Pandas——进阶一(数据处理)
-
-
- 一、Pandas数据算术运算
-
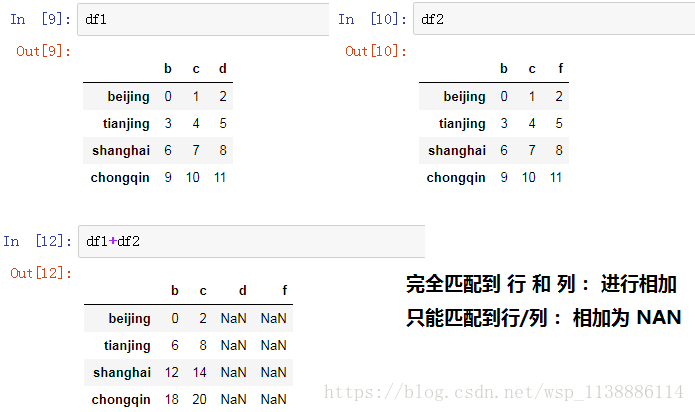
- 1.1 Dateframe元素相加
- 1.2 Dateframe与Series元素相减
- 1.3 apply 与 applymap
-
- 二、Pandas数据修改
-
- 2.1 数据复制–直接赋值
- 2.2 数据复制–copy()函数
- 2.3 行列删除
- 2.4 列增加
- 2.5 行增加
-
- 三、索引重命名
-
- 3.1 整体重命名
- 3.2 部分重命名
-
- 四、索引顺序调整
-
- 4.1 同时调整行和列
- 4.2 单独调整行或列
-
- 五、列格式修改
- 六 、数据排序
- 七 、数据转换(索引列名转换)df.T
- 八、重复值、唯一值、统计
-
- 8.1 重复值查看
- 8.2 删除重复值
- 8.3 统计重复值
-
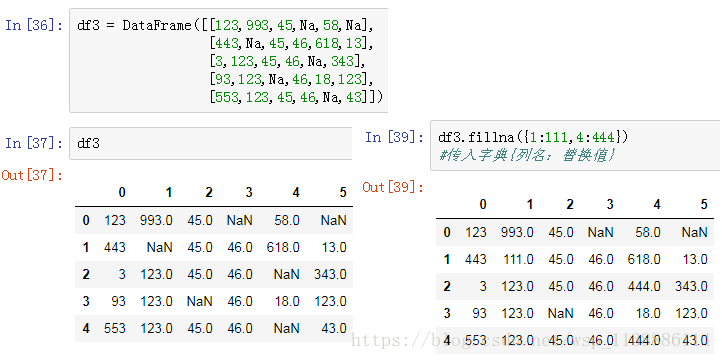
- 九、部分值替换
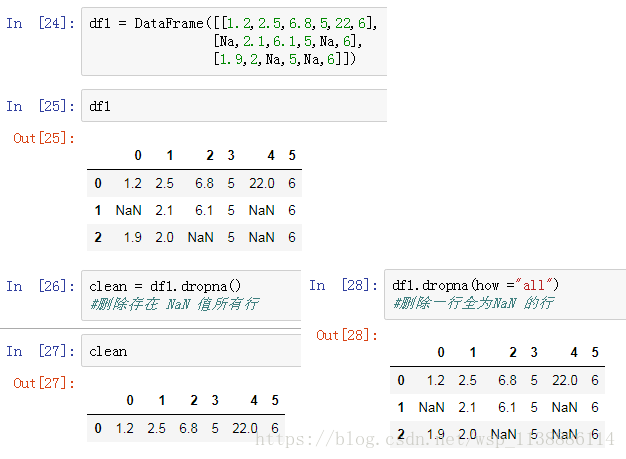
- 十、缺失值处理 -isnull
-
- 缺失值处理步骤:
-
- 一、Pandas数据算术运算
-
以下所有的例子都导入以下包
import pandas as pd
from pandas import DataFrame,Series
import numpy as np
from numpy import nan as Na
一、Pandas数据算术运算
1.1 Dateframe元素相加
在将对象相加时,如果存在不同的索引对,则结果的索引就是该索引对的并集。

1.2 Dateframe与Series元素相减
现将一维数据广播成二维,再进行运算

1.3 apply 与 applymap
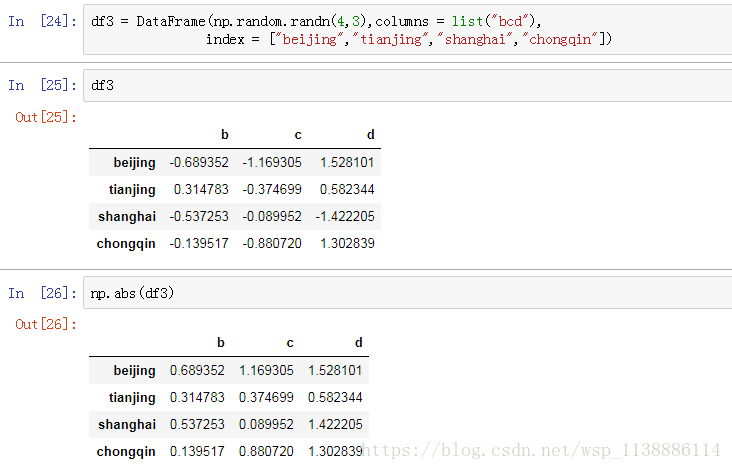

二、Pandas数据修改
2.1 数据复制–直接赋值
若直接赋值的话,只是复制索引,元素存储在相同内存位置中,对元素修改会影响另外一个 train1 = train.head() train1.iloc[0,0] #源数据 train.iloc[0,0] = 100 #修改其中一个对象 #对2个对象都起作用 train.iloc[0,0] train1.iloc[0,0]2.2 数据复制–copy()函数
对索引、内存进行复制,还创建了新储存位置,对元素修改不影响另外一个 train1 = train.head().copy() train1.iloc[0,0] #源数据 train.iloc[0,0] = 200 #修改其中一个对象 #只对修改的对象起作用 train.iloc[0,0] train1.iloc[0,0]2.3 行列删除
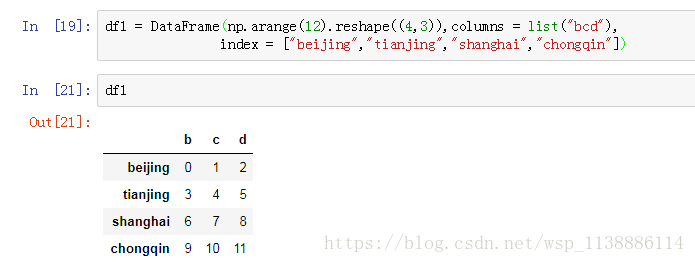
▶ Del 只能删除一列:del df['column_name'] train1.column del train['Age'] train.column ▶ pd.drop 删除多列:pd.drop(labels,axis=1,inplace = False) labels:行列名称列表 axis: 0表示删除行,1表示删除列 inplace: False表示源 DataFrame 不变(默认) True 表示源 DataFrame改变 train1.columns train1.drop(labels=['Name','Ticket'],inplace=True,axis=1) train1.column ▶ pd.pop() 只能删除一列并把删除的一列赋值给新的对象 train.columns sex = train.pop('Sex') train1.columns type(sex) ▶ pd.drop 删除行:pd.drop(labels,axis=0,inplace = False) train1.index train1.drop(labels=['index1','index3'],inplace=True,axis=0) train1.index示例:(删除是操作视图) df = DataFrame(np.arange(20).reshape((4,5)), index = ["山东","山西","湖南","湖北"], columns = ["one","two","three","four","five"]) >>> one two three four five 山东 0 1 2 3 4 山西 5 6 7 8 9 湖南 10 11 12 13 14 湖北 15 16 17 18 19 df.drop(["湖南","山东"]) #默认删除行 >>> one two three four five 山西 5 6 7 8 9 湖北 15 16 17 18 19 df.drop(["one","two"],axis = 1) #指定axis = 1 删除列 >>> three four five 山东 2 3 4 山西 7 8 9 湖南 12 13 14 湖北 17 18 192.4 列增加
▶ 通过 [] 操作符+列名方式增加多列 #新增列在最后 df['new_column1','new_column2'……] = train1.columns train1.[['age_copy','sex_copy']]= train[['Age','Sex']] train1.columns ▶ 通过 loc+列名新增,不能新增多列 #新增列在最后 pd.loc[:,'new_column'] = train1.columns train1.loc[:,'new_copy'] = train['Name'] #每列只能插入一列 train1.columns ▶ 通过 insert(loc,column,value,allow_duplicates = False) loc 位置参数:0<=loc <=len(columns) 新增列在中间,一次只能增加一列 #新增列在指定位置,只能插入单列 train1.columns train1.insert(1,'insert_column',np.linspace(0,1,len(train1 ))) train1.columns2.5 行增加
通过 loc函数新增一行,不能新增多行 pd.loc[:,'new_index'] = #新增行在最后,只能插入单行 train1.index train1.loc['new_copy'] = train1.loc['index'] train1.index
三、索引重命名
3.1 整体重命名
pd.index = pd.column = #整体重命名,不能生成新的对象 train1.index train1.index ='new_' = train1.index train1.index3.2 部分重命名
● 列行同时修改 rename(index = None,columns = None,**kwargs) inplace:boolean,default False(生成新对象) copy: inplace为 False 时生效,表示只是生成新的行列索引。True 时,创建新的存储位置 train2 = train.rename(index={'index':'new_index',……},columns = {'column':'new_column'}) train2.index.difference(train1.index) #查看新索引 train2.column.difference(train1.columns) ● 单独修改行列 rename_axis(mapper,axis = 0,copy = True,inplace = False) mapper:dict示例为{'oldname':'newname'} axis:0表示行,1表示列 train2 = train1.rename_axis(mapper={'name':'new_name',……},axis =1) train2.columns.difference(train1.column)
四、索引顺序调整
4.1 同时调整行和列
reindex(index = None,columns = None,**kwargs) fill_value:出现新的索引时默认的值 method = ffill ffill/pad 前向填充; bfill/backfill 后向填充4.2 单独调整行或列
reindex_axis(labels,axis = 0,method = None copy = True,fill_value = NaN)
五、列格式修改
astype(dtype,copy = True)只能生成新对象dtype取值方式 1:格式:np.float64 2: 字典{'column_name':np.float64,……}
六 、数据排序
pd.sort_index(axis= 1,ascending = False, inplace = True) train.sort_index(axis= 1,ascending = False, inplace = True) ascending #顺序排序/ False倒序排序(大->小) 列值排序 pd.sort_values(by = 'b',ascending = False, inplace = True)
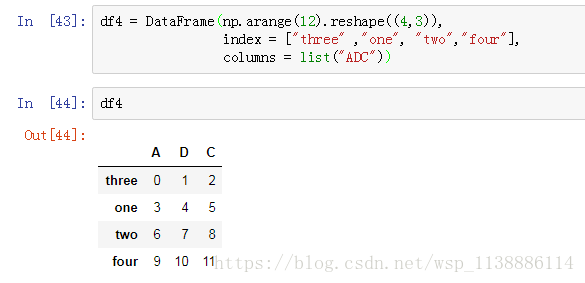

七 、数据转换(索引列名转换)df.T
train2 = train.T train.info() train2 转换后会将 数值型转换为字符串
八、重复值、唯一值、统计
8.1 重复值查看
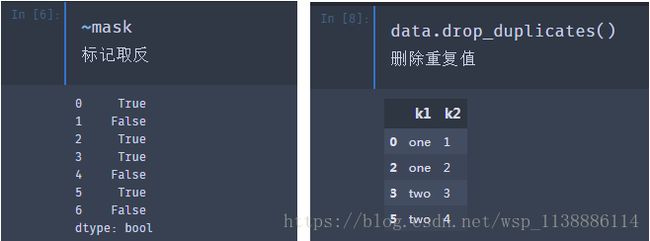
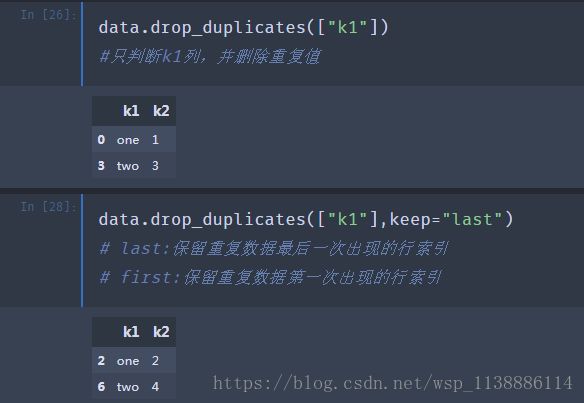
duplicated(subset = None,keep = 'first') Subset 是否只需要检查某几列 Keep:First:支持从前向后,后面出现的为重复值 Last: 从后至前8.2 删除重复值
drop.duplicates(subset = None,keep = 'first',inplace= False)data=DataFrame({"k1":["one"]*3+["two"]*4, 'k2':[1,1,2,3,3,4,4]}) 输出:data k1 k2 0 one 1 1 one 1 2 one 2 3 two 3 4 two 3 5 two 4 6 two 4 mask = data.duplicated() 输出: 0 False 1 True 2 False 3 False 4 True 5 False 6 True dtype: bool
8.3 统计重复值
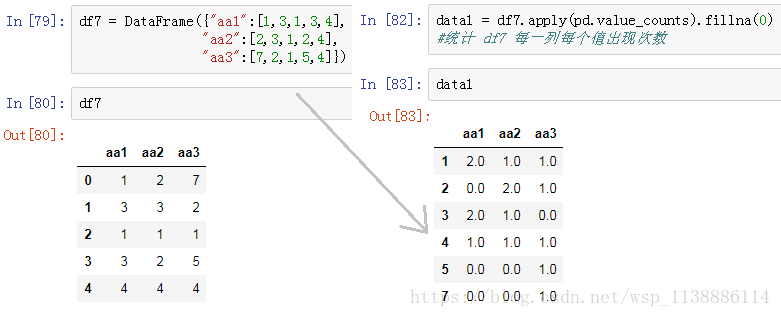

九、部分值替换
replace(to_replace = None,value = None,regex = False,inplace = False) ▶直接指定方式:to_replace 与value 配套使用。old->new 单独值: to_replace = old value = new 相同长度list: to_replace = [old1,old2] value = [new1,new2] list->单值 to_replace = [old1,old2] value = new 指定相同列dict:to_replace={col1:old1,col2:old2} value={col1:new1,col2:new2} dict->单值: to_replace={col1:old1,col2:old2} value=new old,new组成dict: to_replace={old:new1,old2:new2} value=new ▶正则匹配法:to_replace、value、regex 搭配使用 所有使用方式和上面一致,只是多了regex = True ,to_replace 值用正则表示 缺失值处理 - isnull 缺失值处理步骤: 缺失值确认:isnull notnull 缺失值处理:dropno fillna
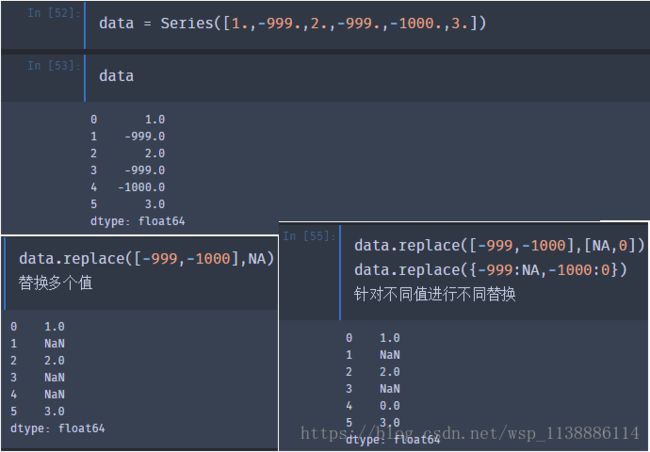
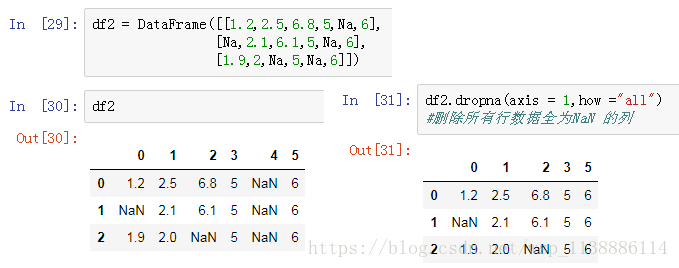
十、缺失值处理 -isnull
缺失值处理步骤:
缺失值确认:isnull,notnull 缺失值处理:dropna,fillna isnull(): 返回一个含有布尔值的对象,表示哪些值是NA Notnull(): isnull的否定式 缺失值处理 -dropna() 判定指定轴是否存在缺失数据,对轴进行过滤(调节阈值对缺失值的容忍度) DataFrame.dropna(axis = 0,how="any",thresh=None,subset=None,inplace=False) how: any表示出现Na就删除,all表示所有制为Na才删除 thresh: 指定非缺失值个数,若个数没有超过这个thresh,则删除 inplace: false表示原DataFrame不变,生成新对象(操作视图) 缺失值处理 -fillna 用指定值或者插值方法,填充缺失值数据 DataFrame.fillna(value =None,methed=None,axis=None,inplace=None,downcast=None,**kwargs) value: 填充值的标量值或者字典对象,与methed只能同时使用一个,只能用于列填充,axis不能赋值 axis: 待填充的轴 limit: 可以连续填充最大数量(method为ffill,bfill时有效)