "execute-script-for-job2"
上面这个例子就是一个最简单且带有两个独立任务的CI配置,每个任务分别执行不同的命令。
script可以直接执行系统命令(例如:./configure;make;make install)或者是直接执行脚本(test.sh)。
任务是由Runners接管并且由服务器中runner执行。更重要的是,每一个任务的执行过程都是独立运行的。
用下面这个例子来说明YAML语法还有更多复杂的任务:
image: ruby:2.1
services:
- postgres
before_script:
- bundle install
after_script:
- rm secrets
stages:
- build
- test
- deploy
job1:
stage: build
script:
- execute-script-for-job1
only:
- master
tags:
- docker
下面列出保留字段,这些保留字段不能被定义为job名称:
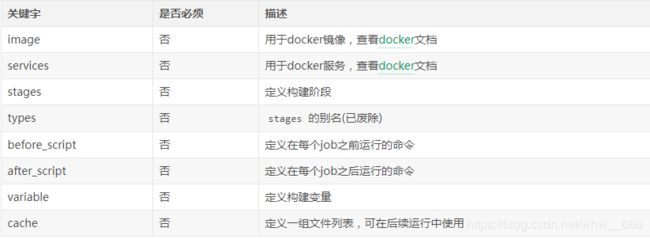
image和services
这两个关键字允许使用一个自定义的Docker镜像和一系列的服务,并且可以用于整个job周期。详细配置文档请查看a separate document。
before_script
before_script用来定义所有job之前运行的命令,包括deploy(部署) jobs,但是在修复artifacts之后。它可以是一个数组或者是多行字符串。
after_script
GitLab 8.7 开始引入,并且要求Gitlab Runner v1.2
after_script用来定义所有job之后运行的命令。它必须是一个数组或者是多行字符串
stages
stages用来定义可以被job调用的stages。stages的规范允许有灵活的多级pipelines。
stages中的元素顺序决定了对应job的执行顺序:
1. 相同stage的job可以平行执行。
2. 下一个stage的job会在前一个stage的job成功后开始执行。
接下仔细看看这个例子,它包含了3个stage:
stages:
- build
- test
- deploy
首先,所有build的jobs都是并行执行的。
所有build的jobs执行成功后,test的jobs才会开始并行执行。
所有test的jobs执行成功,deploy的jobs才会开始并行执行。
所有的deploy的jobs执行成功,commit才会标记为success
任何一个前置的jobs失败了,commit会标记为failed并且下一个stages的jobs都不会执行。
这有两个特殊的例子值得一提:
如果.gitlab-ci.yml中没有定义stages,那么job's stages 会默认定义为 build,test 和 deploy。
如果一个job没有指定stage,那么这个任务会分配到test stage。
types
已废除,将会在10.0中移除。用stages替代。
与stages同义
variables
GitLab Runner V0.5.0. 开始引入
GItLab CI 允许在.gitlab-ci.yml文件中添加变量,并在job环境中起作用。因为这些配置是存储在git仓库中,所以最好是存储项目的非敏感配置,例如:
variables:
DATABASE_URL:"postgres://postgres@postgres/my_database"
这些变量可以被后续的命令和脚本使用。服务容器也可以使用YAML中定义的变量,因此我们可以很好的调控服务容器。变量也可以定义成job level。
除了用户自定义的变量外,Runner也可以定义它自己的变量。CI_COMMIT_REG_NAME就是一个很好的例子,它的值表示用于构建项目的分支或tag名称。除了在.gitlab-ci.yml中设置变量外,还有可以通过GitLab的界面上设置私有变量。
更多关于variables。
cache
Gitlab Runner v0.7.0 开始引入。
cache用来指定需要在job之间缓存的文件或目录。只能使用该项目工作空间内的路径。
从GitLab 9.0开始,pipelines和job就默认开启了缓存
如果cache定义在jobs的作用域之外,那么它就是全局缓存,所有jobs都可以使用该缓存。
缓存binaries和.config中的所有文件:
rspec:
script: test
cache:
paths:
- binaries/
- .config
缓存git中没有被跟踪的文件:
rspec:
script: test
cache:
untracked: true
缓存binaries下没有被git跟踪的文件:
rspec:
script: test
cache:
untracked: true
paths:
- binaries/
job中优先级高于全局的。下面这个rspecjob中将只会缓存binaries/下的文件:
cache:
paths:
- my/files
rspec:
script: test
cache:
key: rspec
paths:
- binaries/
注意,缓存是在jobs之前进行共享的。如果你不同的jobs缓存不同的文件路径,必须设置不同的cache:key,否则缓存内容将被重写。
缓存只是尽力而为之,所以别期望缓存会一直存在。查看更多详细内容,请查阅GitLab Runner。
缓存key
GitLab Runner v1.0.0 开始引入。
key指令允许我们定义缓存的作用域(亲和性),可以是所有jobs的单个缓存,也可以是每个job,也可以是每个分支或者是任何你认为合适的地方。
它也可以让你很好的调整缓存,允许你设置不同jobs的缓存,甚至是不同分支的缓存。
cache:key可以使用任何的预定义变量。
默认key是默认设置的这个项目缓存,因此默认情况下,每个pipelines和jobs中可以共享一切,从GitLab 9.0开始。
配置示例
缓存每个job:
cache:
key: "$CI_JOB_NAME"
untracked: true
缓存每个分支:
cache:
key: "$CI_COMMIT_REF_NAME"
untracked: true
缓存每个job且每个分支:
cache:
key: "$CI_JOB_NAME/$CI_COMMIT_REF_NAME"
untracked: true
缓存每个分支且每个stage:
cache:
key: "$CI_JOB_STAGE/$CI_COMMIT_REF_NAME"
untracked: true
如果使用的Windows Batch(windows批处理)来跑脚本需要用%替代$:
cache:
key: "%CI_JOB_STAGE%/%CI_COMMIT_REF_NAME%"
untracked: true
Jobs
.gitlab-ci.yml允许指定无限量jobs。每个jobs必须有一个唯一的名字,而且不能是上面提到的关键字。job由一列参数来定义jobs的行为。
job_name:
script:
- rake spec
- coverage
stage: test
only:
- master
except:
- develop
tags:
- ruby
- postgres
allow_failure: true
script
script是Runner执行的yaml脚本。举个例子:
job:
script: "bundle exec rspec"
该参数也可以用数组包含多个命令:
job:
script:
- uname -a
- bundle exec rspec
有时候,script命令需要被单引号或者是双引号包裹起来。举个例子,当命令中包含冒号(:)时,script需要被包在双引号中,这样YAML解析器才可以正确解析为一个字符串而不是一个键值对(key:value)。使用这些特殊字符的时候一定要注意::,{,},[,],,,&,*,#,?,|,-,<,>,=,!。
stage
stage允许一组jobs进入不同的stages。jobs在相同的stage时会parallel同时进行。查阅stages更多的用法请查看stages。
only and except
only和except是两个参数用分支策略来限制jobs构建:
only定义哪些分支和标签的git项目将会被job执行。
except定义哪些分支和标签的git项目将不会被job执行。
下面是refs策略的使用规则:
only和except可同时使用。如果only和except在一个job配置中同时存在,则以only为准,跳过except(从下面示例中得出)。
only和except可以使用正则表达式。
only和except允许使用特殊的关键字:branches,tags和triggers。
only和except允许使用指定仓库地址但不是forks的仓库(查看示例3)。
在下面这个例子中,job将只会运行以issue-开始的refs(分支),然而except中设置将被跳过。
job:
# use regexp
only:
- /^issue-.*$/
# use special keyword
except:
- branches
在下面这个例子中,job将只会执行有tags的refs,或者通过API触发器明确地请求构建。
job:
# use special keywords
only:
- tags
- triggers
仓库路径只能用于父级仓库执行jobs,而不是forks:
job:
only:
- branches@gitlab-org/gitlab-ce
except:
- master@gitlab-org/gitlab-ce
上面这个例子将会为所有的分支执行job,但master分支除外。
Job variables
在job中是可以使用关键字variables来定义job变量。它的运行原理跟global-level是一样的,但是它允许设置特殊的job变量。
当设置了job级别的关键字variables,它会覆盖全局YAML和预定义中的job变量。想要关闭全局变量可以在job中设置一个空数组:
job_name:
variables: []
Job变量的优先级关系可查看variables文档说明。
tags
tags可以从允许运行此项目的所有Runners中选择特定的Runners来执行jobs。
在注册Runner的过程中,我们可以设置Runner的标签,比如ruby,postgres,development。
tags可通过tags来指定特殊的Runners来运行jobs:
job:
tags:
- ruby
- postgres
上面这个示例中,需要确保构建此job的Runner必须定义了ruby和postgres这两个tags。
allow_failure
allow_failure可以用于当你想设置一个job失败的之后并不影响后续的CI组件的时候。失败的jobs不会影响到commit状态。
当开启了允许job失败,所有的intents和purposes里的pipeline都是成功/绿色,但是也会有一个"CI build passed with warnings"信息显示在merge request或commit或job page。这被允许失败的作业使用,但是如果失败表示其他地方应采取其他(手动)步骤。
下面的这个例子中,job1和job2将会并列进行,如果job1失败了,它也不会影响进行中的下一个stage,因为这里有设置了allow_failure: true。
job1:
stage: test
script:
- execute_script_that_will_fail
allow_failure: true
job2:
stage: test
script:
- execute_script_that_will_succeed
job3:
stage: deploy
script:
- deploy_to_staging
when
when is used to implement jobs that are run in case of failure or despite the failure.
when可以设置以下值:
on_success - 只有前面stages的所有工作成功时才执行。 这是默认值。
on_failure - 当前面stages中任意一个jobs失败后执行。
always - 无论前面stages中jobs状态如何都执行。
`manual ` - 手动执行(GitLab8.10增加)。更多请查看手动操作。
举个例子:
stages:
- build
- cleanup_build
- test
- deploy
- cleanup
build_job:
stage: build
script:
- make build
cleanup_build_job:
stage: cleanup_build
script:
- cleanup build when failed
when: on_failure
test_job:
stage: test
script:
- make test
deploy_job:
stage: deploy
script:
- make deploy
when: manual
cleanup_job:
stage: cleanup
script:
- cleanup after jobs
when: always
脚本说明:
只有当build_job失败的时候才会执行`cleanup_build_job 。
不管前一个job执行失败还是成功都会执行`cleanup_job 。
可以从GitLab界面中手动执行deploy_jobs。
Manual actions
GitLab 8.10 开始引入手动执行。GitLab 9.0 开始引入手动停止。GitLab 9.2 开始引入保护手动操作。
手动操作指令是不自动执行的特殊类型的job;它们必须要人为启动。手动操作指令可以从pipeline,build,environment和deployment视图中启动。
部署到生产环境是手动操作指令的一个很好示例。
了解更多请查看environments documentation。
手动操作指令可以是可选的或阻塞。在定义了手动执行的那个stage中,手动操作指令将会停止pipline中的自动执行指令。当有人通过点击play按钮来执行需要手动执行的job时,可以来恢复pipeline的执行。
当pipeline被阻塞时,即使是pipeline是成功状态也不会merge。被阻塞的pipelines也有一个特殊的状态,叫manual。
手动操作指令默认是不阻塞的。如果你想要手动操作指令产生阻塞,首先需要在job的配置文件.gitlab-ci.yml中添加allow_failure:false。
可选的手动操作指令默认设置allow_failure:true。
可选动作的状态不影响整个pipeline的状态。
手动操作指令被认为是写操作,所以当前用户触发操作时,必须拥有操作保护分支的权限。换句话说,为了触发一个手动操作指令到pipeline中正在运行的指定分支,当前用户必须拥有推送到这分支的权限。
enviroment
注意:
GitLab 8.9 开始引入。
更多关于environment说明或者示例可以查看 documentation about environments。
environment用于定义job部署到特殊的环境中。如果指定了environment,并且没有该名称下的环境,则会自动创建新环境。
在最简单的格式中,环境关键字可以定义为:
deploy to production:
stage: deploy
script: git push production HEAD:master
environment:
name: production
在上面这个例子中,deploy to profuctionjob将会执行部署到production环境的操作。
environment:name
注意
GitLab 8.11 开始引入。
在GitLab8.11之前,环境名称定义为environment:production。现在推荐的做法是定义为name关键字。
environment名称可以包含:
英文字母(letters)
数字(digits)
空格(spaces)
-
_
/
$
{
}
常用的名称有qa,staging,和production,当然你可以在你的工作流中使用任意名字。
除了在environment关键字右边紧跟name定义方法外,也是可以为环境名称单独设定一个值。例如,用name关键字在environment下面设置:
deploy to production:
stage: deploy
script: git push production HEAD:master
environment:
name: production
environment:url
注意:
GitLab 8.11 开始引用。
在GitLab 8.11之前,URL只能在GitLab's UI中添加。现在推荐的定义方法是在.gitlab-ci.yml。
这是设置一个可选值,它会显示在按钮中,点击它可以带你到设置的URL页面。
在下面这个例子中,如果job都成功完成了,在environment/deployments页面中将会创建一个合并请求的按钮,它将指向https://prod.example.com。
deploy to production:
stage: deploy
script: git push production HEAD:master
environment:
name: production
url: https://prod.example.com
environment:on_stop
注意:
GitLab 8.13中开始引入。
从GitLab 8.14开始,当在environment中定义了一个stop操作,GitLab将会在相关联的分支本删除时自动触发一个stop操作。
关闭(停止)environments可以通过在environment下定义关键字on_stop来实现。它定义了一个不同的job,用于关闭environment。
请查看environment:action模块中例子。
environment:action
Gitlab 8.13 开始引入。
action和on_stop联合使用,定义在job中,用来关闭environment。
举个例子:
review_app:
stage: deploy
script: make deploy-app
environment:
name: review
on_stop: stop_review_app
stop_review_app:
stage: deploy
script: make delete-app
when: manual
environment:
name: review
action: stop
上面这个例子中,我们定义了review_appjob来部署到review环境中,同时我们也定义了一个新stop_review_appjob在on_stop中。一旦review_appjob执行完成并且成功,它将触发定义在when中的stop_review_appjob。在这种情况下,我们设置为manual,需要通过GitLab's web界面来允许manual action。
stop_review_appjob需要定义下面这些关键字:
when - 说明
environment:name
environment:action
stage需要和review_app相同,以便分支删除被删除的时候自动执行停止。
dynamic environment
注意:
GitLab 8.12开始引入,并且要求GitLab Runner 1.6 。
GitLab 8.15开始引入$CI_ENVIRONMENT_SLUG。
environment也可以是代表配置项,其中包含name和url。这些参数可以使用任何的CI variables(包括预定义、安全变量和.gitlab-ci.yml中的变量)。
举个例子:
deploy as review app:
stage: deploy
script: make deploy
environment:
name: review/$CI_COMMIT_REF_NAME
url: https://$CI_ENVIRONMENT_SLUG.example.com/
当$CI_COMMIT_REF_NAME 被Runner设置为environment variable时,deply as review appjob将会被指定部署到动态创建revuew/$CI_COMMIT_REF_NAME的环境中。$CI_ENVIRONMENT_SLUG变量是基于环境名称的,最终组合成完整的URLs。在这种情况下,如果deploy as review appjob是运行在名称为pow的分支下,那么可以通过URLhttps"//review-pw.example.com/来访问这个环境。
这当然意味着托管应用程序的底层服务器已经正确配置。
常见的做法是为分支创建动态环境,并讲它们作为Review Apps。可以通过https://gitlab.com/gitlab-exa...上查看使用Review Apps的简单示例。
artifacts
注意:
非Windows平台从GitLab Runner v0.7.0中引入。
Windows平台从GitLab Runner V1.0.0中引入。
在GItLab 9.2之前,在artifacts之后存储缓存。
在GItLab 9.2之后,在artifacts之前存储缓存。
目前并不是所有的executors都支持。
默认情况下,job artifacts 只正对成功的jobs收集。
artifacts用于指定成功后应附加到job的文件和目录的列表。只能使用项目工作间内的文件或目录路径。如果想要在不通的job之间传递artifacts,请查阅依赖关系。以下是一些例子:
发送binaries和.config中的所有文件:
artifacts:
paths:
- binaries/
- .config
发送所有没有被Git跟踪的文件:
artifacts:
untracked: true
发送没有被Git跟踪和binaries中的所有文件:
artifacts:
untracked: true
paths:
- binaries/
定义一个空的dependencies可以禁用artifact传递:
job:
stage: build
script: make build
dependencies: []
有时候只需要为标签为releases创建artifacts,以避免将临时构建的artifacts传递到生产服务器中。
只为tags创建artifacts(default-job将不会创建artifacts):
default-job:
script:
- mvn test -U
except:
- tags
release-job:
script:
- mvn package -U
artifacts:
paths:
- target/*.war
only:
- tags
在job成功完成后artifacts将会发送到GitLab中,同时也会在GitLab UI中提供下载。
artifacts:name
GitLab 8.6 和 Runner v1.1.0 引入。
name允许定义创建的artifacts存档的名称。这样一来,我们可以为每个存档提供一个唯一的名称,当需要从GitLab中下载是才不会混乱。artifacts:name可以使用任何的预定义变量(predefined variables)。它的默认名称为artifacts,当下载是就变成了artifacts.zip。
配置示例
通过使用当前job的名字作为存档名称:
job:
artifacts:
name: "$CI_JOB_NAME"
使用当前分支名称或者是tag作为存到名称,只存档没有被Git跟踪的文件:
job:
artifacts:
name: "$CI_COMMIT_REF_NAME"
untracked: true
使用当前job名称和当前分支名称或者是tag作为存档名称,只存档没有被Git跟踪的文件:
job:
artifacts:
name: "${CI_JOB_NAME}_${CI_COMMIT_REF_NAME}"
untracked: true
使用当前stage和分支名称作为存档名称:
job:
artifacts:
name: "${CI_JOB_STAGE}_${CI_COMMIT_REF_NAME}"
untracked: true
如果是使用Windows批处理来运行yaml脚本,需要用%替换$:
job:
artifacts:
name: "%CI_JOB_STAGE%_%CI_COMMIT_REF_NAME%"
untracked: true
artifacts:when
GitLab 8.9和GitLab Runner v1.3.0 引入。
在job失败的时候,artifacts:when用来上传artifacts或者忽略失败。
artifacts:when可以设置一下值:
on_success - 当job成功的时候上传artifacts。默认值。
on_failure - 当job失败的时候上传artifacts。
always - 不论job失败还是成功都上传artifacts。
示例配置
只在job失败的时候上传artifacts。
job:
artifacts:
when: on_failure
artifacts:expire_in
GitLab 8.9 和 GitLab Runner v1.3.0 引入。
artifacts:expire_in用于过期后删除邮件上传的artifacts。默认情况下,artifacts都是在GitLab中永久保存。expire_in允许设置设置artifacts的存储时间,从它们被上传存储到GitLab开始计算。
可以通过job页面的Keep来修改有效期。
过期后,artifacts会被通过一个默认每小时执行一次的定时job删除,所以在过期后无法访问artifacts。
expire_in是一个时间区间。下面可设置的值:
'3 mins 4 sec'
'2 hrs 20 min'
'2h20min'
'6 mos 1 day'
'47 yrs 6 mos and 4d'
'3 weeks and 2 days'
示例配置
设置artifacts的有效期为一个星期:
job:
artifacts:
expire_in: 1 week
dependencies
GitLab 8.6 和 GitLab RUnner v1.1.1引入。
这个功能应该与artifacts一起使用,并允许定义在不同jobs之间传递artifacts。
注意:所有之前的stages都是默认设置通过。
如果要使用此功能,应该在上下文的job中定义dependencies,并且列出之前都已经通过的jobs和可下载的artifacts。你只能在当前执行的stages前定义jobs。你如果在当前stages或者后续的stages中定义了jobs,它将会报错。可以通过定义一个空数组是当前job跳过下载artifacts。
在接下来的例子中,我们定义两个带artifacts的jobs,build:osx和build:linux。当test:osx开始执行的时候,build:osx的artifacts就会开始下载并且会在build的stages下执行。同样的会发生在test:linux,从build:linux中下载artifacts。
因为stages的优先级关系,deployjob将会下载之前jobs的所有artifacts:
build:osx:
stage: build
script: make build:osx
artifacts:
paths:
- binaries/
build:linux:
stage: build
script: make build:linux
artifacts:
paths:
- binaries/
test:osx:
stage: test
script: make test:osx
dependencies:
- build:osx
test:linux:
stage: test
script: make test:linux
dependencies:
- build:linux
deploy:
stage: deploy
script: make deploy
before_script 和 after_script
它可能会覆盖全局定义的before_script和after_script:
before_script:
- global before script
job:
before_script:
- execute this instead of global before script
script:
- my command
after_script:
- execute this after my scriptcoverage
注意:
GitLab 8.17 引入。
coverage允许你配置代码覆盖率将会从该job中提取输出。
在这里正则表达式是唯一有效的值。因此,字符串的前后必须使用/包含来表明一个正确的正则表达式规则。特殊字符串需要转义。
一个简单的例子:
job1:
coverage: '/Code coverage: \d+\.\d+/'
Git Strategy
GitLab 8.9中以试验性功能引入。将来的版本中可能改变或完全移除。GIT_STRATEGY要求GitLab Runner v1.7+。
你可以通过设置GIT_STRATEGY用于获取最新的代码,可以再全局variables或者是在单个job的variables模块中设置。如果没有设置,将从项目中使用默认值。
可以设置的值有:clone,fetch,和none。
clone是最慢的选项。它会从头开始克隆整个仓库,包含每一个job,以确保项目工作区是最原始的。

GIT_STRATEGY: clone
当它重新使用项目工作区是,fetch是更快(如果不存在则返回克隆)。git clean用于撤销上一个job做的任何改变,git fetch用于获取上一个job到现在的的commit。
variables:
GIT_STRATEGY: fetch
none也是重新使用项目工作区,但是它会跳过所有的Git操作(包括GitLab Runner前的克隆脚本,如果存在的话)。它主要用在操作job的artifacts(例如:deploy)。Git数据仓库肯定是存在的,但是他肯定不是最新的,所以你只能依赖于从项目工作区的缓存或者是artifacts带来的文件。
variables:
GIT_STRATEGY: none
Git Checout
GitLab Runner 9.3 引入。
当GIT_STRATEGY设置为clone或fetch时,可以使用GIT_CHECKOUT变量来指定是否应该运行git checkout。如果没有指定,它默认为true。就像GIT_STRATEGY一样,它可以设置在全局variables或者是单个job的variables中设置。
如果设置为false,Runner就会:
fetch - 更新仓库并在当前版本中保留工作副本,
clone - 克隆仓库并在默认分支中保留工作副本。
Having this setting set to true will mean that for both clone and fetch strategies the Runner will checkout the working copy to a revision related to the CI pipeline:
【如果设置这个为true将意味着clone和fetch策略都会让Runner执行项目工作区更新到最新:】
variables:
GIT_STRATEGY: clone
GIT_CHECKOUT: false
script:
- git checkout master
- git merge $CI_BUILD_REF_NAME
需要GitLab Runner v1.10+。
GIT_SUBMODULE_STRATEGY变量用于在构建之前拉取代码时,Git子模块是否或者如何被引入。就像GIT_STRATEGY一样,它可在全局variables或者是单个job的variables模块中设置。
它的可用值有:none,normal和recursive:
none意味着在拉取项目代码时,子模块将不会被引入。这个是默认值,与v1.10之前相同的。
normal意味着在只有顶级子模块会被引入。它相当于:
git submodule sync
git submodule update --init
recursive意味着所有的子模块(包括子模块的子模块)都会被引入,他相当于:
git submodule sync --recursive
git submodule update --init --recursive
注意:如果想要此功能正常工作,子模块必须配置(在.gitmodules)下面中任意一个:
可访问的公共仓库http(s)地址,
在同一个GitLab服务器上有一个可访问到另外的仓库的真实地址。更多查看Git 子模块文档。
Job stages attempts
GitLab引入,要求GItLab Runner v1.9+。
正在执行的job将会按照你设置尝试次数依次执行下面的stages:

默认是一次尝试。
例如:
variables:
GET_SOURCES_ATTEMPTS: 3
你可以在全局variables模块中设置,也可以在单个job的variables模块中设置。
Shallow cloning
GitLab 8.9 以实验性功能引入。在将来的版本中有可能改变或者完全移除。
你可以通过GIT_DEPTH来指定抓取或克隆的深度。它可浅层的克隆仓库,这可以显著加速具有大量提交和旧的大型二进制文件的仓库的克隆。这个设置的值会传递给git fetch和git clone。
注意:如果设置depth=1,并且有一个jobs队列或者是重试jobs,则jobs可能会失败。
由于Git抓取和克隆是基于一个REF,例如分支的名称,所以Runner不能指定克隆一个commit SHA。如果队列中有多个jobs,或者您正在重试旧的job,则需要测试的提交应该在克隆的Git历史记录中存在。设置GIT_DEPTH太小的值可能会导致无法运行哪些旧的commits。在job日志中可以查看unresolved reference。你应该考虑设置GIT_DEPTH为一个更大的值。
当GIT_DEPTH只设置了部分存在的记录时,哪些依赖于git describe的jobs也许不能正确的工作。
只抓取或克隆最后的3次commits:
variables:
GIT_DEPTH: "3"
Hidden keys
GitLab 8.6 和 GitLab Runner v1.1.1引入。
Key 是以.开始的,GitLab CI 将不会处理它。你可以使用这个功能来忽略jobs,或者用Special YAML features 转换隐藏键为模版。
在下面这个例子中,.key_name将会被忽略:
.key_name:
script:
- rake spec
Hidden keys 可以是像普通CI jobs一样的哈希值,但你也可以利用special YAMLfeatures来使用不同类型的结构。
Special YAML features
使用special YAML features 像anchors(&),aliases(*)和map merging(<<),这将使您可以大大降低.gitlab-ci.yml的复杂性。
查看更多YAML features。
Anchors
GitLab 8.6 和 GitLab Runner v1.1.1引入。
YAML有个方便的功能称为"锚",它可以让你轻松的在文档中复制内容。Anchors可用于复制/继承属性,并且是使用hidden keys来提供模版的完美示例。
下面这个例子使用了anchors和map merging。它将会创建两个jobs,test1和test2,该jobs将集成.job_template的参数,每个job都自定义脚本:
.job_template: &job_definition # Hidden key that defines an anchor named 'job_definition'
image: ruby:2.1
services:
- postgres
- redis
test1:
<<: *job_definition # Merge the contents of the 'job_definition' alias
script:
- test1 project
test2:
<<: *job_definition # Merge the contents of the 'job_definition' alias
script:
- test2 project
&在anchor的名称(job_definition)前设置,<<表示"merge the given hash into the current one",*包括命名的anchor(job_definition)。扩展版本如下:
.job_template:
image: ruby:2.1
services:
- postgres
- redis
test1:
image: ruby:2.1
services:
- postgres
- redis
script:
- test1 project
test2:
image: ruby:2.1
services:
- postgres
- redis
script:
- test2 project
让我们来看另外一个例子。这一次我们将用anchors来定义两个服务。两个服务会创建两个job,test:postgres和test:mysql,他们会在.job_template中共享定义的script指令,以及分别在.postgres_services和.mysql_services中定义的service指令:
.job_template: &job_definition
script:
- test project
.postgres_services:
services: &postgres_definition
- postgres
- ruby
.mysql_services:
services: &mysql_definition
- mysql
- ruby
test:postgres:
<<: *job_definition
services: *postgres_definition
test:mysql:
<<: *job_definition
services: *mysql_definition
扩展版本如下:
.
job_template:
script:
- test project
.postgres_services:
services:
- postgres
- ruby
.mysql_services:
services:
- mysql
- ruby
test:postgres:
script:
- test project
services:
- postgres
- ruby
test:mysql:
script:
- test project
services:
- mysql
- ruby
你可以看到hidden keys被方便的用作模版。
Triggers
Triggers 可用于强制使用API调用重建特定分支,tag或commits。
在triggers文档中查看更多。
pages
pages是一个特殊的job,用于将静态的内容上传到GitLab,可用于为您的网站提供服务。它有特殊的语法,因此必须满足以下两个要求:
任何静态内容必须放在public/目录下
artifacts必须定义在public/目录下
下面的这个例子是将所有文件从项目根目录移动到public/目录。.public工作流是cp,并且它不会循环复制public/本身。
pages:
stage: deploy
script:
- mkdir .public
- cp -r * .public
- mv .public public
artifacts:
paths:
- public
only:
- master
更多内容请查看GitLab Pages用户文档。
Validate the .gitlab-ci.yml
GitLab CI的每个实例都有一个名为Lint的嵌入式调试工具。 你可以在gitlab实例的/ci/lint下找到该链接。
原文:https://blog.csdn.net/weixin_37934134/article/details/80736957