mysql数据库面试题
一、mysql的存储引擎有哪些?都有什么特点?

- MyISAM: 拥有较高的插入,查询速度,但不支持事务。
- InnoDB :5.5版本后Mysql的默认数据库,事务型数据库的首选引擎,支持ACID事务,支持行级锁定
- BDB: 源自Berkeley DB,事务型数据库的另一种选择,支持COMMIT和ROLLBACK等其他事务特性
- Memory :所有数据置于内存的存储引擎,拥有极高的插入,更新和查询效率。但是会占用和数据量成正比的内存空间。并且其内容会在Mysql重新启动时丢失
- Merge :将一定数量的MyISAM表联合而成一个整体,在超大规模数据存储时很有用
- Archive :非常适合存储大量的独立的,作为历史记录的数据。因为它们不经常被读取。Archive拥有高效的插入速度,但其对查询的支持相对较差
- Federated: 将不同的Mysql服务器联合起来,逻辑上组成一个完整的数据库。非常适合分布式应用 Cluster/NDB :高冗余的存储引擎,用多台数据机器联合提供服务以提高整体性能和安全性。适合数据量大,安全和性能要求高的应用
- CSV: 逻辑上由逗号分割数据的存储引擎。它会在数据库子目录里为每个数据表创建一个.CSV文件。这是一种普通文本文件,每个数据行占用一个文本行。CSV存储引擎不支持索引。
- BlackHole :黑洞引擎,写入的任何数据都会消失,一般用于记录binlog做复制的中继
另外,Mysql的存储引擎接口定义良好。有兴趣的开发者通过阅读文档编写自己的存储引擎。
二、用一条SQL语句查询出每门课都大于80分的学生姓名

解析:
1、只需name字段
2、需所有课程(2门)的fenshu字段均>80——>where筛选条件,count计算筛选where后是否不少于2门高于80分
3、显示的结果不重复——>group by
select name from users
where fenshu >= 80
group by name
having count(name) >= 2;
三、按格式查询结果,将上图查询出下图结果(行转列)

解析:
1、每年只4个月
2、由于是求每月总金额——> SUM函数(可据实际替换成AVG、MAX、MIN)
3、别名要求M1-M4——> as
4、如果某个月份无金额则为0——> if函数(和三目运算符一样)
5、显示结果不重复——> group by
SELECT year,
SUM(IF(`month`=1,amount,0)) as 'M1',
SUM(IF(`month`=2,amount,0)) as 'M2',
SUM(IF(`month`=3,amount,0)) as 'M3',
SUM(IF(`month`=4,amount,0)) as 'M4'
FROM Bill
GROUP BY year
PS:列转行
使用uinon进行语句查询连接,all使得允许出现重复值
(union要求列数相同,列数据类型相同,顺序相同)
select year,1 as month,M1 as amount from Bill
union all
select year,2 as month,M2 as amount from Bill
union all
select year,3 as month,M3 as amount from Bill
union all
select year,4 as month,M4 as amount from Bill
order by years
四、将上表查询出下图结果(行转列+字符串连接concat)
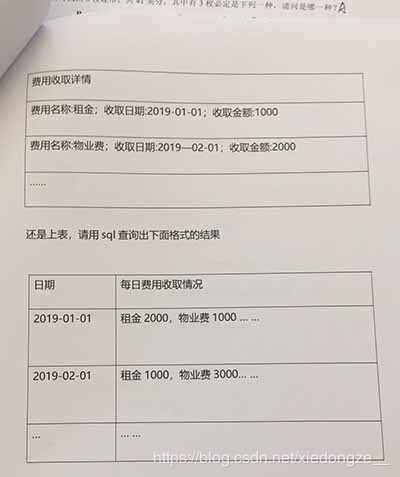
解析:
1、日期不变,使用别名——>as
2、第二列字段要求所有当月费用连接在一起——>concat()
3、显示结果不重复——>group by
Select date as '日期',
concat('租金',IF(`fee_name`='租金',amount,0),',','物业费',IF(`fee_name`='物业费',amount,0)) as '每月费用收取情况'
from Bill
group by date
五、优化sql语句

limit知识点:
① selete * from testtable limit 2,1;
② selete * from testtable limit 2 offset 1;
①是从数据库中第三条开始查询,取一条数据,即第三条数据读取,一二条跳过
②是从数据库中的第二条数据开始查询两条数据,即第二条和第三条。
由于id为主键索引,所以使用嵌套查询所需的10个id,再进行内连接筛选
1、题目的sql会访问1000010次数据页。而优化后的1的sql只访问10次数据页
select * from user u1
inner join (select id from user limit 1000000,10) u2 on u1.id=u2.id
2、适合id连续的系统,速度极快。不适合带有条件的、id不连续的查询
select * from user
where id between 1000000 and 1000010
order by id desc