Kibana快速介绍
作者:罗海鹏,叩丁狼高级讲师。本文为原创文章,转载请注明出处。
Kibana介绍
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看存放在Elasticsearch中的数据。Kibana与Elasticsearch的交互方式是各种不同的图表、表格、地图等,直观的展示数据,从而达到高级的数据分析与可视化的目的。
Elasticsearch、Logstash和Kibana这三个技术就是我们常说的ELK技术栈,可以说这三个技术的组合是大数据领域中一个很巧妙的设计。一种很典型的MVC思想,模型持久层,视图层和控制层。Logstash担任控制层的角色,负责搜集和过滤数据。Elasticsearch担任数据持久层的角色,负责储存数据。而我们这章的主题Kibana担任视图层角色,拥有各种维度的查询和分析,并使用图形化的界面展示存放在Elasticsearch中的数据。
Kibana安装
1、下载Kibana安装包:
https://www.elastic.co/downloads/kibana
以上地址为Kibana官网下载的地址,目前最新版为6.3.2,Kibana版本和Elasticsearch版本同步更新,所以我们最好使用一致的版本,而我们Elasticsearch使用的版本是6.2.4,所以我们Kibana也需要下载6.2.4。在下载页面点击past releases连接,进入历史版本下载界面,选择6.2.4版本,我们下载tar格式的压缩包,包的全名为:kibana-6.2.4-linux-x86_64.tar.gz。
2、运行Kibana
把Kibana的安装包上传到Linux并解压,进入bin目录可以看到有个名字为Kibana的脚本,该脚本就是启动Kibana的脚本程序,直接执行即可运行Kibana实例:$ ./kibana
我们在执行kibana启动脚本后,看到控制台打印的信息,发现kibana启动就马上去连接Elasticsearch服务,打印信息如下:
log [17:40:27.350] [warning][admin][elasticsearch] Unable to revive connection: http://localhost:9200/
log [17:40:27.355] [warning][admin][elasticsearch] No living connections
通过控制台的打印信息,我们可以知道,Kibana试图连接本机IP的Elasticsearch服务,但是连接不上,那是因为我们还没有把Elasticsearch启动起来。一旦我们把Elasticsearch服务启动起来了,就可以看到以下信息:
log [17:45:06.851] [info][status][plugin:[email protected]] Status changed from red to green - Ready
通过上面的信息我们知道,Kibana的状态是正常的,能连接上elasticsearch服务
kibana默认的端口是5601,给Linux防火墙打开5601的端口后,在另一台windows系统的主机中的浏览器访问Kibana,发现无法访问,原因是因为Kibana默认情况下只能给本机访问,不能远程访问,如果想要远程访问Kibana服务,则需要修改配置文件,那接下来我们看看Kibana有哪些关键的配置。
3、配置文件
Kibana的配置文件在kibana/config目录中,文件名为kibana.yml。我们使用vi编辑器打开后可以看到,该文件所有的配置都是注释掉的,说明所有的配置都是使用默认的,那如果我们需要修改这些默认的配置,就需要找到对应的配置属性,注释解开,然后填写我们自己想要的值。
1、服务的端口配置:
属性名为:server.port默认是5601
2、允许远程访问的地址配置:
属性名为:server.host默认为本机,如果我们需要把Kibana服务给远程主机访问,只需要在这个配置中填写远程的那台主机的ip地址,那如果我们希望所有的远程主机都能访问,那就填写0.0.0.0
3、连接Elasticsearch服务配置
属性名为:elasticsearch.url默认为连接到本机的elasticsearch,并且端口为9200,也就是为localhost:9200,如果我们Elasticsearch不是与Kibana安装在同一台主机上,或者Elasticsearch的端口号不是9200,就就需要修改这个配置了
4、Elasticsearch的用户名和密码
属性名为:elasticsearch.username和elasticsearch.password,默认是没有用户名和密码,如果elasticsearch是配置了用户名和密码的,那就需要配置这两行属性
5、访问Kibana服务
相关的配置修改好了后,就可以使用浏览器访问kibana了,看到如下界面: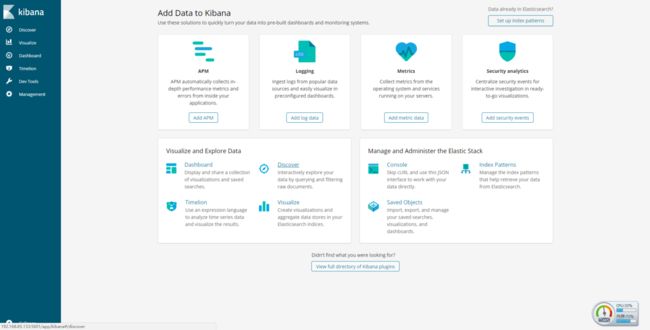
导入测试数据
由于当前我们的Elasticsearch数据量比较少,没办法充分发挥Kibana的作用,很多高级的数据分析和图形化界面都没法展示出来,所以我们需要导入一些测试数据到Elasticsearch中。
数据说明
为了更好的学习Kibana各个功能的使用,我们导入3种不同类型的数据:
1、莎士比亚的所有著作
2、虚构的账号数据
3、随机生成的日志文件
在导入数据之前,我们需要给各个类型的数据创建类型映射。
创建莎士比亚的所有著作的数据类型映射
莎士比亚的所有著作的测试数据的字段有以下这些:
line_id、play_name、speech_number、line_number、speaker、text_entry
我们用以下DSL为该数据创建类型映射(其他没有在映射中约束的字段,使用默认约束):
PUT /shakespeare
{
"mappings" : {
"_default_" : {
"properties" : {
"speaker" : {"type": "keyword" },
"play_name" : {"type": "keyword" },
"line_id" : { "type" : "integer" },
"speech_number" : { "type" : "integer" }
}
}
}
}
映射解析:
1、speaker和play_name是关键字字段,因此不会分词。
2、line_id和speech_number是一个整数。
创建日志数据类型映射
日志数据有几十个不同的字段,但是在教程中关注的字段如下:
memory、geo.coordinates、@timestamp
我们用以下DSL为该数据创建类型映射:
2015.05.18的日志数据映射
PUT logstash-2015.05.18
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}
2015.05.19的日志数据映射
PUT logstash-2015.05.19
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}
2015.05.20的日志数据映射
PUT logstash-2015.05.20
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}
映射解析:
日志数据需要一个表明地理位置的经纬度,通过在那些字段使用一个geo_point类型。
创建账号信息数据类型映射
账号信息测试数据的字段有以下这些:
account_number、balance、firstname、lastname、age、gender、address、employer、city、state
账号数据的各个字段不需要任何约束映射,全都使用默认即可
导入数据
测试数据下载:
https://pan.baidu.com/s/1r--IISJ_8ypRznUx-0aFYw
下载好了之后,上传到Linux上,执行elasticsearch的数据批量导入命令:
curl -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary @accounts.json
curl -XPOST 'localhost:9200/shakespeare/_bulk?pretty' --data-binary @shakespeare.json
curl -XPOST 'localhost:9200/_bulk?pretty' --data-binary @logs.jsonl
导入这些数据需要一点时间,具体根据主机性能而定。导入完之后,可以执行数据查看命令:curl 'localhost:9200/_cat/indices?v'
输出结果如下:
health status index pri rep docs.count docs.deleted store.size pri.store.size
yellow open bank 5 1 1000 0 418.2kb 418.2kb
yellow open shakespeare 5 1 111396 0 17.6mb 17.6mb
yellow open logstash-2015.05.18 5 1 4631 0 15.6mb 15.6mb
yellow open logstash-2015.05.19 5 1 4624 0 15.7mb 15.7mb
yellow open logstash-2015.05.20 5 1 4750 0 16.4mb 16.4mb
通过以上的输出结果,可以看到我们新增的3个测试数据shakespeare,bank和logstash*的数据都导入进去了。那接下来我们就来开始学习Kibana的使用。
