学习笔记——关于信号稀疏表示相关概念的整理
一、图像的稀疏
首先理解图像的稀疏,分解原始图像为若干个![]()
![]() 的块,这些样本就是图像中的单个样本块,在固定的字典上系数分解y之后,便得到稀疏向量,从而组成稀疏矩阵,其中x为y在D上的分解稀疏,成为稀疏矩阵,可表示为:
的块,这些样本就是图像中的单个样本块,在固定的字典上系数分解y之后,便得到稀疏向量,从而组成稀疏矩阵,其中x为y在D上的分解稀疏,成为稀疏矩阵,可表示为:
![]()
字典矩阵中的各个列向量被称为原子(Atom). 当字典矩阵中的行数小于甚至远小于列数时,即m⩽n,字典D是冗余的。所谓完备字典是指原子可以张成n纬欧式空间. 如果在某一样本在一过完备字典上稀疏分解所得的稀疏矩阵含有大量的零元素,那么该样本就可以被稀疏表征,即具有稀疏性。一般用L0范数作为稀疏度量函数
二、匹配追踪算法的大体思想总结
匹配追踪的算法思想优点类似于贪婪算法的思想,简单来说,由Y=D*x我们可知,每个原子的贡献情况不同,比如假设D中有b1,b2,b3三个元素,我们假设稀疏矩阵使b1的贡献最大,b2的贡献次之,而匹配追踪的算法做的事情则是,首先寻找贡献最大的原子,然后再寻找贡献次之的原子,最终接近所给出的稀疏度

三、k-svd算法理解
最近在看的论文也正是k-svd,有关它的详解网上已经有很多了,简单来说,因为给出训练数据后一次寻找到全局最优的字典时NP-hard 问题,因此k-svd 问题分两步进行:稀疏表示和字典更新
以下理解摘自其他博客:
-
稀疏表示
首先设定一个初始化的字典,用该字典对给定数据迚行稀疏表示(即用尽量少的系数尽可能近似地表示数据),得到系数矩阵X。此时,应把DX看成D中每列X对应每行乘积的和,也就是把DX分“片”,即:(di 表示D的列 , xi表示X的行),然后逐片优化。 -
字典更新
初始字典往往不是最优的,满足稀疏性的系数矩阵表示的数据和原数据会有较大误差,我们需要在满足稀疏度的条件下逐行逐列更新优化,减小整体误差,逼近可用字典。剥离字典中第k(1-K)项dk的贡献,计算当前表示误差矩阵:
误差值为 :上式可以看做把第k个基分量剥离后,表达中产生空洞,如何找到一个新基,以更好的填补这个洞,就是SVD 方法的功能所在,当误差值稳定的时候字典基本收敛。
关于字典更新的补充:
K-svd采用逐列更新的方法更新字典,就是当更新第k列原子的时候,其它的原子固定不变。假设我们当前要更新第k个原子αk,令编码矩阵X对应的第k行为xk,则目标函数为:
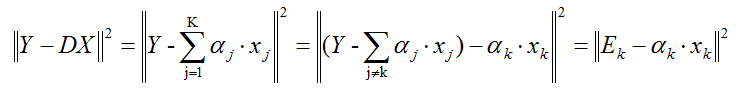
上面的方程,我们需要注意的是xk不是把X一整行都拿出来更新(因为xk中有的是零、有的是非零元素,如果全部抽取出来,那么后面计算的时候xk就不再保持以前的稀疏性了),所以我们只能抽取出非零的元素形成新的非零向量,然后Ek只保留xk对应的非零元素项。
上面的方程,我们可能可以通过求解最小二乘的方法,求解αk,不过这样有存在一个问题,我们求解的αk不是一个单位向量,因此我们需要采用svd分解,才能得到单位向量αk。进过svd分解后,我们以最大奇异值所对应的正交单位向量,作为新的αk,同时我们还需要把系数编码xk中的非零元素也给更新了(根据svd分解)。
然后算法就在1和2之间一直迭代更新,直到收敛。
----------------------------------------------------------------关于代码的理解,之后再更新------------------------------------------------------------------