Cloudflare 七月全球服务中断始末(上)
背景
七月二日,互联网安全和网络公司 Cloudflare 全球曾出现中断服务事件,其根源是一个不当的正则表达式耗尽了 CPU 资源。 这篇文章 分析了这个祸首,其简化后是 .*.*=.* ,它包含了三个贪婪匹配,进而导致计算量急剧增长,而耗尽 CPU 。
这篇文章篇幅较长,我这里将分两次进行翻译。
引言
大约在九年前,Cloudflare 还只是一个小公司,那时我是一个它的一个客户而非员工。那天,Cloudflare 发起了一个提前一个月和一天的告警,我被告知自己的小网站 jgc.org 貌似不再具有有效的 DNS 。Cloudflare 之前推出了它的缓存协议的变更,该变更破坏了 DNS。
我直接给 Matthew Prince 写了一封邮件,询问:“ 我的 DNS 呢?” 他回复了我一封详细的长邮件,这是我的邮件原文:
感谢您的精彩报告,一旦我确定了这个问题就立即给您电话。在某种程度上,当你已经获得了所有的技术细节后,最好是将这件事情写成一篇博客公开出来。因为,我认为人们真正欣赏的是对这些事件的开放性和坦诚。尤其是,如果您结合几个图表并展示在您的发表内容中的,肯定会增加流量的。
我的网站有很好的监控能力,一旦有任何异常我都会收到短信提示。监控显示网站从 13:03:07 到 14:04:12 是宕机的,每五分钟测试一次。
这只是个小插曲,我相信您会很好地解决它的。但是,您确定在欧洲不需要什么人吗?
Matthew Prince 是这样回复我的:
谢谢!我们已经回复了所有给我们写信的人。我现在正赶往办公室,并且将会在我们的公告版上发布一篇官方博客来说明这件事情,我也完全同意您的观点:透明是最好的解决方案!
因此,今天,作为 Cloudflare 公司的一名员工,我成了那个回复邮件的角色,并透明我们犯的错误、它的影响,以及我们将会怎么处理它。
7 月 2 日事件
今年的 7 月 2 日,我们在 WAF 管理规则中部署了一个新规则,它导致所有 CPU 内核在处理 Cloudflare 网络的 HTTP/HTTPS 流量时,资源被耗尽。我们一直都在提高 WAF 管理规则对新的脆弱性和威胁的响应能力。例如,五月份,我们使用了一种提升能力,有了它可以更新 WAF 去推送一条规则,用来防范一种严重的共享点脆弱性。
能够快速和全局部署一种新规则,是我们的 WAF 的一种关键性的特征。
不幸地是,上周四的一个更新中包含了一个不当的正则表达式,该正则对用于 HTTP/HTTPS 服务的 CPU 进行了极大的回溯,导致 CPU 资源 耗尽。这最终拖垮了 Cloudflare 的核心代理、DNS 和 WAF 功能。下图显示,在我们的网络服务中,专用于 HTTP/HTTPS 服务的 CPU 流量峰值接近 100% 的使用率。
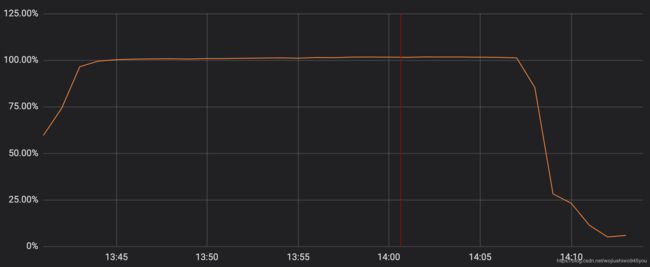
这导致我们的客户(和客户的客户)在访问任何 Cloudflare 域名时将会看到 502 错误页面。502 错误是由 Cloudflare 前端服务器产生的,虽然前端服务器仍然有 CPU 内核访问能力,但是它却无法到达 HTTP/HTTPS 流量服务的进程。

我们深知这件事情对客户带来了多大的伤害,对于此事的发生,我们也很惭愧。在我们处理这一事件时,它也对我们自己的行动产生了负面影响。
对于我们的客户而言,这事一定让他们经历了难以置信地压力、沮丧和恐惧。甚至令人心烦意乱,因为我们已经六年没有出现过一次全球故障了。
CPU 耗尽是由单个 WAF 规则引发的,它包含一个糟糕的正则表达式,最终导致了过量的回溯。故障的核心正则是这样的:
?:(?:\"|'|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*)))
尽管有后很多人对这个正则本身感兴趣,Cloudflare 服务中断 27 分钟背后的真实故事却比 “ 一个变坏的正则 ” 复杂的多。我们花费了一些时间写出这个故障的一系列经过,以帮助我们保持快速响应能力。因此,如果你想知道更多关于正则回溯和如何处理它的内容,您可以在本文的附录中找到它。
发生了什么
让我们一起来看看这个事件的始末,本文所有的时间都是 UTC 时间。
13:42 ,防火墙项目组的一个工程师,通过自动化进程部署了一个针对 XSS 检测的微小变更规则。这产生了一个变更请求票据,我们使用 Jira 【Atlassian 公司出品的项目与事务跟踪工具】来管理这些票据和它们对应的快照。
三分钟后,第一个监控页面出现了,它显示 WAF 出现了一个故障。这是一个来自 Cloudflare 外部的、检查 WAF 功能的语法测试,目的是确保WAF 能够正确工作。紧接着,大量的页面表明其他端到端的 Cloudflare 服务测试失败了,一个全球流量下降警报,传播的 502 错误和许多来自城市网点的报告,种种迹象显示发生了 CPU 耗尽问题。


这些告警击打着我的手表,我不得不放下正在进行的会议,在回到办公桌的路上,一个解决方案团队的 leader 告诉我:我们已经损失了 80% 的流量。我跑到 SRE 部门,那个项目组正则调试解决方案。在故障最开始的时候,有一种推测是发生了我们从未见过的攻击类型。

Cloudflare 的 SRE 团队分布在全世界,能持续覆盖 24 小时。像这样的告警,其中绝大部分都是在有限范围内被注意的具体问题,会在内部公共板上被监控,每天都要被处理很多次。这种页面和告警的模式,虽然能够说明发生了严重的事件, SRE 立即声明一个 P0 事件 ,并且升级为工程领导和系统工程。
伦敦工程师团队,当时正则我们的主要活动中心聆听一个内部技术演讲。演讲被中断了,所有人都集中到一个大会议室,其他团队的人也都拨号接入。这不是一个 SRE 能够独立处理的正常问题,它需要每一个相关的团队同时在线。
14:00,WAF 被识别为故障组件,并且排除了攻击的可能性。性能分析团队从一台机器里拉出了在线的 CPU 数据,这些信息清晰地表明 WAF 要为此负责。另一个团队成员使用 strace 命令进行确认,其他一个团队看到了 WAF 故障的错误日志。14:02,当有人提议我们可以使用了 “global kill ” 时,整个团队的人都看着我,这是 Cloudflare 一个内置机制,可以使单个万维网组件失效。
至于如何 kill 掉 WAF 就是另一个故事了,一切站在我们这边。我们使用自己的产品,由于我们的访问服务故障了,所以不能认证到内部控制面板(而且,一旦我们回退,将会发现有些团队会失去访问,因为安全特性会使得他们的访问凭证失效,如果它们不经常使用内部控制面板)。
我们不能访问到内部服务如 Jira 或构建系统,为了访问它们,我们不得不使用一个不常用的 bypass 机制(这又是另一件可以深度讨论的问题)。最终,一个团队成员在 14:07 执行了全局 WAF kill 操作,14:09 流量等级和 CPU 回退到预期的状态,Cloudflare 其他的保护机制继续操作。
紧接着,我们继续恢复 WAF 功能。出于对当前形式的敏感,我们将付费用户的流量从该处移除后,又将使用流量子集同时进行了反测试(反问自己,真的是这个特殊变更导致的问题吗?)和正测试(验证回滚是否生效)。
14:52,我们完全明白了事件的根源,并且在正确的位置作了修正,WAF 全球服务重新恢复了。
未完,待续……