我的java学习笔记(上)
简介:综合所学,花了三个月,写了一份较为详细的Java学习笔记。希望对大家有帮助。由于内容过多,本篇为上半部分。
目录
第一章 java语言基础
一、java概述
二、JDK环境变量设置
1、设置步骤
2、jdk jre 之间的区别
3、cmd命令运行java程序
三、Java语言基础
1、java中的标识符
2、java中的关键字
3、注释
4、java中的数据类型
5、java类型转换
6、运算符
7、break和continue
8、数组
9、for each循环
第二章 java面向对象基础
一、基础
1、类和对象
2、面向对象与面向过程的区别
3、成员变量和局部变量
4、方法
5、对象的构造
6、static关键字
7、单例设计模式
二、继承
1、继承概述
2、访问控制
3、继承详解
4、this关键字解析
5、super关键字
6、方法的重载与重写
三、抽象类和接口
1、抽象类
2、接口
四、多态
1、多态的概念
2、向上转型和向下转型
3、多态的作用
4、instanceof关键字
五、内部类
1、内部类概述
2、内部类基础
3、内部类种类
六、包装类
1、基本数据类型对象包装类概述
2、Integer
3、JDK1.5自动装箱拆箱
七、字符串
1、String类
2、StringBuffer和StringBuilder
八、其他常用类
1、System类
2、系统属性信息
3、Runtime类
4、Math类
5、Date类
6、DateFormat类
7、Calendar类
8、Scanner
第三章、java虚拟机体系结构
一、java虚拟机概述
二、方法区
1、方法区概述
2、运行时常量池
三、堆
1、堆
2、引用类型变量和对象的区别
四、栈
1、栈
2、Java栈的组成
五、PC寄存器
六、本地方法栈
第四章、java类记得加载机制及其步骤
一、类的加载过程
1、类的加载
2、链接(验证+准备+解析)
3、初始化
二、加载顺序-案例分析
案例一:
1、静态初始化块和非静态初始化块
2、类加载特性
3、Java代码编译和执行
4、static属性内存分配
5、final修饰符
二、方法的调用
1、指令调用
2、调用方式
第五章 java进阶
一、异常、断言和调试
1、异常的基本概念及其分类
2、如何抛出异常
3、异常捕获
4、异常处理的原则
5、记录日志
二、集合
1、集合概述
2、Collection接口
3、List接口
3.1、ArrayList类
3.2、LinkedList类
4、Set接口
5、Map接口
5.1、HashMap类
5.2、Hashtable类
注:这些方法是Hashtable独有的,Map中并没有这些方法。
5.3、TreeMap类
5.4、区别:
6、集合工具类Collections
7、泛型
7.1、Java泛型实现原理:类型擦除
7.2、泛型类、泛型方法、泛型接口
三、java反射
1、反射概述
2、反射获取对象的三种方式
3.获取Class中的构造函数
4、静态代理和动态代理
四、IO流
1、File类
2、IO流概述
3、字节流-字节输入流-InputStream
4、字节流-字节输出流-OutputStream
5、字符流-字符输入流-Reader
6、字符流-字符输出流-Writer
7、自定义缓冲区
8、装饰设计模式
9、RandomAccessFile类随机存取
10、其他综合练习
11、Properties类
五、多线程
1、基本概念
2、java多线程的实现方式
3、线程的五种状态
4、线程的优先级
5、停止线程的方式
6、守护线程
7、join方法
8、卖票案例
9、线程同步方式
10、死锁
11、线程等待与唤醒
12、线程让步
13、线程睡眠
14、单例模式设计的多线程问题
15、生产者和消费者问题
16、jdk1.5以后同步和锁封装成了对象
第六章 其他综合
一、常用帮助类型
二、正则表达式
第一章 java语言基础
一、java概述
1、编程语言的发展
第一代语言:机器语言
第二代语言:汇编语言、单片机MOV A B
第三代语言:C所有高级语言的基础、面向过程的语言,C++面向过程/对象语言,Java完全面向对象的跨平台语言,.net跨语言的面向对象平台。
2、Java发展史
Java语言出现于1991年,JDK1.0版本正式发布于1995年
Java的摇篮:SUN Stanford University NetWork
Java之父:James Gosling(詹姆斯•高斯林)
JDK1.0、JDK1.1、JDK1.2、JDK1.3、JDK1.4、JDK5.0、JDK6.0、JDK7.0、JDK8.0
JDK1.4之后-Sun将JDK1.5改名为J2SE5.0,J2SE5.0较以前的J2SE版本有着很大的改过。
3、Java技术架构体系
Java代表一个技术体系、根据应用方向的不同分为SE/EE/ME三部分
a) J2SE:桌面应用程序
b) J2EE:web应用程序
c) J2ME:手机应用程序
Java SE:(Java Platform,Standard Edition)为创建和运行java程序提供了最基本的环境,是java技术的核心和基础,可以重点学习:集合类、文件操作、I/O流、线程、序列化和CUI窗体编程等内容。
Java EE:(Java Platform,Enterprise Edition)为基于服务器的分布式企业应用提供开发和运行环境,可以重点学习jsp、servlet、jdbc、ejb以及ssh等框架。
Java ME:(Java Platform,Micro Edition)为嵌入式应用提供开发和运行环境。如手机程序和PDA程序。可以重点学习配置和简表。
4、android与java语言有什么关系
Android:是由google于2007年11月5日宣布的基于linux平台开源的手机操作系统。
Android-SDK:Android应用程序开(Android SDK引用了大部分的Java SDK)
Java平台和java语言:
Java平台:由三部分组成,分为核心的java api(包、框架及类库)、java字节码(编译且可执行的形式)以及java虚拟机(jvm执行字节码的运行机制)
Java语言只不过是java平台中的一小部分,其他语言同样可以实现java原则的功能。例如:Groovy(jvm的一个替代语言,它的语法与java语言相似,以精简有趣的方式在java平台处理事务并把类似Python Ruby等强大的功能带到了java世界)、JRuby及JPython等这些语言同样可以编写出运行在jvm上执行的字节码。
5、Java特点
a) Java是一种面向对象的编程语言
b) Java语言是一种编译解释型语言
c) 因为Java语言是基于Java虚拟机运行,所以Java语言可以实现跨平台
d) Java的GC垃圾回收器
计算机高级编程语言按其程序的执行方式可以分为:编译型语言和解释型语言。
编译型:使用专门的编译器,针对特定操作系统将查询代码一次性翻译成计算机能识别的机器指令。C、c++都属于编译型。
解释型:使用专门的解释器,将源程序代码逐条的解释成特定平台的机器指令,解释一句执行语句,类似于同声翻译。ASP、PHP属于解释型。
Java既不是编译型也不是解释型语言,它是介于编译型和解释型之间的一个结合体。
首先采用通用的java编译器将java源程序编译成为与平台无关的字节码文件(.calss文件),然后由虚拟机(jvm)对字节码文件解释。执行。一次编译、多处执行。Jvm是通过jdk中的java.exe来实现的。
二、JDK环境变量设置
1、设置步骤
a)在系统变量里点击新建,变量名填写JAVA_HOME,变量值填写JDK的安装路径,比如:“C:\Program Files\Java\jdk 1.7.0_67”了。

b)在系统变量里点击新建变量名填写CLASSPATH,变量值填写“.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME\lib\tools.jar ”。注意不要忘记前面的点和中间的分号。

c)在系统变量里找到Path变量,这是系统自带的,不用新建。后加上“;%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin”。注意前面的分号。

d)cmd中运行java和javac,没出错就配置成功了。例如:

解释:在window中“ .”指的是当前路径,linux中也是,也就是说从当前目录开始查找class文件(classPath:告诉jvm要使用或者执行的class放在什么路径上)(dos中用echo %path%可以查看环境变量配置)
% % 取JAVA_HOME=....的这个值,不写就是字符串了
Path任何路径下都可以识别java/javac命令
dt.jar是关于运行环境的类库,主要是swing包
tools.jar是关于一些工具类的类库
rt.jar包含了jdk的基础类库
Jdk目录下的src.zip文件:是java提供的API类的源代码压缩文件。
2、jdk jre 之间的区别
Jre:是java runtime environment 的简称,即java运行时环境。主要有java虚拟机,java平台核心类和若干支持文件组成。Jre不包括开发工具、编译器、调试器以及其他工具。
Jre由classLoader(类加载器)负责查找和加载程序引用到基础类库和其他类库。基础类库会自动到rt.jar中加载,操作系统通过path环境变量来操作jre并确定基础类库问价rt.jar的位置。其他类库classLoader在环境变量classPath指定路径中搜索。
Jdk:是java development kit 的简称,即java开发工具包,提供了java的开发环境和运行环境。Jdk中除了包含jre的全部内容以外,还包括开发者用以编译、调试和运行的java的工具:
常见的工具:
Javac.exe 编译器,用于将java源程序转成字节码
Jar.exe 打包工具
Javadoc.exe 文档生成器
Jdb.exe debugger,差错工具
Java.exe 运行编译后的java程序
Javah.exe 可调用java的过程,c过程
Javap.exe java反汇编器
......
如果只需要运行java程序/Applet程序(是一种特殊的java程序,本身不能单独运行,需要嵌入在html中,借助浏览器/appletviewer解释执行),下载安装jre环境即可。如果要自行开发,需要下载jdk,djk中附带有jre环境。
java -version 查看的是系统安装的JDK,它找的路径是path中:C:/WINDOWS/system64/java.exe;
javac -version 查看的是环境变量设置的JDK版本;
3、cmd命令运行java程序
一个java程序,由一个或多个类组成。一个程序只有一个main()主入口方法。
//例如:
public class Test{
public static void main(String[] args){
System.out.println("hello world!");
}
}
把Test.java 在D盘,而Test.class在C盘。而D盘中没有Test.class然后在cmd中:
D:\>set classpath=c: //设置class开始查找的路径,echo %classpath%查看
D:\>java Test
hello world!
//带包的,如果当前目录在D盘,知道.java文件在哪,如果放在D:\盘
package com.cn;
public class Test{
public static void main(String[] args){
System.out.println("hello world!");
}
}方式一:从当前目录开始
D:\>javac -d . Test.java //-d打包,则生成的class,会放在D:\com\cn目录
D:\>java com.cn.Test //即可运行
方式二:指定目录开始
D:\>javac -d D:\myclass Test.java //-d打包,则生成的class,会放在
D:myclass\com\cn目录
D:\>set classpath=D:\myclass
D:\>java com.cn.Test //即可运行
三、Java语言基础
1、java中的标识符
标识符是用于标识某一事物的符号,java程序中的类名、方法名和变量名都属于标识符。
规则:
a)可用英文字母、下划线、$符合数字构成但不能以数字开头(其他特殊字符均不能识别)
b)Java是大小写敏感的,标识符也不例外
c)避开java语言中默认的关键字或保留字
d)标识符没有长度限制
习惯:
类名:每个单词首字母大写,其他小写
接口:每个单词首字母大写,其他小写
方法:以小写字母开头,多个单词,从第二个开始首字母大写
变量:以小写字母开头,多个单词,从第二个开始首字母大写
常量:全部大写,多个单词以_连接
包名:全部小写
2、java中的关键字
| 关键字定义和特点 |
||||
| 定义:被java语言赋予了特殊含义的单词 特点:关键字中所有的字母都是小写 |
||||
| 用于定义数据类型的关键字 |
||||
| void |
byte |
short |
int |
long |
| float |
double |
char |
boolean |
|
| 用于定义数据类型值的关键字 |
||||
| true |
false |
null |
|
|
| 用于定义流程控制的关键字 |
||||
| if |
else |
switch |
case |
default |
| while |
do |
for |
break |
continue |
| return |
|
|
|
|
| 用于定义访问权限的关键字权限 |
||||
| private |
default |
protected |
public |
|
| 定义类、接口、函数、变量修饰符、类与类之间关系的关键字 |
||||
| class |
interface |
abstract |
static |
final |
| synchronized |
extends |
implement |
|
|
| 用于定义建立实例及引用实例、判断实例的关键字 |
||||
| new |
this |
super |
instanceof |
|
| 用于异常处理的关键字 |
||||
| try |
catch |
finally |
throw |
throws |
| 用于包的关键字 |
||||
| package |
import |
|
|
|
| 其他关键字 |
||||
| native |
strictfp |
transient |
volatitle |
assert |
保留字:goto const
3、注释
Java中的注释格式:
•单行注释: 格式: // 注释文字
•多行注释: 格式: /* 注释文字 */
•文档注释: 格式:/** 注释文字 */
4、java中的数据类型
| 基本数据类型 |
对应的包装类 |
占位 |
字节 |
默认值 |
| boolean |
Boolean |
1 |
1 |
false |
| byte |
Byte |
8 |
1 |
(byte)0 |
| char |
Character |
16 |
2 |
\u000 |
| short |
Short |
16 |
2 |
(short)0 |
| int |
Integer |
32 |
4 |
0 |
| long |
Long |
64 |
8 |
0L |
| float |
Float |
32 |
4 |
0.0f |
| double |
Double |
64 |
8 |
0 |
注:整数默认:int 小数默认:double
long a=8888l(L);
float b=8888.88f(F)
char类型采用的是Unicode编码,无论是字母还是中文,在java中都是占用两个字节。
解决double和float精度不准,使用BigDecimal类。前者多用于计算科学/工程计算。后者多用于商业计算。
JDK5.0中其实引用类型中还有一种:就是枚举。枚举就是将新的类型做一个限定。例如:
public enum Sex{
MALE("男"),FEMALE("女");
private final String value;
//构造器默认也只能是private, 从而保证构造函数只能在内部使用
Sex(String value) {
this.value = value;
}
public String getValue() {
return value;
}
public static void main(String[] args) {
System.out.println(Sex.MALE.getValue()); //男
}
}
//这就是枚举,这里是将Sex所有可能的取值都列举到这个枚举中,如果一个属性定义为枚举类型,只能到这个枚举中区寻找他的值!
5、java类型转换
1)自动转换(也叫隐式类型转换)
a)转换双方的类型必须兼容:如:int 和long 兼容 但是和boolean不兼容
b)目标类型比原类型范围要大
2)强制转换(也叫显示类型转换)
语法:(欲转的类型)变量名
常用数字转字符:
方式一:String.valueOf(int a)
方式二:Integer.toString(int a)
方式三:String str = num + "";
6、运算符
1)运算符类型
| 类型 |
描述 |
| 算数运算符 |
+ - * / % ++ -- |
| 关系运算符 |
> >= < <= == != |
| 逻辑运算符 |
! & | ^ && (短路与) ||(短路或) |
| 位运算符 |
~(取反)&(按位与)| ^ >>(右移) <<(左移) >>>(无符号移) |
| 其他运算符 |
= += -= xy:z instanceof new |
2)运算符优先级
| 优先级 |
运算符 |
| 1、分隔符 |
. [] () , ; |
| 2单目运算符 |
+(正) -(负) ~(取反) ! ++ -- |
| 3、创建对象(类型转换) |
New 强制转换 |
| 4、乘/除 |
* / % |
| 5、加/减 |
+ - |
| 6、位移 |
<< >> >>> |
| 7、关系比较 |
< > <= >= instanceof |
| 8、等于/不等于 |
== != |
| 9、按位与 |
& |
| 10、按位异或 |
^ |
| 11、按位或 |
| |
| 12、条件与 |
&& |
| 13、条件或 |
|| |
| 14、三目 |
: |
| 15、赋值 |
= += -= <<= |
3) += 和 + 的区别
x+= y 和 x = x + y 平时是可以互换通用的。但是 += 除了实现了 + 的功能之外还进行了一次强制类型转换
例如: short s = 3;
s += 1; 编译通过
s = s + 1; 编译不通过
因为s+1表达式计算结果为int型,而左边是short型。
4) & 和 &&的区别
&被称为逻辑与,该运算在计算表达式结果时,表达式的每一个操作都要参与计算,然后再得出整个表达式结果。
&&被称为短路与,表达式从左往右计算时,如果发现一个false值,就放弃运算直接将false结果返回。
&&效率高于&
5)i++ 和++i区别
如果i++ 和 ++i 作为一条单独的语句执行是等价的。好比在for循环中for(int i=0;i<10;i++)与for(int i=0;i<10;++i)是等价的
如果i++和++i作为表达式的一部分,就会有差别,++i表示先将变量+1然后再参与计算,而i++是先参加运算再+1
6)其他运算符
a) <<:左移几位其实就是该数据乘以的几次幂
b) >>:右移几位,其实就是该数据除以2的几次幂
例如:最有效率的方式算出2乘以8等于几?
解:2<<3 (2*2³=16)
c) ^ :异或(两个是否相同) 例如:true ^ true=flase
7、break和continue
break:跳出
break作用的范围:要么是switch语句,要么是循环语句。
记住:当break语句单独存在时,下面不要定义其他语句,因为执行不到。
break跳出当前循环
例:
for(int i=0;i<5;i++){
System.out.println("abc"+i);
break;
System.out.println("def"+i); //编译无法通过
}
continue:继续
作用的范围:循环结构。
作用:结束本次循环,继续下次循环。
如果continue单独存在时,下面不要有任何语句,因为执行不到。
break语句:应用范围:选择结构和循环结构。
continue语句:应用于循环结构。
8、数组
1)一维数组
数组的声明方式:
a)int[] arr = new int [长度];arr[0]=1;arr[1]=2......
b)int[] arr ={1,2,3};
c)int[] arr new int[]{1,2,3};
数组的拷贝:
System.arraycopy(源数组,起始位置,目标数组,存放目标数组位置,复制长度);
数组的排序:
a)Arrays.sort(数组对象); //升序排
b)冒泡排序(重要)
原理:一次比较两个,如果他们的顺序错了就把他们位置交换。
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - 1 - i; j++) {
if (arr[j] > arr[j + 1]) { //挨个比,小到大排
int tem = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tem;
}
}
}c)选择排序(重要)
原理:每一趟比较从待排序的数据中选出最大(或最小)的一个元素,按顺序放在已经排好的数列后,直到待排序的数据排完。
for (int i = 0; i < arr.length - 1; i++) {
for (int j = i + 1; j < arr.length; j++) {
if (arr[i] > arr[j]) { //每次挑出最大的,从小到大排
int tem = arr[i];
arr[i] = arr[j];
arr[j] = tem;
}
}
}d)插入排序
原理:将要排序的数组分成两部分,每次从后面的数组部分取出索引最小的数组元素插入到前面的数组部分的适当位置中,通常把数组的第一个元素作为一组,后面的为一组。
e)快速排序:应用到了递归。
f)归并排序、希尔排序、堆排序、基数排序
注:以上都属于内部排序。
(2)二维数组
二维数组的定义方式:
int[][] erw = new int[行数][列数];
注:定义二维数组必须指定其行数,列数可以指定,可以不指定。
数组名后直接加上length(如arr.length),所指的是有几行(Row);
指定索引后加上length(如arr[0].length),指的是该行所拥有的元素,也就是列数目。
9、for each循环
又称强化的for循环,java5新增,在遍历数组、集合的时候,foreach拥有不错的性能。其基本语法如下:
for(元素类型T element:循环对象){语句或块 //循环体}
注:foreach虽然能遍历数组或者集合,但是只能用来遍历,无法在遍历的过程中对数组或者集合进行修改,而for循环可以在遍历的过程中对源数组或者集合进行修改。foreach循环通过iterator实现,使用foreach循环的对象必须实现Iterable接口,所以取到的element没有下标,无法对其进行修改。
第二章 java面向对象基础
一、基础
1、类和对象
类:是对一类相同事物的抽象描述。对象:对象是类的一个具体实例。
注:类的声明仅创建了一个模板,没有创建实际的对象。
类定义格式:
[修饰符] class <类名> {
属性定义:[修饰符] 类型 <属性名> [=初始值]
方法定义:<修饰符> <返回类型> <方法名>([参数列表]){}
构造方法:
}
2、面向对象与面向过程的区别
对于面向过程思想,强调的是过程(动作)。 C语言
举例:冰淇淋装进冰箱
打开冰箱—>存储冰淇淋—>关上冰箱
面向对象
对于面向对象思想,强调的是对象(实体)。
冰箱打开—>冰箱存储—>冰箱关闭
特点:
a)面向对象就是一种常见的思想,符合人们的思考的习惯。
b)面向对象的出现,将复杂的问题简单化。
c)面向对象的出现,让曾经在过程中的执行者,变成了对象中的指挥者。
3、成员变量和局部变量
成员变量:是指在类中的变量,也就是指属性,其作用域是在整个类中有效。成员变量在定义时可以不指定初始值,系统会按其默认原则初始化(但是成员变量被final修饰时为常量,系统不会为它初始化)
局部变量:一般是指在方法体内部定义的变量,其作用域是在方法块内部有效。局部变量在使用是必须先初始化,否则不能通过编译。
注:public、protected、private、static等修饰符可用于修饰成员变量,但是不能修饰局部变量,两者都可以被final修饰。
成员变量存储在堆内存中,局部变量存储在栈内存中。
在类中声明的变量是成员变量,也叫全局变量,放在堆中的。在类中声明的变量即可是基本类型的变量,也可是引用类型的变量:当声明的是基本类型的变量其变量名及其只时放在堆类存中的;当为引用类型时,其声明的变量仍然会存储一个内存地址值,该内存地址值指向所引用的对象。
在方法中声明的变,即该变量是局部变量,每当程序调用方法时,系统都会为该方法建立一个方法栈,其所在方法中声明的变量就放在(方法)栈中,当方法结束系统会释放方法栈,其对应在该方法中声明的变量随着栈的销毁而结束,这就局部变量只能在方法中有效的原因。Java栈上的所有数据都是此线程私有的。
在方法中生明的变量可以是基本类型的变量,也可以是引用类型的变量:当声明是基本类型的变量的时,其变量名及值(变量名及值是两个概念)是放在方法栈中;当声明的是引用变量时,所声明的变量是放在方法的栈中,该变量所指向的对象是放在堆内存中。
4、方法
静态方法:没有this隐式参数(非静态方法中都会有一个隐式参数this)。因为静态方法不能操作对象。虽然操作静态变量或者静态方法,都会使类初始化,但是静态的属性和方法是类的属性和方法,而非静态的属性和方法是对象的属性和方法。
静态方法的用途:静态工厂模式
构造方法的名字必须与类名相同。这一特性的优点是符合Java语言的规范,缺点是类的所有重载的构造方法的名字都相同,不能从名字上区分每个重载方法,不容易根据其名字分辨其功能。静态工厂方法的方法名可以是任意的。new每次都会创建对象,而静态工厂是否创建对象,则取决于里面如何实现的。
例如:
//返回符合中国标准的日历
Calendar cal=Calendar.getInstance(Locale.CHINA);
例如:我们看名字就知道其功能
NumberFormat cf = NumberFormat.getCurrencyInstance(); //货币格式
NumberFormat pf = NumberFormat.getPercentInstance(); //百分比
注:方法什么时候设计为静态,什么时候为非静态?
对象是类的一个实例,各个对象结构相同,只是属性不同。而静态方法是对象无法调用的。所以,静态方法适合那些工具类中的工具方法,这些类只是用来实现一些功能,也不需要产生对象,通过设置对象的属性来得到各个不同的个体。
5、对象的构造

构造方法所完成的主要工作就是帮助新创建的对象赋初值。如果程序中没有声明构造方法,那么系统会自动声明一个无参构造方法。如果有声明构造方法,那么就不会创建默认的构造方法了。
注:构造方法可以是私有,外部无法通过其构造方法产生实例对象。构造方法中可以有return语句。其实void方法后面也可以写return。
6、static关键字
(1)static的特点:
a)static是一个修饰符,用于修饰成员。
b)static修饰的成员被所有的对象所共享。
c)static优先于对象存在,因为static的成员随着类的加载就已经存在了。
d)static修饰的成员多了一种调用的方式,直接可以通过类名调用。
e)static修饰的数据是共享的,对象中存储的是特有数据。
(2)成员变量和静态变量的区别:
a)两个变量的生命周期不同
成员变量随着对象的创建而存在,随着对象的被回收而释放。
静态变量随着类的加载而存在,随着类的消失而消失。
b)调用方式不同。
成员变量只能被对象调用。
静态变量可以被对象调用,还可以被类名调用。
c)别名不同
成员变量(实例变量)
静态变量(类变量)
d)数据存储位置不同。
成员变量数据存储到堆内存的对象中,所以也叫对象的特有数据。
静态变量数据存储在方法区(共享数据区)的静态区,所以也叫对象的共享数据。一个对象修该静态属性值后,会影响其他对象。
e)静态使用的注意事项:
静态方法只能访问静态成员。(非静态既可以访问静态,也可访问非静态)。
静态方法中不可以使用this或者super关键字。
注:main()为程序的主方法,该方法前添加static修饰,是与类相关的。Java解释器运行时将会寻找该方法,因为解释器调用该方法是,还没来得及创建当前类的对象,因此不能定义成与对象相关。这也是为什么主方法是静态的。调用静态方法会使得类被加载。
7、单例设计模式
(1)设计模式:对问题行之有效的解决方式,其实它是一种设计思想。
单例设计模式:
a)解决的问题:就是可以保证一个类在内存中的对象唯一性。
b)必须对于多个程序使用同一个配置信息对象时,就需要保证对象的唯一性。
不允许其他程序用new创建该类对象;在该类中创建一个本类实例;对外提供一个方法让其他程序可以获取该对象。
(2)步骤
a)私有化该类的构造函数。
b)通过new在本类中创建一个本类静态对象。
c)定义一个共有静态方法,将创建的对象返回。
(3)饿汉式和懒汉式
// a)饿汉式
class Single{ // 类一加载,对象就已经存在了。
private Single() {//私有化构造}
private static final Single s = new Single();
public static Single getInstance() {
return s; //返回对象的引用,且引用地址不可修改
}
}
// b)懒汉式
class Single1{
// 类加载进来,没有对象,只能调用getInstance方法时,才会创建对象。延迟加载
private static Single s = null;
private Single() {//私有化构造
}
public static Single getInstance() {
if (s == null) //如果存在就不会创建新的
s = new Single();
return s;
}
}
二、继承
1、继承概述
(1)继承的好处
a)提高了代码的复用性。
b)让类与类之间产生关系,给第三个特征多态提供了前提。
(2)java中支持单继承,不直接支持多继承。
单继承:一个子类只能有一个直接父类。因为多个父类中可能有相同成员,调用会产生不确定性。同时子类能继承父类中所有的的公有属性和公有方法,而隐式的继承继承了私有属性。(当我们去调用子类的构造器时,会默认先实例化父类的无参构造器。如果父类没有无参构造器,只有有参构造器,则子类中构造器中必须显示的指定父类构造器。当调用父类构造器时,父类中不管是共有属性方法,还是私有属性方法都会被加载到内存当中。只是子类对象访问不到父类的私有属性和方法。)
多层继承:java支持多层继承。例如:C继承B,B继承A 就会出现继承体系。
注:类的方法可以被继承,但是类的构造器不能被继承。从构造本身的结构来看,要与类名相同,这一点上就无法实现继承。从本质上看构造方法不属于类的成员。因此不能被子类继承。
2、访问控制
在Java中,可以在类、类的属性以及类的方法前面加上一个修饰符,来对类进行一些访问上的控制。
| 修饰符 |
同一个类中 |
同一个包中 |
子类中 |
全局 |
| private |
Yes |
|
|
|
| default |
Yes |
Yes |
|
|
| protected |
Yes |
Yes |
Yes |
|
| public |
Yes |
Yes |
Yes |
Yes |
3、继承详解
1)实现继承的格式
[修饰符] class 子类名 extends 父类
2)子类继承父类的成员变量
当子类继承了某个类之后,便可以使用父类中的成员变量具体的原则如下:
对于子类可以继承的父类成员变量,如果在子类中出现了同名称的成员变量,则会发生隐藏现象,即子类的成员变量会屏蔽掉父类的同名成员变量。如果要在子类中访问父类中同名成员变量,需要使用super关键字来进行引用。而对于私有变量,子类是无权限访问的。
例如:
public class Parent {
private String sy = "我是父类私有的属性";
public String gy = "我是父类共有的属性";
public static String jt = "我是父类静态的属性";
public final int i = 3; //父类常量
public static final int A = 4; //父类静态常量
}
class Child extends Parent{
private String sy = "我是子类私有的属性";
public String gy = "我是子类共有的属性";
public static String jt = "我是子类静态的属性";
public final int i = 4; //子类常量
public static final int A = 5; //子类静态常量
private String getParent(){
String message = "父类:"+super.gy+" 子类:"+this.gy; //(this可省略)得到父类和子类属性
return message;
}
public static void main(String[] args) {
Parent p = new Child();//p是父类引用,向上转型
System.out.println(p.gy);//我是父类共有的属性
System.out.println(p.jt);//我是父类静态的属性
System.out.println(p.i); //3
System.out.println(p.A); //4
//System.out.println(p.sy); //访问受限,访问不到父类私有属性,private只能在同类中
//System.out.println(p.getParent()); //父类对象中并不存在该方法
System.out.println(new Child().getParent());//父类:我是父类共有的属性 子类:我是子类共有的属性 可以通过super访问到父类的属性,说明继承了父类的属性
}
}
(3)子类继承父类的方法
对于子类可以继承的父类成员方法,如果在子类中出现了同名称的成员方法,则称为覆盖,即子类的成员方法会覆盖掉父类的同名成员方法。如果要在子类中访问父类中同名成员方法,需要使用super关键字来进行引用。
父类声明为final的方法不能被覆盖;
父类声明为static的方法不能被覆盖,只会被隐藏;
注意:隐藏和覆盖是不同的。隐藏是针对成员变量和静态方法的,而覆盖是针对普通方法的。
例如:
public class Parent {
public void jc(){
System.out.println("我是父类的方法");
}
public static void jt(){
System.out.println("我是父类的静态方法");
}
public final void zz(){
System.out.println("我是父类的final方法");
}
private void sy(){
System.out.println("我是父类私有的方法");
}
}
class Child extends Parent{
public void jc(){
System.out.println("我是子类的方法");
}
public static void jt(){
System.out.println("我是子类的静态方法");
}
/*public final void zz(){//编译无法通过
System.out.println("我是父类的final方法");//Cannot override the final method from
}*/
private void sy(){
System.out.println("我是子类私有的方法");
}
public void getMessage(){
super.jc(); //继承了父类的方法
super.jt(); //继承了父类的方法
}
public static void main(String[] args) {
Parent p = new Child();
p.jc(); //我是子类的方法 ---父类方法被覆盖
p.jt(); //我是父类的静态方法 ---没有被覆盖
//p.sy(); //访问不到
new Child().sy(); //我是子类私有的方法
new Child().getMessage();//我是父类的方法//我是父类的静态方法
}
}
4、this关键字解析
Java为了解决变量名冲突和不确定性的问题,而引入了关键字this。This代表当前类的一个实例(该类的对象)
具体使用情况:
- 返回调用当前方法的对象的引用 return this
- 在构造方法中调用当前类中的其它构造方法
- 当前方法参数名和成员变量名相同时,用this区分参数名和成员变量名
//举例:
public class A{
String name;
public A test(){
return this;//这里的this就代表这个类的对象
}
public A (String name){
this();//这里调用了无参构造
this.name = name;
}
}
return this; 对于 A a1 = new A(); this 代表a1
A a2 = new A(); this 代表a2
this()代表无参构造
this(参数)代表有参构造
this.属性 代表成员变量名
//注:不能在构造函数之外的任何函数中调用构造函数,在一个构造函数中只能调用一个构造函数,且必须处于起始位置。
注:由于this是指向当前类的实例的引用,因此只能够在实例方法的定义体内使用它,在类方法中,用关键字static声明的方法,不能使用this
5、super关键字
Super代表父类的实例。在子类中使用super可以调用其父类的方法、属性和构造方法(包括父类中被子类覆盖的方法或属性,被覆盖了用才有意义)
Super具体使用情况:
- 调用父类中的构造方法
- 调用父类中的方法和属性
举例:super()表示父类中的无参构造
Super(参数)表示父类中的有参构造
注:如果父类中没有对应的构造方法,将会产生编译错误
Super.方法名() super.属性名
注意:在子类的构造函数中会默认先调用父类的构造函数,若是父类没有默认无参构造函数,则会需要子类中调用父类的相应的构造否则会报错。
问:Java中this()和super能否同时出现在子类的一个构造函数中?
不能。Java中规定this()和super()必须放在构造函数第一行,而第一行只有一个。
6、方法的重载与重写
(1)方法的重写(覆盖):子类继承父类可以继承父类中的属性和方法,当子类从父类继承的方法不能够满足子类需要的时候,可以在子类中对其进行改写。方法重写需要注意:
a)子类中重写的方法要和父类中被覆盖的方法具有相同的方法名、参数和返回类型
b)子类中重写的方法不能使用比父类被覆盖的方法具有更为严格的访问权限
父类中的方法是publicà子类中重写的方法只能是public
父类中的方法是protected子类中重写的方法可以是public也可以是protected当子类
对从父类中继承的方法进行重写以后,当前子类对象再调用这个方法的时候,调用的就是子类中重写后的方法。
(2)方法的重载:在一个类中可以有多个方法名相同的方法,但是这多个方法名相同的方法参数列表不能相同。
方法重载需要注意:
a)在同一个类中
b)重载的多个方法,方法名相同,返回类型可以相同也可以不同,参数列表必须不同(参数的个数不同、参数对应的类型不同),访问权限可以相同也可以不同
c)在调用方法时,是根据给定的实际参数的类型来识别调用的是哪个方法。
(3)方法的重写和重载比较:
|
|
方法重写 |
方法重载 |
| 定义 |
在子类中对父类的方法进行改写 |
在一个类中可以定义多个方法名相同的方法 |
| 涉及的类 |
子类和父类 |
当前一个类 |
| 方法名 |
子类中重写的方法名要和父类中被覆盖的方法名一致 |
本类中的多个方法名要相同 |
| 参数列表 |
参数列表必须相同 |
参数列表必须不同(个数或者对应类型) |
| 返回类型 |
返回类型必须一致 |
可以相同也可以不同 |
| 访问权限 |
子类中重写的方法不能够使用比父类中被覆盖方法更为严格的权限 |
访问权限没有限制 |
三、抽象类和接口
1、抽象类
有abstract关键字修饰,允许包含未实现方法的类(将方法的设计和方法的实现分离),抽象类为所有子类提供了一个通用的模板,子类可以在这个模板基础上进行扩展。通过抽象类可避免子类设计的随意性。
定义格式:
[修饰符] abstract class <类名>{
[属性定义]
[构造方法定义]
[abstract] [方法声明]
}
使用规则:
抽象类不能实例化,即不能创建对象,只能作为父类用于被继承
子类继承一个抽象类后,必须要实现父类中所有的抽象方法,否则也要定义为抽象类
抽象类中可以包含抽象方法,也可以不包含抽象方法,但是包含一个抽象方法的类必须是抽象类
抽象方法只需要声明不需要实现(不能有方法体)
抽象方法不可以使用final修饰
<1>抽象类中有构造函数吗?
有,用于给子类对象进行初始化。
<2>抽象类可以不定义抽象方法吗?
可以的,但是很少见,目的就是不让该类创建对象。
看到一个比较形象的比喻:张三是个人,人是动物,这里面张三是对象,人是类,动物就是个抽象类,你怎么去实例化一个动物?让他长成什么样?这样想抽象类不能直接实例化,其实这样的定义规则是符合我们的逻辑思维的。虽然不能直接实例化,但是可以通过父类的引用来指向子类的实例来间接地实现父类的实例化因为子类要实例化前,一定会先实例化他的父类。
2、接口
接口是方法声明和常量值定义的集合,接口可以理解为一个标准,其他类可以遵循该标准做不同的实现。
定义格式:
[修饰符] interface <接口名>{
[public static final缺省后会自动补全][常量声明]
[public abstract缺省时会自动补全][方法声明]
}
接口中的属性和方法声明必须是public访问权限(即使不写默认也是)
注:由于接口中的属性属于常量定义,因此定义属性时必须显示指定初始值,不能使用默认初始化的形式
接口使用规则:
接口只包含方法声明和常量定义,即使定义普通属性,在编译后也将变常量
当其他类实现该接口时,接口中定义的方法都要实现
一个类可以实现多个接口,定义接口时可以使用继承,接口之间允许多继承
接口多实现:
一个类可以实现多个接口
class Demo implements A,B,C
接口之间存在多继承:
interface C extends A,B
四、多态
1、多态的概念
多态:从字面意思上理解,就是事物存在着多种体现形态。
在java语言中,多态:主要是指对象变量的多态,即一个A类型的变量既可以指向A类的对象,又可以指向其子类的对象。简而言之就是多态的出现使相同父类的事务有不同的结果,从而体现出多种状态,就是多态。
现实中,关于多态的例子:比方说按下 F1 键这个动作,如果当前在 Flash 界面下弹出的就是 AS 3 的帮助文档;如果当前在 Word 下弹出的就是 Word 帮助;在 Windows 下弹出的就是 Windows 帮助和支持。同一个事件发生在不同的对象上会产生不同的结果。
2、向上转型和向下转型
(1)向上转型
父类对象通过子类对象去实例化,实际上就是对象的向上转型。向上转型是不需要进行强制类型转换的,但是向上转型会丢失精度。
Animal animal = new Cat();
(2)向下转型
父类对象转换为子类对象。
Animal a = new Cat(); Cat c =(Cat)a;
注:发生向下转型前一定要先向上转型。这种较多的运用于返回值,调用了别人一个方法,返回一个类型的对象(假如说是Object类),而你想要更加精确的类型(比如String),而且你知道这个转换不会出现问题,这时候就要使用向下类型转换了。
注:一个接口类型变量也可以指向其实现类的实例,这也是多态的表现。Java中借助方法的重写和重载与动态连接构成多态性。
3、多态的作用
消除类型之间的耦合关系。
当父类对象引用变量引用子类对象时,被引用的对象的类型决定了调用的方法,而不是引用变量的类型决定,但是这个被调用的方法必须是在父类中定义过的。
a)成员变量
编译时:参考引用型变量所属的类中的是否有调用的成员变量,有,编译通过,没有,编译失败。
运行时:参考引用型变量所属的类中的是否有调用的成员变量,并运行该所属类中的成员变量。
简单说:编译和运行都看左边。
b)成员函数(非静态的)
编译时:参考引用类型变量所属的类中是否有调用函数,有,编译通过,没有,编译失败。
运行时:参考的是对象所属的类中是否有调用函数。
简单说:编译看左边,运行看右边。
c)静态函数
编译时:参考引用变量所属的类中是否有调用的静态方法。
运行时:参考引用变量所属的类中是否有调用的静态方法。
简单说:编译和运行都看左边。
其实对于静态方法,是不需要对象的,直接类名调用即可。
特别注意:当继承的时候,子类会继承父类的一切属性和方法,但是呢,只有方法支持后期绑定,而成员变量不支持,所以,使用多态的时候,成员变量的调用是和引用的类型保持一致的。方法支持后期绑定,所以对象的实际类型是什么类型就用什么类型里面的方法。[第四章第五章中会分析其真正的原理:在JVM内存机制中,在编译期间都是静态绑定的,JVM只能认出表面。方法和属性唯一不同的是,在非静态方法都会包含一个隐式参数this,this的引用决定了调用的方法,而属性中就不具备这种特性,所以所属性是静态绑定的,而方法是动态绑定的]
案例:
在实际运用中,我们经常看到List list = new ArrayList() ,而不直接用 ArrayList alist = new ArrayList()呢?
public class ListTest {
public static void main(String[] args) {
List list = new ArrayList();
ArrayList arrayList = new ArrayList();
list.trimToSize(); //错误,没有该方法,这里父类的引用只能调用父类的非私有属性和方法(编译时会有静态检查),如果方法被重写了会执行子类重写的。
arrayList.trimToSize(); //trimToSize是子类ArrayList特有的方法
/**如果这个样子:
List a=new ArrayList();
如果List与ArrayList中有相同的属性(如int i),有相同的方法(如void f())
则a.i是调用了List中的i ,属性静态绑定,看的是前面的静态类型,即编译时认为a就是父类类型
a.f()是调用了ArrayList中的f(); 方法执行的是动态绑定。重写了调用子类的,没有重写调用父类的*/
}
}
这样做的好处就是:可以解耦。突然有一天,发现方法还是那些,但是想换个实现方法,如果以前写死了,那么可能就要重构代码了的赋值语句。如果不必引用到子类中特殊的方法,这样的定义方式更有利于维护。通过多态的方式,可以保证子类使用的方法父类全部都定义过了,于是你重新写一个子类,然后用父类的引用指向它,并不需要改原来的代码,改的仅仅是这一行代码。
4、instanceof关键字
instanceof:用于判断对象的具体类型,只能用于引用数据类型的判断。
向下转型,一般使用 instanceof 进行类型判断,防止出现转换异常
public static void method(Animal a) {// Animal a = new Dog();
a.eat();
if (a instanceof Cat){//通常在向下转型前用于健壮性的判断
Cat c = (Cat) a;
c.catchMouse();
} else if (a instanceof Dog) {
Dog d = (Dog) a;
d.lookHome();
} else {
}
}
五、内部类
1、内部类概述
(1)内部类定义:定义在类或者方法中的类称为内部类
(2)内部类访问特点
a)内部类可以直接访问外部类中的成员。
b)内部类提供了更好的封装,外部类要访问内部类,必须建立内部类的对象。
(3)内部类的用途
a)一般用于类的设计。分析事物时,发现该事物描述中还有事物,而且这个事物还在访问描述事物的内容,这是就是还有的事物定义成内部类来描述。
Java内部类其实在J2EE编程中使用较少,不过在窗口应用编程中特别常见,主要用来事件的处理。
2、内部类基础
内部类InnerClass可以对外围类OuterClass的属性和方法进行无缝的访问,尽管它是private修饰的。
public class OuterClass {
private int outerField = 0;
class InnerClass{
void InnerMethod(){
int i = outerField;
}
}
}为什么内部类可以他是可以无限制的访问外围类的所有成员属性和方法,即使是private的?编译这个java文件,我们会发现除了生成了一个OuterClass.class还生成了OuterClass$InnerClass.class。它任然是把他们当做两个类来处理的。使用javap命令查看字节码文件:
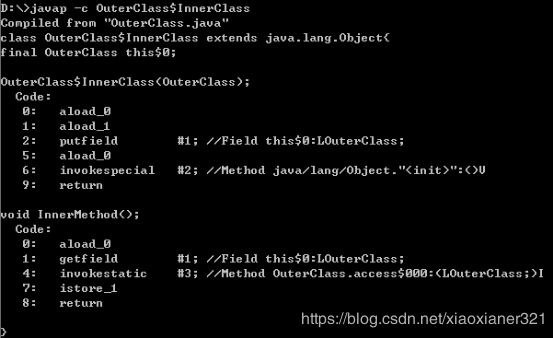

我们发现在内部类中,系统自动加了一个外部类的引用:this$0;并且内部类的构造器中传递了外部类的引用。其次在看外部类,对于私有属性我们看到生成了一个static int access$000(OuterClass)的静态方法,返回了外部类的私有属性值。当我们在内部类调用外部类的私有属性时,我们看到了这个指令:invokestatic指令调用的是access$000()方法,所以内部类:int i = outerField; 实际上是:int i = this$0.access$000(OuterClass);而对于私有方法,也是一样的,也会生成一个静态的方法供内部类调用。
3、内部类种类
内部类按照其所在位置不同,可分为以下几种:
(1)成员内部类(最普通的内部类)
需要等外部类创建了对象以后才会被加载到JVM中,它属于外部类的某个实例,在成员内部类中要注意两点,第一:成员内部类中不能存在任何static的变量和方法;第二:成员内部类是依附于外围类的,所以只有先创建了外围类才能够创建内部类。
public class OuterClass {
private String str;
public void outerDisplay(){
System.out.println("outerClass...");
}
public class InnerClass{//需要等外部类创建了对象以后才会被加载到JVM中
public void innerDisplay(){
//使用外围内的属性
str = "outerClassName";
System.out.println(str);
//使用外围内的方法
outerDisplay();
}
}
/*推荐使用getxxx()来获取成员内部类,尤其是该内部类的构造函数无参数时 */
public InnerClass getInnerClass(){
return new InnerClass();
}
public static void main(String[] args) {
/*OuterClass.InnerClass inner1 = outer. new InnerClass();
inner1.innerDisplay();*/
OuterClass outer = new OuterClass();
OuterClass.InnerClass inner = outer.getInnerClass();
inner.innerDisplay();
}
}(2)方法内部类
方法内部类也有两个特点
a)方法中的内部类没有访问修饰符, 即方法内部类对包围它的方法之外的任何东西都不可见。
b)方法内部类只能够访问该方法中的局部变量,所以也叫局部内部类。而且这些局部变量一定要是final修饰的常量。
class Outer{
public void doSomething(){
final int a =10;
class Inner{
public void seeOuter(){
System.out.println(a); //这里面只能使用局部变量,并且是final的
}
}
}
}这又是为什么呢?
a)我们首先查看Outter的字节码文件,Outter中再也没有返回私有域的隐藏方法了。
b)对Inner类的反射发现,Inner类内部多了一个对beep变量的备份隐藏域:final int val$i;
我们可以这样解释Inner类中的这个备份常量域,首先当JVM运行到需要创建Inner对象之后,Outter类已经全部运行完毕,这是垃圾回收机制很有可能释放掉局部变量beep。那么Inner类到哪去找beep变量呢?
编译器又出来帮我们解决了这个问题,他在Inner类中创建了一个beep的备份 ,也就是说即使Ouuter中的beep被回收了,Inner中还有一个备份存在,自然就不怕找不到了。
但是问题又来了。如果Outter中的beep不停的在变化那。那岂不是也要让备份的beep变量无时无刻的变化。为了保持局部变量与局部内部类中备份域保持一致。 编译器不得不规定死这些局部域必须是常量,一旦赋值不能再发生变化了。所以为什么局部内部类应用外部方法的域必须是常量域的原因所在了。
(3)静态内部类
class Outer{
private static int a = 3;
private static class Inner{
public void test(){
System.out.println(a);
}
}
}静态内部类中无法引用到其外围类的非静态成员。除了静态本身的特性外,我们看内部类的字节码文件。系统默认创建的构造函数中不再传递外部类的引用了。所以静态内部类中无法引用外部类的实例属性或者方法。
(4)匿名类
匿名内部类,就是内部类的简写格式。它没有名字,没有构造,所以匿名内部类只能使用一次。
使用匿名内部类还有个前提条件:必须继承一个父类或实现一个接口
匿名内部类的声明格式如下:
new 父类或者接口(){子类内容}
匿名内部类使用场景:只用到类的一个实例/类在定义后马上用到/类非常小(SUN推荐是在4行代码以下)
interface AInterface {
void show();
}
abstract class BAbstract{
abstract void show2();
}
class Main {
public void getSomething(){
AInterface i = new AInterface(){
public void show(){
System.out.println("show接口实现");
}
};
i.show();
}
public void getShow(final String name){ //匿名内部类使用外部类的形参,必须定义为final的,其原理和方法内部类同
new BAbstract() {
void show2() {
System.out.println("show抽象实现"+name);
}
};
}
}六、包装类
1、基本数据类型对象包装类概述
为了方便操作基本数据类型,并封装成了对象,在对象中定义了属性和行为丰富了该数据的操作。用于描述该对象的类就成为基本数据类型对象包装类。
byte ----- Byte
Short ----- Short
int ----- Integer
long ----- Long
double ----- Double
char ----- Character
Boolean ----- Boolean
注:该包装类主要用于基本类型和字符串之间的转换
2、Integer
Integer 类在对象中包装了一个基本类型 int 的值。Integer 类型的对象包含一个 int 类型的字段。
构造方法
| Integer(int value) |
| Integer(String s) |
常用方法
a)字符串→整数
| static int |
parseInt(String s) |
b)整数→字符串
String类中的valueOf(基本数据类型值)
基本数据类型值+“”
用Integer的静态方法valueOf(基本数据类型值)
c)进制之间的转换
十进制转换其他进制
| static String |
|
| static String |
|
| static String |
|
| static String |
|
其他进制数转换为10进制数
| static int |
parseInt(String s, int radix) |
d)其他方法
| int |
intValue() |
| long |
longValue() |
3、JDK1.5自动装箱拆箱
Integer i=4; //i=new Integer(4);自动装箱,简化书写
i=i+5;//i自动拆箱为基本数据类型4
System.out.println(i);
注:Integer i=4;4会自动装箱,成为一个对象
i=i+5; i+5:i自动拆箱(i.intValue()),变成int型,和5进行运算,再自动装箱赋给左边的i
Integer a=new Integer(127);
Integer b=new Integer(127);
System.out.println("a==b:"+(a==b)); //flase
System.out.println("a.equals(b):"+a.equals(b));//true
Integer x=127;
Integer y=127;
System.out.println("x==y:"+(x==y));//true
System.out.println("x.equals(y):"+x.equals(y)); //true
Integer m=128;
Integer n=128;
System.out.println("m==n:"+(m==n));//false
System.out.println("m.equals(n):"+m.equals(n));//true
JDK1.5以后,自动装箱,如果装箱的是一个字节(-128-127),那么该数据会被共享不会重新开辟空间。
七、字符串
1、String类
a)字符串对象一旦被初始化就不会被改变。
b)字符串常量的特点:常量池中没有就建立,有就直接用。
String s="abc"; //”abc”存储在字符串常量池中。
String s1="abc"; //如果有“abc”字符串,就直接使用,不创建,如果没有,则创建。
System.out.println(s==s1);//true
<2>创建String对象时String s = new String(“abc”)和String s = “abc”;有何区别?
String s = “abc”;直接使用字面常量定义字符串(若常量池中有)s会引用常量池中的对象。
String s = new String(“abc”)创建的字符串并不是常量,不能在编译期就确定,并且不放在常量池,他们有自己的地址空间。(堆里面)
注:Java为了加强程序的运行速度,因此设计了两种不同的方法来生成字符串对象。Java为String类型提供了缓冲池机制(常量池),使用双引号定义对象时java环境首先会去字符串缓冲池中寻找相同内容的字符串,如果有就直接拿,没有就创建一个新的字符串放在常量池中。
举例:
a)String str = new String (“abc”);创建了几个对象
一般是两个[abc new String]。(或者一个。若常量池中有abc就一个,这里不考虑)
b)String s = new String(“abc”)+ new String(“abc”)
创建了4个[abc 、new Strng(两次,两个)、s(abcabc)]
c)String s = new String(“1”+“2”);
创建了2个[12、s] 因为“1”和“2”都是字母常量,编译器就会自动优化处理。代表一个字符串“12”。
<3>String类常用的方法
| int |
length() 返回此字符串的长度。 |
| char |
charAt(int index) 根据位置获取位置上的某个字符。 |
| int |
indexOf(int ch) 返回指定字符第一次出现处的位置。 |
| int |
indexOf(String str) 返回指定子字符串第一次出现处的位置。 |
| int |
lastIndexOf(int ch) 返回指定字符最后一次出现处的索引。 |
| int |
lastIndexOf(String str) 返回指定子字符串最右边出现处的索引。 |
| String |
substring(int beginIndex) 返回一个新的字符串,它是此字符串的一个子字符串。(从指定位置到结尾) |
| String |
substring(int beginIndex, int endIndex) 返回一个新字符串,它是此字符串的一个子字符串。(包含头,不包含尾) |
| boolean |
equals(Object anObject) 将此字符串与指定的对象比较。 |
| boolean |
equalsIgnoreCase(String anotherString) 将此 String 与另一个 String 比较,不考虑大小写。 |
| boolean |
contains(CharSequence s) 判断该字符串中是否包含某一个子串 |
| boolean |
isEmpty() 当且仅当 length() 为 0 时返回 true。 |
| boolean |
startsWith(String prefix) 测试此字符串是否以指定的前缀开始。 |
| boolean |
endsWith(String suffix) 测试此字符串是否以指定的后缀结束。 |
| byte[] |
getBytes(String charsetName) 字符串→字节数组。 |
| String |
toUpperCase() 将字符串→大写。 |
| String |
toLowerCase() 将字符串→小写。 |
| String |
trim() 将字符串两端的空格去除。 |
| int |
compareTo(String anotherString) 按字典顺序比较两个字符串。 |
2、StringBuffer和StringBuilder
1)StringBuffer
就是字符串缓冲区,用于存储数据的容器。
<1>特点
a)长度是可变的。
b)可以存储不同类型的数据。
c)最终要转成字符串进行使用。
d)可以对字符串就行修改。
<2>常用方法
| StringBuffer |
append(数据类型 变量量)追加变量 |
| StringBuffer |
insert(int offset, 数据类型 变量) 在指定位置插入变量。 |
| StringBuffer |
delete(int start, int end) 移除此序列的子字符串中的字符(包含头,不包含尾)。 |
| StringBuffer |
deleteCharAt(int index) 移除此序列指定位置的 char。 |
| StringBuffer |
replace(int start, int end, String str) 使用给定 String 中的字符替换此序列的子字符串中的字符。 |
| void |
setLength(int newLength) 设置字符序列的长度。 |
| StringBuffer |
reverse() 将此字符序列用其反转形式取代。 |
2)StringBuilder
使用String连接字符串,每次都会构建一个新的对象。而使用StringBuilder类就可以避免浪费空间。StringBulider是在JDK5.0中引入的。StringBuffer和StringBuffer(允许采取多线程的方式执行添加或删除字符串操作,因为它对方法加了同步锁)都继承自AbstractStringBuilder类。如果一个字符串在单线程中编辑,用StringBuilder比StringBuffer效率高。
八、其他常用类
1、System类
1)System:类中的方法和属性都是静态的。
常见方法:
| static long |
currentTimeMillis() |
| static Properties |
getProperties() |
|
|
|
| static void |
exit(int status) |
| static String |
setProperty(String key, String value) |
2)Properties类
常用方法
| String |
getProperty(String key) |
| Set |
stringPropertyNames() |
例:SystemDemo.java
import java.util.Iterator;
import java.util.Properties;
import java.util.Set;
public class SystemDemo {
public static void main(String[] args) {
System.setProperty("mypath", "C:\\myclass");
Demo_2();
System.out.println(System.getProperty("user.dir"));
}
public static void Demo_2() {
Properties prop = System.getProperties();
Set nameSet = prop.stringPropertyNames();
// 高级for
for (String name : nameSet) {
String value = prop.getProperty(name);
System.out.println(name + "=" + value);
}
// 迭代器
// Iterator it=nameSet.iterator();
// while(it.hasNext())
// {
// String key=it.next();
// String value=prop.getProperty(key);
// System.out.println(key+"="+value);
// }
}
public static void Demo_1() {
long time = System.currentTimeMillis();
System.out.println(time);
}
}
2、系统属性信息
| 键 |
相关值的描述 |
| java.version |
Java 运行时环境版本 |
| java.vendor |
Java 运行时环境供应商 |
| java.vendor.url |
Java 供应商的 URL |
| java.home |
Java 安装目录 |
| java.vm.specification.version |
Java 虚拟机规范版本 |
| java.vm.specification.vendor |
Java 虚拟机规范供应商 |
| java.vm.specification.name |
Java 虚拟机规范名称 |
| java.vm.version |
Java 虚拟机实现版本 |
| java.vm.vendor |
Java 虚拟机实现供应商 |
| java.vm.name |
Java 虚拟机实现名称 |
| java.specification.version |
Java 运行时环境规范版本 |
| java.specification.vendor |
Java 运行时环境规范供应商 |
| java.specification.name |
Java 运行时环境规范名称 |
| java.class.version |
Java 类格式版本号 |
| java.class.path |
Java 类路径 |
| java.library.path |
加载库时搜索的路径列表 |
| java.io.tmpdir |
默认的临时文件路径 |
| java.compiler |
要使用的 JIT 编译器的名称 |
| java.ext.dirs |
一个或多个扩展目录的路径 |
| os.name |
操作系统的名称 |
| os.arch |
操作系统的架构 |
| os.version |
操作系统的版本 |
| file.separator |
文件分隔符(在 UNIX 系统中是“/”) |
| path.separator |
路径分隔符(在 UNIX 系统中是“:”) |
| line.separator |
行分隔符(在 UNIX 系统中是“/n”) |
| user.name |
用户的账户名称 |
| user.home |
用户的主目录 |
| user.dir |
用户的当前工作目录 |
注:当代码在本地则为本地属性,当代码部署在服务器上时则获取的是服务器系统属性
3、Runtime类
Runtime:没有构造方法,说明该类不能创建自己的 Runtime 类实例。
又发现还有非静态方法,说明该类提供静态的返回该类对象的方法,而且只有一个,说明Runtime类使用了单例设计模式。
常用方法
| static Runtime |
getRuntime() |
| Process |
exec(String command) |
exec(“软件 文件”);
Process类
| abstract void |
destroy() |
//例: Demo01.java
public class Demo01 {
public static void main(String[] args) throws IOException {
Runtime r = Runtime.getRuntime();
Process p1 = r.exec("F:\\Program Files\\KuGou2012\\KuGou.exe"); //打开酷狗软件
Process p2 = r.exec("notepad.exe C:\\Users\\dell\\Desktop\\新建文本文档.txt"); //使用notepad软件打开文件
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
p1.destroy(); //只能关闭由它开启的线程。
p2.destroy();//关闭文件
}
}
//调用cmd命令
//比如定时关机
//Runtime.getRuntime().exec("shutdown -s -t 600");
4、Math类
Math 类包含用于执行基本数学运算的方法,都是静态的。
常用方法
| static 数据类型 |
abs(数据类型 a) |
| static double |
ceil(double a) |
| static double |
floor(double a) |
| static double |
random() |
| Static 数据类型 |
max(数据类型a, 数据类型b) |
| Static 数据类型 |
min(数据类型 a, 数据类型 b) |
| static double |
pow(double a, double b) |
| static double |
random() |
| static double |
log(double a) |
| static double |
exp(double a) |
类 Random
| double |
nextDouble() |
| int |
nextInt() |
| int |
nextInt(int n) |
5、Date类
1)构造方法
|
|
|
|
|
|
2)日期对象和毫秒值之间的转换
毫秒值——>日期对象
a) 通过Date对象的构造方法
|
|
|
Date d1=new Date(System.currentTimeMillis());
System.out.println(d1);
b)再通过毫秒值转为日期
| void |
setTime(long time) |
因为可以通过Date对象的方法对该日期中的各个字段(年 月 日)进行操作。
3)日期对象——>毫秒值
| long |
getTime() |
因为可以通过具体的数值进行运算。
练习:
2012-3-17到2012-4-6中间有多少天?
思路:
两个日期相减就行了。
必须有两个可以减法运算的数。
能减得是毫秒值,可以通过Date对象获取毫秒值。
//DateTest3.java
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class DateTest3 {
public static void main(String[] args) throws ParseException {
String str_date1 = "2012-3-17";
String str_date2 = "2012-4-6";
DateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd");// 自定应格式
// dateFormat=DateFormat.getDateInstance();//系统带有的格式
Date date1 = dateFormat.parse(str_date1);
Date date2 = dateFormat.parse(str_date2);
long time1 = date1.getTime();
long time2 = date2.getTime();
long time = time2 - time1;
System.out.println(time / 1000 / 60 / 60 / 24);
}
}
6、DateFormat类
1)DateFormat类-日期对象转成字符串
从 JDK 1.1 开始,应该使用 Calendar 类实现日期和时间字段之间转换,使用 DateFormat 类来格式化和解析日期字符串。Date 中的相应方法已废弃。
DateFormat中常用方法
| static DateFormat |
getDateInstance() |
| static DateFormat |
getDateInstance(int style) |
| static DateFormat |
getDateTimeInstance() |
| static DateFormat |
getDateTimeInstance(int dateStyle, int timeStyle) |
| static DateFormat |
getTimeInstance() |
| static DateFormat |
getTimeInstance(int style) |
对日期对象进行格式化
将日期对象——>日期格式字符串
使用的是DateFormat类中的format方法。
将日期对象——>指定的显示格式,使用的是DateFormat子类SimpleDateFormat类中的构造函数
| 构造方法摘要 |
|
|
|
|
DateTest.java
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
public class DateTest {
public static void main(String[] args) {
Date date = new Date();
// 获取日期对象,具备着默认的风格。
DateFormat dateFormat = DateFormat.getDateInstance(DateFormat.FULL);// 2013年1月18日星期五
dateFormat = DateFormat.getDateTimeInstance(DateFormat.FULL,
DateFormat.FULL);// 2013年1月18日 星期五 下午02时57分01秒 CST
// 如果风格是自定义的如何让解决?
dateFormat = new SimpleDateFormat("yyyy--MM--dd");// 2013--01--18
String str_date = dateFormat.format(date);
System.out.println(str_date);
}
}
2)DateFormat类-字符串转成日期对象
使用的是DateFormat类中的parse()方法
DateTest2.java
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class DateTest2 {
public static void main(String[] args) throws ParseException {
Method_3();
}
// 系统默认风风格解析
public static void Method_1() throws ParseException {
String str_date = "2013-1-18";
DateFormat dateFormat = DateFormat.getDateInstance();
Date date = dateFormat.parse(str_date);
System.out.println(date);
}
// 系统含有的方法
public static void Method_2() throws ParseException {
String str_date = "2013年1月18日";
DateFormat dateFormat = DateFormat.getDateInstance(DateFormat.LONG);
Date date = dateFormat.parse(str_date);
System.out.println(date);
}
// 自定义风格解析
public static void Method_3() throws ParseException {
String str_date = "2013:1:18";
DateFormat dateFormat = new SimpleDateFormat("yyyy:MM:dd");
Date date = dateFormat.parse(str_date);
System.out.println(date);
}
}7、Calendar类
它是一个抽象类
常用方法
| static Calendar |
getInstance() |
Calendar对象存储的是键值对
根据键取值
| int |
get(int field) |
| abstract void |
add(int field, int amount) |
| void |
set(int year, int month, int date) |
获取某一年中2月的天数
//CalendarDemo.java
import java.util.Calendar;
public class CalendaDemo {
public static void main(String[] args) {
Calendar calendar = Calendar.getInstance();
showDays(2017);
}
public static void showDays(int year) {//获取某一年中二月份的天数
Calendar calendar = Calendar.getInstance();
calendar.set(year, 2, 1);
calendar.add(Calendar.DAY_OF_MONTH, -1);
show_date(calendar);
}
public static void show_date(Calendar calendar) {
int year = calendar.get(Calendar.YEAR);
int month = calendar.get(Calendar.MONTH) + 1;
int day = calendar.get(Calendar.DAY_OF_MONTH);
String week = getWeek(calendar.get(Calendar.DAY_OF_WEEK));
System.out.println(year + "年" + month + "月" + day + "日" + week);
}
public static String getWeek(int i) {
String week[] = { "", "星期日", "星期一", "星期二", "星期三", "星期四", "星期五", "星期六" };
return week[i];
}
}
万年历
import java.util.Calendar;
import java.util.Scanner;
public class YearCalendar {
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
System.out.println("************【欢迎使用万年历】************");
System.out.println("请输入年份:");
int year = scan.nextInt();
System.out.println("请输入月份:");
int month = scan.nextInt();
printCalendar(year, month);
}
public static void printCalendar(int year, int month) {
Calendar c = Calendar.getInstance();
int num = getTotalDays(year, month);
c.set(Calendar.YEAR, year);
c.set(Calendar.MONTH, month - 1);
c.set(Calendar.DAY_OF_MONTH, 1);
System.out.println("-------------【" + year + "年" + month
+ "月日历】--------------------");
System.out.println("星期天\t星期一\t星期二\t星期三\t星期四\t星期五\t星期六");
int weekDay = c.get(Calendar.DAY_OF_WEEK) - 1;
for (int i = 0; i < weekDay; i++) {
System.out.print("\t");
}
for (int i = 0; i < num; i++) {
System.out.print(c.get(Calendar.DAY_OF_MONTH) + "\t");
if (c.get(Calendar.DAY_OF_WEEK) == 7) {
System.out.println();
}
c.add(Calendar.DAY_OF_WEEK, 1);
}
}
public static int getTotalDays(int year, int month) {
if (month > 12 || month < 1) {
throw new RuntimeException("月份不正确!");
}
if (month == 1 || month == 3 || month == 5 || month == 7 || month == 8|| month == 10 || month == 12) {
return 31;
} else if (month == 4 || month == 6 || month == 9 || month == 11) {
return 30;
}
if (isRunYear(year)) {
return 29;
} else {
return 28;
}
}
public static boolean isRunYear(int year) {
if (year % 400 == 0 || year % 4 == 0 && year % 100 != 0) {
return true;
} else {
return false;
}
}
}
8、Scanner
一个可以使用正则表达式来解析基本类型和字符串的简单文本扫描器。
Scanner scan = new Scanner(System.in);
| 构造方法摘要 |
|
|
|
|
| String |
next() |
| boolean |
nextBoolean() |
| byte |
nextByte() |
| double |
nextDouble() |
| float |
nextFloat() |
| int |
nextInt() |
| String |
nextLine() |
| long |
nextLong() |
| short |
nextShort() |
第三章、java虚拟机体系结构
一、java虚拟机概述
Java虚拟机,之所以被称之为“虚拟”的,就是因为它仅仅是由一个规范来定义的抽象计算机。要运行java程序,首先就要符合该规范的具体实现。在java程序运行时,为了方便管理,将数据区域划分为:方法区、堆、java栈、pc寄存器和本地方法栈。
二、方法区
1、方法区概述
方法区存储被装载类型的信息,所有的线程都共享方法区。(方法区)又叫静态区,存放所有的①类(class)②静态变量(static变量)③静态方法④常量⑤成员方法等。
具体存储以下类型信息:
类的基本信息:
<1>这个类型的全限定名
<2>这个类型的直接超类的全限定名(例如Object 的全限定名:java.lang.Object)
<3>这个类型是类类型还是接口类型
<4>这个类的访问修饰符(public、abstract或者final的某个子集)
<5>任何直接超类的全限定名的有序列表
注:在class文件中所有的点(“.”)都被替换斜杠(“/”)代替
已装载类的详细信息:
<6>常量池:该类型所用的常量的一个有序的集合,池中的数据项就像数组一样是通过索引访问的(常量池是方法区中的一个数据结构)
<7>字段信息:即类成员变量信息,字段名、字段类型、字段修饰符
<8>方法信息:方法名、返回类型、方法参数数量和类型、方法修饰符
<9>类(静态)变量:虚拟机在使用某个类之前,必须在方法区中为这些类变量分配空间。
一个类中,一个static变量只会有一个内存空间,虽然有多个类实例,但这些类实例中的这个static变量会共享同一个内存空间。
<10>指向ClassLoader类的引用
<11>指向Class类的引用:可以使用forName()来得任何包中任何类型的Class对象的引用。
[反射基础:在装载类的时候,加入方法区中的所有信息,最后都会形成Class类的实例,代表这个被装载的类。方法区中的所有的信息,都是可以通过这个Class类对象反射得到。我们知道对象是类的实例,类是相同结构的对象的一种抽象。同类的各个对象之间,其实是拥有相同的结构(属性),拥有相同的功能(方法),各个对象的区别只在于属性值的不同。同样的,我们所有的类,其实都是Class类的实例,他们都拥有相同的结构-----Field数组、Method数组。而各个类中的属性都是Field属性的一个具体属性值,方法都是Method属性的一个具体属性值。]
<12>方法表:为每个装载的非抽象类,都生成一个方法表等。
方法区中存放的都是在整个程序中永远唯一的元素。这也是方法区被所有的线程共享的原因。方法区的大小由-XX:PermSize和-XX:MaxPermSize来调节,类太多有可能撑爆永久代。静态变量或常量也有可能撑爆方法区。
注:静态成员变量和常量的区别: 静态成员变量本质是变量(没有静态变量:方法内的局部变量是不允许存在访问权限修饰的,不用创建任何实例对象,静态变量就会被分配空间,如果把静态变量定义在成员函数内,岂不是静态变量归类的某个对象所有),是整个类所有对象共享的一个变量,其值一旦改变对这个类的所有对象都有影响;常量一旦赋值后不能修改其引用,其中基本数据类型的常量不能修改其值。
2、运行时常量池
程序运行期间,静态存储的数据将随时等候调用。可用static关键字指出一个对象的特定元素是静态的。但Java对象本身永远都不会置入静态存储空间。常量池这个区域属于方法区。用于保存在编译期已确定的、已编译的class文件中的一份数据。该区域存放类和接口的常量[也包括字符串常量,如String s = "java"这种申明方式],除此之外,它还存放成员变量和成员方法的所有引用。当一个成员变量或者成员方法被引用的时候,JVM就通过运行常量池中的这些引用来查找成员变量和成员方法在内存中的的实际地址。
扩展:jdk:1.6 1.7 1.8 常量池的位置变化,但是不影响后面的理解
//运行如下代码,探究常量池中的位置
public static void main(String[] args){
List list = new ArrayList();
int i=0;
while(true){
list.add(String.valueOf(i++));
}
} 如果是jdk1.6
运行前在myeclipse中首先设置永久代(PermGen)的内存大小:-XX:PermSize=10M -XX:MaxPermSize=10M,运行后:Exception in thread “main” java.lang.OutOfMemoryError:PermGen space的内存溢出异常,表示永久代内存溢出。

如果是jdk1.7
设置参数:-Xmx20m -Xms20m -XX:-UseGCOverheadLimit,这里的-XX:-UseGCOverheadLimit是关闭GC占用时间过长时会报的异常,然后限制堆的大小,运行程序,果然,一会后报异常: Exception in thread “main” java.lang.OutOfMemoryError: Java heap space 从上面的异常可以知道我们测试增加的常量都放到了堆中,所以限制堆内存以后,不断增加常量,堆内存会溢出。
注:在Java7之前,HotSpot虚拟机中将GC分代收集扩展到了方法区,使用永久代来实现了方法区。这个区域的内存回收目标主要是针对常量池的回收和对类型的卸载。但是在之后的HotSpot虚拟机实现中,逐渐开始将方法区从永久代移除。Java7中已经将运行时常量池从永久代移除,在Java 堆(Heap)中开辟了一块区域存放运行时常量池。而在Java8中,已经彻底没有了永久代,将方法区直接放在一个与堆不相连的本地内存区域,这个区域被叫做元空间。
三、堆
1、堆
一种通用的内存池,也位于RAM当中。java的堆是一个运行时的数据区,用来存储数据的单元,存放通过new关键字新建的对象和数组,对象从中分配内存。java运行时所创建的实例或者数组都放在同一个堆中,一个java程序独占一个java虚拟机实例,每个java程序都有自己的堆空间。在堆中声明的对象,是不能直接访问的,必须通过在栈中声明的指向该引用的变量来调用。引用变量就相当于是为数组或对象起的一个名称,以后就可以在程序中使用栈中的引用变量来访问堆中的数组或对象。
“堆”最吸引人的地方在于编译器不必知道要从堆里分配多少存储空间,也不必知道存储的数据要在堆里停留多长的时间。因此,用堆保存数据时会得到更大的灵活性。当然,为达到这种灵活性,必然会付出一定的代价:在堆里分配存储空间时会花掉更长的时间。在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。
堆所占内存的大小由-Xmx指令和-Xms指令来调节
2、引用类型变量和对象的区别
例如:String str = new String("abc");
声明的对象是在堆内存中初始化的, 真正用来存储数据的。不能直接访问。
引用类型变量[str]是保存在栈当中的,一个用来引用堆中对象的符号(指针)而已。
四、栈
1、栈
位于RAM当中,通过堆栈指针可以从处理器获得直接支持。堆栈指针向下移动,则分配新的内存;向上移动,则释放那些内存。这种存储方式速度仅次于寄存器[寄存器:最快的存储区,位于处理器内部,但是数量极其有限。所以寄存器根据需求进行自动分配,无法直接人为控制。
Java栈:以帧为单位保存线程的运行状态。Java虚拟机只会直接对java栈执行两种操作:以帧为单位的压栈或出栈。在执行方法时,他使用当前帧来存储参数、局部变量、中间运算结果等数据[Java方法可以以两种方式完成,一种通过return返回的,成为正常的返回。一种是通过异常抛出的异常中止]。
Java栈上的所有数据都是此线程私有的。任何线程都不能访问另一个线程的栈数据。
Java栈所占内存的大小由Xss来调节,方法调用层次太多会撑爆这个区域。
2、Java栈的组成
Java栈部分组成:局部变量区、操作数栈、动态连接和返回地址等。局部变量区和操作数栈的大小视对应的方法而定,编译器在编译时就确定了这些值并且放在class文件中,而帧数据区的大小依赖于具体的实现。
局部变量区:调用方法时,将方法的局部变量组成一个数组,通过索引来访问。若为非静态方法,则加入一个隐含的引用参数this,该参数指向调用这个方法的对象。而静态方法则没有this参数。因此,对象无法调用静态方法。
局部变量表是一组变量值存储空间,用于存放方法参数和方法内部定义的局部变量。在Java程序编译为Class文件时,就在方法表的Code属性的max_locals数据项中确定了该方法需要分配的最大局部变量表的容量。
在方法执行时,虚拟机是使用局部变量表完成参数变量列表的传递过程,如果是实例方法,那么局部变量表中的每0位索引的Slot默认是用于传递方法所属对象实例的引用,在方法中可以通过关键字“this”来访问这个隐含的参数,其余参数则按照参数列表的顺序来排列,占用从1开始的局部变量Slot,参数表分配完毕后,再根据方法体内部定义的变量顺序和作用域来分配其余的Slot。局部变量表中的Slot是可重用的,方法体中定义的变量,其作用域并不一定会覆盖整个方法,如果当前字节码PC计算器的值已经超出了某个变量的作用域,那么这个变量对应的Slot就可以交给其它变量使用。
局部变量不像前面介绍的类变量那样存在“准备阶段”。类变量有两次赋初始值的过程,一次在准备阶段,赋予系统初始值;另外一次在初始化阶段,赋予程序员定义的值。因此即使在初始化阶段程序员没有为类变量赋值也没有关系,类变量仍然具有一个确定的初始值。但局部变量就不一样了,如果一个局部变量定义了但没有赋初始值是不能使用的。]
操作数栈:也是一个数组,但是通过栈操作来访问。所谓操作数是那些被指令操作的数据。当需要对参数操作时如a=b+c,就将即将被操作的参数压栈,如将b 和c 压栈,然后由操作指令将它们弹出,并执行操作。虚拟机将操作数栈作为工作区。
[操作数栈也常被称为操作栈,它是一个后入先出栈。同局部变量表一样,操作数栈的最大深度也是编译的时候被写入到方法表的Code属性的max_stacks数据项中。操作数栈的每一个元素可以是任意Java数据类型,包括long和double。32位数据类型所占的栈容量为1,64位数据类型所占的栈容量为2。栈容量的单位为“字宽”,对于32位虚拟机来说,一个”字宽“占4个字节,对于64位虚拟机来说,一个”字宽“占8个字节。
当一个方法刚刚执行的时候,这个方法的操作数栈是空的,在方法执行的过程中,会有各种字节码指向操作数栈中写入和提取值,也就是入栈与出栈操作。例如,在做算术运算的时候就是通过操作数栈来进行的,又或者调用其它方法的时候是通过操作数栈来行参数传递的。]
动态连接:每个栈帧都包含一个指向运行时常量池中该栈帧所属性方法的引用,持有这个引用是为了支持方法调用过程中的动态连接。在Class文件的常量池中存有大量的符号引用,字节码中的方法调用指令就以常量池中指向方法的符号引用为参数。这些符号引用一部分会在类加载阶段或第一次使用的时候转化为直接引用,这种转化称为静态解析。另外一部分将在每一次的运行期期间转化为直接引用,这部分称为动态连接。
方法返回地址:当一个方法被执行后,有两种方式退出这个方法。第一种方式是执行引擎遇到任意一个方法返回的字节码指令,这时候可能会有返回值传递给上层的方法调用者(调用当前方法的的方法称为调用者),是否有返回值和返回值的类型将根据遇到何种方法返回指令来决定,这种退出方法方式称为正常完成出口。
另外一种退出方式是,在方法执行过程中遇到了异常,并且这个异常没有在方法体内得到处理,无论是Java虚拟机内部产生的异常,还是代码中使用athrow字节码指令产生的异常,只要在本方法的异常表中没有搜索到匹配的异常处理器,就会导致方法退出,这种退出方式称为异常完成出口。一个方法使用异常完成出口的方式退出,是不会给它的调用都产生任何返回值的。
无论采用何种方式退出,在方法退出之前,都需要返回到方法被调用的位置,程序才能继续执行,方法返回时可能需要在栈帧中保存一些信息,用来帮助恢复它的上层方法的执行状态。一般来说,方法正常退出时,调用者PC计数器的值就可以作为返回地址,栈帧中很可能会保存这个计数器值。而方法异常退出时,返回地址是要通过异常处理器来确定的,栈帧中一般不会保存这部分信息。
方法退出的过程实际上等同于把当前栈帧出栈,因此退出时可能执行的操作有:恢复上层方法的局部变量表和操作数栈,把返回值(如果有的话)压入调用都栈帧的操作数栈中,调用PC计数器的值以指向方法调用指令后面的一条指令等。
五、PC寄存器
每个线程启动的时候,都会创建一个PC(Program Counter,程序计数器)寄存器。PC寄存器里保存有当前正在执行的JVM指令的地址。 每一个线程都有它自己的PC寄存器,也是该线程启动时创建的。保存下一条将要执行的指令地址的寄存器是 :PC寄存器。PC寄存器的内容总是指向下一条将被执行指令的地址,这里的地址可以是一个本地指针,也可以是在方法区中相对应于该方法起始指令的偏移量。
六、本地方法栈
Nativemethodstack(本地方法栈):保存native方法进入区域的地址。在Java里面用native修饰符来描述一个方法是本地方法。本地方法栈就是虚拟机线程调用Native方法执行时的栈,它与虚拟机栈发挥类似的作用。
总结:
按照编译原理的观点,程序运行时的内存分配有三种策略,分别是静态的,栈式的,和堆式的。
静态存储分配是指在编译时就能确定每个数据目标在运行时刻的存储空间需求,因而在编译时就可以给他们分配固定的内存空间。这种分配策略要求程序代码中不允许有可变数据结构(比如可变数组)的存在,也不允许有嵌套或者递归的结构出现,因为它们都会导致编译程序无法计算准确的存储空间需求。
栈式存储分配也可称为动态存储分配,是由一个类似于堆栈的运行栈来实现的.和静态存储分配相反,在栈式存储方案中,程序对数据区的需求在编译时是完全未知的,只有到运行的时候才能够知道,但是规定在运行中进入一个程序模块时,必须知道该程序模块所需的数据区大小才能够为其分配内存,和我们在数据结构所熟知的栈一样,栈式存储分配按照先进后出的原则进行分配。
堆式存储分配则专门负责在编译时或运行时模块入口处都无法确定存储要求的数据结构的内存分配,比如可变长度串和对象实例,堆由大片的可利用块或空闲块组成,堆中的内存可以按照任意顺序分配和释放。
总之方法区保存的就是一个类的模板,堆是放类的实例(即对象)的。栈是一般来用来函数计算的。栈里的数据,函数执行完就不会存储了。这就是为什么局部变量每一次都是一样的。就算给他加一后,下次执行函数的时候还是原来的样子。
案例:从内存分布分析类的执行过程
// AppMain.java
public class AppMain { //运行时,JVM把AppMain的信息都放入方法区
public static void main(String[] args) { //main成员方法本身放入方法区。
Sample test1 = new Sample( " 测试1 " ); //test1是引用,所以放到栈区里,Sample是自定义对象应该放到堆里面
Sample test2 = new Sample( " 测试2 " );
test1.printName();
test2.printName();
}
}
// Sample.java
public class Sample { //运行时,JVM把appmain的信息都放入方法区。
private name; //new Sample实例后,name引用放入栈区里,name对象放入堆里。
public Sample(String name) { //构造方法放入方法区
this .name = name;
}
public void printName() {// printName()成员方法本身放入方法区里。
System.out.println(name);
}
}
系统收到了我们发出的指令,启动了一个Java虚拟机进程,这个进程首先从classpath中找到AppMain.class文件,读取这个文件中的二进制数据,然后把Appmain类的类信息存放到运行时数据区的方法区中。这一过程称为AppMain类的加载过程。
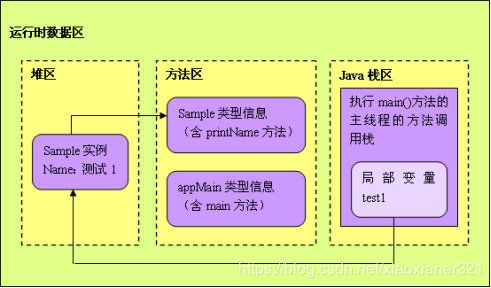
接着,JVM定位到方法区中AppMain类的Main()方法的字节码,开始执行它的指令。这个main()方法的第一条语句就是:
Sample test1 = new Sample("测试1");
Java虚拟机直奔方法区(方法区存放已经加载的类的相关信息,如类、静态变量和常量)而去,先找到Sample类的类型信息再说。结果呢,没找到立马加载了Sample类, 把Sample类的相关信息存放在了方法区中。
Sample类的相关信息加载完成后。Java虚拟机做的第一件事情就是在堆中为一个新的Sample类的实例分配内存,这个Sample类的实例持有着指向方法区的Sample类的类型信息的引用(Java中引用就是内存地址)。这里所说的引用,实际上指的是Sample类的类型信息在方法区中的内存地址,而这个地址呢,就存放了在Sample类的实例的数据区中。
在JVM中的一个进程中,每个线程都会拥有一个方法调用栈,用来跟踪线程运行中一系列的方法调用过程,栈中的每一个元素被称为栈帧,每当线程调用一个方法的时候就会向方法栈中压入一个新栈帧。这里的帧用来存储方法的参数、局部变量和运算过程中的临时数据。位于“=”前的test1是一个在main()方法中定义的变量,可见,它是一个局部变量,因此,test1这个局部变量会被JVM添加到执行main()方法的主线程的Java方法调用栈中。而“=”将把这个test1变量指向堆区中的Sample实例,也就是说,test1这个局部变量持有指向Sample类的实例的引用(即内存地址)。
接下来,JVM将继续执行后续指令,在堆区里继续创建另一个Sample类的实例,然后依次执行它们的printName()方法。当JVM执行test1.printName()方法时,JVM根据局部变量test1持有的引用,定位到堆中的Sample类的实例,再根据Sample类的实例持有的引用,定位到方法区中Sample类的类型信息(包括①类,②静态变量,③静态方法,④常量⑤成员方法),从而获取printName()成员方法的字节码,接着执行printName()成员方法包含的指令。
第四章、java类记得加载机制及其步骤
一、类的加载过程
一个java文件从被加载到被卸载这个生命过程,总共要经历5个阶段,JVM将类加载过程分为:
加载->链接(验证+准备+解析)->初始化(使用前的准备)->使用->卸载
1、类的加载
类加载第一步是先加载,在加载阶段有3件事情:
a.通过全先限定名获取此类的二进制字节流
b.将字节流所代表的静态存储结构转化为方法区的运行时数据
c.在内存中(堆区)生成一个代表类的java.lang.Class,作为这个类里面内容的访问入口
<1>加载.class文件的方式
①从本地系统中直接加载
②通过网络下载.class文件
③从zip,jar等归档文件中加载.class文件
④从专有数据库中提取.class文件
⑤将Java源文件动态编译为.class文件
<2>类的加载过程
①Bootstrap Loader(启动类加载器)
JDK在执行程序运行命令时会去JRE目录中找到jvm.dll,并初始化JVM。这时会产生一个Bootstrap Loader(启动类加载器)。负责加载$JAVA_HOME中jre/lib/rt.jar里所有的class。
②ExtensionClassLoader(标准扩展类加载器)
负责加载java平台中扩展功能的一些jar包,包括$JAVA_HOME中jre/lib/*.jar或-Djava.ext.dirs指定目录下的jar包。载System.getProper
ty(“java.ext.dirs”)所指定的路径或jar。
③AppClassLoader(系统类加载器)
负责记载classpath中指定的jar包及目录中class
④CustomClassLoader(自定义加载器)
属于应用程序根据自身需要自定义的ClassLoader,如tomcat、jboss都会根据j2ee规范自行实现。
<3>类的加载顺序

①加载过程中会先检查类是否被已加载,检查顺序是自底向上,从Custom ClassLoader到BootStrap ClassLoader逐层检查,只要某个classloader已加载就视为已加载此类,保证此类只所有ClassLoader加载一次。而加载的顺序是自顶向下,也就是由上层来逐层尝试加载此类。 (双亲委派机制)
②在加载类时,每个类加载器会将加载任务上交给其父,如果其父找不到,再由自己去加载。
③Bootstrap Loader(启动类加载器)是最顶级的类加载器了,其父加载器为null。
2、链接(验证+准备+解析)
<1>验证
验证主要分为以下几个步骤:文件格式验证->元数据验证->字节码验证->符号引用验证。
文件格式验证:主要是检查字节码的字节流是否符合Class文件格式的规范,验证该文件是否能被当前的 jvm 所处理,如果没问题,字节里就可以进入方法区进行保存了;
元数据验证:对字节码描述的信息进行语义分析,保证其描述的内容符合java语言的语法规范,能被java虚拟机识别;
字节码验证:该部分最为复杂,对方法体内的内容进行验证,保证代码在运行时不会做出什么危害虚拟机安全的事件;
符号引用验证:来验证一些引用的真实性与可行性,比如代码里面引了其他类(符号中通过字符串描述的全限定名是否能找到对应的类)。
<2>准备
准备阶段会为类变量(指的是静态变量,这就是我们常说的,静态变量/方法 在类加载的时候就执行了,通过类名.静态**来调用)分配内存并设置类的初始值;例如://成员变量
int i = 123;
在准备阶段的初始值是0,而不是123.因为此时只是分配内存空间而已,并没有对i进行初始化,真正对i赋值是在初始化阶段。所以成员变量即使我们不初始化,在类加载的时候也会默认初始化。
<3>解析
把常量池中的符号引用转换为直接引用。在解析阶段,jvm会将所有的类或接口名、字段名、方法名转换为具体的内存地址。
3、初始化
类初始化阶段是类加载过程的最后阶段。
Java虚拟机没有严格约束什么时候开始类加载过程的第一阶段,但严格规定了有且只有5钟情况必须立即马上光速对类进行初始化
①遇到new,get static[取],put static[存],invoke static[调用]这4条字节码指令时,假如类还没进行初始化,则马上对其进行初始化工作。
也就是三种情况:用new实例化一个对象时、读取或设置一个类的静态字段时、执行静态方法时;
②使用java.lang.reflect.*的方法对类进行反射调用时,如果类还没有进行过初始化,立即光速对其进行初始化!
③初始化一个类的时候,如果其父类还没有被初始化,那么会先去初始化其父类;
④当 JVM 启动时,用户需要指定一个要执行的主类(包含static void main(String []args)的那个类),则JVM会先去初始化这个类;
⑤当使用JDK1.7 的动态语言支持时,如果一个java.lang.invoke.MethodHandle实例最后的解析结果为 get static,put static,invoke static 的方法句柄,并且这个方法句柄所对应的类没有进行过初始化,则需要先初始化;
在准备阶段,已经为类变量赋过一次系统要求的初始值,到了初始化阶段会根据程序员的要求初始化类变量并赋值。类变量的初始化总是处于实例变量初始化之前。
而实例(对象)初始化默认赋值发生在分配内存的那一刻。
当Java语法层面使用new关键字创建一个Java对象时,JVM首先会检查相对应的类是否已经成功经历加载、解析和初始化等步骤;当类完成装载步骤之后,就已经完全确定出创建对象实例时所需的内存空间大小,才能对其进行内存分配,以存储所生成的对象实例。JVM在为一个对象分配完内存之后,会给每一个实例变量赋予默认值,这个时候实例变量被第一次赋值,这个赋值过程是没有办法避免的,其次可以在初始化器中对其进行初始化,再是构造器中初始化。
总结:静态初始化是属于类加载的过程,所以它只执行一次,而实例初始化是每个对象创建时都会执行一次,而构造方法跟实例初始化其实也差不多,不过它在实例初始化之后执行,而且构造方法可以重载多个,执行哪个构造方法是根据你的选择来的。
静态代码块跟静态变量都是类加载时进行初始化的(同等条件下,初始化顺序由书写顺序决定)
非静态变量和非静态代码块是在类实例时进行初始化的(同等条件下,初始化顺序由书写顺序决定)
static final 修饰的变量,系统不会对其进行默认初始化,因为他是final不可变的常量。又因为它是静态的必须赋初始值(也可以在静态代码块中初始化)。
final 修饰的变量,在每次创建新实例时被初始化(每次),必须赋初始值。
4、使用
5、卸载-销毁
二、加载顺序-案例分析
案例一:
对于静态变量、静态初始化块、变量、初始化块、构造器,它们的初始化顺序依次是(静态变量、静态初始化块)>(变量、初始化块)>构造器。
/*-----------父类-------------*/
public class Parent
{
public static int t = parentStaticMethod2();
{
System.out.println("父类非静态初始化块");
}
static
{
System.out.println("父类静态初始化块");
}
public Parent()
{
System.out.println("父类的构造方法");
}
public static int parentStaticMethod()
{
System.out.println("父类类的静态方法");
return 10;
}
public static int parentStaticMethod2()
{
System.out.println("父类的静态方法2");
return 9;
}
@Override
protected void finalize() throws Throwable
{
// TODO Auto-generated method stub
super.finalize();
System.out.println("销毁父类");
}
}
/*--------------子类------------*/
class Child extends Parent
{
{
System.out.println("子类非静态初始化块");
}
static
{
System.out.println("子类静态初始化块");
}
public Child()
{
System.out.println("子类的构造方法");
}
public static int childStaticMethod()
{
System.out.println("子类的静态方法");
return 1000;
}
@Override
protected void finalize() throws Throwable
{
// TODO Auto-generated method stub
super.finalize();
System.out.println("销毁子类");
}
}
public class Test {
public static void main(String[] args) {
Parent.parentStaticMethod(); //方式一
//Child child = new Child(); //方式二
}
}
方式一结果:
父类的静态方法2
父类静态初始化块
父类类的静态方法
解释:类中static 方法在第一次调用时加载,类中static成员按在类中出现的顺序加载。首先遇到静态的成员变量,加载时初始化它,因为它调用了parentStaticMethod2()方法,然后执行父类的静态初始化块。然后加载完成,调用parentStaticMethod()方法。
方式二结果:
父类的静态方法2
父类静态初始化块
子类静态初始化块
父类非静态初始化块
父类的构造方法
子类非静态初始化块
子类的构造方法
若方式一、方式二同时运行,其结果和方式二中相同,原因就在于静态变量、静态初始化块只会执行一次。
1、静态初始化块和非静态初始化块
<1>静态初始化块
当使用static修饰初始化块时,初始化块将变成静态初始化块。静态初始化块只在类加载时执行,并非一定要创建对象,且只会执行一次,而且静态初始化块只能给静态变量赋值,不能初始化普通成员变量。
<2>初始化块
是java类中使用{ }括起来的代码块。初始化块具有初始化的功能,在创建对象时会先执行初始化块中的代码,初始化块的执行按其上下顺序执行。然后再执行相应的构造方法。静态块只执行一次,初始化块可以执行多次。初始化块并不常用:主要用来初始化代码需要处理异常;执行计算,这些计算不能通过实例变量初始化块表示;另一种情况是匿名内部类,由于其不能声明构造方法,实例初始化块非常有用。
2、类加载特性
*在虚拟机的生命周期中一个类只被加载一次。
*类加载的原则:延迟加载,能少加载就少加载,因为虚拟机的空间是有限的。
*类加载的时机:
1)第一次创建对象要加载类.
2)调用静态方法时要加载类,访问静态属性时会加载类。
3)加载子类时必定会先加载父类。
4)创建对象引用不加载类.
5) 子类调用父类的静态方法时
①当子类没有覆盖父类的静态方法时,只加载父类,不加载子类
②当子类有覆盖父类的静态方法时,既加载父类,又加载子类
6)访问静态常量,如果编译器可以计算出常量的值,则不会加载类,例如:public static final int a =123;否则会加载类,例如:public static final int a = math.PI。
Public class FinalStatic {
public static final int A = 4 + 4;
static {
System.out.println("如果执行了,证明类加载了");
}
}
public class Test {
public static void main(String[] args) {
System.out.println(FinalStatic.A); //只输出了 8
}
}
//注:常量在编译阶段会被存入调用类的常量池中,本质上并没有引用到定义常量类,所以自然不会触发定义常量的类的初始化
3、Java代码编译和执行
编译和执行的整个过程包含了以下三个重要的机制:Java源码编译机制;类加载机制;类执行机制。
Java源码编译机制由以下三个过程组成:分析和输入到符号表、注解处理、语义分析和生成class文件。
最后生成的class文件由以下部分组成:
a)结构信息。包括class文件格式版本号及各部分的数量与大小的信息
b)元数据。对应于Java源码中声明与常量的信息。包含类/继承的超类/实现的接口的声明信息、域与方法声明信息和常量池
c)方法信息。对应Java源码中语句和表达式对应的信息。包含字节码、异常处理器表、求值栈与局部变量区大小、求值栈的类型记录、调试符号信息。
4、static属性内存分配
static修饰符能够与属性、方法和内部类一起使用,表示静态的。类中的静态变量和静态方法能够与类名一起使用,不需要创建一个类的对象来访问该类的静态成员,所以,static修饰的变量又称作“类变量”。
<1>一个类中,一个static变量只会有一个内存空间,虽然有多个类实例,但这些类实例中的这个static变量会共享同一个内存空间。
<2>static的变量是在类装载的时候就会被初始化,即,只要类被装载,不管是否使用了static变量,都会被初始化。
<3>static的基本规则
·一个类的静态方法只能访问静态属性
·一个类的静态方法不能直接调用非静态方法
·如访问控制权限允许,static属性和方法可以使用类名加“.”的方式调用,也可以使用实例加“.”的方式调用
·静态方法中不存在当前对象,因而不能使用this,也不能使用super
·静态方法不能被非静态方法覆盖
·构造方法不允许声明为static的
注:非静态变量只限于实例,并只能通过实例引用被访问。
<4>静态初始器——静态块
静态初始器是一个存在与类中方法外面的静态块,仅仅在类装载的时候执行一次,通常用来初始化静态的类属性。
5、final修饰符
在Java声明类、属性和方法时,可以使用关键字final来修饰,final所标记的成分具有终态的特征,表示最终的意思。
<1>final的具体规则
·final标记的类不能被继承
·final标记的方法不能被子类重写
·final标记的变量(成员变量或局部变量)即成为常量,只能赋值一次
·final标记的成员变量必须在声明的同时赋值,如果在声明的时候没有赋值,那么只有一次赋值的机会,而且只能在构造方法中显式赋值,然后才能使用,常量而非静态常量,属于类的对象,他不能被初始化,当对象创建时就应该有确定的值。(final 修饰的变量,系统并不会对其进行默认初始化)
·final标记的局部变量可以只声明不赋值,然后再进行一次性的赋值
·final一般用于标记那些通用性的功能、实现方式或取值不能随意被改变的成分,以避免被误用
注:如果将引用类型(即,任何类的类型)的变量标记为final,那么,该变量不能指向任何其它对象,但可以改变对象的内容,因为只有引用本身是final的。
public class Final {
int i;
final int s;
{
System.out.println(i+"因为我会默认初始化为0,编译通过");
System.out.println(s+"final修饰的成员变量系统不会默认初始化,所以不能通过编译");
//如果默认初始化,那么他又不可以更改,就会矛盾了,默认初始化是该变量的默认值这么做没有意义了
}
public Final(){
s = 4; //可以在构造函数中进行一次赋值,因为变量真正赋值,是在初始化中进行的
}
}
<2>final关键字可以修饰类、成员变量和方法,表示最终的。
a)final修饰类
表示该类不能再被其他类继承。例如:String和Math不能当做父类
b)修饰成员变量
表示该变量是一个是常量。如果final修饰的是一个基本类型的变量,那么变量变量值一旦初始化后将不能修改。如果final修饰的是一个引用变量,那么该变量的引用不可变。但是可以修改引用对象的属性值。
例如: final Dog dog = new Dog(“嘻嘻”);
Dog.name(“呵呵”);可以
dog = new Dog(“嘿嘿”);//不能通过编译
注:final不会限定对内存中数据的修改。限定的是引用的地址,不能修改。
c)修饰方法
final修饰方法是,表示该方法不能在子类中重写
在java编程思想中提到:( ^_^ )
使用final方法的原因有两个:
第一:把方法锁定,以防任何继承类修改他的含义。
第二:效率(这是早期java版本提的,现在该优化并不需要)
注意:当final修饰变量是基本数据类型以及Stirng类型是,如果在编译器就能知道他的确切的值,则编译器会把它当做编译期常量使用,也就是说在用到该final变量的地方,相当于直接访问的这个常量,不需要运行时确定(类似于c语中的宏替换)
//举例:
String a = “hello2”;
final String b = “hello”;
String d = “hello”;
String c = b +2 ;
String e = d +2 ;
//那么:
// a == c 和 a == e 输出的结果如何?由于b被final修饰,被当做常量使用,用到b的地方会直接将变量b替换为他的值而此时c = “hello2”与a 引用的将会是同一个地址。但是变量d的访问需要在运行时通过链接来进行(指向),只是最后的值是一样。但是地址不一样。 String e = d +2 ; (d运行时确定)这种形式会创建一个新的对象。
案例二:从内存分布看类的加载过程
public class Test {
public static void main(String[] args) {
Person p1=new Person("赵丽颖", 18);
p1.speak();
}
}
class Person{
private String name;
private int age;
public Person(String name,int age) {
this.name=name;
this.age=age;
}
public void speak(){
System.out.println("赵丽颖说爱我");
}
}
步骤:
<1>找到入口函数,将Test.class通过类加载器加载、连接初始化。
虚拟机一运行先找到含有main方法的类(Test类)。于是Test类通过类加载器加载,连接(-验证-准备-解析),没有问题就可以进内存的方法区中,所以该类中的Test(){}构造方法也随着Test类进入了方法区中,并且与Test类处于同一片区域;而Test类中的public static void main(){}方法由于是静态成员,所以main(){}方法进入了方法区的静态代码区(Static Code),至此,Test类中的所有成员都已加载进内存。
<2>Main()进入内存的栈区--压栈
通过invokestatic指令调用静态方法,所有方法调用中的目标在class文件里都有一个常量池中的符号引用,在类加载的解析阶段,会将其中一部分符号引用转化为直接引用,静态方法,构造方法,和可以唯一确定版本的方法(父类方法)
<3>执行Person p1 ----创建Person类型的引用变量p1
<4>执行new Person(“赵丽颖”,25)
通过invokespecial指令调用构造方法,此时Person类才加载进内存,Person类在内存的方法区中开辟一片属于Person的空间,Person类中的成员name,age,Person(name,age){},speak(){}也进入了该区域;
a)new首先在堆内存开辟一片内存空间
b)将成员变量放在该片内存空间中
c)成员变量此刻的值是系统默认赋予的初始值:String:null int:0
d)在堆区生成一个代表类的java.lang.Class,作为这个类里面内容的访问入口(Person类实例)
<5>调用Person类的相匹配的有参构造函数进栈
a)先将开辟的内存空间的首地址赋值给this,其指向堆内存中的对象
b)而对于够着函数中的两个局部变量name和age,因为是局部变量放在方法栈中。
c)所以用赵丽颖和25初始化两个局部变量
d)初始化对内存中类对象的两个成员变量name和age,分别赋值赵丽颖和25
e)初始化类的成员变量的操作完成,构造函数执行完毕,出栈。
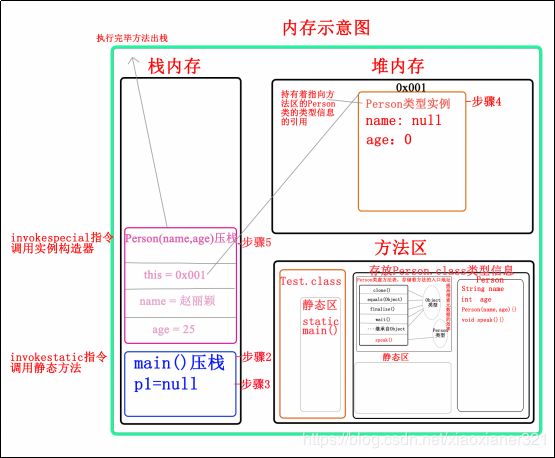
<6>把对象的地址赋值给引用类型变量p1,时其指向该对象,此时Person p1=new Person("赵丽颖", 25);执行完毕。
<7>执行p1.sleep(),sleep()进栈,执行输出:赵丽颖说爱我。是speak()出栈
<8>然后就是main()出栈。查询main()函数出栈,垃圾回收机制回收类对象,程序结束。

二、方法的调用
1、指令调用
在java虚拟机中提供了5条方法调用字节码指令。
1)invokestatic:调用静态方法。
2)invokespecial:调用实例构造器
3)invokevirtual:调用所有的虚方法
4)invokeinterface:调用接口方法,会在运行时再确定一个实现此接口的对象
5)invokedynamic:现在运行时动态解析出调用点限定符所引用的方法,然后再执行该方法
注:前4条指令是虚拟机内部固化的,而第5条由用户所设定的引导方法决定。
非虚拟方法:invokestatic、invokespecial调用的方法,包括:静态方法、私有方法、实例构造器、父类方法(和final方法)。但是final虽然是使用invokevirtual调用的,但是它是非虚方法。其他都是虚方法。
2、调用方式
<1>解析
所有方法调用中的目标在class文件里都有一个常量池中的符号引用,在类加载的解析阶段,会将其中一部分符号引用转化为直接引用。这种调用方式的前提是,在运行前就有一个可确定的调用版本。
<2>分派
分派调用方式可能是静态的,也可能是动态的。
a)静态分派
所有依赖静态类型来定位执行版本的分派成为静态分派,静态分派发生在编译阶段。典型应用:方法重载。
public class StaticDispach {
static abstract class Human{
}
static class Man extends Human{
}
static class Woman extends Human{
}
public void sayHello(Human guy){
System.out.println("hello,guy");
}
public void sayHello(Man guy){
System.out.println("hello,gentleman");
}
public void sayHello(Woman guy){
System.out.println("hello,lady");
}
public static void main(String[] args) {
Human man = new Man(); //Human man静态类型 new Man() 实际类型
Human woman = new Woman();
StaticDispach sr = new StaticDispach();
sr.sayHello(man); //hello,guy --man的静态类型匹配
sr.sayHello(woman); //hello,guy
}
}
//编译器,只会确定一个最合适的选择
public class Overload {
public void say(Object o){
System.out.println("say Object");
}
public void say(int i){
System.out.println("say int");
}
public void say(char c){
System.out.println("say char");
}
public static void main(String[] args) {
Overload ol = new Overload();
//ol.say('a'); //say char
//注释掉say(char c)
ol.say('a'); //say int
//再注释掉say(int i)
ol.say('a'); //say Object
}
}
b)动态分派
类在加载的连接阶段,类变量初始化后,虚拟机会把该类的方法表也初始化完毕。方法表是实现动态调用的核心。方法表存放在方法区中的类型信息中。方法表中存放有该类定义的所有方法及指向方法代码的指针。这些方法中包括从父类继承的所有方法以及自身重写(override)的方法。
案例三:动态绑定和静态绑定
class Person {
String name =”Person”;
@Override
public String toString() {
return "I'm a person.";
}
public void eat() {
System.out.println("Person eat");
}
public void speak() {
System.out.println("Person speak");
}
}
class Boy extends Person {
String name =”Boy”;
@Override
public String toString() {
return "I'm a boy";
}
@Override
public void speak() {
System.out.println("Boy speak");
}
public void fight() {
System.out.println("Boy fight");
}
}
class Girl extends Person {
String name =”Girl”;
@Override
public String toString() {
return "I'm a girl";
}
@Override
public void speak() {
System.out.println("Girl speak");
}
public void sing() {
System.out.println("Girl sing");
}
}
public class classReference {
public static void main(String[] args) {
Person boy = new Boy();
System.out.println(boy); // I'm a boy
boy.eat(); // Person eat
boy.speak(); // Boy speak
System.out.println(boy.name);//Parent
// boy.fight(); //报错
Person girl = new Girl();
System.out.println(girl);// I'm a girl
girl.eat(); // Person eat
girl.speak(); // Girl speak
// girl.sing();//报错
}
}
内存示意图:
解释:java编译器将java源代码编译成class文件,在编译过程中,会根据静态类型将调用的符号引用写到class文件中。
在执行时,JVM根据class文件找到调用方法的符号引用,然后在静态类型的方法表中找到偏移量,然后根据this指针确定对象的实际类型,使用实际类型的方法表,偏移量跟静态类型中方法表的偏移量一样,如果在实际类型的方法表中找到该方法,则直接调用,否则,按照继承关系从下往上搜索。
在方法区中,这个class的类型信息只有唯一的实例(方法时共享的),而在堆中可以有多个该class对象(堆中存对象的属性和类在方法区中的引用信息)。可以通过堆中的class对象访问到方法区中类型信息。就像在java反射机制那样,通过class对象可以访问到该类的所有信息一样。调用合适的方法入栈。这里的this的引用的实际类型是Boy,所有就会去Boy类的方法表中查找eat()方法,该方法在方法表中存储的实际入口地址是继承的父类的,所有回去Person类数据中取该方法入栈。当执行boy.speak()方法时,在方法表中找到speak()方法,因为重写了父类的方法,这时的实际地址,指向的是Boy类数据区的,所以调用的是子类的方法。
而调用属性则是静态绑定的,而调用属性则是静态绑定,实际上在编译的时候编译器会将这些字段生成符号的引用,保存在运行时常量池中,这些运行时常量池项会在解析阶段转换为引用对象中的实际字段位置(堆中)。只要在编译期间所有的行为jvm都会解析成父类的对象或值。编译期他他只认静态的,而无法动态去预测。同样静态方法中不能使用非静态方法的根本原因也是在这,非静态方法中都会有隐式参数this,而静态方法中没有。Person boy = new Boy(),Person boy 是静态类型,new Boy()是实际类型。所以boy.name中boy是父类类型的引用,所以调用的是父类的属性。
我认为决定动态绑定和静态绑定的本质的区别就在于有没有这个隐式的参数。
如果觉得这样还是不好理解,那么,结合左侧继续看:使用javap命令,反编译查看字节码文件。
注:javap -c 输出类中各方法的未解析的代码,即构成java字节码的指令
javap -v/verbose 打印堆栈大小、各方法的locals及args参数,以及class文件的编译版本
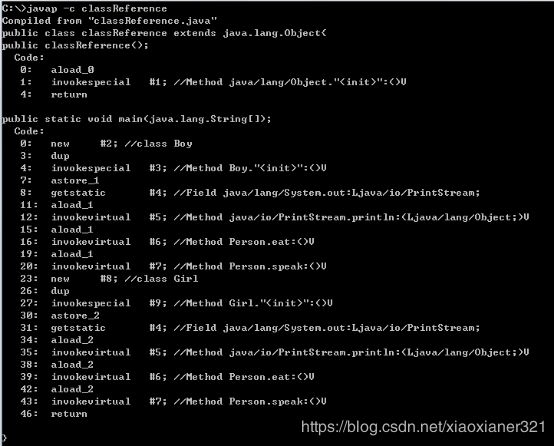
解释每行指令:
0:new #2 创建一个对象,并将其引用值压入操作数栈(#2符号引用为class: Son)
3:dup 复制操作数栈中的引用,并存入栈顶
4:invokespecial #14 调用Boy构造方法,初始化对象,让另一个引用指向初始化的对象,前面的引用(this)弹出栈
7:astore_1 将栈顶引用保存到局部变量表中的索引为1位置中,然后引用弹出栈
8:获取一个对象(静态变量)引用:System.out,局部变量表中0-this,1-out,
11:aload_1将该对象的引用推送至操作数栈
12:调用打印方法
15:将局部变量表中索引为1的变量(Boy对象的引用)压入操作数栈
16:#6只是常量池中的一个符号引用,虽然在编译时只是编译都只能按照静态去编译,但是真正在运行时,根据this指针确定方法接收者的实际类型,得到该实际类型对应的方法表。所以此处调用的会是子类重写的方法。
第五章 java进阶
一、异常、断言和调试
1、异常的基本概念及其分类
<1>异常定义:是在运行时期发生的不正常情况,会打断程序正常执行的事件。
<2>异常分类:
在java程序设计语言中,异常对象都派生于Throwable类的一个实例。
Java运行时遇到的例外情况大致可以分为两类:
a)Error(错误):系统内部错误,由虚拟机生成和抛出。例如:资源耗尽等情况。
b)Exception(异常):编程错误或者偶然的外在因素导致的一般性问题。
Exception(异常)类又可分为运行时异常和非运行时异常。
①运行时异常(RuntimeException):编译时不检测的异常,这些异常完全可以避免。就是Exception中的RuntimeException和其子类。这种问题的发生,无法让功能继续,运算无法进行,更多是因为调用者的原因导致的而或者引发了内部状态的改变导致的。运行时由java虚拟机生成的异常。
②非运行时异常:编译时被检测的异常。只要是Exception和其子类都是,除了特殊子类RuntimeException体系。这种问题一旦出现,希望在编译时就进行检测,让这种问题有对应的处理方式。必须经过异常处理之后才能正常编译。在编码过程中,运行时异常不需要try/catch来处理,而一般性异常必须使用try/catch进行处理
| Exception |
ClassNotFoundException 访问的类不存在 |
|
| NoSuchMethodException 调用的方法不存在à反射中调用方法 |
||
| NoSuchFieldException 调用的字段(属性)不存在 |
||
| IOException IO流异常 |
FileNotFoundException访问的文件不存在 |
|
| EOFException 文件异常结束 |
||
| SocketExceptionSocket异常 |
||
| RuntimeException (运行时异常) |
ArithmeticException 算数异常à int c = 9/0;对负数开平方 |
|
| ClassCastException 类型转换异常àEmployee e = new Worker(); Engineer en = (Engineer)e; |
||
| IndexOutOfBoundsException 数组索引越界异常 à int[] arr={4,5}; System.out.println(arr[2]); |
||
| NumberFormatException 数字转换异常àint i=Integer.parseInt(“a”); |
||
| NullPointerException 空指针异常àStudent s = null; s.study(); |
||
2、如何抛出异常
<1>在程序中抛出异常:使用throw关键字
throw使用在方法内。抛出一个异常对象。可以将这种抛出看成一种不同的返回机制,抛出异常与正常方法返回值的相似之处:到此为止。
<2>指定方法抛出异常:使用throws关键字
throws使用在方法上,可以抛出多个,用逗号隔开。
如果方法内的程序可能会发生异常,且方法体内又没有使用任何代码块来捕获异常。则必须在声明方法时一并指定所有可能发生的异常。以便调用此方法的程序得以做好准备来捕获异常。如果方法抛出异常,在使用此方法时,要明确地使用try-catch来捕获。如果没有,则可以将此异常继续向上传递。而main()方法是整个程序的起点,如果继续传递,到main()方法出再使用throws抛出异常,则此异常将交由JVM进行处理。
注:子类在覆盖父类方法时,父类的方法如果抛出了异常,那么子类的方法中只能抛出父类的异常或者该异常的子类。如果父类的方法没有抛出异常,那么子类覆盖时绝对不能抛,就只能try 。
3、异常捕获
异常捕获,就是可以对异常进行针对性处理的方法。当异常抛出后,抛出的异常必须在某处得到处理,这个地点就是异常处理程序,如果异常发生后,没有处理的话,当程序出现该异常时程序就会终止。
注:throws只是告诉调用者,有异常要处理。但是调用者可以继续将其往上抛。
异常捕获的具体格式:
try{
//需要被检测异常的代码
}catch(异常类 变量){//该变量用于接收发生异常的对象
//处理异常代码
}finally{
//一定会被执行的代码
}
注:多catch,异常范围由小到大,大的catch放在最下面。
a)try会对其代码块中的代码进行“检查”,在运行过程中,一旦try中的代码出现异常就会创建一个对应类型的异常对象,并且把这个异常对象提交给Java运行系统。
b)接着Java系统就会在try的后面去寻找一个能够处理当前类型异常的catch来处理这个异常。
如果找不到能够处理当前异常的catch,则程序终止,所有的代码都不会再执行了。
如果能够找到处理这个异常的catch,Java系统就会将异常对象交给这个catch,就会执行这个catch中的代码进行处理。处理完成之后,(如果有finally则一定会执行)接着执行try/catch之后的代码。
4、异常处理的原则
a)函数内容如果抛出需要检测的异常,那么函数上必须要申明。否则必须在函数内用try catch捕捉,否则编译失败。
b)如果调用到了声明异常的函数,要么try catch,要么throws,否则编译失败。
c)功能内容可以解决,用catch解决不了,用throws告诉调用者,由调用者解决。
d)一个功能如果抛出多个异常,那么调用时,必须有对应多个catch进行针对性的处理。内部有几个需要检测的异常,就抛几个异常,抛出几个,就catch几个。
自定义异常案例:
/*
* 如果让一个类称为异常类,必须要继承异常体系,因为只有称为异常体系
* 的子类才有资格具备可抛性。才可以被两个关键字所操作,throws throw
*/
public class DefaultException extends Exception {
DefaultException(){}
DefaultException(String msg){
super(msg);
}
public static void main(String[] args) throws DefaultException {
int[] str = new int[]{1,2,3};
int index = 4;
if (index > str.length) {
throw new DefaultException("数组越界了!!");
}
}
}
5、记录日志
JDK1.4自带java.util.logging.Logger
通常有以下7个日志记录器级别:
Severe:严重
Warning:警告
Info:信息
Congig:
Fine:
Finer:
Finest:
注:待深入。。。
二、集合
1、集合概述
<1>集合概念:集合,有时也称为容器,用于存储(对象)数据。这和我们以前数学中学习的集和映射有类似之处。
<2>集合的特点:a)用于存储对象的容器;b)集合的长度是可变的;c)集合中不能存储基本数据类型值。(例如:List<int> l = new ArrayList<int>();这样会报错,但是我们看到的可以直接使用l.add(1)-->是因为这里的基本数据类型都会进行自动装箱Integer对象。
之所以不能存储基本类型其根源和其内存分布有着密切的关系。首先基本数据类型都是在栈中,而栈中的数据用完就会被回收掉。而对于引用类型是保存在堆中的)
注:数组只能存放一种数据类型的数据,且长度是固定的。
<3>集合框架的体系

java“集合框架”就是由一组用来操作对象的接口组成。
Collection和Map的区别在于容器中每个位置保存的元素个数。Collection 每个位置只能保存一个元素(对象)。
Map保存的是“键值对”,就像一个小型数据库。我们可以通过“键”找到该键对应的“值”。
List 关注事物的索引列表
Set 关注事物的唯一性
Queue 关注事物被处理时的顺序
Map 关注事物的映射和键值的唯一性
2、Collection接口
2.1、Collection中常用方法
Collection包含了集合框架的共性方法。Collection 它仅仅只是一个接口,而我们真正使用的时候,确是创建该接口的一个实现类。
<1>添加
| boolean |
add(E e) 确保此 collection 包含指定的元素(可选操作)。 |
| boolean |
addAll(Collection c) 将指定 collection 中的所有元素都添加到此 collection 中(可选操作)。 |
<2>删除
| boolean |
remove(Object o) 从此 collection 中移除指定元素的单个实例,如果存在的话(可选操作)。 |
| boolean |
removeAll(Collection c) 移除此 collection 中那些也包含在指定 collection 中的所有元素(可选操作)。 |
| void |
clear() 移除此 collection 中的所有元素(可选操作 |
<3>判断
| boolean |
contains(Object o) 如果此 collection 包含指定的元素,则返回 true。 |
| boolean |
containsAll(Collection c) 如果此 collection 包含指定 collection 中的所有元素,则返回 true。 |
| boolean |
isEmpty() 如果此 collection 不包含元素,则返回 true。 |
<4>获取
| int |
size() 返回此 collection 中的元素数。 |
| Iterator |
iterator() 返回在此 collection 的元素上进行迭代的迭代器。 |
<5>其他方法
| boolean |
retainAll(Collection c) 取交集。 |
| boolean |
removeAll(Collection c) 去除交集。 |
| Object[] |
toArray() 将集合转换为数组。 |
2.2、Collection遍历方法
Collection不提供get()方法。如果要遍历Collectin中的元素,就必须用Iterator()。
Iterator
| boolean |
hasNext() 如果仍有元素可以迭代,则返回 true。 |
| E |
next() 返回迭代的下一个元素。 |
| void |
remove() 从迭代器指向的 collection 中移除迭代器返回的最后一个元素(可选操作)。 |
注:Iterator在迭代过程中不能使用集合中的方法对元素进行添加,删除操作,但可以使用Iterator中的方法对元素进行删除,也可以使用集合的方法对元素进行修改
public class TestCollection {
public static void main(String[] args) {
Collection c = new ArrayList();
c.add("java001");
c.add("java002");
c.add("java003");
c.add("java004");
Iterator it = c.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
for (Iterator it1 = c.iterator(); it1.hasNext();) {
System.out.println(it1.next());
}
}
}
3、List接口
1)List概述
|--List:有序(存入和取出的顺序一致);元素都有索引(角标);元素可以重复。
|--Vector:内部是数组数据结构,是同步的。增删和查询都很慢。
|--ArrayList:内部是数组数据结构是不同步的。替代了Vector。查询速度快。
|--LinkedList:内部是链表数据结构,是不同步的。增删速度快。
2)List中特有的方法
a)添加
| void |
add(int index, E element) 在列表的指定位置插入指定元素(可选操作)。 |
| boolean |
addAll(int index, Collection c) 将指定 collection 中的所有元素都插入到列表中的指定位置(可选操作)。 |
b)删除
| E |
remove(int index) 移除列表中指定位置的元素(可选操作),返回被删除的元素。 |
c)修改
| E |
set(int index, E element) 用指定元素替换列表中指定位置的元素(可选操作)。 |
d)获取
| E |
get(int index) 返回列表中指定位置的元素。 |
| int |
indexOf(Object o) 返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1。 |
| int |
lastIndexOf(Object o) 返回此列表中最后出现的指定元素的索引;如果列表不包含此元素,则返回 -1。 |
| List |
subList(int fromIndex, int toIndex) 返回列表中指定的 fromIndex(包括 )和 toIndex(不包括)之间的部分视图。 |
e)迭代
| Iterator |
iterator() 返回按适当顺序在列表的元素上进行迭代的迭代器。 |
| ListIterator |
listIterator() 返回此列表元素的列表迭代器(按适当顺序)。 |
| ListIterator |
listIterator(int index) 返回列表中元素的列表迭代器(按适当顺序)从列表的指定位置开始。 |
3)接口 ListIterator
List集合在使用Iterator迭代时,不能对集合添加元素。
如下面代码是不允许的:
public static void main(String[] args) {
List list=new ArrayList();
list.add("java01");
list.add("java02");
list.add("java03");
Iterator it=list.iterator();
while(it.hasNext()){
String s=it.next();
if(s.equals("java02"))
list.add("java08");
}
} 会抛出ConcurrentModificationException(并发修改异常)异常。
List集合特有的迭代器,ListIterator是Iterator的子接口。在迭代时,不可以通过集合对象的方法操作集合中的元素。因为会发生ConcurrentModificationException异常。所以,在迭代器时,只能用迭代器的方法操作元素,但是Iterator的方式是有限的,只能对元素进行判断,取出,删除的操作
如果想要其他的的操作如添加,修改,删除等,或需要使用其子接口,ListIterator,该接口只能通过List集合的ListIterator方法获取。
ListIterator接口中的方法
| void |
add(E e) 将指定的元素插入列表(可选操作)。 |
| boolean |
hasNext() 以正向遍历列表时,如果列表迭代器有多个元素,则返回 true(换句话说,如果 next 返回一个元素而不是抛出异常,则返回 true)。 |
| boolean |
hasPrevious() 如果以逆向遍历列表,列表迭代器有多个元素,则返回 true。 |
| E |
next() 返回列表中的下一个元素。 |
| int |
nextIndex() 返回对 next 的后续调用所返回元素的索引。 |
| E |
previous() 返回列表中的前一个元素。 |
| int |
previousIndex() 返回对 previous 的后续调用所返回元素的索引。 |
| void |
remove() 从列表中移除由 next 或 previous 返回的最后一个元素(可选操作)。 |
| void |
set(E e) 用指定元素替换 next 或 previous 返回的最后一个元素(可选操作)。 |
public class TestListIterator {
public static void main(String[] args) {
List list = new ArrayList();
list.add("java01");
list.add("java02");
list.add("java03");
ListIterator it = list.listIterator();//获取列表迭代器对象
// 它可以实现在迭代过程中完成元素的增删改查。
// 注意:只有List集合具备该迭代器。该迭代器中有add方法
while (it.hasNext()) {
Object obj = it.next();
if (obj.equals("java02"))
it.add("java08");
}
System.out.println(list);
show_1(list);
show_2(list);
}
// List特有取出元素方法
public static void show_2(List list) {
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
// 通用方法
public static void show_1(List list) {
Iterator it = list.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
3.1、ArrayList类
3.1.1、ArrayList概述
ArrayList是Java集合框架中的一个重要的类。它:
继承于AbstractList,实现了List接口,是一个长度可变的集合,提供了增删改查的功能。集合中允许null的存在。
ArrayList类还是实现了RandomAccess接口,可以对元素进行快速访问。
实现了Serializable接口,说明ArrayList可以被序列化。
实现了Cloneable接口,可以被复制。
和Vector不同的是,ArrayList不是线程安全的。
因为ArrayList底层是数组实现的,根据下标查询不需要比较,所以非常快;增删会带来元素的移动,增加数据会向后移动,删除数据会向前移动,所以增删与LinkedList相比就会慢些。
3.1.2、ArrayList实现原理
ArrayList是内部是以动态数组的形式来存储数据的。这里的动态数组不是意味着去改变原有内部生成的数组的长度、而是保留原有数组的引用、将其指向新生成的数组对象、这样会造成数组的长度可变的假象。
3.1.3、ArrayList类
a)特有方法
| void |
ensureCapacity(int minCapacity) 增加此 ArrayList 实例的容量,增加为原来的1.5倍 |
| void |
trimToSize() 将此 ArrayList 实例的容量调整为列表的当前大小。 |
b)contains(Object o)方法
contains调用了equals方法,所以要根据自己的需求复写equals方法。对于String类来说,已经复写了equals方法。
public class ArrayListTest {
public static void main(String[] args) {
// 去除ArrayList中Person对象相同内容的元素。
ArrayList list = new ArrayList();
list.add(new Person("wangcai", 21));
list.add(new Person("zhangsan", 22));
list.add(new Person("lisi", 23));
list.add(new Person("zhaoliu", 24));
list.add(new Person("wangcai", 21));
list.add(new Person("lisi", 23));
System.out.println(list);
list = getNewList(list);
System.out.println(list);
singleStringDemo();
}
// 去除ArrayList集合中字符串中相同的元素
public static void singleStringDemo() {
ArrayList list = new ArrayList();
list.add("java01");
list.add("java02");
list.add("java05");
list.add("java02");
list.add("java04");
list.add("java05");
list.add("java04");
System.out.println(list);
list = getNewList(list);
System.out.println(list);
}
public static ArrayList getNewList(ArrayList list) {
ArrayList temp = new ArrayList();
Iterator it = list.iterator();
while (it.hasNext()) {
Object obj = it.next();
if (!temp.contains(obj))
temp.add(obj);
}
return temp;
}
}
class Person {
private String name;
private int age;
public Person() {
super();
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public boolean equals(Object obj) {
if (obj == this)
return true;
if (!(obj instanceof Person))
throw new RuntimeException("类型错误");
Person p = (Person) obj;
// System.out.println(this + "...equals..." + p.name + "---" + p.age);
return name.equals(p.name) && age == p.age;
}
public String toString() {
return name + "--" + age;
}
}
c)T[] toArray(T[] a) 方法
ArrayList al= new ArrayList();
for (int i = 0; i < 10; i++) {
al.add("arr"+i);
}
/---ArrayList优先选择前两种---//---LinkedList优先选择foreach---/
//方法一:下标遍历
for (int i = 0; i < al.size(); i++) {
System.out.println(al.get(i));
}
//方法二:foreach遍历
for (String str: al) {
System.out.println(str);
}
//方法三:迭代Iterator
Iterator it = al.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
for (Iterator itr = al.iterator();itr.hasNext();) {
System.out.println(itr.next());
}
//方法四:转换为数组
String[] str =al.toArray(new String[0]);
for (int i = 0; i < str.length; i++) {
System.out.println(str[i]);
}
3.2、LinkedList类
3.2.1、LinkedList概述
ArrayList 继承自AbstractList,通过一个Object[]数组存储对象。AbstractSequentialList 继承自AbstractList,它是专门为LinkedList而设计的,进一步地实现了add()、get()以及remove()方法。
LinkedList 继承自AbstractSequentialList,通过一个双向链表存储对象。
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
LinkedList 是非同步的。如果多个线程同时访问一个链接列表,而其中至少一个线程从结构上修改了该列表,则它必须保持外部同步。(结构修改指添加或删除一个或多个元素的任何操作;仅设置元素的值不是结构修改。)这一般通过对自然封装该列表的对象进行同步操作来完成。如果不存在这样的对象,则应该使用 Collections.synchronizedList 方法来“包装”该列表。最好在创建时完成这一操作,以防止对列表进行意外的不同步访问。
注:链表插入数据速度快的说法是相对的,在数据量很小的时候,ArrayList的插入速度不仅不比LinkedList慢,而且还快很多,只有当数据量达到一定量,这个特性才会体现出来。
3.2.2、LinkedList实现原理

3.2.3、LinkedList
a)特有方法
| void |
addFirst(E e) |
| void |
addLast(E e) |
| E |
getFirst() |
| E |
getLast() |
| E |
removeFirst() |
| E |
removeLast() |
b)JDK1.6升级新增
| boolean |
offerFirst(E e) 在此列表的开头插入指定的元素。 |
| boolean |
offerLast(E e) 在此列表末尾插入指定的元素。 |
| E |
peek() 获取但不移除此列表的头(第一个元素)。 |
| E |
peekFirst() 获取但不移除此列表的第一个元素;如果此列表为空,则返回 null。 |
| E |
peekLast() 获取但不移除此列表的最后一个元素;如果此列表为空,则返回 null。 |
| E |
pollFirst() 获取并移除此列表的第一个元素;如果此列表为空,则返回 null。 |
| E |
pollLast() 获取并移除此列表的最后一个元素;如果此列表为空,则返回 null。 |
3.3、Vector
是线程同步的,是线程安全的,多用于多线程编程
a)特有特殊方法
| Enumeration |
elements() |
b)Enumeration接口中的方法
| boolean |
hasMoreElements() |
| E |
nextElement() |
Enumeration接口的功能与 Iterator 接口的功能是重复的。Iterator 接口添加了一个可选的移除操作,并使用较短的方法名。新的实现应该优先考虑使用 Iterator 接口而不是 Enumeration 接口
public class VectorDemo {
public static void main(String[] args) {
Vector v = new Vector();
v.addElement("java01");
v.addElement("java02");
v.addElement("java03");
Enumeration en = v.elements();
while (en.hasMoreElements()) {
System.out.println(en.nextElement());
}
}
4、Set接口
|——Set:有序,元素不能重复。
|--HashSet :内部是哈希表数据结构,是不同步的。
|--TreeSet :可以对Set集合中的元素进行指定顺序排序,不同步的
Set最大的特性就是不允许在其中存放的元素是重复的。Set 可以被用来过滤在其他集合中存放的元素,从而得到一个没有包含重复元素的新集合。
4.1、HashSet类
4.1.1、HashSet类概述
HashSet类继承自AbstractSet(重写了equals和hashCode方法),并实现了Set接口。
(HashSet的本质是一个"没有重复元素"的集合,它是通过HashMap实现的)
HashSet实现了Cloneable接口,说明HashSet可以被复制。
HashSet实现了Serializable接口,说明HashSet可以被序列化。
HashSet不保证元素的顺序,而且HashSet允许使用 null 元素。
HashSet是非同步的。
HashSet的内部数据结构是哈希表,哈希表确定元素是否相同
a)判断的是两个元素的哈希值(hashCode)是否相同,如果相同,再判断两个对象的内容是否相同。
b)判断哈希值是否相同,其实判断的是对象的HashCode的方法,判断内容是否相同,用的是equals方法。
注意:如果哈希值不同,是不需要判断equals的。
4.1.2、HashSet实现原理
// HashSet是通过map(HashMap对象)保存内容的
private transient HashMap map;
// 因为HashSet中只需要用到key,而HashMap是key-value键值对;
// 所以,向map中添加键值对时,键值对的值固定是PRESENT
private static final Object PRESENT = new Object();
// 默认构造函数
public HashSet() {
// 调用HashMap的默认构造函数,创建map
map = new HashMap();
}
// 将元素(e)添加到map的key中 --->作为HashSet的值
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// 调用 map 的 keySet 来返回所有的 key
public Iterator iterator(){
return map.keySet().iterator();
}
// 调用 HashMap 的 size() 方法返回 Entry 的数量,就得到该 Set 里元素的个数
public int size(){
return map.size();
}
4.1.3、HashSet遍历方式
HashSet set = new HashSet();
set.add("a");
set.add("b");
set.add("c");
set.add("d");
//方法一:Iterator迭代
for(Iterator iterator = set.iterator();iterator.hasNext();){
System.out.println(iterator.next()); //dbca
}
//方法二:转换为数组--不推荐
/**
* d--100
* b--98
* c--99
* a--97
* 虽然说HashSet是无序的,但是这里的无序指的是存入的顺序是无序的,意思是并不是
* 按照我们初始添加的顺序,而是根据hashCode来计算得到的数组存放下标,一旦存入
* 这个顺序是不变的
*/
String[] arr = (String[])set.toArray(new String[0]);
for (String s:arr){
System.out.println(s+"--"+s.hashCode());
}
4.1.4、LinkedHashSet类
LinkedHashSet具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的次序)。其内部使用了LinkedHashMap来维护元素的顺序。
//调用了父类的构造方法
public LinkedHashSet() {
super(16, .75f, true);
}
//父类的构造中使用LinkedHashMap来实现......
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap(initialCapacity, loadFactor);
}
//LinkedHashSet 有序
LinkedHashSet hs = new LinkedHashSet();
hs.add("haha");
hs.add("xixi");
hs.add("heihei");
hs.add("biabia");
System.out.println(hs);//运行结果为[haha, xixi, heihei, biabia]
4.2、TreeSet类
4.2.1、TreeSet概述
TreeSet是一个有序的集合,它的作用是提供有序的Set集合。它继承于AbstractSet抽象类,实现了NavigableSet
TreeSet 继承于AbstractSet,所以它是一个Set集合,具有Set的属性和方法。
TreeSet 实现了NavigableSet接口,意味着它支持一系列的导航方法。比如查找与指定目标最匹配项。
TreeSet 实现了Cloneable接口,意味着它能被克隆。
TreeSet 实现了java.io.Serializable接口,意味着它支持序列化。
TreeSet是基于TreeMap实现的。TreeSet中的元素支持2种排序方式:自然排序或比较器排序(根据创建TreeSet 提供的 Comparator 进行排序)。
另外,TreeSet是非同步的。
注:自然排序一般是指按字母顺序或者数值大小排序,比如Integer型和字母类的数据就自带了自然排序的功能。因为这些带有自然排序的基本上都是实现了Comparable接口,已经重写了compareTo()方法的。
注:比较器排序就是你自己去定义各种数据类型的大小的方法,比如一个Student类就可以只比较其age属性,或者再比完age属性后再加上比较name的长短,或者再加上比较score成绩的高低,总之就是你去定义数据类型的某些属性来进行比较,得出大小值,然后排序。
如果往TreeSet添加元素的时候,如果元素本身具备自然顺序的特性,那么treeSet就会按照元素自然顺序的特性进行排序存储。
如果往TreeSet添加元素的时候, 如果元素本身不具备自然顺序的特性, 那么元素所属的类就必须要实现Comparable接口,把元素的比较规则定义在compareTo(T o)方法上。
在TreeSet中如果比较的方法返回的是0,该元素则被视为重复元素,不允许添加。
往TreeSet添加元素的时候,如果元素本身不具备自然顺序的特性,而且元素所属的类没有实现Comparable接口, 那么在创建TreeSet对象的时候就必须要传入一个比较器对象。(Comparator --- 一个自定义类,实现了这个接口)
public class TreeSetDemo {
public static void main(String[] args) {
TreeSet ts = new TreeSet();
ts.add(new Person("zhangsan", 28));
ts.add(new Person("wangwu", 23));
ts.add(new Person("lisi", 21));
ts.add(new Person("zhouqi", 29));
ts.add(new Person("zhaoliu", 28));
Iterator it = ts.iterator();
while (it.hasNext()) {
Person p = (Person) it.next();
System.out.println(p.getName() + "--" + p.getAge());
/*-----方法一输出结果:----*/
/* lisi--21
wangwu--23
zhangsan--28
zhaoliu--28
zhouqi--29
*/
}
show1();//[abcd, ajk, boy, cba, good, nba]
TreeSet ts1 = new TreeSet(new ComparatoByName());
ts1.add(new Person("zhangsan", 28));
ts1.add(new Person("wangwu", 30));
ts1.add(new Person("lisi", 21));
ts1.add(new Person("zhouqi", 29));
ts1.add(new Person("zhaoliu", 28));
Iterator it = ts1.iterator();
while (it.hasNext()) {
Person p = (Person) it.next();
System.out.println(p.getName() + "--" + p.getAge());
}
/*------方法二输出结果-------*/
/*lisi--21
wangwu--30
zhangsan--28
zhaoliu--28
zhouqi--29
*/
}
// 对字符串进行排序(自然排序)-String类中重写了compareTo方法不用我们再重写
public static void show1() {
TreeSet ts = new TreeSet();
ts.add("boy");
ts.add("good");
ts.add("cba");
ts.add("abcd");
ts.add("nba");
ts.add("ajk");
System.out.println(ts);
}
}
//方法一:
class Person implements Comparable {
// 按年龄进行排序
public int compareTo(Object o) {
Person p = (Person) o;
int tem = age - p.age;
return (tem == 0) ? (name.compareTo(p.name)) : tem;
}
private String name;
private int age;
public Person() {
super();
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
//方法二:
class ComparatoByName implements Comparator {
public int compare(Object o1, Object o2) {
Person p1 = (Person) o1;
Person p2 = (Person) o2;
int tem = p1.getName().compareTo(p2.getName());
return tem == 0 ? p1.getAge() - p2.getAge() : tem;
}
}
4.2.2、TreeSet实现原理
// NavigableMap对象
private transient NavigableMap m;
// 不带参数的构造函数。创建一个空的TreeMap
public TreeSet() {
this(new TreeMap());
}
//带比较器的构造
public TreeSet(Comparator comparator) {
this(new TreeMap(comparator));
}
// 将TreeMap赋值给 "NavigableMap对象m"
TreeSet(NavigableMap m) {
this.m = m;
}
// 添加e到TreeSet中 - treeMap中的put方法
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
public V put(K key, V value) {
Entry t = root;
if (t == null) { //获取首个元素,不需要排序
root = new Entry(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry parent;
//如果是带比较器Comparator的构造则走此方法
Comparator cpr = comparator;
if (cpr != null) {
do {
parent = t; //父节点
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left; //比较小则放父节点的左边
else if (cmp > 0)
t = t.right;//否则放右边
else
return t.setValue(value);//如果相等就替换
} while (t != null);
}
else {//如果不是带比较器的,则走这条路,必须是实现了compareTo方法的
if (key == null)
throw new NullPointerException();
Comparable k = (Comparable) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry e = new Entry(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
} TreeSet底层数据结构就是二叉树:下图就是一个(平衡)二叉树。
4.2.3、TreeSet遍历
//方法一:Iterator顺序遍历
for(Iterator iter = set.iterator(); iter.hasNext(); ) {
iter.next();
}
//方法二:Iterator顺序遍历
for(Iterator iter = set.descendingIterator(); iter.hasNext(); ) {
iter.next();
}
//方法三:for-each遍历 //不推荐-先要将其转换为数组
String[] arr = (T[])set.toArray(new T[0]);
for (String str:arr){
System.out.printf("for each : %s\n", str);
}
5、Map接口
1)Map概述

Map:一次添加一对元素,Collection一次添加一个元素。Map也称为双列集合,Collection集合称为单列集合。
(1) Map集合中存储的是键值对。Map集合中必须保证键的唯一性。
(2) AbstractMap 是继承于Map的抽象类,它实现了Map中的大部分API。其它Map的实现类可以通过继承AbstractMap来减少重复编码。
(3) SortedMap 是继承于Map的接口。SortedMap中的内容是排序的键值对,排序的方法是通过比较器(Comparator)。
(4) NavigableMap 是继承于SortedMap的接口。相比于SortedMap,NavigableMap有一系列的导航方法;如"获取大于/等于某对象的键值对"、“获取小于/等于某对象的键值对”等等。
(5) TreeMap 继承于AbstractMap,且实现了NavigableMap接口;因此,TreeMap中的内容是“有序的键值对”!
(6) HashMap 继承于AbstractMap,但没实现NavigableMap接口;因此,HashMap的内容是“键值对,但不保证次序”!
(7) Hashtable 虽然不是继承于AbstractMap,但它继承于Dictionary(Dictionary也是键值对的接口),而且也实现Map接口;因此,Hashtable的内容也是“键值对,也不保证次序”。但和HashMap相比,Hashtable是线程安全的,而且它支持通过Enumeration去遍历。
(08) WeakHashMap 继承于AbstractMap。它和HashMap的键类型不同,WeakHashMap的键是“弱键”。
2)Map常用方法
a)添加
| V |
put(K key, V value) 添加键值对,返回前一个与key关联的值,如果没有就返回null。 |
b)删除
| void |
clear() 清空Map集合。 |
| V |
remove(Object key) 根据指定的key删除这个键值对。 |
c)判断
| boolean |
containsKey(Object key) 如果此映射包含指定键的映射关系,则返回 true。 |
| boolean |
containsValue(Object value) 如果此映射将一个或多个键映射到指定值,则返回 true。 |
| boolean |
isEmpty() 如果此映射未包含键-值映射关系,则返回 true。(注:也是判断size == 0) |
d)获取
| V |
get(Object key) 返回指定键所映射的值;如果不包含该键的映射关系,则返回 null。 |
| int |
size() 返回此映射中的键-值映射关系数。 |
e)其他方法
| Set |
keySet() 返回此映射中包含的键的 Set 视图。 |
| Set |
entrySet() 返回此映射中包含映射关系的 Set 视图。 |
| Collection |
values() 返回此映射中包含的值的 Collection 视图。 |
(Map.Entry)我们注意到,在Map源码中定义了一个内部接口 interface Entry
3)Map的遍历方式
//方法一:普遍使用(二次取值:通过Map.keySet得到遍历key,再取value)
for (K key : map.keySet()) {
System.out.println("key= "+ key + " and value= " + map.get(key));
}
//方法二:通过Map.entrySet使用iterator遍历key和value
for (Map.Entry entry : map.entrySet()) {
System.out.println("key= "+entry.getKey()+"value="+entry.getValue());
}
//或者
Iterator> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry entry = it.next();
System.out.println("key= "+entry.getKey()+"value= "+entry.getValue());
}
//方法三:通过Map.values()遍历所有的value,但不能遍历key
for (String v : map.values()) {
System.out.println("value= " + v);
}
5.1、HashMap类
5.1.1、HashMap概述
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。容量 是哈希表中桶的数量,初始容量 只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
5.1.2、HashMap实现原理
//默认的初始容量是16,必须是2的幂。
static final int DEFAULT_INITIAL_CAPACITY = 16;
// 最大容量(必须是2的幂且小于2的30次方,传入容量过大将被这个值替换)
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 存储数据的Entry数组,长度是2的幂。
// HashMap是采用拉链法实现的,每一个Entry本质上是一个单向链表
transient Entry[] table;
// HashMap的大小,它是HashMap保存的键值对的数量
transient int size;
// HashMap的阈值,用于判断是否需要调整HashMap的容量(threshold = 容量*加载因子)
int threshold;
// 加载因子实际大小
final float loadFactor;
// HashMap的默认构造
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // 设置“加载因子”
// 设置“HashMap阈值”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
// 创建Entry数组,用来保存数据
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init(); //没有
}
public V put(K key, V value) {
if (key == null) // 若“key为null”,则将该键值对添加到table[0]中。
return putForNullKey(value);
// 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
// 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出!
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 若“该key”对应的键值对不存在,则将“key-value”添加到table中
addEntry(hash, key, value, i);
return null;
}
5.1.3、LinkedHashMap类
LinkedHashMap是HashMap的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用LinkedHashMap。
LinkedHashMap map = new LinkedHashMap();
map.put("1","1");
map.put("2","2");
map.put("a","a");
map.put("b","b");
map.put("3","3");
for (String s: map.keySet()) {
System.out.println(s + "-" + map.get(s));
}
/*--------结果-----------*/
/*1-1
2-2
a-a
b-b
3-3*/
5.2、Hashtable类
5.2.1、Hashtable概述
和HashMap一样,Hashtable 也是一个散列表,它存储的内容是键值对(key-value)映射。
Hashtable 继承于Dictionary(Dictionary是声明了操作"键值对"函数接口的抽象类),实现了Map、Cloneable、java.io.Serializable接口。Hashtable 的函数都是同步的,这意味着它是线程安全的。
它的key、value都不可以为null。此外,Hashtable中的映射不是有序的。
5.2.2、Hashtable实现原理
Hashtable实现原理和HashMap差不多,只不过它是同步的。在其方法上加了synchronized 。
public synchronized V put(K key, V value) {
......
}
除了以上区别:Hashtable比HashMap多继承了Dictionary接口,为此他还可以使用Enumeration类来枚举Hashtable中的key/value。
注:这些方法是Hashtable独有的,Map中并没有这些方法。
//利用枚举获取value
Enumeration e = ht.elements();
while(e.hasMoreElements()){
System.out.println(e.nextElement());
}
//利用枚举获取key:value对
Enumeration e2 = ht.keys();
while(e2.hasMoreElements()){
String key = e2.nextElement();
System.out.println(key+" = "+ht.get(key));
}
5.3、TreeMap类
5.3.1、TreeMap概述
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
TreeMap 实现了Cloneable接口,意味着它能被克隆。
TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
另外,TreeMap是不同步的。
5.3.2、红黑树简介
红黑树又称红-黑二叉树,它首先是一颗二叉树,它具体二叉树所有的特性。同时红黑树更是一颗自平衡的排序二叉树。
一颗基本的二叉树他们都需要满足一个基本性质--即树中的任何节点的值大于它的左子节点,且小于它的右子节点。按照这个基本性质使得树的检索效率大大提高。
平衡二叉:树必须具备如下特性:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。也就是说该二叉树的任何一个等等子节点,其左右子树的高度都相近。

为了解决二叉树的不平衡问题,研究出了红-黑二叉树,它总是生成像左图那样的平衡二叉树。对于红黑二叉树而言它主要包括三大基本操作:左旋、右旋、着色。
规则:
1、每个节点都只能是红色或者黑色
2、根节点是黑色
3、每个叶节点(NIL节点--空/null节点)是黑色的。
4、如果一个结点是红的,则它两个子节点都是黑的。也就是说在一条路径上不能出现相邻的两个红色结点。
5、从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
若是插入或者删除节点,有必要进行响应的调整。或进行左旋/右旋,着色等,使其依旧保持平衡。
5.3.3、TreeMap的实现原理
public V put(K key, V value) {
//用t表示二叉树的当前节点
Entry t = root;
//t为null表示一个空树,即TreeMap中没有任何元素,直接插入
if (t == null) {
//将新的key-value键值对创建为一个Entry节点,并将该节点赋予给root
root = new Entry<>(key, value, null);
//容器的size = 1,表示TreeMap集合中存在一个元素
size = 1;
//修改次数 + 1
modCount++;
return null;
}
int cmp; //cmp表示key排序的返回结果
Entry parent; //父节点
// split comparator and comparable paths
Comparator cpr = comparator; //指定的排序算法
//如果cpr不为空,则采用既定的排序算法进行创建TreeMap集合
if (cpr != null) {
do {
parent = t; //parent指向上次循环后的t
//比较新增节点的key和当前节点key的大小
cmp = cpr.compare(key, t.key);
//cmp返回值小于0,表示新增节点的key小于当前节点的key,则以当前节点的左子节点作为新的当前节点
if (cmp < 0)
t = t.left;
//cmp返回值大于0,表示新增节点的key大于当前节点的key,则以当前节点的右子节点作为新的当前节点
else if (cmp > 0)
t = t.right;
//cmp返回值等于0,表示两个key值相等,则新值覆盖旧值,并返回新值
else
return t.setValue(value);
} while (t != null);
}
//如果cpr为空,则采用默认的排序算法进行创建TreeMap集合
else {
if (key == null) //key值为空抛出异常
throw new NullPointerException();
/* 下面处理过程和上面一样 */
Comparable k = (Comparable) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
//将新增节点当做parent的子节点
Entry e = new Entry<>(key, value, parent);
//如果新增节点的key小于parent的key,则当做左子节点
if (cmp < 0)
parent.left = e;
//如果新增节点的key大于parent的key,则当做右子节点
else
parent.right = e;
/*
* 上面已经完成了排序二叉树的的构建,将新增节点插入该树中的合适位置
* 下面fixAfterInsertion()方法就是对这棵树进行调整、平衡
*/
fixAfterInsertion(e);
//TreeMap元素数量 + 1
size++;
//TreeMap容器修改次数 + 1
modCount++;
return null;
}
//以上是TreeMap添加节点的过程,当添加节点后会调用fixAfterInsertion(e)进行相应的调整-左旋/右旋、着色;
//待学习:红黑树---左旋/右旋、着色
5.3.4、TreeMap排序
TreeMap和TreeSet都是有序的,具体参照TreeSet中的阐述。
public class TreeMapDemo {
public static void main(String[] args) {
//方法一TreeMap tm = new TreeMap();
//方法二:TreeMap tm = new TreeMap(new ComparatorByLength());
tm.put(new Student("xiaoming", 18), "北京");
tm.put(new Student("lisi", 20), "上海");
tm.put(new Student("zhaoliu", 19), "沈阳");
tm.put(new Student("wangcai", 23), "大连");
tm.put(new Student("lisi", 20), "武汉");
// 方法一结果: // 方法二结果:
/*xiaoming:18--北京 /*lisi:20--武汉
zhaoliu:19--沈阳 wangcai:23--大连
lisi:20--武汉 xiaoming:18--北京
wangcai:23--大连*/ zhaoliu:19--沈阳*/
}
}
//按照姓名进行排序
//方法一:
class ComparatorByLength implements Comparator {
public int compare(Student p1, Student p2) {
int tem = p1.getName().compareTo(p2.getName());
return tem == 0 ? p1.getAge() - p2.getAge() : tem;
}
}
//方法二:
public class Student implements Comparable {
private String name;
private int age;
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
// 按照年龄进行排序
public int compareTo(Student p) {
int tem = age - p.age;
return (tem == 0) ? (name.compareTo(p.name)) : tem;
}
}
5.3.5、练习:记录字符次数
public class TreeMapDemo {
public static void main(String[] args) {
String str = "abdabdadjakjjdkasjdkajskjdakasdha213123";
System.out.println(getCharCount(str));
}
private static String getCharCount(String str){
char[] ch = str.toCharArray();
TreeMap tm = new TreeMap();
for (int i = 0; i < ch.length; i++) {
int count = 1;
Integer value = tm.get(ch[i]);
if (value != null) {
count = value + 1;
}
tm.put(ch[i], count);
}
StringBuffer sb = new StringBuffer();
for (Character c: tm.keySet()) {
sb.append(c+"("+tm.get(c)+")");
}
return sb.toString();
}
}
5.4、区别:
List和Set的区别:
List是有序的,即存入和取出的顺序一致,元素可以重复,Set:无序,元素不能重复
ArrayList和LinkedList的区别:
ArrayList是基于数组的实现,查询速度快,增删速度慢
LinkedList是基于链表的实现,查询效率偏低,但增删效率
ArrayList和Vector的区别:
ArrayList:是线程不同步,是线程不安全的,但效率高于Vector
Vector:是实现线程同步,是线程安全的,但效率偏低
HashSet和TreeSet的区别:
TreeSet可以对Set集合中的元素进行指定顺序排序,而HashSet不行
HashMap和Hashtable区别:
①HashMap允许有一个null键和多个null值;Hashtable不允许有null键和null值。
②Hashtable是线程同步的,多用于多线程中;HashMap未实现同步。
6、集合工具类Collections
6.1、常用的方法
java.util.Collections 是一个包装类(工具类/帮助类)。它包含有各种有关集合操作的静态多态方法。此类不能实例化,就像一个工具类,用于对集合中元素进行排序、搜索以及线程安全等各种操作,服务于Java的Collection框架。
a)排序
| static |
sort(List |
| static |
sort(List |
| static void |
swap(List list, int i, int j) 在指定列表的指定位置处交换元素。 |
b)折半(二分查找)
| static |
binarySearch(List> list, T key) 使用二分搜索法搜索指定列表,以获得指定对象。 |
| static |
binarySearch(List list, T key, Comparator c) 使用二分搜索法搜索指定列表,以获得指定对象。 |
c)最值
| static |
max/min(Collection coll) |
| static |
max/min(Collection coll, Comparator comp) 根据指定比较器产生的顺序,返回给定 collection 的最大/最小元素。 |
d)逆序
| static |
reverseOrder() 返回一个比较器,它强行逆转实现了 Comparable 接口的对象 collection 的自然顺序。 |
| static |
reverseOrder(Comparator |
e)反转
| static void |
reverse(List list) 反转指定列表中元素的顺序。 |
f)替换
| static |
replaceAll(List |
g)其他方法
| static |
fill(List list, T obj) 使用指定元素替换指定列表中的所有元素。 |
| static void |
shuffle(List list) 使用默认随机源对指定列表进行置换(随机排序)。 |
h)返回同步的集合
| static |
synchronizedCollection(Collection |
| static |
synchronizedList(List |
| static |
synchronizedMap(Map |
| static |
synchronizedSet(Set |
6.2、JDK5.0特性-函数可变参数
public class Demo{
public static void main(String[] args){
int arr[] = { 1, 2, 3, 4, 5};
System.out.println(myAdd(arr));//15
int sum1 = myAdd(1, 2, 3, 4, 5);
System.out.println(sum1);//15
}
public static int myAdd(int... arr){ //其实就是(int arr[])
int sum = 0;
for (int i = 0; i < arr.length; i++){
sum += arr[i];
}
return sum;
}
}
7、泛型
1)泛型概述
泛型的定义:
泛型是JDK 1.5的一项新特性,它的本质是参数化类型的应用,也就是说所操作的数据类型被指定为一个参数,在用到的时候在指定具体的类型。这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口和泛型方法。
泛型的好处:
将运行时期的问题ClassCastException转到了编译时期。避免了强制转换的麻烦。Java泛型的设计原则是,只要代码在编译时没有出现警告,就不会遇到运行时ClassCastException异常。
为什么要用泛型:
由于Java语言里面所有的类型都继承于java.lang.Object,那Object转型为任何对象成都是有可能的。但是也因为有无限的可能性,就只有程序员和运行期的虚拟机才知道这个Object到底是个什么类型的对象。在编译期间,编译器无法检查这个Object的强制转型是否成功,如果仅仅依赖程序员去保障这项操作的正确性,许多ClassCastException的风险就会被转嫁到程序运行期之中。
public class Demo{
public static void main(String[] args) {
List list = new ArrayList();
list.add("aa");
list.add("bb");
list.add(100);
for (int i = 0; i < list.size(); i++) {
//当遇到的类型无法直接强转为String,就会抛出:java.lang.ClassCastException
String name = (String) list.get(i);
System.out.println("name:" + name);
/*复习:list.get(i)返回的Object对象,在编译时,不会有问题。但是在实际运行时这个Object的实际类型是Integer:obj = new Integer(100);这里将Integer转换为String就会报错了。因为Integer类和String类并没有直接的上下级关系。*/
}
}
}
//将运行时期的ClassCastException转到了编译时期。避免了强制转换的麻烦。
public class FanXingDemo {
public static void main(String[] args) {
List list1 = new ArrayList();
list1.add("a");
String name1 = list1.get(0);//这里没有进行强制类型转换,是因为已经告诉可编译器类型。在运行时期,通过获取元素的类型进行转换动作,不用使用者再强制转换了。-(这就是泛型补偿)
System.out.println(name1);
List list2 = new ArrayList();
list2.add("b");
String name2 = (String) list2.get(0);//不强制类型转换,无法通过编译
System.out.println(name2);
}
}
<>:什么时候用?
当操作的引用数据类型不确定的时候,就是用<>。将要操作的引用数据类型传入即可。其实<>就是一个用于接收具体引用数据类型的参数范围。
7.1、Java泛型实现原理:类型擦除
Java的泛型是伪泛型。在编译期间,所有的泛型信息都会被擦除掉。
Java中的泛型基本上都是在编译器这个层次来实现的。在生成的Java字节码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会在编译器在编译的时候去掉。这个过程就称为类型擦除。 如在代码中定义的List
List
List
System.out.println(list1.getClass());//class java.util.ArrayList
System.out.println(list2.getClass());//class java.util.ArrayList
类型擦除后保留的原始类型。例如:
class Pair {
private T value;
public T getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
}
原始类型:
class Pair {
private Object value;
public Object getValue() {
return value;
}
public void setValue(Object value) {
this.value = value;
}
}
//注:可以使用javap -c 命令查看字节码文件:

因为在Pair
如果泛型类型加了限定?-----public class Pair
T继承自Comparable,那么编译后类型擦除会把所有T类型参数替换为Comparable,即将其类型限定为Comparable。
为什么擦除呢?因为为了兼容运行时加载器。擦除这不是一个语言特性。它是Java的泛型实现中的一种折中,因为泛型不是Java语言出现时就有的组成部分,所以这种折中是必需的。泛型并不强制,现有的代码依旧合法,并且继续保存着之前的含义。
如果泛型类型的类型变量没有限定(
7.2、泛型类、泛型方法、泛型接口
7.2.1、泛型类
/**
* 不使用泛型以前的做法
*/
class Tool {
private Object object;
public Object getObject() {
return object;
}
public void setObject(Object object) {
this.object = object;
}
}
/**
* 使用泛型
* 编译时若本身无限定的则当做Object处理,有限定根据具体的限定来确定
* 只有在运行时才会真正根据类型来构造和分配内存。
*/
class Tool_Generic {
private T t;
public T getT() {
return t;
}
public void setT(T t) {
this.t = t;
}
}
public class GenericDemo {
public static void main(String[] args) {
// 不适用泛型,以前的做法
Tool tool=new Tool();
tool.setObject(new String("xiaoming"));
tool.setObject(new Integer(18));
Integer i = (Integer) tool.getObject();//当不小心改了一个其他类型,不注意时
//编译没问题,运行ClassCastException Student
String s =(String) tool.getObject();//不用泛型就需要强转
System.out.println(s);//java.lang.ClassCastException
Tool_Generic tool1 = new Tool_Generic();
tool1.setT(new String("xiaoming"));
//tool1.setT(new Integer(18));//编译时出错,限定为String
String s1 = tool1.getT(); //用泛型时,不需要我们强转,编译器帮我们完成
System.out.println(s1);
}
}
7.2.2、泛型方法
public class Tool {
// 将泛型定义在方法上
public void show(Q str) {
System.out.println("show:" + str);
}
public void print(T str){// 这个方法的泛型跟着对象走的
System.out.println("print:" + str);
}
// 这个方法的泛型不跟着对象走
public void method(Z str) {
System.out.println("method:" + str);
}
// 如果静态方法使用泛型时,只能将泛型定义在方法上。
public static void run(Y str) {
System.out.println("static :" + str);
}
// 当方法是静态时,不能访问类上定义的泛型
//Cannot make a static reference to the non-static type T
/*public static void run(T str) {
System.out.println("static :" + str);
}*/
public static void main(String[] args) {
Tool tool = new Tool();
/*可以看到方法的参数彻底泛化了,这个过程涉及到编译器的类型推导
和自动打包,也就说原来需要我们自己对类型进行的判断和处理,
现在编译器帮我们做了*/
tool.show("String"); tool.show(18);
tool.print("abc"); //tool.print(18);//编译不通过
tool.method("xixi");
tool.method(new Integer(12));
Tool.run("heihei");
Tool.run(new Integer(6));
}
}
7.2.3、泛型接口
public class GenericDemo2 {
public static void main(String[] args) {
InterImpl1 in = new InterImpl1();
in.show("haha");
InterImpl2 in2 = new InterImpl2();
in2.show(new Integer(5));
}
}
// 泛型接口,将泛型定义在接口上
interface Inter {
public void show(T t);
}
class InterImpl1 implements Inter {
public void show(String str) {
System.out.println("show:" + str);
}
}
class InterImpl2 implements Inter {
public void show(Q q) {
System.out.println("show:" + q);
}
}
7.3、泛型约束与局限性
<1>不能用基本类型实例化类型参数
其原因就在于类型擦除。(如类 List
<2>运行时类型查询只适用于原始类型
运行时:通常指在Classloader装载之后,JVM执行之时
类型查询:instanceof、getClass、强制类型转换
原始类型:即泛型类型经编译器类型擦除后是Object或泛型参数的限定类型(例如Pair
public class Pair {
private T value;
public T getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
static Map map1;
static Map map2;
static Map map3;
static void assign1(Map map) { map1 = map; }
//注: 当全是通配符时,编译器就无法将其与原生Map区分开来了
static void assign2(Map map) { map2 = map; }
static void assign3(Map map) { map3 = map; }
public static void main(String[] args) {
Pair a = new Pair();
System.out.println(new ArrayList().getClass());
System.out.println(new Pair().getClass());
System.out.println(a.getClass());
//if(a instanceof Pair){} //编译不通过:Cannot perform instanceof check against parameterized type Pair...
if(a instanceof Pair){} //编译通过
Pair p = (Pair) a; //编译通过,Warning
Pair i = new Pair();
System.out.println(((Pair) a).getClass() == i.getClass());//true
//警告:HashMap is a raw type. References to generic type HashMap should be parameterized
assign1(new HashMap());
//警告:HashMap is a raw type. References to generic type HashMap should be parameterized
assign2(new HashMap());
// 警告:The expression of type HashMap needs unchecked conversion to conform to Map
assign3(new HashMap());
/*在泛型中使用instanceof时,会抛出Cannot perform instanceof check against
parameterized type Pair. Use instead its raw form Pair since generic type
information will be erased at runtime错误。
字面意思是instanceof关键字不能用于参数化的类型判断,建议使用原生类型。
这个可能是java遗留的历史原因,因为在jdk5之前,java中没有泛型概念,而
instanceof在以前的版本中已经实现,因此使用该功能对泛型进行判断时,会
出现错误.
无界通配符看起来意味着“任何事物”,因此使用无界通配符好像等价于使用
原生类型。在这些情况中,可以被认为是一种装饰,但它仍旧很有价值,声
明了“我是想用Java的泛型来编写这段代码,我在这里并不是要用原生类型但在
这种情况下,泛型参数可以持有任何类型。
上面assign1()和assign2()显示同样的警告,也就是说,当全是通配符时,编
译器也无法将其与原生类型区分开。所有的类型查询,只产生原始类型。*/
}
}
<2>不能创建参数化类型的数组
数组在创建的时候必须知道内部元素的类型,而且会一直记得这个类型信息,这个类型就是在数组创建时确定的,每次往数组里添加元素都会做类型检查,他的使命就是提供一个类型安全和效率更高的容器。而事实上泛型只作用在编译期,运行时其类型会被擦除。所以不能创建参数化类型的数组。
List l = new ArrayList();
l.add("hello"); //黄色警告因为编译时 l静态绑定的是List接口的引用,他并没有限定泛型
String s = (String) l.get(0);//为此这里需要强转
List l1 = new ArrayList();
l1.add("world");
String s1 = l1.get(0);//加了泛型这里,编译器知道了他的类型,由编译器完成不需要我们强转
/*在Java中,Object[]数组可以是任何数组的父类,或者说,任何一个数组都可以向上转型成它在定义时指定元素类型的父类的数组,这个时候如果我们往里面放不同于原始数据类型 但是满足后来使用的父类类型的话,编译不会有问题,但是在运行时会检查加入数组的对象的类型,于是会抛ArrayStoreException*/
String[] str = new String[]{"a","b"};
Object[] obj = str;
obj[0] = new Integer(1);//java.lang.ArrayStoreException
Map[] mapArray = new Map[2];//不允许创建泛型数组
Map[] mapArray1 = new Map[2];//不允许创建泛型数组
//假如允许创建泛型数组的话:
Object[] obj1= mapArray;
obj1[0]= mapArray1[0];
//那么这样在存入数组元素时,由于类型擦除,往里面存放的都是Map对象,被认为是合法的,连数组类型检查都无能为力
//本来是定义的Map型数组结果我们可以往里面放任何类型的Map,这样做肯定是不安全的
<3>其他局限
a)不能实例化类型变量
public class Pair {
public T getValue() {
T t = new T();//Cannot instantiate the type T
} //擦除后就是Object 这并不是我们真正希望动态创建的
} b)泛型类的静态上下文不能变量无效
c)不能抛出或捕获泛型类的实例
7.4、通配符
7.4.1、通配符概述
注:如果Foo是Bar的一个子类型(子类或者子接口),而G是具有泛型声明的类或接口,G
下面合法吗:
List
Listlo = ls; //2
lo.add(new Object());
String s = ls.get(0); //试图把Object赋值给String
Object obj = new Object();
String s = new String();
s =(String) obj;//3
解答:1是合法的;2是不合法的(编译不通过)。3编译通过,但是会出现类型转换异常。
Object是任何类的父类,编译通过。而List不是List
子类转到父类是自动的,必然的。父类向子类转型,是可能的。父类转向子类前可以用instanceof操作(用于判断子类对象是否是父类的类型)。抛出类型转换异常的,是因为:事实上父类是不可以转子类的。因为父类创建对象时根本没有记录子类任何的信息。之前看到的强制转换,即向下转型的一个很重要的前提就是:在发生向下转型之前,一定发生过向上转型。只有当父类本身指向的就是一个子类对象(多态),才能进行强制转换。
由于固定的泛型类型有很多限制因素。尤其是在继承上。泛型不会自动向上转型,为此java的设计者发明了一种巧妙的解决方案-----通配符。通配符有三种形式:
a)无限定通配符 形式
b)上边界限定通配符 形式< ? extends T>
c)下边界限定通配符 形式< ? super T>
向上转型构造一个泛型对象的引用
向下转型构造一个泛型对象的引用
7.4.2、无限定通配符
使用原生态类型,就失掉了泛型在安全性和表述性方面的所有优势。既然不应该使用原生态类型,为什么Java设计还要允许使用它们呢?这是为了提供兼容性,要兼容以前没有使用泛型的Java代码。
无界通配符看起来意味着“任何事物,具有某种特定的非原生类型”。直接写?,等同于? extends Object这里的"?"就代表了对这个其中的元素没有限制或者根本不关心。在提供了方便性的同时它也有一个很大的限制,那就是使用了无限制通配符类型的泛型比如:List,是不能添加任何元素进去的,除非是null。
Java中使用泛型“T”,代表一个变量的类型,“?”不能作为一个变量类型使用。后者一般用于只读模式。如果你既想存,又想取,那就别用通配符。
7.4.3、上边界限定通配符
表示类型的上界,表示参数化类型的可能是T 或是 T的子类。extends 可用于的返回类型限定,不能用于参数类型限定。如果你想从一个数据类型里获取数据,使用 ? extends 通配符
public class GenericType {
static class Food{}
static class Fruit extends Food{}
static class Apple extends Fruit{}
static class RedApple extends Apple{}
public static void main(String[] args) {
/**
* List
* 表示具有任何从Fruit继承类型的列表
* elist 编译期 类型可以是任何继承Fruit的子类类型
* 编译器无法确定elist的真实类型,所以无法安全的向其中添加对象。
* 但是可以添加null,null可以表示任何类型
*/
List elist = new ArrayList(); //1
//elist.add(new Apple()); //编译不通过
//elist.add(new Fruit()); //编译不通过
elist.add(null);
//List elist = new ArrayList(); //2
//List elist2 = new ArrayList(); //编译不通过
/**
* 由于其中放置的是从Fruit中继承的类型,所以可以安全的取出。父
* 类的引用指向子类的对象不需要强转,也不会出现类型转换异常。
* 当我们在读取数据时,能确保得到的数据是一个Fruit类型的实例
*/
Fruit fruit = elist.get(0); //3
Apple apple = (Apple) elist.get(0);
}
}
7.4.4、下边界通配符--通配符的超类限定
表示类型下界,表示参数化类型是该类型或他的超类型,直至Object。即该引用可以接收的类型的下界就是T。super 可用于参数类型限定,不能用于返回类型限定。如果你想把对象写入一个数据结构里,使用 ? super 通配符
public class GenericType {
static class Food{}
static class Fruit extends Food{}
static class Apple extends Fruit{}
static class RedApple extends Apple{}
public static void main(String[] args) {
/**
* List
* 表示具有任何Fruit超类的列表,列表的类型至少是一个Fruit类型,因此可以
* 安全的向其中添加Fruit及其子类类型。
*/
List slist = new ArrayList(); //1
slist.add(new Fruit());
slist.add(new Apple());
/**
*由于List中的类型可能是任何Fruit的超类型,无法将其赋值为
*Fruit的子类型Apple的List
*/
//List slist1 = new ArrayList();//2编译不通过
/**
* List 3中不会报错
* slist(可能是1也可能是3)编译期可能是Fruit类型或其超类型。但是在实际
* 运行时其具体类型我们不知道是Fruit还是
* 他的超类型,为此4编译不通过,如果是其超类型,直接向下转型会出现类型
* 转换异常
*/
//List slist = new ArrayList(); //3
//Fruit item = slist.get(0); //4 编译不通过
}
}
--------------------------------------------------------------------------------------内容过多下篇续--------------------------------------------------------------