机器学习集成算法:XGBoost模型构造
请点击上面公众号,免费订阅。
《实例》阐述算法,通俗易懂,助您对算法的理解达到一个新高度。包含但不限于:经典算法,机器学习,深度学习,LeetCode 题解,Kaggle 实战。期待您的到来!
01
—
回顾
昨天介绍了XGBoost的基本思想,说到新加入进来的决策树必须能使原已有的更好才行吧,那么将XGBoost这个提升的过程如何用数学模型来表达呢?
02
—
XGBoost整体模型
机器学习的有监督问题,通常可以分为两步走:模型建立(比如线性回归时选用线性模型),根据目标函数求出参数(比如球出线性回归的参数)。对于XGBoost,也是做有监督任务了,也可以按照这个过程去分析,它的模型表示为如下,k表示树的个数,f表示构建的每个数结构,xi表示第i个样本,xi在每个树上的得分值的和就是xi的预测值,
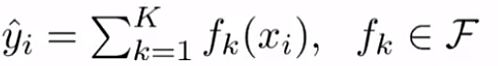
它的目标函数表示为如下,其中等号右侧第一项表示所有样本点的误差和,第二项表示对每棵树的惩罚项(我们知道,惩罚项是用来使得预测的模型不那么复杂的方法,这也是为了提高模型的泛化能力),原始目标函数形式如下:
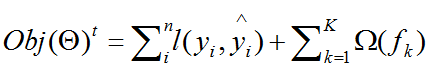
其中上标 t 代表第 t 轮集成
总之,我们就是要让预测值接近真实值,同时要让树模型尽可能的简单。接下来,看看在集成的过程中,如何尽可能地使得目标函数尽可能地小。
03
—
如何集成
XGBoost是串行集成的,这是与随机森林的不同之处,详细看下这个过程,期初只有一棵树,后来yi2时,加入进来f2,依次递推,第 t轮的预测模型,等于保留前面 t-1 轮的模型预测,和新来的 ft,前面说过f可以看做一颗树的构造。

将上面的递推公式带入到初始目标函数后得到,第一次改进目标函数后得到:
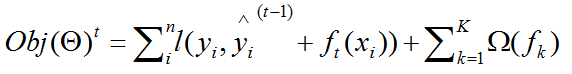
上式中等号的第二项是正则化惩罚项,是为了限制树的叶子节点的个数,防止树变得过于庞大的,它等于:
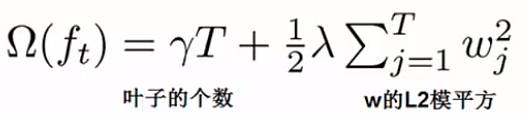
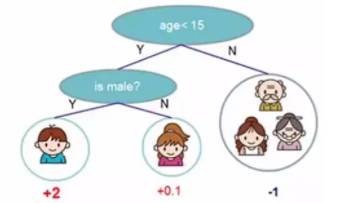
上式怎么用呢?举个例子,如下图,一共3个叶子节点,则 T = 3,小男孩这个叶子节点的权重为+2,所以平方为4,因此惩罚项等于如下吧:
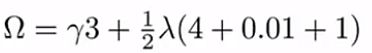
目标函数至此做了一步演化,下面进一步将等号右边第一项误差函数项,在此采用常用的平方误差项,进行目标函数的第二次演化,如下,
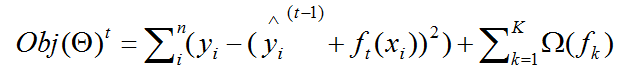
XGBoost模型还给出了一个更一般的误差模型,上面我们不是根据平方误差项吗,如果采取一个通用性更强的模型,应该怎么写的,可以看到 ft 相当于一个当前轮次的变化量,可以想到 f(x + dx) = f(x) + f(x)'dx + 0.5f(x)''dx + ... 这就是泰勒展开式,一般地取前三项就能保证问题的精度了,所以我们进行目标函数的第二次,更一般的演化,得到下式:
这是第一次演化后的公式,进行泰勒展开,关键要分清谁是 x , 谁是 dx 吧! 可以看到 与参数 t 相关的才是公式的变量,所以 x 为 y(t-1), dx 相当于 ft(xi) 吧,yi是给定样本编号 i的真实值吧,为常数,
所以,对其展开后为
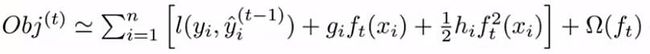
其中,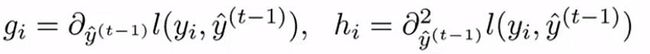
在进行第 t 轮集成的时候,loss( yi, yi(t-1) )这项已经知道了吧,是个常数了,比如预测一个价格为每股2元的股票,在第 t-1 轮的时候我们就得出股票的价格为1.5元,所以在第 t 轮的时候,loss就等于0.5吧,因此 loss那项是可以拿掉的。
好了,至此,我们就把目标函数演化了一部分了,但是,XGBoost真正NB的地方,是下面这节,将对样本的遍历,转化为对叶子节点的遍历,这是巧妙的地方。
04
—
XGBoost最精彩的部分:转化的巧妙
首先,晒出两个映射,第一个映射是 q,在树结构 f 已知的情况下表,给出一个样本 xi ,通过 q 可以得出 xi 位于的叶子节点编号,如同下图,给出小女孩,通过 q 可以得出 leaf2,即属于叶子编号2,
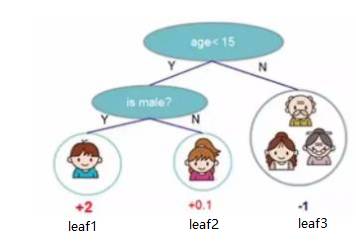
晒出的第二个映射为 w ,这个不难理解,就像神经网络中神经元的权重参数,即 小女孩的权重参数为 +0.1,综合起来分析,
w ( q ( 小女孩 ) ) = +0.1
因此,可以将下式:
进行第三次演化后为下式:
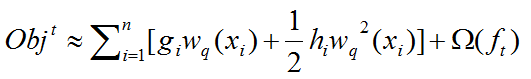
这还不是最精彩的地方,因为上式还是对样本 i 从1到n的遍历,接下来,这个式子,将对样本的遍历转化为了对叶子节点的遍历,这是XGBoost的最重要的一步转化,进行第四次演化后为下式,
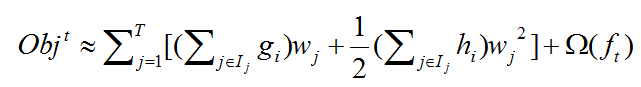
其中 , ![]() 表示:第 j 个叶子中包括的所有样本, wj表示第 j 个叶子的权重。
表示:第 j 个叶子中包括的所有样本, wj表示第 j 个叶子的权重。
综上所述,将 ![]() 再由上带入进去,进一步化简为,
再由上带入进去,进一步化简为,
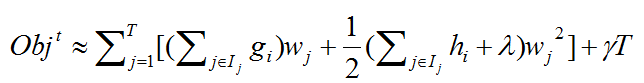
令,Gj, Hj 分别为:
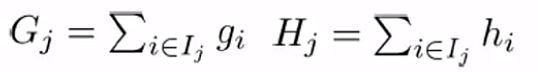 ,
,
目标函数经过第五次演化后为下式,
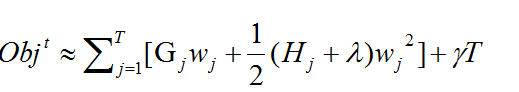
这就是目标函数的最终形式了。
05
—
求解目标函数
看到这个目标函数,就已经非常明了了,它是关于wj 的一维二次函数吧,所以对它求最小值,还是非常简单的吧,这个就不讲了,直接求出 wj 在取得什么值时,loss值会取到最小值,
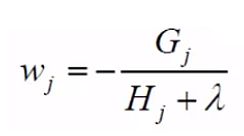 ,
,
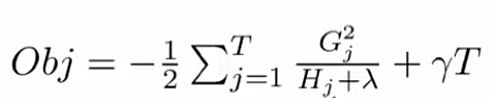
我们费了这么多劲,至此终于推算出,在第 t 轮集成时,到底该选择哪个树结构 ft 的衡量标准了,哪个树结构 ft 能使得在t-1轮的目标函数上减少的最多,也就是 obj 越小越好吧,我们就选择它吧。
05
—
分割所得的信息增益
对于每次扩展,是要枚举所有可能的分割方案,比较分割后的信息增益,求出最大值对应的分割点。比如要枚举所有 x < constant 这样的条件,对于某个分割,要计算 constant 左边和右边,还有没有切分这个节点时的信息增益求出来,求解信息增益的公式如下:
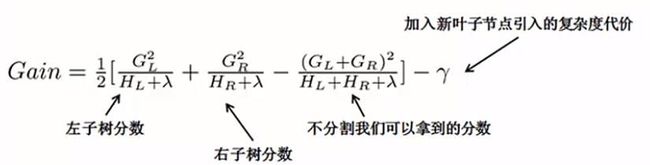
如果,Gain 大于某个阈值,则这个分割是有必要的,然后根据枚举的结果,取出分割能获得的最大增益。
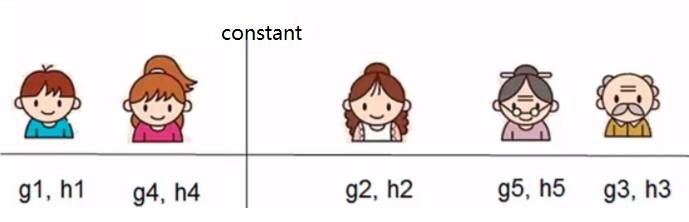
对于这次特定的分割,
GL = g1 + g4
HL = h1 + h4
GR = g2 + g5 + g3
HR = h2 + h5 + h3
然后带入信息增益的公式,求出本次分割获得信息增益,然后枚举所有可能的分割得到的信息增益,选取最大值,假定得出如下所示的最佳分割点,此时 constant = 0.9,则可以得到 x < 0.9时,左子树只含有一个节点,右子树含有剩余节点,这种 ft 树结构。
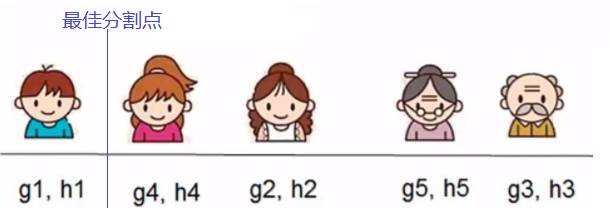
总结下,以上介绍了XGBoost的目标函数原理推导,进一步得出了某个分割的信息增益,进而得出构造 ft 的过程。明天根据XGBoost的开源库,实战演练下XGBoost做分类和回归的过程。
算法channel已推送的更多文章:
1 机器学习:不得不知的概念(1)
2 机器学习:不得不知的概念(2)
3 机器学习:不得不知的概念(3)
4 回归分析简介
5 最小二乘法:背后的假设和原理(前篇)
6 最小二乘法原理(后):梯度下降求权重参数
7 机器学习之线性回归:算法兑现为python代码
8 机器学习之线性回归:OLS 无偏估计及相关性python分析
9 机器学习线性回归:谈谈多重共线性问题及相关算法
10 机器学习:说说L1和L2正则化
11 机器学习逻辑回归:原理解析及代码实现
12 机器学习逻辑回归:算法兑现为python代码
13 机器学习:谈谈决策树
14 机器学习:对决策树剪枝
15 机器学习决策树:sklearn分类和回归
16 机器学习决策树:提炼出分类器算法
17 机器学习:说说贝叶斯分类
18 朴素贝叶斯分类器:例子解释
19 朴素贝叶斯分类:拉普拉斯修正
20 机器学习:单词拼写纠正器python实现
21 机器学习:半朴素贝叶斯分类器
22 机器学习期望最大算法:实例解析
23 机器学习高斯混合模型(前篇):聚类原理分析
24 机器学习高斯混合模型(中篇):聚类求解
25 机器学习高斯混合模型(后篇):GMM求解完整代码实现
26 高斯混合模型:不掉包实现多维数据聚类分析
27 高斯混合模型:GMM求解完整代码实现
28 数据降维处理:背景及基本概念
29 数据降维处理:PCA之特征值分解法例子解析
30 数据降维处理:PCA之奇异值分解(SVD)介绍
31 数据降维处理:特征值分解和奇异值分解的实战分析
32 机器学习集成算法:XGBoost思想
请记住:每天一小步,日积月累一大步!

《实例》阐述算法,通俗易懂,助您对算法的理解达到一个新高度。包含但不限于:经典算法,机器学习,深度学习,LeetCode 题解,Kaggle 实战。期待您的到来!