Python—docx 批量生成 docx 文件
文章目录
- 一、文档结构
- 二、方法
- 三、表格批量写入数据
- 四、批量修改表格文字字体大小颜色
一、文档结构
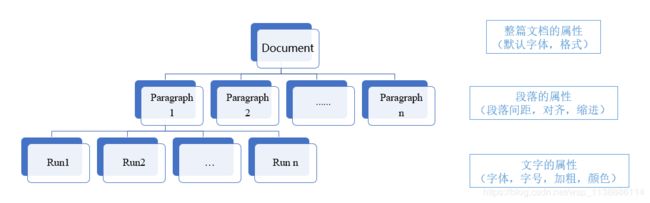
二、方法

from docx import Document
from docx.shared import Pt # 字体磅数
from docx.oxml.ns import qn # 中文格式
from docx.shared import Inches # 图片尺寸
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.shared import RGBColor
import time
today = time.strftime("%Y{y}%m{m}%d{d}",time.localtime()).format(y='年',m='月',d='日')
# 对客户或者领导的工作报告
Customer_Leader = {
'经理1':'9:20',
'经理2':'9:30',
'经理3':'10:40',
'张三': '13:20',
'李四': '14:20',
'王五': '15:20',
}
for key,value in Customer_Leader.items():
document = Document()
document.styles['Normal'].font.name = u'微软雅黑'
document.styles['Normal'].font.size = Pt(14)
document.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), '微软雅黑')
p = document.add_heading('关于XXX'+Customer_Leader[key]+'今日的报告', 0) # 添加标题
# 自定义--段落样式(样式名, 样式类型),样式类型: 1为段落样式, 2为字符样式, 3为表格样式)
UserStyle1 = document.styles.add_style('UserStyle1', 1)
UserStyle1.font.size = Pt(30) # 字体尺寸
UserStyle1.font.color.rgb = RGBColor(0xff, 0xde, 0x00) # 字体颜色
UserStyle1.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中文本
UserStyle1.paragraph_format.first_line_indent = Inches(0.3) # 缩进
UserStyle1.paragraph_format.space_before = Pt(18) # 段前间距
UserStyle1.paragraph_format.space_after = Pt(12) # 段后间距
UserStyle1.font.name = 'Times New Roman' # 西文字体
UserStyle1._element.rPr.rFonts.set(qn('w:eastAsia'), '微软雅黑') # 中文字体
# 自定义--字符样式
UserStyle2 = document.styles.add_style('UserStyle2', 2)
UserStyle2.font.size = Pt(15)
UserStyle2.font.color.rgb = RGBColor(0x0c, 0x8a, 0xc5)
UserStyle2.font.name = '宋体'
UserStyle2._element.rPr.rFonts.set(qn('w:eastAsia'), '宋体')
# 段落-内容(依次添加段落1,段落2)
txt_p1 = '由于天气原因导致产品价格上升%s的通知'%(today)
p1 = document.add_paragraph(txt_p1, style=UserStyle1)
txt_p2 = '预计2019年1-6月归属于上市公司股东的净利润盈利:7,419.218016万元至7,869.218016万元,同比上年增长约:50%至60%。'
p2 = document.add_paragraph('').add_run(txt_p2,style=UserStyle2)
# 添加分页符
document.add_page_break()
# 创建 有序列表
document.add_paragraph('').add_run('微软财务分析人-有序列表内容').font.size = Pt(20)
document.add_paragraph('UBS分析师', style='List Number')
document.add_paragraph('纳德拉', style='List Number')
document.add_paragraph('德意志银行分析师', style='List Number')
# 创建 无序列表
document.add_paragraph('').add_run('微软财务收入-无序列表内容').font.size = Pt(30)
document.add_paragraph('游戏还是主要基于游戏机和个人电脑,微软对自己的定位', style='List Bullet')
document.add_paragraph('微软会在Windows 10商务组件业务上保持两位数的增长', style='List Bullet')
document.add_paragraph('最新的Office对Teams来说是一个全新的突破', style='List Bullet')
document.add_paragraph('用户长期地表现出对产品的忠诚度,该产品越来越被认可了', style='List Bullet')
# 添加分页符,插入图片(默认居左)
document.add_page_break()
document.add_paragraph('').add_run('详情价格单').font.size = Pt(30)
document.add_picture('../gggg/001.png', width=Inches(1.25))
records = (
('浙江东日',
'预计2019年1-6月归属于上市公司股东的净利润盈利:7,419.218016万元至7,869.218016万元,同比上年增长约:50%至60%。',
'因雨雪天气较多,蔬菜批发价格上涨'),
('长城汽车', '预计2019年1-6月归属于上市公司股东的净利润盈利:153,000万元,同比上年下降:58.6%。',
'公司提高产品优惠额度让利消费者,并继续加大品牌推广力度及研发投入'),
('圣济堂', '预计2019年1-6月归属于上市公司股东的净利润亏损:1,500万元至2,500万元。',
'甲醇市场处于持续低迷状态,医药行业受集中带量采购政策所影响,药品价格有所下降')
)
# 添加表
table = document.add_table(rows=1, cols=3)
hdr_cells = table.rows[0].cells # 设置表首行标题
hdr_cells[0].text = '股票简称' # 表首行标题赋值
hdr_cells[1].text = '业绩变动'
hdr_cells[2].text = '业绩变动原因'
for qty, id, desc in records: # for循环将records内容赋值到单元格内
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = desc
document.save('./demo_'+str(key)+'.docx') # 保存文件
三、表格批量写入数据
from docx import Document
from docx.shared import Pt # 字体磅数
from docx.oxml.ns import qn # 中文格式
from docx.shared import RGBColor
import time
def read_txt(txt_path):
f = open(txt_path, "r", encoding="utf-8")
lines = f.readlines()
data_list = []
for line in lines:
data_list.append(line.strip('\n'))
f.close()
return data_list
def write_docx(doc_path,index,text):
document = Document()
document.styles['Normal'].font.name = u'宋体'
document.styles['Normal'].font.size = Pt(10)
document.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), '宋体')
records = (
zip(tuple(text[:5000]),tuple(text[5000:10000]))
)
# 添加表(n行两列)
table = document.add_table(rows=0, cols=2)
for text1, text2 in records:
row_cells = table.add_row().cells
row_cells[0].text = text1
row_cells[1].text = text2
document.save(doc_path+'/medical_'+str(index)+'.docx') # 保存文件
if __name__ == '__main__':
txt_path = './text_local/medical.txt'
doc_path = './test_doc'
data_list = read_txt(txt_path)
doc_num = len(data_list)//5000+1
for index in range(doc_num):
try:
write_docx(doc_path, index,data_list[index*5000:(index+1)*10000])
except:
write_docx(doc_path, index,data_list[index*10000:])
四、批量修改表格文字字体大小颜色
import os
from docx import Document
from docx.shared import Pt # 字体磅数
from docx.oxml.ns import qn
from docx.shared import RGBColor
def get_docx(docx_paths):
docx_list = []
for paths,dirs,filenames in os.walk(docx_paths):
for filename in filenames:
if filename.endswith('.docx'):
docx_list.append(paths+'/'+filename)
return docx_list
'''
增值税发票:深蓝色 #172194(23,33,148)
增值税电子发票:深紫黑色 #1F1023(31,16,35)
增值税发票:浅蓝色 #51557C(81,85,124)
医疗票据: 深黄黑色 #3F4537(63,69,55)
增值税电子发票: 浅黄色 #90867A(144,134,122)
'''
def rewrite_doc(docx_path,output_docx_paths):
save_name = output_docx_paths+'/xieti_127_127_127_'+docx_path.split('/')[-1]
document = Document(docx_path)
table = document.tables[0]
for row in table.rows:
for cell in row.cells:
paragraphs = cell.paragraphs
paragraph = paragraphs[0]
run_obj = paragraph.runs
run = run_obj[0]
# run.font.size = Pt(6.5) # 字体大小
# run.font.name = u'宋体' # 字体
# run._element.rPr.rFonts.set(qn('w:eastAsia'), '宋体') # 字体
# run.font.name = 'Times New Roman'
run.font.color.rgb = RGBColor(23,33,148) # 字体颜色
run.italic = True
document.save(save_name)
if __name__ == '__main__':
input_docx_paths = './标准轮廓宋体大小6.5副本'
output_docx_paths = './xieti_23_33_148'
docx_list = get_docx(input_docx_paths)
for docx_path in docx_list:
rewrite_doc(docx_path, output_docx_paths)
有关模板填充:https://www.cnblogs.com/cofear/p/10686299.html