python爬虫—练习题(re,request&BeautifulSoup,selenium)
一、使用 正则 获取51job职位信息
网页分析(
python3.x环境)
import re #导入re模块 import xlwt import chardet from urllib import request import random def getHtml(url): # 获取网页内容 USER_AGENTS = [] # 浏览器(末尾附浏览器) proxies = [] # 代理IP(末尾附IP) req = request.Request(url) # 设置url地址 req.add_header('User-Agent', random.choice(USER_AGENTS)) # 随机选取浏览器 proxy_support = request.ProxyHandler({"http": random.choice(proxies)}) # 随机选取IP地址 opener = request.build_opener(proxy_support) # 获取网站访问的对象 request.install_opener(opener) res = request.urlopen(req) # 处理浏览器返回的对象 html = res.read() return html def get_Datalist(page_number, jobname): # 网址分析 URL = "https://search.51job.com/list/020000,000000,0000,00,9,99," \ +urllib.parse.quote(jobname)+",2," + str(page_number) + ".html?lang=c&stype=&postchannel\ =0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=\ 99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=\ 9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=" html = getHtml(URL) # 传入需要分析网页 code = chardet.detect(html)["encoding"] # 获取网页编码 html = html.decode(code,'replace').encode("utf-8") # 解编码,转成utf-8编码 # 设置正则表达式 reg = re.compile(r'.*? r' r'(.*?).*?' r'(.*?).*?' r'(.*?)', re.S) result = re.findall(reg, html.decode("utf8",'replace')) #replace:替换非法字符 return result datalist = [] # 全局数据列表 def solve_data(page_number, jobname): # 向全局变量添加数据 global datalist for k in range(int(page_number)): # 设置页数,循环获取 data = get_Datalist(k + 1, jobname) for i in data: datalist.append(i) def save_Excel(jobname, filename): # 设置存储函数 book = xlwt.Workbook(encoding="utf-8") # 创建工作簿 sheet = book.add_sheet("51job" + str(jobname) + "职位信息") col = ('职位名', '公司名', '工作地点', '薪资', '发布时间') for i in range(len(col)): sheet.write(0, i, col[i]) for i in range(len(datalist)): # 控制行 for j in range(len(datalist[i])): # 控制列 sheet.write(i + 1, j, datalist[i][j]) book.save(u'51job' + filename + u'职位信息.xls') def main(jobname, page_number, filename): solve_data(page_number, jobname) save_Excel(jobname, filename) main(u"机器学习工程师", "2", u"机器学习职业1") # 爬取职业,爬取多少页码,保存文件名

二、使用 正则 爬取智联招聘
import requests
import chardet
import xlwt
from urllib import request
import random
import re
def getHtml(): #获取链接
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; \
.NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1;\
.NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko)\
Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) \
Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732;\
.NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; \
SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; \
Media Center PC 6.0; .NET4.0C; .NET4.0E)"
] # 浏览器
proxies = [{"HTTP":"117.63.78.64:6666"},
{"HTTPS":"114.225.169.215:53128"},
{"HTTPS":"222.185.22.108:6666"}] # 代理IP
url = "https://sou.zhaopin.com/jobs/searchresult.ashx?jl=%E4%B8%8A%E6%B5%B7&kw=AI&p=1&isadv=0"
r=requests.get(url,
headers={"User-Agent":random.choice(USER_AGENTS)},
proxies=random.choice(proxies))
code = chardet.detect(r.content)["encoding"]
return r.content.decode(code)
DataList = []
def Parser_HTML():
html = getHtml()
reg = re.compile(r'.*?(AI)(.*?).*?'
r' (.*?).*?'
r' (.*?) .*?'
r'(.*?) .*?', re.S)
result = re.findall(reg,html)
for i in result:
DataList.append(i)
print(DataList)
return DataList
def Save_Excel():
wbk = xlwt.Workbook(encoding="utf-8")
sheet1 = wbk.add_sheet("AI职位薪资信息")
field = ("职位名称","公司名称","职位薪资","工作地点")
for i in range(len(field)):
sheet1.write(0,i,field[i])
for j in range(len(DataList)):
for k in range(len(field)):
sheet1.write(j+1,k,DataList[j][k])
wbk.save("AI职业2.xls")
def main():
Parser_HTML()
Save_Excel()
main()
三、使用requests & BeautifulSoup 抓取 豆瓣电影Top250
网页分析(
Python3.x环境)
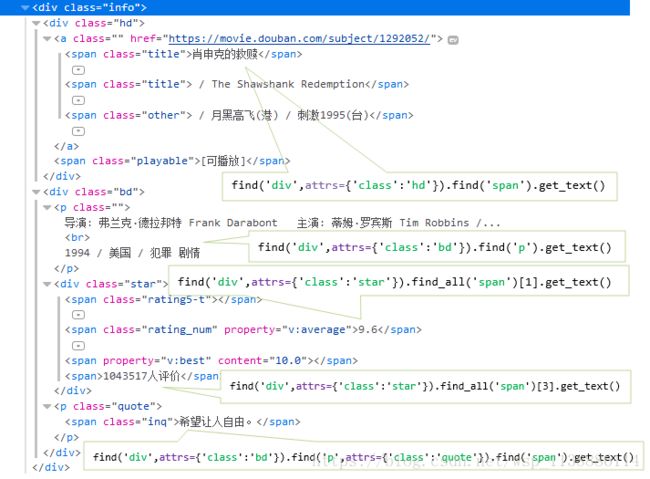
import requests from bs4 import BeautifulSoup import chardet import re import xlwt import time def getHtml(index): # 获取某页的内容 USER_AGENTS = [ ... ] # 浏览器列表 proxies = [{"HTTP":"117.63.78.64:6666"}, {"HTTPS":"114.225.169.215:53128"}, {"HTTPS":"222.185.22.108:6666"}] # 代理IP(临时的) print('正在抓取第',index+1,'页信息') url = 'https://movie.douban.com/top250?start='+str(index*25)+'&filter=' r = requests.get(url, headers={"User-Agent":random.choice(USER_AGENTS)}, proxies=random.choice(proxies)) code = chardet.detect(r.content)['encoding'] return r.content.decode(code) reg = re.compile('.*(\d{4}).*') #获取年份正则 def getData(n): datalist = [] for step in range(n): global reg time.sleep(0.2) html = getHtml(step) soup = BeautifulSoup(html,'html.parser') parent = soup.find('div',attrs={'id':'content'}) #父节点 lis = parent.find_all('li') #获取所有li for li in lis: data = [] film_name = li.find('div',attrs={'class':'hd'}).find('span').get_text() data.append(film_name) #获取电影名称 film_time_str = li.find('div',attrs={'class':'bd'}).find('p').get_text() film_time = re.findall(reg,film_time_str)[0] data.append(film_time) # 获取上映时间 film_score = li.find('div',attrs={'class':'star'}).\ find_all('span')[1].get_text() data.append(film_score) # 获取电影评分 person_number = li.find('div',attrs={'class':'star'}).\ find_all('span')[3].get_text() number = re.findall(re.compile('\d*'),person_number)[0] data.append(number) #获取评价人数 # 获取 简评,因为有个别没有简评标签,所以加判断 if li.find('div',attrs={'class':'bd'}).\ find('p',attrs={'class':'quote'}): evaluate = li.find('div',attrs={'class':'bd'}).\ find('p',attrs{'class':'quote'}).find('span').get_text() else: evaluate = '' data.append(evaluate) datalist.append(data) #存入datalist return datalist def saveToExcel(n,fileName): #存储到excel book = xlwt.Workbook() sheet = book.add_sheet('豆瓣电影Top250') data=getData(n) col = ('电影名称','上映年份','电影评分','评分人数','电影简评') for k,v in enumerate(col): #写入首行 sheet.write(0, k, v) for i,each in enumerate(data): #写入电影数据 for j,value in enumerate(each): sheet.write(i+1, j, value) book.save(fileName) saveToExcel(10,'豆瓣.xls') #设定获取页码,命名 print('结束')
四、使用requests&BeautifulSoup爬取西刺代理网站
分析网页
(python 3.x环境)
import requests from bs4 import BeautifulSoup import re import chardet import random data_dic_http=[] data_dic_https =[] # 定义函数获取天数至少大于10天的代理IP,n代表获取两种代理IP至少分别为n个,缺省值为5 def get_IP(n=5): userAgent = [……] # 浏览器列表 proxies = [{"HTTP": "117.63.78.64:6666"}, {"HTTPS": "222.185.22.108:6666"}] # 代理IP(临时的) url = "http://www.xicidaili.com/" r = requests.get(url, headers={"User-Agent":random.choice(USER_AGENTS)}, proxies=random.choice(proxies)) code = chardet.detect(r.content)["encoding"] html=r.content.decode(code) soup=BeautifulSoup(html,"html.parser") parentTable=soup.find("table",attrs={"id":"ip_list"}) trs=parentTable.find_all("tr") for i in range(2): #删除标题(两行) trs.pop(0) for each in trs: #循环查找 # data_dic_http={"http":[]} # data_dic_https = {"https": []} if each.find_all("td"): tds=each.find_all("td") reg=re.compile("(\d+)天") # print(tds[6]) days=re.findall(reg,tds[6].string) if days: if tds[5].string=="HTTPS" and int(days[0])>=10: data_dic_https.append(tds[1].string+":"+tds[2].string) elif tds[5].string=="HTTP" and int(days[0])>=10: data_dic_http.append(tds[1].string + ":" + tds[2].string) else: continue else: continue if len(data_dic_http)>=n and len(data_dic_http)>=n: break return data_dic_http,data_dic_https http_list,https_list=get_IP(10) # 获取两个代理IP列表,且每个列表种至少10个10天以上的IP print(http_list) >>> ['222.185.22.247:6666', '123.134.87.136:61234', '14.118.255.8:6666', \ '117.67.11.136:8118', '115.28.90.79:9001', '112.115.57.20:3128', \ '123.57.217.208:3128', '222.185.22.247:6666', '123.134.87.136:61234', '14.118.255.8:6666'] print(https_list) >>> ['115.204.25.93:6666', '120.78.78.141:8888', '1.196.161.172:9999', \ '121.231.32.205:6666', '122.72.18.35:80', '101.37.79.125:3128', \ '118.212.137.135:31288', '120.76.231.27:3128', '122.72.18.34:80', \ '115.204.25.93:6666', '1.196.161.172:9999', '121.231.32.205:6666', \ '122.72.18.35:80', '101.37.79.125:3128', '118.212.137.135:31288', \ '120.76.231.27:3128', '122.72.18.34:80']

四、使用BeautifulSoup爬取美女图片
import requests import chardet from bs4 import BeautifulSoup import random from urllib import request import os import time def getHtml(number): #获取链接 USER_AGENTS = [ "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; \ .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1;\ .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)", "Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1;\ .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; \ .NET4.0C; .NET4.0E)" ] # 浏览器 proxies = [{"HTTP":"117.63.78.64:6666"}, {"HTTPS":"114.225.169.215:53128"}, {"HTTPS":"222.185.22.108:6666"}] # 代理IP url = "http://www.27270.com/ent/meinvtupian/list_11_"+str(number+1)+".html" r=requests.get(url, headers={"User-Agent":random.choice(USER_AGENTS)}, proxies=random.choice(proxies)) code = chardet.detect(r.content)["encoding"] return r.content.decode(code) imgList=[] # 全局变量(用来存储图片信息) def Get_ImgData(pageNum): # 获取图片信息 for k in range(pageNum): time.sleep(2) html = getHtml(pageNum) soup = BeautifulSoup(html, "html.parser") Parents = soup.find("div",{'class':"MeinvTuPianBox"}) img = Parents.find_all("img") for i in img: imgList.append(i) return imgList def SaveFile(name): #保存文件 if os.path.exists(name): #创建文件夹 os.rmdir("photos") else: os.mkdir(name) os.chdir(name) for img in imgList: image_name = img['alt'] suffix = img['src'] print("图片名:",image_name) print("图片链接:", suffix) request.urlretrieve(suffix,image_name+str('.jpg')) #强制转成jpg return def main(pageNum,name): #主函数 Get_ImgData(pageNum) SaveFile(name) main(2,'美女_01') #获取页码,文件名

五、使用selenium爬取网易云音乐歌单
from selenium import webdriver
import xlwt
url = 'https://music.163.com/#/discover/toplist'
driver = webdriver.Chrome()
driver.get(url)
driver.maximize_window()
driver.switch_to.frame('contentFrame')
# 切换窗口失败的;先获取frame对象,再切换
# myframe = driver.find_elements_by_tag_name('contentFrame')
# driver.switch_to.frame(myframe)
parents = driver.find_element_by_id("song-list-pre-cache")
table = parents.find_elements_by_tag_name("table")[0]
tbody = table.find_elements_by_tag_name("tbody")[0]
trs = tbody.find_elements_by_tag_name('tr')
SongList = []
for each in trs:
song_Num = each.find_elements_by_tag_name("td")[0].text
song_Name = each.find_elements_by_tag_name("td")[1].\
find_elements_by_tag_name('b')[0].get_attribute('title')
song_time = each.find_elements_by_tag_name("td")[2].text
singer = each.find_elements_by_tag_name("td")[3].\
find_elements_by_tag_name('div')[0].get_attribute('title')
SongList.append([song_Num,song_Name,song_time,singer])
#print(SongList)
book = xlwt.Workbook(encoding="utf-8") # 创建工作簿
sheet = book.add_sheet("Netcloud_song")
col = ('排名', '歌名', '歌曲时长', '歌手')
for i in range(len(col)):
sheet.write(0, i, col[i])
for i in range(len(SongList)): # 控制行
for j in range(len(SongList[i])): # 控制列
sheet.write(i + 1, j, SongList[i][j])
book.save(u'网易云音乐.xls')