Opencv 人脸检测训练分类器,及其常见问题
源文:
计算机开发视觉之训练分类器
翻译时间:2017-5-18
笔者:理解概念,参数配置正确,是保证我们检测效率达到指标的前提条件。建议先阅读级联分类器训练,再来阅读本文,相信会有所获。
正样本图像:
问:什么是正样本图像?
答:一张正样本图像应该包括我们要检测的目标对象,相反,负样本图像则不能包括我们要检测的目标对象。
笔者理解:假如我们要检测人脸,那么正样本图像就只能包含人脸,负样本图像就不能包含人脸。
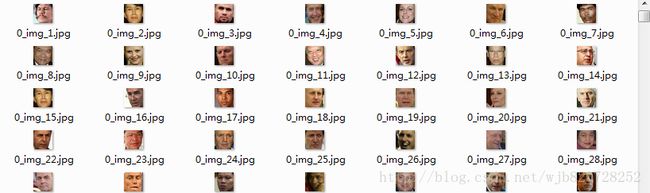
笔者测试:我在做人脸检测的时候,用到的正样本图像如下:(5061张,尺寸 24*24)下载链接
问:在opencv haartraining中vec文件是指什么文件。
答:在haartraining中,每个正样本图像都应该用命令“-w -h size”指定宽和宽一样大小,高和高一样大小(笔者理解:在一个图像样本中w和h不一定要相同,但是不同图像样本之间就应该保持宽高相同),并且,原始正样本应该全部重新调整大小并且打包到vec文件。
笔者理解:vec文件是用来存储-经过resize等操作后得到的正样本图像的描述文件。
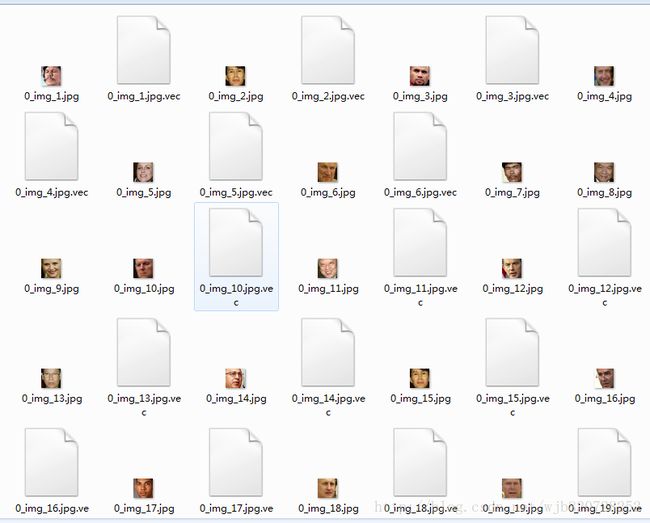
笔者测试:本次人脸识别的vec文件
![]()
问:能合并vec文件吗?
答:可以的,opencv的社区写了这种工具。工具链接,不过上面这个连接失效了,下面提供一个我上传到CSDN的下载连接,里面有使用方法。
笔者:合并vec文件有一个技巧可以利用,就是用来生成大量的正样本图像,比如说一张正脸A,我可以生成多张A的不同方位,不同背景,不同色相,等等的正样本图像。
#!/bin/sh
positive_dir="./pos2/"
list=($(find ./pos2/ -name "*.jpg" ))
length of filelist: ${#list[@]}
for file in ${list[@]}
do
echo ==========================
name=${file##*/}
echo filename: $name
vecname=${name}
./opencv_createsamples.exe -vec ./pos2/$vecname.vec -bg ./neg.txt -img $file -w 24 -h 24 -num 5
echo ==========================
done
listfile=$positive_dir"vec_list.txt"
targetfile="./merge/target.vec"
echo $listfile
echo $targetfile
find $positive_dir -name "*.vec" > $listfile
./merge/mergevec.exe $listfile $targetfile -w 24 -h 24上面是shell脚本,得在bash环境下运行,工作:为./pos2/目录下所有名后缀为.jpg的图像分别每一张生成5张图像(随机利用 ./neg.txt 中的负样本图像作为背景),再把这5张图像打包成vec文件,最后把所有的vec文件再一起合并为target.vec文件。存放在./merge/目录下。
运行shell命令

可以看到每一张正样本图像都对应生成了一个.vec文件
在merge目录下就可以看到target.vec文件的生成。

问:我有正样本图像,那我如何利用这些图像来创建.vec文件?
答: 有一个工具是opencv提供的,名为createsamples,目录:C:\ProgramFiles\OpenCV\apps\HaarTraining\src createsamples.cpp
用法:
opencv_createsamples.exe -vec pos.vec -info pos.txt -num 5061 -w 24 -h 24笔者使用的是opencv2.4.10版本,它自带的createsamples.exe文件,在我的opencv源代码目录下
D:\opencv\opencv\build\x64\vc12\bin问:什么是正样本描述文件?
答:每一张正样本文件都可以有好几个目标(即:我们想检测到的)对象,每个目标都是一个一个有边界的矩形,所以,你可以为每张照片按照下面的方式写出每个目标对象位置、宽和高描述信息。
positive_image_name num_of_objects x y width height x y width height …把每张正样本图像的信息按上面形式写在一个文本文件里面,这个文本文件就可以说是正样本描述文件,本质上讲,正样本文件是用来加快机器学习的。
笔者测试:本次人脸识别的正样本描述文件:
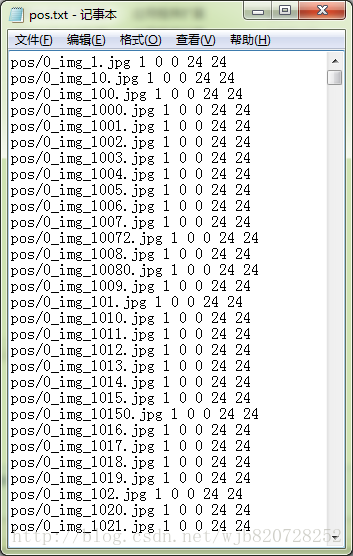
生成上述文件的命令:(文件和图像应该在同一位置)
dir /b > pos.txt得到的pos.txt没有截图中的“pos/“,要加目录的话,可以用替换功能修改。
问:即使我每张图像上只有一个目标对象,我也需要描述文件吗?
答:是的,如果你利用opencv自带的createsamples工具来生成vec文件的话你是需要描述文件的。如果在你的图像上只有一个目标的话,那么目标矩形就可以是一整张图像。当然,你也可以自己写一个工具来生成vec文件。
问:正样本图像的背景需要多样化吗?
答:是的,这很重要,在每一张正样本图像上,除了目标对象之外,就是背景了,要尝试用随机噪点去填充背景,避免固定的背景。
问:正样本图像应该有多大的背景(像素)?
答:如果正样本图像的背景像素远多于目标像素的话,这很糟糕,因为这样的话,haartraining在训练中就会以正样本图像的背景作为正样本图像的特征的了。但,如果正样本图像一点背景都没有的话,也不好,所以,建议在一张正样本图像中,目标像素数量应该比背景像素数量多。
问:所有的原始正样本图像应该有相同的大小吗?
答:不一定,原始正样本图像可以有各自的大小,但重要的是他们的宽,高应该是相同的纵横比。
问:在createsamples的-w -h 的参数上我应该怎么填?w一定要等于h吗?
答:在保持你要检测的目标的宽高纵横比的情况下,你可以指定任意值的w和h。但尺寸设置得较小的话不会被检测到!实际上,经常使用的值是24*24,20*20。但你也可以使用24*20或者20*24等等。
问:错误产生在生成vec文件: Incorrect size of input array, 0 kb vec file
答:
-首先检查你的描述文件,正样本图像名字必须是绝对路径名,并且没有空格,例如:“C:\content\image.jpg”不能是 “C:\con tent\image.jpg” 或者相对路径名。
-再检查描述文件是否有空行,要绝对保证没有空行。
-原始正样本图像像素大小不能比createsamples上输入的-w -h 参数小。
-检查你的文件系统中是否有正样本图像,并且没有损坏。
-正样本图像中不能有不支持的图像格式,支持:JPEG BMP PPM。
问:生成vec文件的例子。
答:首先让你的工作目录是C:\haartraining,在里面有 createsamples.exe。还要有文件C:\haartraining\positives。以下面形式创建正样本描述文件positive_desc.txt。
positives\image1.jpg 1 10 10 20 20
positives\image2.jpg 2 30 30 50 50 60 60 70 70或者
C:\haartraining\positives\image1.jpg 1 10 10 20 20
C:\haartraining\positives\image2.jpg 2 30 30 50 50 60 60 70 70你应该避免有空行和空格在图像路径上,最终执行命令:
createsamples -info positive_desc.txt -vec samples.vec -w 20 -h 20负样本图像
问:怎么样的图像才能算是负样本图像?
答:只要图像格式是opencv支持的,并且没有包含你要检测的目标对象的图像都可以作为负样本图像,但是它们应该是多样化的。多样化这个特性很重要,简单点说就是最好不能有重复的图像。从这里可以下载足够的负样本图像。
笔者:上面链接失效可以下载我百度云盘的资源,链接: https://pan.baidu.com/s/1o8PVQWi 密码: xte1
笔者测试:本次人脸识别的负样本数据:(4631张,在不比正样本图像小的前提下,任意尺寸大小)

问:负样本图像应该有相同的尺寸大小吗?
答:不需要,但是要保证负样本图像像素大小不能比生成vec文件上输入的-w -h 参数小。
问:什么是负样本图像的描述文件?
答:就是一个文本文件,常被命名为negative.dat,它包含负样本图像的完整路径名,例如:
image_name1.jpg
image_name2.jpg避免空行在里面。
笔者测试:本次人脸识别的负样本描述文件:
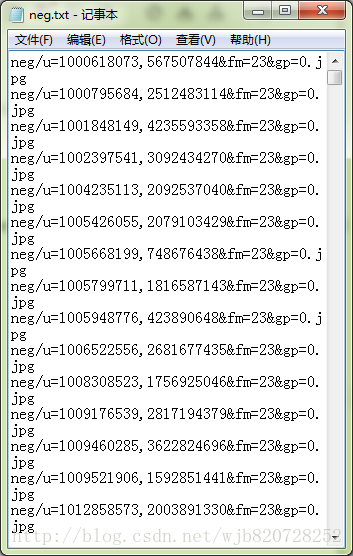
生成上述文件的命令:(文件和图像应该在同一位置)
dir /b > neg.txt得到的neg.txt没有截图中的“neg/“,要加目录的话,可以用替换功能修改。
问:正/负样本数量我应该怎么取?
答:这依赖于你的任务,足够好的比例是 正样本:负样本=1:2,但是这不是硬性的规则,我会建议你一开始使用小数目的样例,生成级联器,然后测试,如果效果不佳就可以加大正负样本数量。
笔者测试:本次的人脸识别我用了两种测试样例,分别如下:
<1> 5061张正样本图像,4681张负样本图像
<2> 10061张正样本图像,4681张负样本图像
运行 haartraining.exe (OpenCV\apps\HaarTraining\src)
问:运行 haartraining.exe 的例子
答:工作目录是C:\haartraining 里面有haartraining.exe工具和samples.vec file描述文件。让负样本图像在C:\haartraining\negative 中,在本次例子中 负样本描述文本 negative.dat 内容应该是如下:
negative\neg1.jpg
negative\neg2.jpg然后在C:\haartraining 目录下运行命令:
haartraining -data haarcascade -vec samples.vec -bg negatives.dat -nstages 20 -minhitrate 0.999 -maxfalsealarm 0.5 -npos 1000 -nneg 2000 -w 20 -h 20 -nonsym -mem 1024参数意义:
-w -h 宽和高 大小要和生成vec文件上输入的-w -h 一致。
-npos -nneg 正样本和负样本图像的数量。
-mem 分配内存,这是一个预测值,代表程序可能会用到这么多内存。
-maxfalsealarm 每阶段的最大错误预警值,如果非常高的错误预警值,意味着这是一个性能差的检测系统。
笔者:所以在每一阶段训练中,只有当错误预警值低于你设置的最大错误预警值的时候才会进入下一阶段的训练。建议设置最大错误预警值为 0.5
笔者测试:我设置的最大错误预警值为0.5(默认),下图你可以看到只有当FA(第三列)小于maxfalsealarm才会进入下一阶段的训练。0.274657<0.5,进入21层训练。
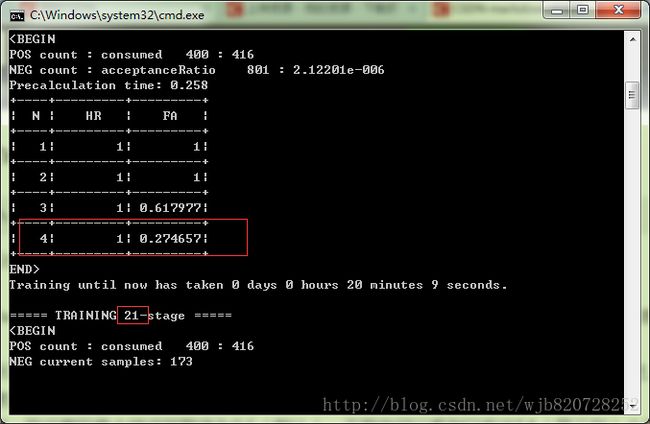
-minhitrate 每阶段都应该保持的最小命中率
-nstage 级联器的阶段数。
问:在每一个阶段中,什么是错误预警器和命中率?
答:你应该看一下adaboost 算法关于强分类器的理论知识。
命中率:举个例子,假如你有1000正样本图像,你想要你的系统从中检测到900张,那渴望的命中率应该是 900/1000=0.9。通常来讲,应该设置最小命中率为0.999
错误预警器:举个例子,假如你有1000张负样本图像,由于它们是负样本图像,你不想你的系统检测到它们,但是你的系统,由于出了错误,还是会检测到它们的一部分。当因为错误检测到了490个图像,那么错误预警值=490/1000=0.49,通常来讲,应该设置错误预警值为0.5。
问:错误预警器和命中率值的设定取决于对方吗?
答:是的,它们之间有依赖,你不应该使得minhitrate=1.0并且maxfalsealarm=0.0。
首先,在每一阶段中,系统使用渴望的命中率编译分类器,然后它会计算错误预警值,如果此时错误预警值比最大错误预警值高的话,系统就会拒绝这样的分类器,将建立下一个分类器。(笔者:直到错误预警值小于最大错误预警值,就选择这个分类器作为本阶段的最佳分类器,如果阶段数还没达到预设定nstage的值,那就进入下一阶段,训练下一阶段的最佳分类器)在haartraining 训练过程中你可能会看到如下:
N |%SMP|F| ST.THR | HR | FA | EXP. ERR|
+—-+—-+-+———+———+———+———+
| 0 |25%|-|-1423.312590| 1.000000| 1.000000| 0.876272|
HR 是 hitrate
FA 是 falsealarm
问:在整个级联器中,错误预警值和命中率是多少?
答:级联器有多个(或者三)阶段链接,那么:
(三个阶段(stage=3,乘3次)示例:)
错误预警值=每一层的错误预警值 * 每一层的错误预警值 * 每一层的错误预警值;
命中率=每一层的命中率 * 每一层的命中率 * 每一层的命中率;
问:一次训练中应该设置多少个阶段:
答:
-如果你设置阶段数量很大的时候,你会得到更好的错误预警值,但是这也需要耗费更多的时间。
-如果你设置阶段数量很大的时候,检测时间将会更慢。
-如果你设置阶段数量很大的时候,命中率会变低(因为 0.99 * 0.99 * …)。通常来讲,设置14-25个阶段是足够的了。
-如果正样本负样本的数量非常少的话,那么设置高阶段数是无效的。
笔者测试:本次人脸识别先后用了四组测试参数,分别如下:
<1>参数为
opencv_traincascade.exe -data data -vec pos.vec -bg neg.txt -numPos 354 -numNeg 4673 -featureType LBP -w 24 -h 24 -numStages 18 -precalcValBufSize 512 -precalcIdxBufSize 1024其中 numpos的354是根据网上一条计算公式得到的。
vec文件中的正样本数目<= numpos+(numStages - 1)(1 - minHitRate) numpos+ s
5061<=354 +(18-1)*(1-0.995)*354+4673
大概取了354
训练结果,历时7个小时25分,训练到16阶段就停止了。
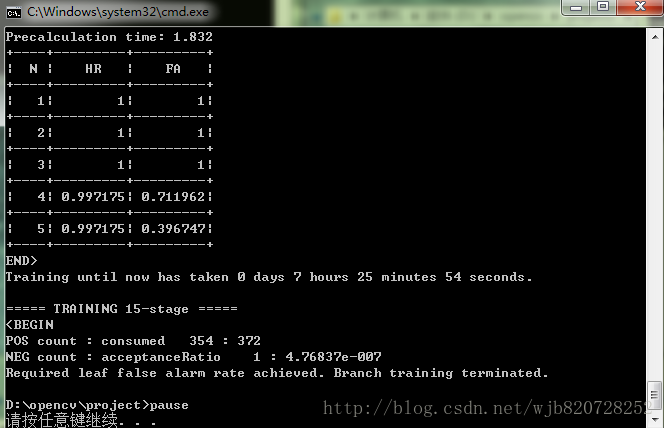
我训练的XML(暂且叫A)测试结果和opencv默认提供的haarcascade_frontalface_alt.xml(暂且叫B)
相比:46个测试样例,A检测到22个人脸,命中率不高,B检测到42个人脸。
<2>参数修改:
opencv_traincascade.exe -data data -vec pos.vec -bg neg.txt -numPos 1354 -numNeg 4673 -featureType LBP -w 24 -h 24 -numStages 18 -precalcValBufSize 512 -precalcIdxBufSize 1024其中 numpos的1354是根据网上说正负样本比例建议1:3得到的。
训练历时8个小时
训练测试结果
46个测试样例,A检测到35个人脸,B检测到42个人脸。命中率稍微有所提升,但是不高。
<3>参数修改如下:
opencv_traincascade.exe -data data -vec pos.vec -bg neg.txt -numPos 2300 -numNeg 4673 -featureType LBP -w 24 -h 24 -numStages 18 -precalcValBufSize 512 -precalcIdxBufSize 1024其中 numpos的2300 是根据本文所说的正负样本比例建议1:2得到的。
训练历时1小时42分
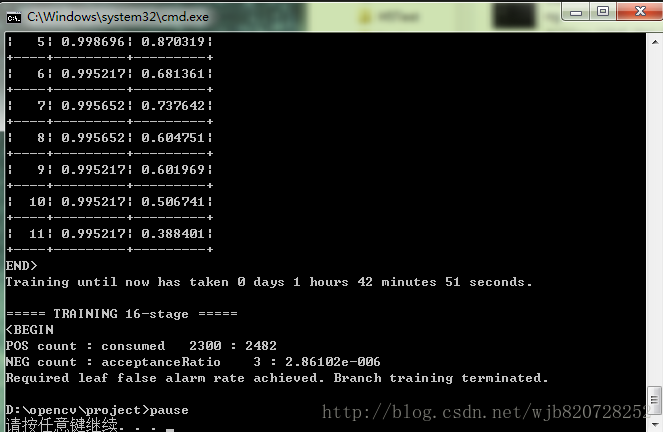
测试结果
46个测试样例,A检测到40个人脸,B检测到42个人脸。命中率竟然接近opencv默认提供的训练XML(B),并且测试了其误检率,明显比B低,还有一点就是opencv默认提供的训练XML(B)文件大小为899KB,而我这个只有40kb,同时回答了XML文件大,命中率就一定高的问题,明显这是不对的。而且我这个是使用opencv_traincascade以LBP特征训练的。可以看出用opencv_traincascade的LBP也是可以训练出精度和haartaining训练差不多的级联器。
大家可以拿去测试一下,这个XML已经上传到我的博客上【XML链接】
注意:级联器调用检测函数的时候参数一定要配置好
我的配置是这样的:
cascade.detectMultiScale(smallImg,rects,1.1,2,0,Size(50,50),Size(70,70)); Size(50,50),Size(70,70)这两个代表检测目标的最小最大尺寸,往往检测不出来,不一定在于级联器训练不好,而且这两个参数没设置好。
总之:npos,nneg,nstage你要怎么设置,现在心中应该有个衡量。建议从小测起,因为数量太多的话,真的真的要检测好几天。。。。
问:什么是weighttrimming,EQW,BT?
答:所有这些参数都与Adaboost有关,阅读理论。简言之:
-nonsym 如果你的正样本图像不是X或Y轴对称的,那么请设置 -nonsym(非对称) 非对称是默认的。
笔者理解:设置为对称的话,算法就只需要计算一半特征值就好了,加快速度,例如人脸就拥有Y轴对称性质。
-eqw 如果你的正样本负样本数量不相同的话,不设置 -eqw会更好(默认不设置)
-weighttrimming 它能减少算法计算时间,但质量可能会变差。
-bt Boosted分类器的类型,Adaboost 算法中会用到的参数: Real AdaBoost (缩写 RAB) 、 Gentle AdaBoost(缩写 GAB)、DAB - Discrete AdaBoost (缩写 DAB )和 LB - LogitBoost (缩写 LB ),其中 GAB是默认。
问:什么是minpos、nsplits、maxyreesplits 选项?
答:这些参数都和聚类有关,在Adaboost 不同弱分类器中可能会用到:stump-based or tree-based这两种类型。如果你设置了nsplits >0 就是一棵树,那么Adaboost 算法中会使用到 tree-based类型,并且你还应该设置minpos和maxtreesplits参数。
-nsplits 树的节点的最小数量
-maxtreesplits 树的节点的最大数量,如果maxtreesplits
-minpos 在训练中会被用到一个节点上的正样本图像的数量,树的每个节点上正样本图像的数量总和就是所有正样本图像的数量。通常,minpos 应该不小于所有正样本数/树的节点数( npos/nsplits)。
问:在haartraining中发生的错误。
答:
1 .Error (valid only for Discrete and Real AdaBoost): misclass
这是一个警告,不是错误。意思是说:你可能在 Boosted分类器类型的参数上选择了一些只能是 DAB 和RAB 专有的参数。所以你的haartraining 还是可以正常运行的。
2 .当荧屏被| 1000 |25%|-|-1423.312590| 1.000000| 1.000000| 0.876272|这样的数据充满的时候,就代表着你的训练进入了循环,需要重新启动训练,第一列的值应该是<100的。
3 .cvAlloc fails. Our of memory 负样本图像的数量太多了,vec文件体积太大。
4 . 注意,参数-w -h 应该和在生成.vec文件时候设置的-w -h 保持一致。
5 .注意,你写在 -npos 和-nneg的正负样本图像应该都是真正可用的,可打开的。
6 .避免空行在负样本描述文件(negative.dat)。
7 .Required leaf false alarm rate achieved. Branch training terminated 意味着很可能在你的负样本图像中有 包含你要检测的目标对象的 图像。导致错误预警值过高,检测你的负样本图像是不是正的符合负样本性质。还有 最大错误预警值 maxfalsealarm 应该在 0.4 -0.5 之间。
opencv 生成 haarcascade XML文件
问:在haartraining 训练中,有一些.txt文件被生成在haarcascade 文件夹中,我们如何把他们生成haarcascade XML 文件?
答:有一个.c文件在目录OpenCV/samples/c下,名为 convert_cascade.c ,你可以键入以下命令:
convert_cascade –size=”20×20″ haarcascade haarcascade.xml笔者:在training中,要手动生成XML文件就更加简单了,你只需要将参数中的numStages 改小一点,改到你想停止那一阶段就OK了,保存再次运行,你会看到程序会停止并且在你指定的目录下生成了XML文件。
问:如何测试我训练生成的XML级联器?
答:有一个perfomance.cpp文件在目录OpenCv/apps/HaarTraining/src /,你需要有正样本图像(不要使用之前用于训练的正样本图像)和正样本描述文件,键入以下命令:
performance -data haarcascade -w 20 -h 20 -info positive_description.txt -ni
performance -data haarcascade.xml -info positive_description.txt -ni时间和加速haar cascade的生成
问:在个人计算机上生成级联器的平均时间是多少?
答:这取决于你的任务和你的机器性能。我生成用于人脸识别的级联器,设置以下参数:-nstages 20 -minhitrate 0.999 -maxfalsealarm 0.5 -npos 4000 -nneg 5000 -w 20 -h 20 -nonsym -mem 1024 。在Pentium 2.7GHZ 2GB RAM 的环境下用了6天的时间训练完成。
问:什么是开放式多处理?
答:OpenMP(开放式多处理)是一个应用程序编程接口(API),支持多平台共享内存的多处理器编程的C、C++和Fortran,在大多数平台上,指令集架构和操作系统,包括AIX、Solaris、HP-UX、Linux、MacOS和Windows。它由一组编译器指令,库例程,和环境变量,影响运行时的行为。如果你有MT 处理器,你可以使用开放式多处理。你需要在你的编译选项中添加openMP的定义,例如在VisualStudio2005环境下:属性(Properties)-> C / C++ ->语言-> OpenMP支持
问:可以提高haartraining的训练速度吗?
答:可以的,一种可行方法是使用并行编程,我们已经实现了OpenCV haartraining使用MPI的Linux集群,你可以在这里阅读原文。
使用opencv XML 级联器检测目标
问:可以检测旋转一定角度的人脸吗?
答:可以的,一种方法是生成一个级联器,用来全方位检测人脸。当然,你也可以分别地为每一个方位生成一个级联器。这样的话你需要旋转一定角度的正样本图像。你可以尝试使用opencv参数 -mode ALL (默认只使用竖直特征,ALL除了能使用竖直特征,还能使用转角为45°的特征集合),生成级联器。但是在opencv1.1上执行效果不好。当然,你也可以为haartraining 添加你自己的特征来训练。这并不是很难。
另一种方法是写头姿态估计器。然后旋转你的图片,让你有正面的人脸并使用opencv默认的人脸级联器来检测它。
问:使用haar 特征可以辨别性别,种族吗?
答:我们尝试过,但用opencvd的haartraining不能做到。像这种分类,我们要使用我们自己的性别分类器,当然你可以用Adaboost haartraining实施这个任务,但我们并没有得到很好的识别率。
问:有可能实时检测人脸吗?
答:可以的。检测分辨率为640*480的图像,5帧每秒(不是实时的),在PC机上使用Opencv 默认提供的人脸检测器(facedetector)检测,大约需要200毫秒。我们已经改变了facedetector得到每秒15帧的实时,你可以在这里看结果,在这里看视频。
至此,翻译也差不多结束了,英语水平有限,如果有错误或者不明白的可以留言,大家一起交流交流,谢谢。
参考资料:
http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/user_guide/ug_traincascade.html
http://blog.csdn.net/liulina603/article/details/8184451
http://blog.csdn.net/u010402786/article/details/52298833
http://blog.csdn.net/wuxiaoyao12/article/details/39227189
http://blog.csdn.net/u010603823/article/details/52557760