Elasticsearch解决问题之道——请亮出你的DSL!
0、引言
在业务开发中,我们往往会陷入开发的细枝末节之中,而忽略了事物的本源。
经常有同学问到:
1, 业务代码实现结果和kibana验证不一致。
比如:我的python或者java程序检索结果怎么和kibana里面不一致?
2, 我的某个关键词明明匹配,但怎么检索不到?
比如:星球群讨论的“三星”ik_max_word + match_phrase匹配问题。
3, 熟悉sql,但转dsl就不会写了。
比如:做聚合搜索的话,select * from user where usrid >5 group by userid having count(userid) >3 这个功能能在一个dsl实现吗 ?
4, 查询慢,但不知道什么原因导致的。
比如:elasticsearch有8亿数据查询慢是怎么回事,有什么办法优化。
等等等等…..
以上的看似复杂的问题,如果转换成DSL,清楚的写出来,梳理清楚问题的来龙去脉,问题就自然解决了一大半。
所以,请亮出你的dsl,不论什么语言的检索,转换到es查询都是sql查询,在es中对应dsl语法,es再拆解比如:分词match_phrase拆解成各term组合,最终传给lucene处理。
亮出你的dsl,确保编程里的实现和你的kibana或者head插件一致是非常重要、很容易被忽视的工作。
如果对dsl拆解不理解,那就再加上profile:true或者explain:true拆解结果一目了然。
1、啥是Elasticsearch DSL?
维基百科定义:领域特定语言(英语:domain-specific language、DSL)指的是专注于某个应用程序领域的计算机语言。又译作领域专用语言。
Elasticsearch提供基于JSON的完整查询DSL来定义查询。 将Query DSL视为查询的AST(抽象语法树),由两种类型的子句组成:
1、叶子查询子句
叶查询子句查找特定字段中的特定值,例如匹配,术语或范围查询。 这些查询可以单独使用。
2、复合查询子句
复合查询子句可以组合其他叶子或复合查询,用于以逻辑方式组合多个查询(例如bool或dis_max查询),或更改其行为(例如constant_score查询)。
给个例子,一看就明白。
1GET "localhost:9200/_search
2{
3 "query": {
4 "bool": {
5 "must": [
6 { "match": { "title": "Search" }},
7 { "match": { "content": "Elasticsearch" }}
8 ],
9 "filter": [
10 { "term": { "status": "published" }},
11 { "range": { "publish_date": { "gte": "2015-01-01" }}}
12 ]
13 }
14 }
15}
16
看到这里,可能会有人着急了:“我X,这不是官网定义吗?再写一遍有意思吗?”
引用一句鸡汤话,“再显而易见的道理,在中国,至少有一亿人不知道”。同样的,再显而易见的问题,在Elasticsearch技术社区也会有N多人提问。
基础认知不怕重复,可怕的是对基础的专研、打磨、夯实。
2、DSL的全局认知
Elasticsearch相关的核心操作,广义上可做如下解读,不一定涵盖全,仅抛砖引玉,说明DSL的重要性。
从大到小。
2.1 维度1:集群的管理。
集群的管理,一般我们会使用Kibana或者第三方工具Head插件、cerebro工具、elastic-hq工具。
基本上硬件的(磁盘、cpu、内存)使用率、集群的健康状态都能一目了然。
但基础的DSL会更便捷,便于细粒度分析问题。
如:集群状态查询:
1GET /_cluster/stats?human&pretty
如:节点热点线程查看:
1GET /_nodes/hot_threads
如:集群分片分配情况查看:
1GET /_cluster/allocation/explain
2.2 维度2:索引的生命周期管理。
索引生命周期是一直强调的概念,主要指索引的“生、老、病、死”的全过程链条的管理。
2.2.1、生:创建索引。
创建索引我们优先使用较单纯index更灵活的template模板。
创建索引类似Mysql的创建表的操作,提前设计好表结构对应ES是提前设计好Mapping非常重要。
两个维度:
1、血淋淋的教训:业务上精炼再精炼,一个索引搞定的绝不多表关联。
2、提前设计好字段及扩展字段,即便ES支持动态添加字段。
3、不使用动态映射,所有字段自己定义,节省存储空间。
举例:
1PUT _template/template_1
2{
3 "index_patterns": ["te*", "bar*"],
4 "settings": {
5 "number_of_shards": 1
6 },
7 "mappings": {
8 "_doc": {
9 "_source": {
10 "enabled": false
11 },
12 "properties": {
13 "host_name": {
14 "type": "keyword"
15 }
16 }
17 }
18 }
19}
20'
21
2.2.2、老:滚动索引、关闭索引或者冻结索引。
举例:
1POST /my_index/_freeze
2POST /my_index/_unfreeze
2.2.3、病:索引出了问题。
如:索引清理缓存。
1POST /twitter/_cache/clear
如:某原因导致分片重新分配,_recovery查看分片分配状态。
1GET index1,index2/_recovery?human
2.2.4、死:删除索引。
1DELETE my_index
高版本的索引生命周期管理推荐使用:ILM功能。
2.3 维度3:数据的增删改查。
这个是大家再熟悉不过的了。
2.3.1 增
单条导入数据、批量bulk写入数据、第三方同步数据(本质也是批量)。
举例:
1POST _bulk
2{ "index" : { "_index" : "test", "_id" : "1" } }
3{ "field1" : "value1" }
2.3.2 删
删除数据包括:指定id删除 delete和批量删除delete_by_query(满足给定条件)。
2.3.3 改
更新操作。包括:指定id的update/upsert或者批量更新update_by_query。
2.3.4 查
这是ES的重头戏。包含但不限于:
1、支持精确匹配查询的:term、range、exists、wildcard、prefix、fuzzy等。
2、支持全文检索的:match、match_phrase、query_string、multi_match等
2.4 维度4:数据统计分析

1、Bucketing分桶聚合
举例:最常用的terms就类似Mysql group by功能。
2、Metric计算聚合
举例:类比Mysql中的: MIN(), MAX(), SUM() 操作。
3、Pipeline针对聚合结果聚合
举例:bucket_script实现类似Mysql的group by 后having的操作。
2.5 更多其他维度
留给大家结合业务场景思考添加。
3、实践干货
讲了那么多,实践中遇到问题咋办?
这里把开头提到的几个问题逐一解答一下。
3.1,业务代码实现结果和kibana验证不一致。
实际Mysql业务中,我们一般是先验证sql没有问题,再写业务代码。
实际ES业务中,也一样,先DSL确认没有问题,再写业务代码。
写完java或者python后,打印DSL,核对是否完全一致。
不一致的地方基本就是结果和预期不一致的原因所在。
3.2,我的某个关键词明明匹配,但怎么检索不到?
第一步:借助analyzer API分析查询语句和待查询document分词结果。
1GET my_index/_analyze
2{
3 "field": "text",
4 "text": "华为鸿蒙系统发布-可随时替代安卓",
5 "analyzer":"ik_smart"
6}
这个API的重要性,再怎么强调都不为过。
第二步:可以借助profile:true查看细节。第三步:核对match_phrase词序的原理。
3.3,熟悉sql,但转dsl就不会写了。
6.3版本后已经支持sql,如果不会写,可以借助translate 如下API翻译一下。
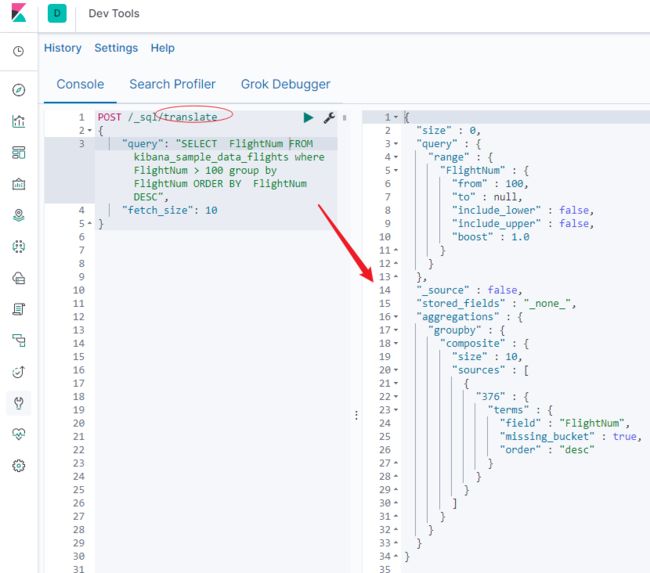
不够精确,但足够参考用了,需要根据业务细节微调。
当然,还是建议,从业务出发,自己写DSL。
3.4,查询慢,但不知道什么原因导致的。
从大往小,逐步细化排解
思路1:索引层面。
8亿条分散到多个索引、多个副本当中,还是一个索引?思路2:Mapping映射设计层面。
举例,设计高效检索Number类型建议改成keyword。
详细参考携程架构师的文章:number?keyword?傻傻分不清楚思路3:检索DSL优化层面
注意:能使用filter过滤检索的就不要使用query,原理参考我之前梳理的文章:
吃透 | Elasticsearch filter和query的不同思路4:返回字段层面
有没有检索的使用_source:"" 限定返回的字段,
如果没有,会全字段返回,数据量大的话,也会慢。思路5:DSL 调试
调试方法:DSL执行语句中加上profile:true .
或者借助:xpack可视化插件排查。
这样,会打印出对应查询的细节花费时间,让你明明白白知道那里慢了。思路6:日志查询
查询的时候,查询ES日志,看看有没有大量的gc。
看看有没有错误日志,错误日志的处理就是优化的方向。思路7:借助cerebro或者xpack mointer监视集群状态
看一看,集群堆内存、cpu、负载的使用情况。思路8:外部思维
想一想,查询的时候,有没有并行的写入操作?
那么查询的时候慢,是不是写入压力大队集群造成的影响。思路9:排除网络慢的原因
内网查询还是外网映射查询,返回时间也不一样。思路10:其他问题
结合业务场景进行分析,自己的业务代码逻辑的问题。
一定要转成DSL进行最小化定位。
4、小结
实际业务中的问题远比上面复杂。但开发的过程中,很多时候,走的太久忘记了出发的目的是什么。
本文仅起到抛砖引玉作用,更多复杂DSL、脚本、自定义评分等DSL没有涉及,不过原理一致。
所以,遇到问题,切莫乱求医。亮出你的DSL,追根溯源、条分缕析逐步细化,问题会迎刃而解。
一起加油,共勉!
推荐阅读:
DSL的诞生 | 复杂sql转成Elasticsearch DSL深入详解
干货 |《深入理解Elasticsearch》读书笔记
干货 | Elasticsearch索引生命周期管理探索
干货 | 通透理解Elasticsearch聚合
Elasticsearch性能优化实战指南

更短时间更快习得更多干货!