Rethinking the value of network pruning
最近将High-way的思想用到了步态识别上,我觉得应该算是一个创新点,但是小伙伴建议我读一读Rethinking the value of resnet ,或许会对我有所启发。所以今天就来拜读一下。主要是翻译的形式,一段英文一段中文。
补充:好伤心,当我把步态识别的跨角度问题的准确率平均提高了8个百分点后,群里的小伙伴们建议我读一读Rethinking the value of resnet,然后我在谷歌上搜呀搜,找呀找,才找见这个与他们说的相似的文章Rethinking the value of network pruning。虽然和我想找的论文题目不一样,但是或许内容是一样的呢,毕竟只能查到这一篇文章,然后等我翻译完,理解完,发现完全不一样时,我又去问了群里的小伙伴,他们说,他们说,我们当时只是开玩笑的,你别当真。呜呜呜~~~,一个人开玩笑也就算了,那么多人一起开玩笑,还都辣么认真。哎,我什么时候能改掉别人随便说说我就当真的坏毛病。所以这篇文章是讲network pruning的,不是讲the value of resnet的。
Abstract
Network pruning is widely used for reducing the heavy computational cost of deep networks. A typical pruning algorithm is a three-stage pipeline, i.e., training (a large model), pruning and fine-tuning, and each of the three stages is considered as indispensable. In this work, we make several surprising observations which contradict common beliefs. For all the six state-of-the-art pruning algorithms we examined, fine-tuning a pruned model only gives comparable or even worse performance than training that model with randomly initialized weights. For pruning algorithms which assume a predefined architecture of the target pruned network, one can completely get rid of the pipeline and directly train the target network from scratch. Our observations are consistent for a wide variety of pruning algorithms with multiple network architectures, datasets, and tasks. Our results have several implications: 1) training an over-parameterized model is not necessary to obtain an efficient final model, 2) learned “important” weights of the large model are not necessarily helpful for the small pruned model, 3) the pruned architecture itself, rather than a set of inherited “important” weights, is what leads to the efficiency benefit in the final model, which suggests that some pruning algorithms could be seen as performing network architecture search.
摘要
网络修剪被广泛用于降低深度网络的繁重计算成本。典型的修剪算法是三阶段流程,即训练(大型模型),修剪和微调,并且三个阶段中的每一个被认为是必不可少的。在这项工作中,我们做出了几个与常见观点相矛盾的令人惊讶的观察。对于我们测试的所有六种最先进的修剪算法,对修剪后的模型进行微调只能提供与使用随机初始化权重训练模型相当甚至更差的性能。对于目标修剪网络的预定义体系结构的修剪算法,可以完全摆流程道并直接从头开始训练目标网络。我们的观察结果与具有多种网络架构,数据集和任务的各种修剪算法一致。我们的结果有几个含义:1)训练过度参数化的模型不是获得有效的最终模型所必需的; 2)学习的大型模型的“重要”权重不一定有助于修剪后的小型模型,3)修剪的体系结构本身,而不是一组继承的“重要”权重,导致最终模型的效率优势,这表明一些修剪算法可以被视为表征网络架构探索。
introduction
Over-parameterization is a widely-recognized property of deep neural networks (Denton et al., 2014; Ba & Caruana, 2014), which leads to high computational cost and high memory footprint. As a remedy, network pruning (LeCun et al., 1990; Hassibi & Stork, 1993; Han et al., 2015; Molchanov et al., 2016; Li et al., 2017) has been identified as an effective technique to improve the efficiency of deep networks for applications with limited computational budget. A typical procedure of network pruning consists of three stages: 1) train a large, over-parameterized model, 2) prune the trained large model according to a certain criterion, and 3) fine-tune the pruned model to regain the lost performance.
过度参数化是深度神经网络的广泛认可的属性(Denton等人,2014; Ba&Caruana,2014),这导致高计算成本和高内存占用。 作为一种补救措施,网络修剪(LeCun等,1990; Hassibi&Stork,1993; Han等,2015; Molchanov等,2016; Li等,2017)已被确定为一种对于应用在应用程序的深度网络且计算预算有限的情况下的有效的改进技术。网络修剪的典型过程包括三个阶段:1)训练大型的过度参数化的模型,2)根据特定标准修剪训练的大模型,以及3)微调修剪的模型以重新获得丢失的性能。
Generally, there are two common beliefs behind this pruning procedure. First, it is believed that starting with training a large, over-parameterized network is important (Luo et al., 2017), as it provides a high-performance model (due to stronger representation & optimization power) from which one can remove a set of redundant parameters without significant hurting the accuracy. This is usually reported to be superior to directly training a smaller network from scratch. Second, both the pruned architecture and its associated weights are believed to be essential for obtaining the final efficient model. Thus most existing pruning techniques choose to fine-tune a pruned model instead of training it from scratch. The preserved weights after pruning are usually considered to be critical, as how to accurately select the set of important weights is a very active research topic in the literature (Han et al., 2015; Hu et al., 2016; Li et al., 2017; Liu et al., 2017; Luo et al., 2017; He et al., 2017b;Ye et al., 2018).
通常,这种修剪程序背后有两个共同的信念。首先,人们认为先训练大型、过度参数化的网络是很重要的(Luo et al。,2017),因为它提供了一个高性能模型(由于更强的表征和优化能力),这个高性能模型可以删除一系列冗余参数并且对于模型的精度没有明显损害。据报道,这通常优于直接从头开始训练较小的网络。其次,被修剪的体系结构及其相关权重被认为是获得最终有效模型所必需的。因此,大多数现有的修剪技术选择微调修剪的模型而不是从头开始训练。修剪后保留的权重通常被认为是关键的,因为如何准确地选择一组重要的权重是学术界中非常活跃的研究课题(Han et al。,2015; Hu et al。,2016; Li et al。,2017; Liu等人,2017; Luo等人,2017; He等人,2017b; Ye等人,2018)。
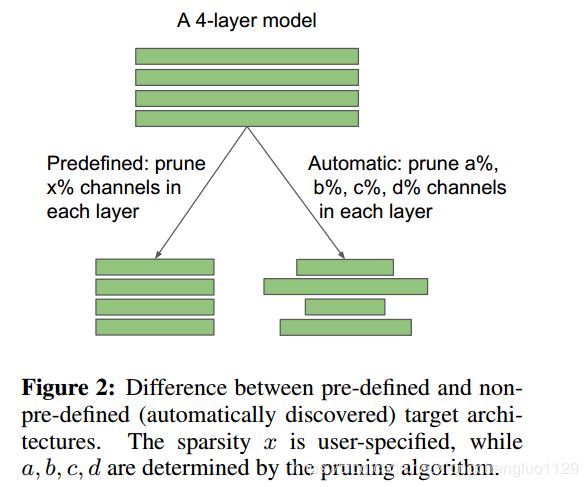
In this work, we show that both of the beliefs mentioned above are not necessarily true. Based on an extensive empirical evaluation of existing pruning algorithms on multiple datasets with multiple network architectures, we make two surprising observations. First, for pruning algorithms with pre-defined target network architectures (Figure 2), directly training the small target model from random initialization can achieve the same, if not better, performance, as the model obtained from the three-stage pipeline. This implies that starting with a large model is not necessary. Second, for pruning algorithms without a pre-defined target network, training the pruned model from scratch can also achieve comparable or even better performance than fine-tuning. This observation shows that for these pruning algorithms, what matters is the obtained architecture, instead of the preserved weights, despite training the large model is required to find that target architecture. The contradiction between our results and those reported in the literature might be explained by less carefully chosen hyper-parameters, data augmentation scheme and unfair computation budget for training.
在这项工作中,我们表明上面提到的两种信念都不一定正确。基于对具有多个网络架构的多个数据集的现有剪枝算法的广泛经验评估,我们做出了两个令人惊讶的观察。首先,对于具有预定义目标网络体系结构的修剪算法(图2),从随机初始化直接训练小目标模型可以实现与从三级流水线获得的模型相同(如果不是更好)的性能。这意味着不需要从大型模型开始。其次,对于没有预定义目标网络的修剪算法,从头开始训练修剪模型也可以实现与微调相当或甚至更好的性能。这一观察表明,对于这些修剪算法,重要的是获得的体系结构,而不是保留的权重,尽管训练需要大模型来找到目标体系结构是必须的。 我们的结果与文献中报道的结果之间的矛盾可能是通过较少精心选择的超参数,数据增强方案和不公平的训练所需的计算资源预算来解释的。
Our results advocate a rethinking of existing network pruning algorithms. It seems that the overparameterization during the first-stage training is not as beneficial as previously thought. Also, inheriting weights from a large model is not necessarily optimal, and might trap the pruned model into a bad local minimum, even if the weights are considered “important” by the pruning criterion. Instead, our results suggest that the value of some pruning algorithms may lie in identifying efficient structures and performing architecture search, rather than selecting “important” weights. We verify this hypothesis through a set of carefully designed experiments described in Section5.
我们的结果提倡重新思考现有的网络修剪算法。似乎训练的第一阶段期间的过度参数化并不像以前认为的那样有益。 此外,从大型模型继承权重不一定是最优的,并且可能将修剪后的模型陷入不良局部最小值,即使权重被修剪标准视为“重要”。 相反,我们的结果表明,一些修剪算法的价值可能在于识别有效结构和执行架构搜索,而不是选择“重要”权重。 我们通过第5节中描述的一系列精心设计的实验验证了这一假设。
The rest of the paper is organized as follows: in Section 2, we introduce the background and some related works on network pruning; in Section 3, we describe our methodology for training the pruned model from scratch; in Section 4 we experiment on various pruning methods to show our main results for both pruning methods with pre-defined or automatically discovered target architectures; in Section 5, we argue that the value of some pruning methods indeed lies in searching efficient network architectures, as supported by experiments; in Section 6 we discuss some implications and conclude the paper.
本文的其余部分安排如下:在第2节中,我们介绍了网络修剪的背景和一些相关工作; 在第3节中,我们描述了从头开始训练修剪模型的方法; 在第4节中,我们尝试了各种修剪方法,以显示我们对具有预定义或自动发现的目标体系结构的修剪方法的主要结果; 在第5节中,我们认为一些修剪方法的价值确实在于搜索有效的网络架构,正如实验所支持的那样; 在第6节中,我们讨论了一些含义并总结了论文。
Recent success of deep convolutional networks (Girshick et al., 2014; Long et al., 2015; He et al., 2016; 2017a) has been coupled with increased requirement of computation resources. In particular, the model size, memory footprint, the number of computation operations (FLOPs) and power usage are major aspects inhibiting the use of deep neural networks in some resource-constrained settings. Those large models can be infeasible to store, and run in real time on embedded systems. To address this issue, many methods have been proposed such as low-rank approximation of weights (Denton et al., 2014; Lebedev et al., 2014), weight quantization (Courbariaux et al., 2016; Rastegari et al.), knowledge distillation (Hinton et al., 2014; Romero et al., 2015) and network pruning (Han et al., 2015; Li et al., 2017), among which network pruning has gained notable attention due to their competitive performance and compatibility.
最近深度卷积网络的成功(Girshick等人,2014; Long等人,2015; He等人,2016; 2017a)与计算资源的需求增加相得益彰。特别地,深度神经网络应用受限的主要资源包括模型大小、存储器占用空间、计算操作(FLOP)的次数和功率用量。 这些大型模型无法存储,并且无法在嵌入式系统上实时运行。为了解决这个问题,已经提出了许多方法,例如权重的低秩逼近(Denton等人,2014; Lebedev等人,2014),权重量化(Courbariaux等人,2016; Rastegari等人), 知识蒸馏(Hinton et al。,2014; Romero et al。,2015)和网络修剪(Han et al。,2015; Li et al。,2017),其中网络修剪因其突出的表现和兼容性而受到关注。
One major branch of network pruning methods is individual weight pruning, and it dates back to Optimal Brain Damage (LeCun et al., 1990) and Optimal Brain Surgeon (Hassibi & Stork, 1993), which prune weights based on Hessian of the loss function. More recently, Han et al. (2015) proposes to prune network weights with small magnitude, and this technique is further incorporated into the “Deep Compression” pipeline (Han et al., 2016). Srinivas & Babu (2015) proposes a data-free algorithm to remove redundant neurons iteratively. However, one drawback of these non-structured pruning methods is that the resulting weight matrices are sparse, which cannot lead to compression and speedup without dedicated hardware/libraries.
网络修剪方法的一个主要分支是个体权重修剪,它可以追溯到最佳脑损伤(LeCun等,1990)和Optimal Brain Surgeon(Hassibi&Stork,1993),它基于损失函数的Hessian矩阵修剪权重。 最近,Han等人。(2015)提出小幅度的修剪的网络权重,并将此技术进一步纳入“深度压缩”流程(Han et al。,2016)。 Srinivas&Babu(2015)提出了一种无数据算法来迭代地去除冗余神经元。 然而,这些非结构化修剪方法的一个缺点是所得到的权重矩阵是稀疏的,如果没有专用硬件/库,则不能达到压缩和加速的效果。这里说的非结构化的修建时直接修建权重的。
In contrast, structured pruning methods prune at the level of channels or even layers. Since the original convolution structure is still preserved, no dedicated hardware/libraries are required to realize the benefits. Among structured pruning methods, channel pruning is the most popular, since itoperates at the most fine-grained level while still fitting in conventional deep learning frameworks.
相反,结构化修剪方法在通道或甚至层的层次上进行修剪。由于原始卷积结构仍然保留,因此不需要专用的硬件/库来实现这些好处。 在结构化修剪方法中,通道修剪是最受欢迎的,因为它在最细粒度的水平上运行,同时仍然适合传统的深度学习框架。
Some heuristic methods include pruning channels based on their corresponding filter weight norm (Li et al., 2017) and average percentage of zeros in the output (Hu et al., 2016). Group sparsity is also widely used to smooth the pruning process after training (Wen et al., 2016; Alvarez & Salzmann, 2016; Lebedev & Lempitsky, 2016; Zhou et al., 2016). Liu et al. (2017) and Ye et al. (2018) impose sparsity constraints on channel-wise scaling factors during training, whose magnitudes are then used for channel pruning. Huang & Wang (2018) uses a similar idea to prune coarser structures such as residual blocks . He et al. (2017b) and Luo et al. (2017) minimizes next layer’s feature reconstruction error to determine which channels to keep. Similarly, Yu et al. (2018) optimizes the reconstruction error of the final response layer and propagates a “importance score” for each channel. Molchanov et al. (2016) use Taylor expansion to approximate each channel’s influence over the final loss and prune accordingly. Suau et al. (2018) analyzes the intrinsic correlation within each layer and prune redundant channels.
一些启发式方法 包括根据相应的滤波器权重范数修剪通道(Li et al。,2017)和输出中零的平均百分比(Hu et al。,2016)。组稀疏度(这个不是很懂) 也被广泛用于在训练后平滑修剪过程(Wen等人,2016; Alvarez&Salzmann,2016; Lebedev&Lempitsky,2016; Zhou等人,2016)。刘等人。(2017年)和叶等人。(2018)在训练期间对原通道方面的缩放因子施加稀疏性约束,其大小随后用于通道修剪。Huang&Wang(2018)使用类似的想法来修剪较粗糙的结构,例如残差模块。He等人。 (2017b)和Luo等人。 (2017)最小化下一层的特征重建错误,以确定要保留哪些通道。同样,Yu等人。 (2018)优化最终响应层的重建误差并传播每个信道的“重要性分数”。 Molchanov等。 (2016)使用泰勒扩展来估计每个渠道对最终损失的影响并相应地修剪。 Suau等人。 (2018)分析每层内的固有相关性并修剪冗余信道。(对这一部分很感兴趣,到时候再来看看,好好理解一下这个方法)
Our work is also related to some recent studies on the characteristics of pruning algorithms. Mittal et al. (2018) shows that random channel pruning (Anwar & Sung, 2016) can perform on par with a variety of more sophisticated pruning criteria, demonstrating the plasticity of network models. Zhu & Gupta (2018) shows that training a small-dense model cannot achieve the same accuracy as a pruned large-sparse model with identical memory footprint. In this work, we reveal a different and rather surprising characteristic of network pruning methods: fine-tuning the pruned model with inherited weights is no better than training it from scratch.
我们的工作还涉及一些关于特征修剪算法的最新研究。 米塔尔等人。 (2018)表明随机通道修剪(Anwar&Sung,2016)可以与各种更复杂的修剪标准相媲美,展示了网络模型的可塑性。 Zhu和Gupta(2018)表明,在相同内存占用条件下,训练小密度模型不能达到与的修剪大稀疏模型相同的精度。 在这项工作中,我们揭示了网络修剪方法的一个不同且相当令人惊讶的特征:使用继承权重微调修剪模型并不比从头开始训练更好。
methodology
In this section, we describe in detail our methodology for training a small target model from random initialization. Target Pruned Architectures. We first divide network pruning methods into two categories. In a pruning pipeline, the target pruned model’s architecture can be determined by either human (i.e., predefined) or the pruning algorithm (i.e., automatic)(see Figure 2).
方法
在本节中,我们将详细描述从随机初始化中训练小规模目标模型的方法。Target Pruned Architectures.我们首先将网络修剪方法分为两类。 在修剪流程中,目标修剪模型的架构可以由人(即,预定义的)或修剪算法(即,自动)确定(参见图2)。
When human predefines the target architecture, a common criterion is the ratio of channels to prune in each layer. For example, we may want to prune 50% channels in each layer of VGG. In this case, no matter which specific channels are pruned, the target architecture remains the same, because the pruning algorithm only locally prunes the least important 50% channels in each layer. In practice, the ratio in each layer is usually selected through empirical studies or heuristics.
当人类预定义目标体系结构时,通用标准是每个层中需要剪枝通道的比率。例如,我们可能希望在每层VGG中修剪50%的通道。 在这种情况下,无论修剪哪个特定通道,目标架构都保持不变,因为修剪算法仅在本地修剪每层中最不重要的50%通道。 在实践中,通常通过实证研究或启发式选择每层中的比率。
When the target architecture is automatically determined by a pruning algorithm, it is usually based on a pruning criterion that globally compares the importance of structures (e.g., channels) across layers. Examples include Liu et al. (2017), Huang & Wang (2018), Molchanov et al. (2016) and Suau et al. (2018). Non-structured weight pruning (Han et al., 2015) also falls into this category, where the sparsity patterns are determined by the magnitude of trained weights.
当通过修剪算法自动确定目标体系结构时,通常基于修剪标准,该修剪标准全局地比较跨层的结构(例如,通道)的重要性。 例如,Liu等人。 (2017),Huang&Wang(2018),Molchanov等。 (2016年)和Suau等人。(2018)。 非结构化重量修剪(Han et al。,2015)也属于这一类,其中稀疏模式由训练重量的大小决定。
Datasets, Network Architectures and Pruning Methods. In the network pruning literature, CIFAR-10, CIFAR-100 (Krizhevsky, 2009), and ImageNet (Deng et al., 2009) datasets are the de-facto benchmarks, while VGG (Simonyan & Zisserman, 2015), ResNet (He et al., 2016) and DenseNet (Huang et al., 2017) are the common network architectures. We evaluate three pruning methods with predefined target architectures, Li et al. (2017), Luo et al. (2017), He et al. (2017b) and three which automatically discovered target models, Liu et al. (2017), Huang & Wang (2018), Han et al. (2015). For the first five methods, we evaluate using the same (target model, dataset) pairs as presented in the original paper to keep our results comparable. For the last one (Han et al., 2015), we use the aforementioned architectures instead, since the ones in the original paper are no longer state-of-the-art. On CIFAR datasets, we run each experiment with 5 random seeds, and report the mean and standard deviation of the accuracy. For testing on the ImageNet, the image is first resized so that the shorter edge has length 256, and then center-cropped to be of 224×224.
数据集,网络架构和修剪方法:在网络修剪文献中,CIFAR-10,CIFAR-100(Krizhevsky,2009)和ImageNet(Deng等,2009)数据集是事实上的基准数据集,而VGG(Simonyan& Zisserman,2015),ResNet(He et al。,2016)和DenseNet(Huang et al。,2017)是常见的网络架构。我们用预定义的目标体系结构评估了三种修剪方法,Li等(2017),罗等人。 (2017年),何等人。 (2017b)和三个自动发现目标模型,刘等人。 (2017),Huang&Wang(2018),Han et al。 (2015年)。对于前五种方法,我们使用原始论文中提供的相同(目标模型,数据集)对进行评估,以使我们的结果具有可比性。对于最后一个(Han et al。,2015),我们使用上述架构,因为原始论文中的那些不再是最先进的。在CIFAR数据集上,我们使用5个随机种子运行每个实验,并报告准确度的均值和标准差。为了在ImageNet上进行测试,首先调整图像大小,使较短边的长度为256,然后将中心裁剪为224×224。
Training Budget. One crucial question is how long we should train the small pruned model from scratch? Naively training for the same number of epochs as we train the large model might be unfair, since the small pruned model requires significantly less computation for one epoch. Alternatively, we could compute the floating point operations (FLOPs) for both the pruned and large models, and choose the number of training epoch for the pruned model that would lead to the same amount of computation as training the large model.
训练预算: 一个关键问题是我们应该从头开始训练小型修剪模型多久? 在我们用相同的训练周期来训练大型模型可能是不公平的,因为小型修剪模型在一个训练周期中明显需要少量的计算资源,我们可以计算修剪模型和大模型的浮点运算(FLOPs),然后选择依据和大型模型一样的运算量来选择小修剪模型的训练周期数。
In our experiments, we use Scratch-E to denote training the small pruned models for the same epochs, and Scratch-B to denote training for the same amount of computation budget1. One may argue that we should instead train the small target model for fewer epochs since it typically converges faster. However, in practice we found that increasing the training epochs within a reasonable range is rarely harmful. We hypothesize that this is because smaller models are less prone to over-fitting.
在我们的实验中,我们使用** Scratch-E 来表示同一个训练周期时的小型修剪模型,并使用 Scratch-B **来表示相同数量的计算预算1的训练。 有人可能会争辩说,我们应该用较少的周期训练小目标模型,因为它通常收敛得更快。 然而,在实践中,我们发现将训练时期在合理范围内增加几乎没有什么害处。 我们假设这是因为较小的模型不太容易过度拟合。
Implementation. In order to keep our setup as close to the original paper as possible, we use the following protocols: 1) If a previous pruning method’s training setup is publicly available, e.g. Liu et al. (2017) and Huang & Wang (2018), we adopt the original implementation; 2) Otherwise, for simpler pruning methods, e.g., Li et al (2017) and Han et al. (2015), we re implement the threestage pruning procedure and achieve similar results to the original paper; 3) For the remaining two methods (Luo et al., 2017; He et al., 2017b), the pruned models are publicly available but without the training setup, thus we choose to re-train both large and small target models from scratch. Interestingly, the accuracy of our re-trained large model is higher than what is reported in the original paper2. In this case, to accommodate the effects of different frameworks and training setups, we report the relative accuracy drop from the unpruned large model.
实现: 为了使我们的设置尽可能接近原始文件,我们使用以下协议:1)如果先前的修剪方法的训练设置是公开可用的,例如, 刘等人。 (2017)和黄和王(2018),我们采用原来的实施; 2)否则,对于更简单的修剪方法,例如,Li等人(2017)和Han等人。 (2015),我们重新实施三阶段修剪程序,并取得与原始论文类似的结果; 3)对于其余两种方法(Luo et al。,2017; He et al。,2017b),修剪的模型是公开的,但没有训练设置,因此我们选择从头开始重新训练大型和小型目标模型。 有趣的是,我们重新训练的大型模型的准确性高于原始论文中报告的2。 在这种情况下,为了适应不同框架和训练设置的效果,我们指出:未修剪的大型模型的精度相对下降了。
In all these implementations, we use standard training hyper-parameters and data-augmentation schemes. For random weight initialization, we adopt the scheme proposed in He et al. (2015). For results of models fine-tuned from inherited weights, we either use the released models from original papers (for case 3 above) or follow the common practice of fine-tuning the model using the lowest learning rate when training the large model (Li et al., 2017; He et al., 2017b). The code to reproduce the results will be made publicly available.
在所有这些实现版本中,我们使用标准训练超参数和数据增强方案。 对于随机权重初始化,我们采用He等人提出的方案。(2015年)。对于从遗传权重微调的模型的结果来看,我们要么使用原始论文中公布的模型(对于上面的案例3),要么遵循在训练大型模型时使用最低学习率对模型进行微调的常规做法(Li et et Li)al。,2017; He et al。,2017b)。 重现结果的代码将公开发布。
4 EXPERIMENTS
看原论文就很清楚明了了,这里就不再翻译了