简易计算机系统综合设计--CPU综合
当完成了各个部件之后,接着要做的就是把各个部件组装起来,配合运作,要使所有部件能够协调地运作,首先得要有一个比较明朗的思路,我们先来分析一下CPU的运行流程:

上图为简易计算机系统的整体构架,现对其运行整体流程进行说明:
(1)取址阶段:
Ⅰ)不受时钟控制的输入(由SM=0确定)有:
①MADD=“00”(选择器选择从PC传输来的地址);
②LDPC=‘1’,INPC=‘1’(PC计数器的计数信号);
③EN=‘1’(RAM的输出使能),WE=‘X’(RAM的写入使能);
④LDIR=‘1’(指令寄存器IR的写入使能)。
Ⅱ)受时钟控制的为:
①由时钟信号CLK1控制存储器RAM对目标地址进行取指令操作。
②由时钟信号CLK2控制指令寄存器IR将从RAM读取的指令进行存储。同时CLK2控制PC计数器中的地址加一。
(2)执行阶段:
Ⅰ)不受时钟控制的操作有:
①指令译码器对从IR输出的指令进行译码,将译码结果传输到各个具体的部件。
②ALU对A,B两个端口得到的数据进行运算并输出。
③位移模块对输入的数据进行操作并输出到BUS总线。
Ⅱ)受时钟控制的信号有:
①由CLK3控制RAM在对应的地址进行读取或者写入(如果具体指令需要—MOVB,MOVC,JMP,JC,JZ);
②由CLK4控制通用寄存器将BUS总线上的数据存入指令中指定的寄存器(如果需要—MOVA,MOVC,ADD,NOT,AND,SUB,SHL,SHR)。
③由CLK4控制PC计数器对BUS总线上的数据进行加载(如果需要—JMP,JC,JZ);
至此一条指令已经运行完成。
然后就只要把各个部件的输入输出端口对应连接就可以了,下面是我的总设计逻辑图:

其中有一些小细节需要注意:
- 从RAM读数据的时候必须要使移位逻辑的输出为高阻态,所以这里移位逻辑的三个输入(F,RL,FR)都与RAM的使能输入取非后做与运算,这样可以避免冲突。在设置时钟信号的时候也有类似的处理。
- Z的值只与ADD和SUB有关,这个我用了一个检测器去作为Z寄存器的使能信号。
- 在某些部位加上输出端口可以查看运行过程中的数据是否正确。
下面是对多个指令的执行结果:
初始化RAM的.mif文件的具体内容:

测试结果:

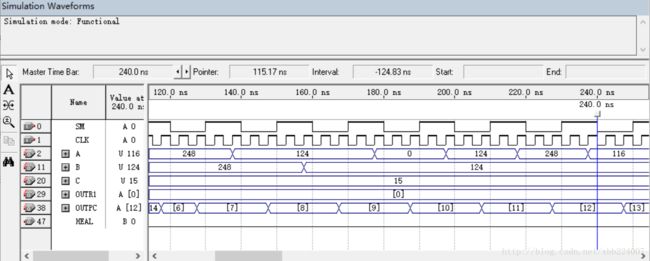

下面对320.0ns前的指令进行分析:
0~20ns:取PC=“0”,得到指令“01010000”,对A寄存器的内容取反,A由152变成103;
20~40ns:取PC=“1”,得到指令“01010100”,对B寄存器的内容取反,B由7变成248;
40~60ns:取PC=“2”,得到指令“10010001”,对A与B求和,将结果95存入A寄存器;
60~80ns:取PC=“3”,得到指令“00010000”,该指令为跳转指令JMP,直接跳转到该指令的后一地址对应的地址“00001100”=12,跳转到地址12;
80~100ns:取PC=“12”,得到指令“11110001”,为MOVA指令,将B寄存器中的内容存入A中,得到A=B=248;
100~120ns:取PC=“13”,得到指令“00010010”,为跳转指令JC,由于在40~60ns的ADD运算中存在进位,故可以跳转,跳转到地址“00000110”=6;
120~140ns:取PC=“6”,得到指令“10100000”,为右移指令,将A寄存器的内容右移,由原来的248变为124;
140~160ns:取PC=“7”,得到指令“10100100”,为右移指令,将B寄存器的内容右移,由原来的248变为124;
160~180ns:取PC=“8”,得到指令“01100001”,为减法指令,将A-B的结果0存入寄存器A中,故结束后A=‘0’;
180~200ns:取PC=“9”,得到指令“10010001”,为加法指令,将A+B的结果124存入寄存器A中,故结束A=124;
200~220ns:取PC=“10”,得到指令“10010001”,为加法指令,将A+B的结果248存入寄存器A中;
220~240ns:取PC=“11”,得到指令“10010001”,为加法指令,将A+B的结果116存入寄存器A中;
240~260ns;取PC=“12”,得到指令“11110001”,为MOVA指令,将B寄存器中的内容存入A中,得到A=B=124;
260~280ns:取PC=“13”,得到指令“00010010”,为跳转指令JC,但由于C/=“1”,故不进行跳转,并跳过下一地址;
280~300ns:取PC=“15”,得到指令“00010010”,为跳转指令JC,但由于C/=“1”,故不进行跳转,并跳过下一地址;
300~320ns:取PC=“17”,得到地址“01010100”,为左移指令,将B寄存器的内容左移,故结束得到,B=131。
最后给出整个CPU综合设计工程,算是留作纪念了。