深入浅出DPDK阅读笔记
深入浅出DPDK
第一章 概述
第二章 Cache和内存
Cache预取
DPDK会在代码层面对数据报文做预取
Cache一致性
要解决以下两个问题:
1、Cache对齐
2、多核访问的冲突
解决方法:
1、数据定义边界对齐
2、每个核单独享有自己的数据结构
3、对于必然同时访问的临界区,对于网络端口而讲,网卡有多队列,每个核用自己的队列。其他的临界区——应该不可避免要用一些窥探协议来处理
TLB问题与大页
如果采用常规页(4KB) 并且使TLB总能命中, 那么至少需要在TLB表中存放两个表项, 在这种情况下, 只要寻址的内容都在该内容页内, 那么两个表项就足够了。 如果一个程序使用了512个内容页也就是2MB大小, 那么需要512个页表表项才能保证不会出现TLB不命中的情况。 通过上面的介绍, 我们知道TLB大小是很有限的, 随着程序的变大或者程序使用内存的增加, 那么势必会增加TLB的使用项, 最后导致TLB出现不命中的情况。
解决方法:使用大页
DDIO
Data Direct I/O技术。
当一个网络报文送到服务器的网卡时, 网卡通过外部总线(比如PCI总线) 把数据和报文描述符送到内存。 接着, CPU从内存读取数据到Cache进而到寄存器。 进行处理之后, 再写回到Cache, 并最终送到内存中。 最后, 网卡读取内存数据, 经过外部总线送到网卡内部, 最终通过网络接口发送出去。可以看出, 对于一个数据报文, CPU和网卡需要多次访问内存。 而内存相对CPU来讲是一个非常慢速的部件。 CPU需要等待数百个周期才能拿到数据, 在这过程中, CPU什么也做不了。
DDIO技术是如何改进的呢? 这种技术使外部网卡和CPU通过LLC Cache(Last Level Cache)直接交换数据, 绕过了内存这个相对慢速的部件。 这样, 就增加了CPU处理网络报文的速度(减少了CPU和网卡等待内存的时间) , 减小了网络报文在服务器端的处理延迟。 这样做也带来了一个问题, 因为网络报文直接存储在LLC Cache中, 这大大增加了对其容量的需求, 因而在英特尔的E5处理器系列产品中, 把LLC Cache的容量提高到了20MB。
NUMA系统
DPDK在NUMA系统中的一些实例:
1) Per-core memory。 一个处理器上有多个核(core) , per-core memory是指每个核都有属于自己的内存, 即对于经常访问的数据结构, 每个核都有自己的备份。 这样做一方面是为了本地内存的需要, 另外一方面也是因为上文提到的Cache一致性的需要, 避免多个核访问同一个Cache行。
2) 本地设备本地处理。 即用本地的处理器、 本地的内存来处理本地的设备上产生的数据。 如果有一个PCI设备在node0上, 就用node0上的核来处理该设备, 处理该设备用到的数据结构和数据缓冲区都从node0上分配。 以下是一个分配本地内存的例子:
/* allocate memory for the queue structure */
q = rte_zmalloc_socket("fm10k", sizeof(*q), RTE_CACHE_LINE_SIZE, socket_id);
该例试图分配一个结构体, 通过传递socket_id, 即node id获得本地内存, 并且以Cache行对齐。
第三章 并行计算
多核并行计算的吞吐率随核数增加而线性扩展, 可并行处理部分占整个任务比重越高, 则增长的斜率越大。 带着这个观点来读DPDK, 很多实现的初衷就豁然开朗。 资源局部化、 避免跨核共享、 减少临界区碰撞、 加快临界区完成速率(后两者涉及多核同步控制, 将在下一章中介绍)等, 都不同程度地降低了不可并行部分和并发干扰部分的占比。
亲和性
线程独占:
DPDK通过把线程绑定到逻辑核的方法来避免跨核任务中的切换开销, 但对于绑定运行的当前逻辑核, 仍然可能会有线程切换的发生, 若希望进一步减少其他任务对于某个特定任务的影响, 在亲和的基础上更进一步, 可以采取把逻辑核从内核调度系统剥离的方法。Linux内核提供了启动参数isolcpus。 对于有4个CPU的服务器, 在启动的时候加入启动参数isolcpus=2, 3。 那么系统启动后将不使用CPU3和CPU4。 注意, 这里说的不使用不是绝对地不使用, 系统启动后仍然可以通过taskset命令指定哪些程序在这些核心中运行。
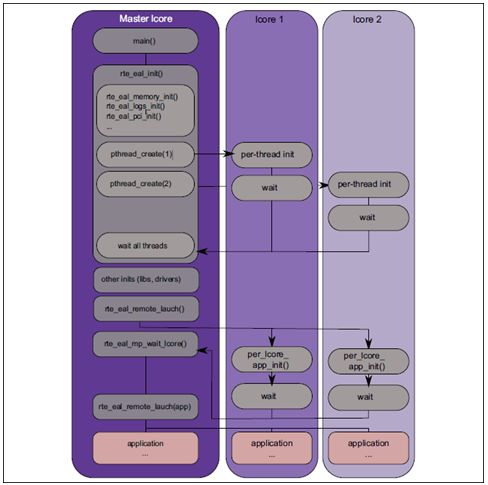
DPDK的线程基于pthread接口创建, 属于抢占式线程模型, 受内核调度支配。 DPDK通过在多核设备上创建多个线程, 每个线程绑定到单独的核上, 减少线程调度的开销, 以提高性能。
DPDK的线程可以作为控制线程, 也可以作为数据线程。 在DPDK的一些示例中, 控制线程一般绑定到MASTER核上, 接受用户配置, 并传递配置参数给数据线程等; 数据线程分布在不同核上处理数据包。
EAL中提供lcore来提供EAL线程,可以与核进行绑定。
单指令多数据SIMD
DPDK中的memcpy就利用到了SSE/AVX的特点。 比较典型的就是rte_memcpy内存拷贝函数。 内存拷贝是一个非常简单的操作, 算法上并无难度, 关键在于很好地利用处理器的各种并行特性。 当前Intel的处理器(例如Haswell、 Sandy Bridge等) 一个指令周期内可以执行两条Load指令和一条Store指令, 并且支持SIMD指令(SSE/AVX) 来在一条指令中处理多个数据, 其Cache的带宽也对SIMD指令进行了很好的支持。 因此, 在rte_memcpy中, 我们使用了平台所支持的最大宽度的Load和Store指令(Sandy Bridge为128bit, Haswell为256bit) 。 此外, 由于非对齐的存取操作往往需要花费更多的时钟周期, rte_memcpy优先保证Store指令存储的地址对齐, 利用处理器每个时钟周期可以执行两条Load这个超标量特性来弥补一部分非对齐Load所带来的性能损失。 更多信息可以参考[Ref3-3] 。
例如, 在Haswell上, 对于大于512字节的拷贝, 需要按照Store地址进行对齐。
/**
* Make store aligned when copy size exceeds 512 bytes
*/
dstofss = 32 - ((uintptr_t)dst & 0x1F);
n -= dstofss;
rte_mov32((uint8_t *)dst, (const uint8_t *)src);
src = (const uint8_t *)src + dstofss;
dst = (uint8_t *)dst + dstofss;
在Sandy Bridge上, 由于非对齐的Load/Store所带来的的额外性能开销非常大, 因此, 除了使得Store对齐之外, Load也需要进行对齐。 在操作中, 对于非对齐的Load, 将其首尾未对齐部分多余的位也加载进来,因此, 会产生比Store指令多一条的Load。
第四章 同步互斥机制
提供了一套自己的内存屏障、互斥、读写锁、SPIN锁、无锁环形队列
第五章 报文转发
报文处理模块划分

浅色和阴影部分都是对应模块和硬件相关的,所以提升这部分性能最佳的选择是尽量多的选择网卡上的或设备芯片提供的网络特定功能相关的卸载的特性,深色软件部分可以通过提高算法的效率和结合CPU相关的并行指令来提升网络性能,了解网络处理模块的基本组成部分后,我们再来看看不同的转发框架如何让这些模块协同工作完成网络包的处理的
转发框架介绍
2.1 流水线模型(pipeline)
pipeline 借鉴与工业上的流水线模型,将整个功能拆分成多个独立的阶段,不同阶段通过队列传递产品。这样对于一些CPU密集和I/O密集的应用,将I/O密集的操作放在另一个微处理器引擎上执行。通过过滤器可以分为不同的操作分配不同的线程,通过队列匹配两个速度,达到最好的并发,

我们可以看到图中,TOP(Task Optimized Processor)单元,每个TOP单元都是对特定的事物进行优化处理的特殊微单元
2.2 run to completion 模型
这个模型是DPDK针对一般的程序的运行方法,一个程序分为几个不同的逻辑功能,几个逻辑功能会在一个CPU的核上运行,我们下面看下模型的视图
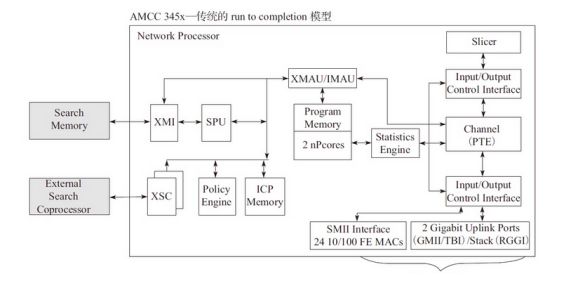
这个模型没有对报文特殊处理的的运算单元,只有两个NP核, 两个NP核利用已烧录的微码进行报文处理
2.3 转发模型对比
从run to completion的模型中,我们可以清楚地看出,每个IA的物理核都负责处理整个报文的生命周期从RX到TX,这点非常类似前面所提到的AMCC的nP核的作用。在pipeline模型中可以看出,报文的处理被划分成不同的逻辑功能单元A、B、C,一个报文需分别经历A、B、C三个阶段,这三个阶段的功能单元可以不止一个并且可以分布在不同的物理核上,不同的功能单元可以分布在相同的核上(也可以分布在不同的核上),从这一点可以看出,其对于模块的分类和调用比EZchip的硬件方案更加灵活。
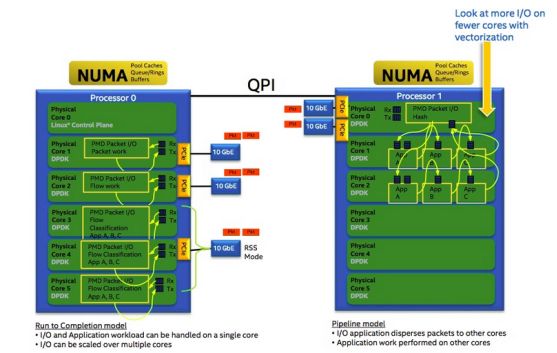
两个的优缺点:

转发算法
除了良好的转发框架之外,转发中很重要的一部分内容就是对于报文字段的匹配和识别,在DPDK中主要用到了精确匹配(Exact Match)算法和最长前缀匹配(Longest Prefix Matching,LPM)算法来进行报文的匹配从而获得相应的信息。精确匹配主要需要解决两个问题:进行数据的签名(哈希),解决哈希的冲突问题,DPDK中主要支持CRC32和J hash。
最长前缀匹配(Longest Prefix Matching,LPM)算法是指在IP协议中被路由器用于在路由表中进行选择的一个算法。当前DPDK使用的LPM算法就利用内存的消耗来换取LPM查找的性能提升。当查找表条目的前缀长度小于24位时,只需要一次访存就能找到下一条,根据概率统计,这是占较大概率的,当前缀大于24位时,则需要两次访存,但是这种情况是小概率事件。
ACL库利用N元组的匹配规则去进行类型匹配,提供以下基本操作:

Packet distributor(报文分发)是DPDK提供给用户的一个用于包分发的API库,用于进行包分发。主要功能可以用下图进行描述:

精确匹配算法
相当于使用了Hash算法
最长匹配算法
使用了两级表。针对IPv4路由查找,一级是2^24个条目,二级是2^8的条目。用空间换时间。
第六章 PCIe与包处理I/O
Mbuf与Mempool
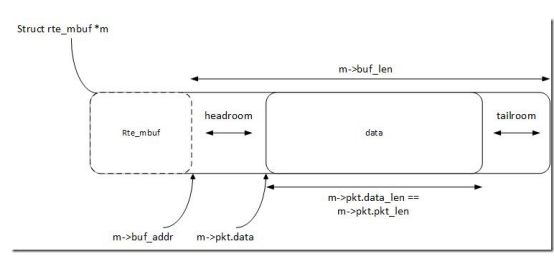
数据结构rte_mbuf可以承载网络数据包buffer或者通用控制消息buffer(由CTRL_MBUF_FLAG指示)。 也可以扩展到其他类型。 rte_mbuf头部结构尽可能小,目前只使用两个缓存行,最常用的字段位于第一个缓存行中
为了存储数据包数据(报价协议头部), 考虑了两种方法:
在单个存储buffer中嵌入metadata,后面跟着数据包数据固定大小区域
为metadata和报文数据分别使用独立的存储buffer。
第一种方法的优点是他只需要一个操作来分配/释放数据包的整个存储表示。 但是,第二种方法更加灵活,并允许将元数据的分配与报文数据缓冲区的分配完全分离。
DPDK选择了第一种方法。 Metadata包含诸如消息类型,长度,到数据开头的偏移量等控制信息,以及允许缓冲链接的附加mbuf结构指针。
用于承载网络数据包buffer的消息缓冲可以处理需要多个缓冲区来保存完整数据包的情况。 许多通过下一个字段链接在一起的mbuf组成的jumbo帧,就是这种情况。
对于新分配的mbuf,数据开始的区域是buffer之后 RTE_PKTMBUF_HEADROOM 字节的位置,这是缓存对齐的。 Message buffers可以在系统中的不同实体中携带控制信息,报文,事件等。 Message buffers也可以使用起buffer指针来指向其他消息缓冲的数据字段或其他数据结构。
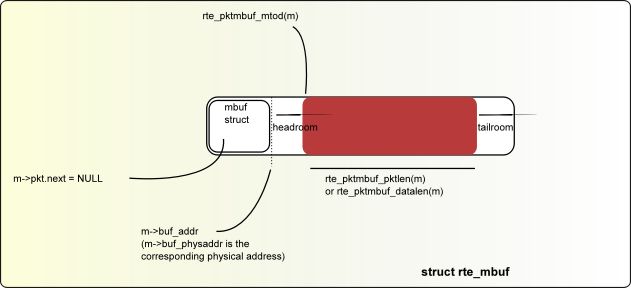
Fig. 6.1 An mbuf with One Segment
多核CPU访问同一个内存池或者同一个环形缓存区时, 因为每次读写时都要进行Compare-and-Set操作来保证期间数据未被其他核心修改,所以存取效率较低。 DPDK的解决方法是使用单核本地缓存一部分数据, 实时对环形缓存区进行块读写操作, 以减少访问环形缓存区的次数。 单核CPU对自己缓存的操作无须中断, 访问效率因而得到提高。 当
然, 这个方法也并非全是好处: 该方法要求每个核CPU都有自己私用的缓存(大小可由用户定义, 也可为0, 或禁用该方法) , 而这些缓存在绝大部分时间都没有能得到百分之百运用, 因此一部分内存空间将被浪费。
第七章 网卡性能优化
DPDK的轮询模式
DPDK采用了轮询或者轮询混杂中断的模式来进行收包和发包, 此前主流运行在操作系统内核态的网卡驱动程序基本都是基于异步中断处理模式。
DPDK的混合中断轮询机制是基于UIO或VFIO来实现其收包中断通知与处理流程的。 如果是基于VFIO的实现, 该中断机制是可以支持队列级别的, 即一个接收队列对应一个中断号, 这是因为VFIO支持多MSI-X中断号。 但如果是基于UIO的实现, 该中断机制就只支持一个中断号, 所有的队列共享一个中断号。
网卡I/O性能优化
使用Burst收发包:把收发包复杂的处理过程进行分解,打散成不同的相对较小的处理阶段,把相邻的数据访问、相似的数据运算集中处理。尽可能减少内存或低一级的处理器缓存的访问次数。即一次完成多个数据包的收发。
平台优化及其配置调优
不同的硬件平台,可以做对应的配置。
第八章 流分类与多队列
Linux内核对多队列的支持
-
多队列对应的结构:Linux的网卡由结构体net_device表示,一个该结构可以对应多个可以调度的数据包发送队列,数据包的实体在内核中以结构体sk_buff(skb)表示
-
接收端:网卡驱动程序为每个接收队列设定相应的中断号,通过中断的均衡处理,或者设置中断的亲和性,从而实现队列绑定到不同的核。
-
发送端:Linux提供了较为灵活的队列选择机制。dev_pick_tx用于选取发送队列,他可以是driver定制的策略,也可以根据队列优先级选取,按照hash做均衡。将队列分配给某个或某几个CPU处理,这样就可以减少锁竞争。
-
收发队列一般会被绑在同一个中断上。如果从收队列1收上来的包从发队列1发出去,cache命中率高,效率也会高。
对于单队列的网卡设备,就需要用软件来均衡流量。
DPDK与多队列
DPDK提供了一系列以太设备的API,其Packt I/O机制具有与生俱来的多队列支持功能,可以根据不同的平台或者需求,选择需要使用的队列数目,并可以很方便地使用队列,指定队列发送或接收报文。
DPDK的队列管理机制还可以避免多核处理器中的多个收发进程采用自旋锁产生的不必要的等待。
以run to completion模型为例,可以从核、内存与网卡队列之间的关系来理解DPDK是如何利用网卡多队列技术带来性能的提升。
-
将网卡的某个接收队列分配给某个核,从该队列中收到的所有报文都应当在该指定的核上处理结束
-
从核对应的本地存储中分配内存池,接收报文和对应的描述符都位于该内存池
-
为每个核分配一个单独的发送队列,发送报文和对应的报文描述符都位于该核和发送队列对应的本地内存池中。
RSS
Receive-Side Scaling:接收方扩展,和硬件相关,需要有网卡的硬件进行支持,RSS把数据包分配到不同的队列中,其中哈希值的计算公式在硬件中完成,也可以定制修改。关键字通常是五元组相关。
Flow Derector
由Intel公司提出的根据包的字段精确匹配,将其分配到某个特定队列的技术
第九章 硬件加速与功能卸载
需要网卡支持
第十章 X86平台上的I/O虚拟化
DPDK支持半虚拟化的前端virtio和后端vhost,并且对前后端都有性能加速的设计。对于I/O透传,DPDK可以直接在客户机里使用,就像在宿主机里,直接接管物理设备,进行操作。
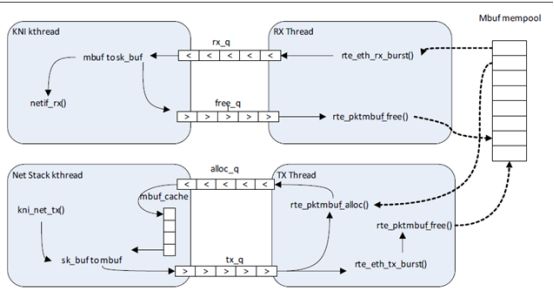
KNI图片: