WebRTC视频JitterBuffer原理机制
前言
如果网络是理想的,即无丢包、无抖动、低延时,那么接收到一帧完整数据就直接播放,效果一定会非常好。但是实际的网络往往很复杂,尤其是无线网络。如果还是这样直接播放,网络稍微变差,视频就会卡顿,出现马赛克等异常情况。所以,在接收端对接收的数据做一个缓冲是很有必要的。
缓冲一定是以延时作为代价的,延时越大,对抖动的过滤效果越好。一个优秀的视频jitterbuffer,不仅要能够对丢包、乱序、延时到达等异常情况进行处理,而且还要能够让视频平稳的播放,尽可能的避免出现明显的加速播放和缓慢播放。
主流的实时音视频框架基本都会实现jitterbuffer功能,诸如WebRTC、doubango等。WebRTC的jitterbuffer相当优秀,按照功能分类的话,可以分为jitter和buffer。buffer主要对丢包、乱序、延时到达等异常情况进行处理,还会和NACK、FEC、FIR等QOS相互配合。jitter主要根据当前帧的大小和延时评估出jitter delay,再结合decode delay、render delay以及音视频同步延时,得到render time,来控制平稳的渲染视频帧。
下面将分别对jitter和buffer做介绍。
Buffer
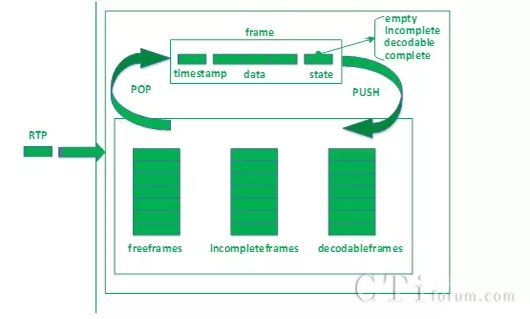
buffer运行机制图
buffer对接收到的rtp包的主要处理操作如下:
- 第一次接收到一个视频包,从freeframes队列中弹出一个空frame块,用来放置这个包。
之后每次接收到一个RTP包,根据时间戳在incompleteframes和decodableframes中寻找,看是否已经接收到过相同时间戳的包,如果找到,则弹出该frame块,否则,从freeframes弹出一个空frame。
- 根据包的序列号,找到应该插入frame的位置,并更新state。其中state有empty、incomplete、decodable和complete,empty为没有数据的状态,incomplete为至少有一个包的状态,decodable为可解码状态,complete为这一帧所有数据都已经到齐。decodable会根据decode_error_mode 有不同的规则,QOS的不同策略会设置不同的decode_error_mode ,包含kNoErrors、kSelectiveErrors以及kWithErrors。decode_error_mode 就决定了解码线程从buffer中取出来的帧是否包含错误,即当前帧是否有丢包。
- 根据不同的state将frame帧push回到队列中去。其中state为incomplete时,push到incompleteframes队列,decodable和complete状态的frame,push回到decodableframes队列中。
- freeframes队列有初始size,freeframes队列为空时,会增加队列size,但有最大值。也会定期从incompleteframes和decodable队列中清除一些过时的frame,push到freeframes队列。
- 解码线程取出frame,解码完成之后,push回freeframes队列。
jitterbuffer与QOS策略联系紧密,比如,incompleteframes和decodable队列清除一些frame之后,需要FIR(关键帧请求),根据包序号检测到丢包之后要NACK(丢包重传)等。
Jitter
所谓jitter就是一种抖动。具体如何解释呢?从源地址发送到目标地址,会发生不一样的延迟,这样的延迟变动就是jitter。
jitter会带来什么影响?jitter会让音视频的播放不平稳,如音频的颤音,视频的忽快忽慢。那么如何对抗jitter呢?增加延时。需要增加一个因为jitter而存在的delay,即jitterdelay。

更新jitterdelay图
其中,frameDelayMS指的是一帧数据因为分包和网络传输所造成的延时总和、帧间延迟。具体如下图,即RTP1和RTP2到达Receiver的时间差。
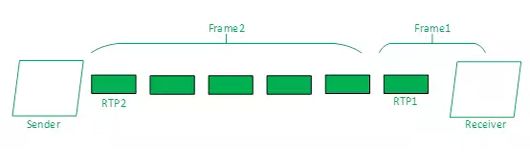
帧间延迟图
framesizeBytes指当前帧数据大小,incompleteFrame指是否为完整的帧,UpdateEstimate为根据这三个参数来更新jitterdelay的模块,这个模块为核心模块,其中会用到卡尔曼滤波对帧间延迟进行滤波。
JitterDelay =theta[0] * (MaxFS – AvgFS) + [noiseStdDevs * sqrt(varNoise) –noiseStdDevOffset]
其中theta[0]是信道传输速率的倒数,MaxFS是自会话开始以来所收到的最大帧大小,AvgFS表示平均帧大小。noiseStdDevs表示噪声系数2.33,varNoise表示噪声方差,noiseStdDevOffset是噪声扣除常数30。UpdateEstimate会不断地对varNoise等进行更新。
在得到jitterdelay之后,通过jitterdelay+ decodedelay +renderdelay,再确保大于音视频同步的延时,加上当前系统时间得到rendertime,这样就可以控制播放时间。控制播放,也就间接控制了buffer的大小。
取帧,解码播放
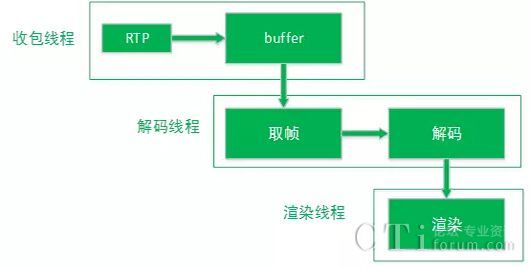
取帧解码播放图
本文只介绍jitterbuffer相关内容,所以这里只详细介绍取帧这一步。
解码线程会一直从buffer中寻找期望的数据,这里说的期望的数据分为必须完整的和可以不完整的。如果期望的数据是完整的,那就要从decodableframes队列取出状态为complete的frame,如果期望的数据可以是不完整的,就要从decodableframes和incompleteframes队列取出数据。取数据之前,总是先去找到数据的时间戳,然后计算完jitterdelay和渲染时间,再经过一段时间的延时(这个延时为渲染时间减去当前时间、decodedelay和render delay)之后再去取得数据,传递到解码,渲染。
取完整的帧时,有一个最大等待时间,即当前buffer中没有完整的帧,那么可以等待一段时间,以期望在这段时间里,可以出现完整的帧。
后记
从上述原理可以看出,WebRTC中的接收buffer并非是固定的,而是根据网络波动等因素随时变化的。jitter则是为了对抗网络波动造成的抖动,使得视频能够平稳播放。
那么,jitterbuffer是否存在可以优化的空间呢?jitterbuffer已经较为优秀,但我们可以通过调整里面的一些策略,来使视频质量更好。比如,增大缓冲区,因为jitterbuffer是动态的,直接增大freeframes的size是无效的,只能通过调整延时,来增大缓冲区。再比如,调整等待时间,以期望获得更多完整的帧。再如,配合NACK,FIR、FEC等QOS策略,来对抗丢包。
当然,这都是以牺牲延时为代价的。总之,要在延时和丢包、抖动之间做出平衡。
http://www.ctiforum.com/news/guonei/512085.html