SQL优化技巧
我们开发的大部分软件,其基本业务流程都是:采集数据→将数据存储到数据库中→根据业务需求查询相应数据→对数据进行处理→传给前台展示。对整个流程进行分析,可以发现软件大部分的操作时间消耗都花在了数据库相关的IO操作上。所以对我们的SQL语句进行优化,可以提高软件的响应性能,带来更好的用户体验。
在开始介绍SQL优化技巧之前,先推介一款数据库管理神器Navicat,官网:https://www.navicat.com.cn/whatisnavicat
Navicat是一套快速、可靠和全面的数据库管理工具,专门用于简化数据库管理和降低管理成本。Navicat 的直观图形用户界面,提供简单的方法管理,设计和操作MySQL、MariaDB、SQL Server、Oracle、PostgreSQL和 SQLite的数据。
在遇到Navicat之前,开发软件常用的数据库管理工具有:
(1)MySQL
phpMyAdmin,官网:https://www.phpmyadmin.net/
MySQL Workbench,官网:http://dev.mysql.com/downloads/workbench/
(2)Orace
PL/SQL Developer,官网:https://www.plsqldev.com/
PL/SQL Developer是一个集成开发环境,由Allround Automations公司开发,专门面向Oracle数据库存储的程序单元的开发。
(3)SQL Server
SQL Server Management Studio 是一个集成环境,用于访问、配置、管理和开发 SQL Server 的所有组件。SQL Server Management Studio 组合了大量图形工具和丰富的脚本编辑器,使各种技术水平的开发人员和管理员都能访问 SQL Server。
前面侃了很多废话,言归正传,正式进入正题:SQL优化技巧。
1.查询索引优化:
①-⑤条测试中使用的SQL基于Oracle数据库。
① 查询出年是2015的所有行:表字段放到函数里执行查询时,索引将不起作用。
CREATE INDEX tb1_idx ON tb1 (date_column);
SELECT text_column1, date_column
FROM tb1
WHERE date_column >= TO_DATE ('2015-01-01', 'YYYY-MM-DD')
AND date_column < TO_DATE ('2016-01-01', 'YYYY-MM-DD');② 查询出最近日期的一行数据:
CREATE INDEX tb1_idx ON tb1 (a, date_column);
SELECT *
FROM
(
SELECT id, text_column1, date_column
FROM tb1
WHERE a =: a
ORDER BY date_column DESC
)
WHERE rownum < = 1;这条SQL语句将会按照经过索引的 Top-N 查询方式执行,它的效率跟INDEX UNIQUE SCAN是等效的。
③ 两个查询语句,通过一个普通列查询:
CREATE INDEX tb1_idx ON tb1 (a, b);
SELECT id, a, b
FROM tb1
WHERE a =: a
AND b =: b;
SELECT id, a, b
FROM tb1
WHERE b =: b; 建立的索引只能用于第一个查询,第二个SQL无法利用索引提高效率。
④ 查询一个字符串:
CREATE INDEX tb1_idx ON tb1 (text_column1);
SELECT id, text_column1
FROM tb1
WHERE text_column1 LIKE '%TermStr%';LIKE对应的查询字符如果是以通配符开头的,索引将无法发挥效能。也没有一个简单的方法来优化这种SQL。
⑤ 查询某条件下的记录数:
CREATE INDEX tb1_idx ON tb1 (a, date_column);
SELECT date_column, count(*)
FROM tb1
WHERE a= :a
GROUP BY date_column;
SELECT date_column, count(*)
FROM tb1
WHERE a = :a
AND b = :b
GROUP BY date_column;上面两条查询语句,第一条可能会查出几千或者几万条记录,而第二条语句因为多了一个条件可能只查出几条或几十条记录,也许大家会认为第二条语句的效率更快。其实刚好相反,第一条语句的执行效率更快。因为第一条语句中,索引覆盖了所有查询字段,而第二个SQL中的b条件没有索引。
2.分页性能优化:
以下测试中使用的SQL基于MySQL数据库。
① 高效的计算行数:
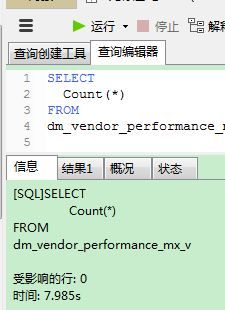
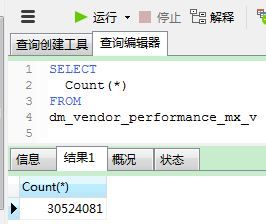
如果采用的引擎是MyISAM,可以直接执行COUNT(*)去获取行数即可。相似的,在堆表中也会将行数存储到表的元信息中。但如果引擎是InnoDB情况就会复杂一些,因为InnoDB不保存表的具体行数。可以将行数缓存起来,然后可以通过一个守护进程定期更新或者用户的某些操作导致缓存失效时,执行下面的语句:
SELECT COUNT(*)
FROM test
USE INDEX(PRIMARY);我的一个测试实例:
offset(分页偏移量)很大时,像下面这样:
SELECT vendorcode, vendorname
FROM dm_vendor_performance_mx_v
LIMIT 10000000,20 
大的分页偏移量会增加使用的数据,MySQL会将大量最终不会使用的数据加载到内存中。就算我们假设大部分网站的用户只访问前几页数据,但少量的大的分页偏移量的请求也会对整个系统造成危害。Facebook意识到了这一点,但Facebook并没有为了每秒可以处理更多的请求而去优化数据库,而是将重心放在将请求响应时间的方差变小。
② 获取记录:
按照实时性排序(最新发布的在最前面,即Id最大的在最前面),实现一个高性能的分页。
一个比较高效的方式是基于要查询的最大Id。查询下一页的语句如下,需要传入当前页面展示的最后一个Id。
SELECT id, vendorcode, perioddate, materialcode
FROM dm_vendor_performance_mx_v WHERE id < 1000000
ORDER BY id DESC
LIMIT 20 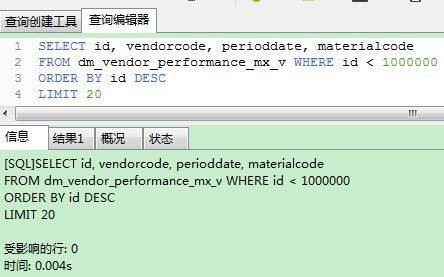
查询上一页的语句类似,只不过需要传入当前页的第一个Id,并且要逆序。
SELECT id, vendorcode, perioddate, materialcode
FROM dm_vendor_performance_mx_v WHERE id > 1500000
ORDER BY id DESC
LIMIT 20 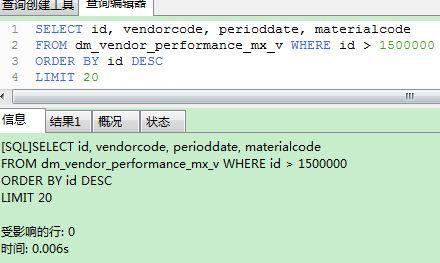
上面的查询方式适合实现简易的分页,即不显示具体的页数导航,只显示“上一页”和“下一页”,例如博客中页脚显示“上一页”,“下一页”的按钮。但如果要实现真正的页面导航还是很难的,下面看看另一种方式。
如果表中的记录很少被删除、修改,还可以将记录对应的页码存储到表中,并在该列上创建合适的索引。采用这种方式,当新增一个记录的时候,需要执行下面的查询重新生成对应的页号。
SET p:= 0;
UPDATE test SET page=CEIL((p:= p + 1) / $perpage) ORDER BY id DESC;当然,也可以新增一个专用于分页的表,可以用个后台程序来维护。
UPDATE pagination T
JOIN (
SELECT id, CEIL((p:= p + 1) / $perpage) page
FROM test
ORDER BY id
)C
ON C.id = T.id
SET T.page = C.page;现在想获取任意一页的元素就很简单了:
SELECT *
FROM test A
JOIN pagination B ON A.id=B.ID
WHERE page=$offset;SQL优化还有很多技巧,我在这里也只是班门弄斧,和资深的DBA比起来还差十万八千里。
以下是我推荐的一些SQL优化的文章:
(1)MySQL知识分享网站:http://ourmysql.com/archives/category/optimize
(2)Sql养成一个好习惯是一笔财富:http://www.cnblogs.com/MR_ke/archive/2011/05/29/2062085.html
(3)MySQL查询语句执行过程:http://shanks.leanote.com/post/MySQL%E6%9F%A5%E8%AF%A2%E8%BF%87%E7%A8%8B
(4)MySQL分页性能优化指南:http://www.codeceo.com/article/mysql-page-performance.html
(5)21条最佳MySQL性能优化:http://www.phpxs.com/post/5092/
(6)100+个MySQL调试和优化技巧:http://mp.weixin.qq.com/s?__biz=MzAwMDM2NzUxMg==&mid=2247484514&idx=1&sn=2cb4246bbf991186eb08aeacd71b2893&scene=21#wechat_redirect