Flume基础操作,自定义Sink
Flume基础操作,自定义Sink
1. 配置一个flume agent
-
任务目标:
source为 exec source,用tailf命令,监控文件任意
channel设置为filechannel
sink为hdfs sink -
任务完成步骤
- 创建Flume agent配置文件,配置source、sink、channel。
配置source type 为exec,tail -f监控test.txt文件,channel type 为 file,sink type 为 hdfs。
知识点:
–1) Exec Source在启动时调用的Unix命令,该命令进程会持续地把标准日志数据输出到Exec Source,如果命令进程关闭,Exec Source也会关闭。Exec Source支持cat [named pipe] 或者tail -F [file]命令。
–2)File Channel把Event保存在本地硬盘中,比Memory Channel提供更好的可靠性和可恢复性,不过要操作本地文件,性能要差一些。
–3) HDFS Sink直接把Event数据写入Hadoop Distributed File System(HDFS)。HDFS Sink支持输出文本文件(text file)和序列文件(sequence file),同时还可以对数据进行压缩。数 据文件可以根据固定时间间隔、文件大小或者Event数据数量创建。HDFS Sink需要 Hadoop支持。
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/yeexun/hongyu.xu/flume/data/test.txt
a1.sources.r1.fileHeader = true
a1.sources.r1.deserializer.outputCharset = UTF-8
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /tmp/xhy/flume1/
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat=Text
a1.sinks.k1.hdfs.maxOpenFiles = 1
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollSize = 1000000
a1.sinks.k1.hdfs.batchSize = 10000
# Use a channel which buffers events in memory
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/yeexun/hongyu.xu/flume/checkpoint
a1.channels.c1.dataDirs = /home/yeexun/hongyu.xu/flume/data_flume_exec
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1

-
创建需要的目录和文件。
/home/yeexun/hongyu.xu/flume/data
用于存放监测文件的目录。
/home/yeexun/hongyu.xu/flume/data_flume_data
用于把Event保存在本地硬盘中,比Memory Channel提供更好的可靠性和可恢复性
/home/yeexun/hongyu.xu/flume/data/test.txt
用于监测的文件 -
运行flume agent,启动成功并创建hdfs文件。
flume-ng agent \
--conf conf \
--conf-file flume_exec.conf \
--name a1 \
-Dflume.root.logger=INFO,console

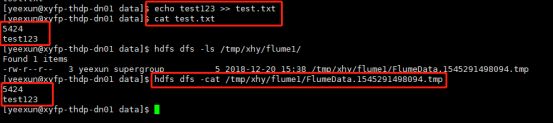
- 往配置的test.txt追加内容,查看test.txt的操作内容flume是否抓取写入到hdfs中,结果成功实时监控test.txt文件。
2.自定义一个sink
-
任务目标:
event中的数据进行处理,如果数据中包含drop、delete、alter字符,则将这条记录
过滤掉,否则将该条记录写入hdfs,处理成功后在MySQL记录处理记录的时间,处理记
录的内容,记录的序号(第几条处理的数据) -
任务完成步骤
- IDEA编写JAVA自定义sink
package com.cloudera.mysql;
import org.apache.flume.*;
import org.apache.flume.conf.Configurable;
import org.apache.flume.sink.AbstractSink;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.yarn.webapp.hamlet.Hamlet;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Date;
import java.util.List;
/**
* Created by hongyu.xu on 2018/12/21.
*/
public class MysqlHdfsSink extends AbstractSink implements Configurable {
private String mysqlurl = "";
private String username = "";
private String password = "";
private String tableName = "";
private String hdfsPath = "";
private int num = 0;
Connection con = null;
@Override
public Status process() throws EventDeliveryException {
Status status = null;
// Start transaction
Channel ch = getChannel();
Transaction txn = ch.getTransaction();
txn.begin();
try
{
Event event = ch.take();
if (event != null)
{
String body = new String(event.getBody(), "UTF-8");
//1,a
//2,b
if(body.contains("delete") || body.contains("drop") || body.contains("alert")){
status = Status.BACKOFF;
}else{
//存入HDFS
Configuration conf = new Configuration();
conf.setBoolean("dfs.support.append",true);
conf.set("dfs.client.block.write.replace-datanode-on-failure.policy", "NEVER");
conf.setBoolean("dfs.client.block.write.replace-datanode-on-failure.enable", true);
Path filePath = new Path(hdfsPath);
FileSystem hdfs = filePath.getFileSystem(conf);
if (!hdfs.exists(filePath)) {
hdfs.createNewFile(filePath);
}
FSDataOutputStream outputStream = hdfs.append(new Path(hdfsPath));
outputStream.write(body.getBytes("UTF-8"));
outputStream.write("\r\n".getBytes("UTF-8"));
outputStream.flush();
outputStream.close();
hdfs.close();
//存入Mysql
num++;
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String createtime = df.format(new Date());
PreparedStatement stmt = con.prepareStatement("insert into " + tableName + " (createtime, content, number) values (?, ?, ?)");
stmt.setString(1, createtime);
stmt.setString(2, body);
stmt.setInt(3, num);
stmt.execute();
stmt.close();
}
/*
JSONObject obj = JSONObject.parseObject(body);
String vehicleId = obj.getString("vehicle_id");
String eventBeginCode = obj.getString("event_begin_code");
String eventBeginTime = obj.getString("event_begin_time");
doc id in index
String id = (vehicleId + "_" + eventBeginTime + "_" + eventBeginCode).trim();
JSONObject json = new JSONObject();
json.put("vehicle_id", vehicleId);
bulkRequest.add(client.prepareIndex(esIndex, esIndex).setSource(json));
BulkResponse bulkResponse = bulkRequest.get();
*/
status = Status.READY;
}
else
{
status = Status.BACKOFF;
}
txn.commit();
}
catch (Throwable t)
{
txn.rollback();
t.getCause().printStackTrace();
status = Status.BACKOFF;
}
finally
{
txn.close();
}
return status;
}
@Override
public void configure(Context context) {
mysqlurl = context.getString("mysqlurl");
username = context.getString("username");
password = context.getString("password");
tableName = context.getString("tablename");
hdfsPath = context.getString("hdfspath");
}
@Override
public synchronized void stop()
{
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
super.stop();
}
@Override
public synchronized void start()
{
try
{
con = DriverManager.getConnection(mysqlurl, username, password);
super.start();
System.out.println("finish start");
}
catch (Exception ex)
{
ex.printStackTrace();
}
}
}
-
Idea将写好的项目clearn并打jar包,上传至/opt/cloudera/parcels/CDH/lib/flume-ng/lib/下。

-
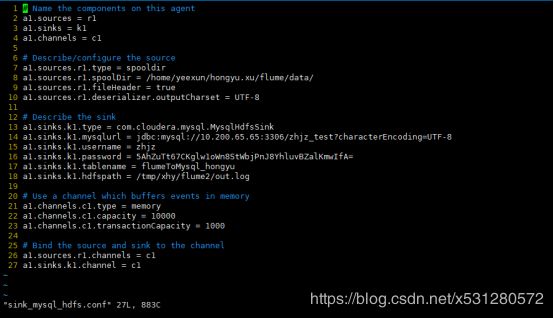
编写flume配置文件,参数需要与java中程序一致,自定义sink至写好的jar。
-
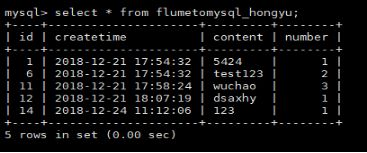
创建Mysql表,与配置内容一致,用于存放处理成功后在MySQL记录处理记录的时间,处理记录的内容,记录的序号。

-
创建/home/yeexun/hongyu.xu/flume/data/路径,用于sources监控路径。
创建hdfs /opt/xhy/flume2/out.log文件,用于写入hdfs日志。 -
运行flume agent,启动成功如果/home/yeexun/hongyu.xu/flume/data下有文件并创建hdfs文件,没有则下次上传文件后创建。
flume-ng agent \
--conf conf \
--conf-file sink_mysql_hdfs.conf \
--name a1 \
-Dflume.root.logger=INFO,console

-
上传文件至data下

-
查看mysql、hdfs是否抓取成功。


-
上传带drop、delete、alter字符的文件查看是否会过滤。
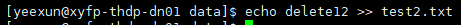
查看hdfs成功过滤:

查看mysql成功过滤: