Redis的数据类型之 hash
书接上回
前一篇文章,我们学习的是 Redis的数据结构 list, 学习了其基本的操作和使用内部数据结构是quicklist和ziplist,这两种数据结构虽然起得名字是list,但是其内部结构确实链表。如果不记得了其内部构成, 就再看看看着上篇文章吧。现在我们继续学习下一个数据类型 hash
hash简介
hash 是一个键值对集合. 是 string 类型的 key 和 value 的映射表, hash 特别适合用于存储对象, 每个hash 类型可以存储 2^32-1 个键值对。
hash 实际上就是一个 哈希表。类似于 Java 里的HashTable。
但是 Redis 的哈希是有两种数据结构(内部编码)来表示的。
-
一种是
ziplist,上篇文章中我们简单的介绍了ziplist的内部构成,见 Redis的数据结构 list, 以及ziplist的编码方式, 可以看这篇文章 10-Redis的数据结构之ziplist.md.Redis什么时候会使用ziplist这种编码方式呢?- 当
hash类型的元素的个数小于hash-max-ziplist-enties配置,默认512. - 所有的值都小于
hash-max-ziplist-value的值,默认是64个字节的时候。
当同时满足以上两个条件的时候, 就会使用ziplist这种结构。
- 当
这种方式最大的优点就是节约空间。
- 另一种就是使用
hashtable来编码了。当不满足上面提及的两个条件时,就会使用hashtable来编码。实际上是dict这种数据结构。这里我们又可以学习到一个新的数据结构dict
hash的应用场景
- 缓存对象信息: 对象的每个属性对应着
hash的一个键值对。改变的时候,只需要改变对应的某个filed-value即可。 - 缓存购物车的信息: 用户的
id为key, 商品的id为field. 商品的数量为value。 比如:hset userId productId productCount
hash的基本命令
hset
- 语法
hset key field value
- 解释
将哈希表 hash 中域 field 的值设置为 value 。
如果给定的哈希表并不存在, 那么一个新的哈希表将被创建并执行 HSET 操作。
如果域 field 已经存在于哈希表中, 那么它的旧值将被新值 value 覆盖。
- 演示
## 设置一个hash结构
127.0.0.1:6379> HSET k38 f1 v38
(integer) 1
# 获取一个字段
127.0.0.1:6379> HGET k38 f1
"v38"
# 设置一个已经存在的值, 注意返回的值。
127.0.0.1:6379> HSET k38 f1 v38v38
(integer) 0
127.0.0.1:6379> HGET k38 f1
"v38v38"
hsetnx
- 语法
HSETNX key field value
- 解释
当且仅当域 field 尚未存在于哈希表的情况下, 将它的值设置为 value 。
如果给定域已经存在于哈希表当中, 那么命令将放弃执行设置操作。
如果哈希表 hash 不存在, 那么一个新的哈希表将被创建并执行 HSETNX 命令。
- 演示
# 设置一个不存在的 key
127.0.0.1:6379> HSETNX k39 f1 v39
(integer) 1
127.0.0.1:6379> HGET k39 f1
"v39"
# 再次设置
127.0.0.1:6379> HSETNX k39 f1 v39v39
(integer) 0
127.0.0.1:6379> HGET k39 f1
"v39"
hget
这个命令上面已经用到了。这里就不浪费时间了。
- 语法
HGET key field
- 解释
获取对应的 key 下的域 field 的值。不存在的时候,返回 nil
hgetall
- 语法
HGETALL key
- 解释
返回哈希表 key 中,所有的域和值。
在返回值里,紧跟每个域名(field name)之后是域的值(value),所以返回值的长度是哈希表大小的两倍。
- 演示
127.0.0.1:6379> HGETALL k39
1) "f1"
2) "v39"
127.0.0.1:6379> hset k39 f2 v39_2
(integer) 1
127.0.0.1:6379> HGETALL k39
1) "f1"
2) "v39"
3) "f2"
4) "v39_2"
hexists
- 语法
HEXISTS key field
- 解释
检查给定域 field 是否存在于哈希表 hash 当中。
存在返回1,不存在返回0。
- 演示
127.0.0.1:6379> HEXISTS k40 f1
(integer) 0
127.0.0.1:6379> HSET k40 f1 v40
(integer) 1
127.0.0.1:6379> HEXISTS k40 f1
(integer) 1
del
- 语法
HDEL key field [field ...]
- 解释
删除哈希表 key 中的一个或多个指定域,不存在的域将被忽略。
- 演示
127.0.0.1:6379> HSET k41 f1 v41_1
(integer) 1
127.0.0.1:6379> HSET k41 f2 v41_2
(integer) 1
127.0.0.1:6379> HSET k41 f3 v41_3
(integer) 1
127.0.0.1:6379> HGETALL k41
1) "f1"
2) "v41_1"
3) "f2"
4) "v41_2"
5) "f3"
6) "v41_3"
127.0.0.1:6379> HDEL k41 f1 f3 f4
(integer) 2
127.0.0.1:6379> HGETALL k41
1) "f2"
2) "v41_2"
hlen
- 语法
HLEN key
- 解释
返回哈希表 key 中域的数量。
- 演示
127.0.0.1:6379> HSET k42 f1 v42_1
(integer) 1
127.0.0.1:6379> HSET k42 f2 v42_2
(integer) 1
127.0.0.1:6379> HSET k42 f3 v42_3
(integer) 1
127.0.0.1:6379> hlen k42
(integer) 3
hstrlen
- 语法
HSTRLEN key field
- 解释
返回哈希表 key 中, 与给定域 field 相关联的值的字符串长度(string length)。
如果给定的键或者域不存在, 那么命令返回 0 。
- 演示
127.0.0.1:6379> HSET k43 f1 "Hello World"
(integer) 1
127.0.0.1:6379> HSTRLEN k43 f1
(integer) 11
127.0.0.1:6379> HSTRLEN k43 f2
(integer) 0
- 语法
HINCRBY key field increment
- 解释
为哈希表 key 中的域 field 的值加上增量 increment 。
增量也可以为负数,相当于对给定域进行减法操作。
如果 key 不存在,一个新的哈希表被创建并执行 HINCRBY 命令。
如果域 field 不存在,那么在执行命令前,域的值被初始化为 0 。
对一个储存字符串值的域 field 执行 HINCRBY 命令将造成一个错误。
本操作的值被限制在 64 位(bit)有符号数字表示之内。
- 演示
# 不存在的key与域 field
127.0.0.1:6379> HINCRBY k45 f1 100
(integer) 100
127.0.0.1:6379> HINCRBY k45 f1 -200
(integer) -100
127.0.0.1:6379> HINCRBY k45 f1 200
(integer) 100
# 错误的类型
127.0.0.1:6379> HSET k45 f2 v45
(integer) 1
127.0.0.1:6379> HINCRBY k45 f2 100
(error) ERR hash value is not an integer
hincrbyfloat
- 语法
HINCRBYFLOAT key field increment
- 解释
为哈希表 key 中的域 field 加上浮点数增量 increment 。
如果哈希表中没有域 field ,那么 HINCRBYFLOAT 会先将域 field 的值设为 0 ,然后再执行加法操作。
如果键 key 不存在,那么 HINCRBYFLOAT 会先创建一个哈希表,再创建域 field ,最后再执行加法操作。
- 演示
127.0.0.1:6379> HINCRBYFLOAT k46 f1 100.5
"100.5"
127.0.0.1:6379> HINCRBYFLOAT k46 f1 100.5
"201"
127.0.0.1:6379> HINCRBYFLOAT k46 f1 -100.5
"100.5"
127.0.0.1:6379> HSET k46 f2 v46_2
(integer) 1
hmset
- 语法
HMSET key field value [field value ...]
- 解释
同时将多个 field-value (域-值)对设置到哈希表 key 中。
此命令会覆盖哈希表中已存在的域。
如果 key 不存在,一个空哈希表被创建并执行 HMSET 操作。
- 演示
127.0.0.1:6379> HMSET k47 f1 v47_1 f2 v47_2 f3 v47_3
OK
127.0.0.1:6379> HGETALL k47
1) "f1"
2) "v47_1"
3) "f2"
4) "v47_2"
5) "f3"
6) "v47_3"
hmget
- 语法
HMGET key field [field ...]
- 解释
返回哈希表 key 中,一个或多个给定域的值。
如果给定的域不存在于哈希表,那么返回一个 nil 值。
因为不存在的 key 被当作一个空哈希表来处理,所以对一个不存在的 key 进行 HMGET 操作将返回一个只带有 nil 值的表。
- 演示
127.0.0.1:6379> HMSET k48 f1 v1 f2 v2 f3 v3 f4 v4
OK
127.0.0.1:6379> hmget k48 f1 f3 f4
1) "v1"
2) "v3"
3) "v4"
127.0.0.1:6379>
hkeys
- 语法
HKEYS key
- 解释
返回哈希表 key 中的所有域。
当 key 不存在时,返回一个空表。
- 演示
127.0.0.1:6379> HMSET k49 f1 v1 f2 v2 f3 v3 f4 v4
OK
127.0.0.1:6379> HKEYS k49
1) "f1"
2) "f2"
3) "f3"
4) "f4"
hvals
- 语法
HVALS key
- 解释
返回 key 对应的所有的value
- 演示
127.0.0.1:6379> HMSET k50 f1 v1 f2 v2 f3 v3 f4 v4
OK
127.0.0.1:6379> HVALS k50
1) "v1"
2) "v2"
3) "v3"
4) "v4"
hscan
- 语法
HSCAN key cursor [MATCH pattern] [COUNT count]
- 解释
这是一个查询命令。 同 SCAN 命令. 可以参考这篇文章 010-其他命令
SCAN 命令是一个基于游标的迭代器(cursor based iterator): SCAN 命令每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 以此来延续之前的迭代过程。
- 演示
127.0.0.1:6379> HMSET k51 f1 v1 f2 v2 f3 v3 f4 v4 f5 v5 f6 v6 f7 v7 f8 v8
OK
127.0.0.1:6379> hscan k51 0
1) "0"
2) 1) "f1"
2) "v1"
3) "f2"
4) "v2"
5) "f3"
6) "v3"
7) "f4"
8) "v4"
9) "f5"
10) "v5"
11) "f6"
12) "v6"
13) "f7"
14) "v7"
15) "f8"
16) "v8"
以上,就是 Redis中hash类型相关的15个命令了。务必熟记~
hash的内部结构
在 hash类型简介的时候,我们就说过 hash是用两种数据结构来编码的。
-
ziplist -
hashtable(dict)
ziplist 之前已经分享过了。具体参考之前的文章吧。 [链接]
这里我们就简单的来看下 hashtable.
我们直接搜索 hash ,可以发现 t_hash.c 这个文件,引入了 server.h . 大体看了一下,都是函数的实现。那我们看下 server.h ,应该存在对 hastable的定义吧。然而,并没有。
那我们来看下t_hash.c中添加方法的实现吧. int hashTypeSet(robj *o, sds field, sds value, int flags)
源码太长了,这里就不粘了, 可以看源码
通过查看源码可以得出:
hash类型的默认编码是OBJ_ZIPLIST. 即默认是使用ziplist这种数据结构进行编码存储的。
robj *createHashObject(void) {
unsigned char *zl = ziplistNew();
robj *o = createObject(OBJ_HASH, zl);
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}
- 当
hash元素的个数大于hash_max_ziplist_entries时会,转换成hashTable(OBJ_ENCODING_HT),
...
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);
...
但是在 redis 5.0.7 中暂时不支持这种方式, 还没有实现。(没有实现从ziplist编码转化成hash编码。)
void hashTypeConvert(robj *o, int enc) {
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
hashTypeConvertZiplist(o, enc);
}
/// 这里!!!
else if (o->encoding == OBJ_ENCODING_HT) {
serverPanic("Not implemented");
} else {
serverPanic("Unknown hash encoding");
}
}
- 当创建的
hash类型是hashtable编码(OBJ_ENCODING_HT)时,是使用dict这种类型存储的.
/// dict类型
typedef struct dict {
dictType *type;
void *privdata;
/// 2个哈希表来实现
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
/// 哈希表实现
typedef struct dictht {
dictEntry **table; /// 哈希表节点指针数据(java源码中的桶的概念)
unsigned long size; /// 指针数组的大小
unsigned long sizemask; /// 指针数据的长度掩码,用于计算索引值
unsigned long used; /// 哈希表现有的节点数量
} dictht;
///哈希表的节点
typedef struct dictEntry {
/// 键
void *key;
/// 值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
/// 下一个节点: dictht 是使用链地址法来处理hash冲突。
struct dictEntry *next;
} dictEntry;
整个 dict 结构就可以这么表示:
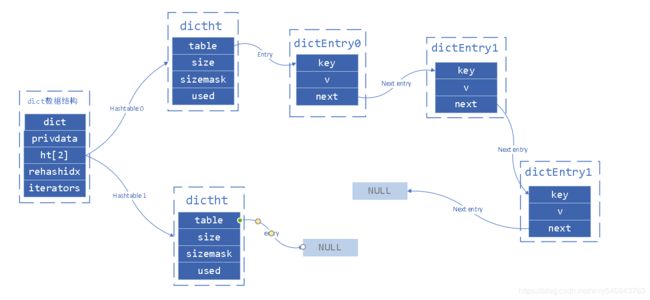
到这里,我们就知道了 hash 这种类型,是如何存储的了。 如果你还想了解
dict 是如何 rehash, 扩容,缩容。以及 dict api相关实现的话,移驾这篇文章吧。 起驾 ~
总结
hash结构,是一种哈希表结构。通过两种数据结构ziplist和hashtable(dict)实现。- 要熟练掌握的
hash相关的15个命令。 hashtable的编码格式, 实际上就是使用的dict这种编码方式。我们简单的学习了Redis中dict结构的实现。还有一篇专门的文章,来介绍dict的详细内容。
最后
希望和你成为朋友!我们一起学习~
最新文章尽在公众号【方家小白】,期待和你相逢在【方家小白】
