scrapy的介绍百度那里一堆的资料,此处不再赘述,我主要参考崔庆才的文章小白进阶之Scrapy第一篇,我的工程路径大致是这样的:

以下引用作者原话
建立一个项目之后:
第一件事情是在items.py文件中定义一些字段,这些字段用来临时存储你需要保存的数据。方便后面保存数据到其他地方,比如数据库 或者 本地文本之类的。
第二件事情在spiders文件夹中编写自己的爬虫
第三件事情在pipelines.py中存储自己的数据
还有一件事情,不是非做不可的,就settings.py文件 并不是一定要编辑的,只有有需要的时候才会编辑。
最后一件事,运行爬虫代码
当然,以上这些步骤也可以参考scrapy的官方介绍,步骤基本一致
第一件事情
首先,第一件事很简单,就是要明确你想要获取的数据,然后按照给定的格式(your_data = scrapy.Field())进行赋值即可,对于item的解释可以参考item的官方文档
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class LianjiaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
district = scrapy.Field() # 区域
street = scrapy.Field() # 街道
position_info = scrapy.Field() # 位置信息补充
community = scrapy.Field() # 小区
community_url = scrapy.Field() # 小区URL
latitude = scrapy.Field() # 小区纬度
longtitude = scrapy.Field() # 小区经度
house_url = scrapy.Field() # 租房网址
title = scrapy.Field() # 租房信息标题
total_price = scrapy.Field() # 房屋总价
unit_price = scrapy.Field() # 每平方单价
shoufu = scrapy.Field() # 首付
tax = scrapy.Field() # 税费
house_id = scrapy.Field() # 房屋链家ID
community_id = scrapy.Field() # 社区ID
bulid_year = scrapy.Field() # 房屋建造年代
base_info=scrapy.Field() # 基本信息,包括基本属性和交易属性
broker = scrapy.Field() # 经纪人姓名
broker_id = scrapy.Field() # 经纪人ID
broker_url = scrapy.Field() # 经纪人URL
broker_score = scrapy.Field() # 经纪人评分
commit_num = scrapy.Field() # 评价人数
broker_commit_url = scrapy.Field() # 经纪人评价URL
broker_phone = scrapy.Field() # 经纪人电话
CommunityInfo=scrapy.Field()
community_unit_price = scrapy.Field() # 小区均价
提取的内容见items.py中各字段的解释
第二件事情
spider文件的详细解释可以参考官方文档
摘要如下:
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
这个部分主要是在spider文件夹下新建一个文件用于处理爬虫事宜,根据我的工程文件,此处建立lianjia.py,代码如下:
import scrapy
import requests
import re
import time
import json
from fake_useragent import UserAgent
import random
import socket
from urllib import request,error
from bs4 import BeautifulSoup as BS
from lxml import etree
from lianjia.items import LianjiaItem
class Myspider(scrapy.Spider):
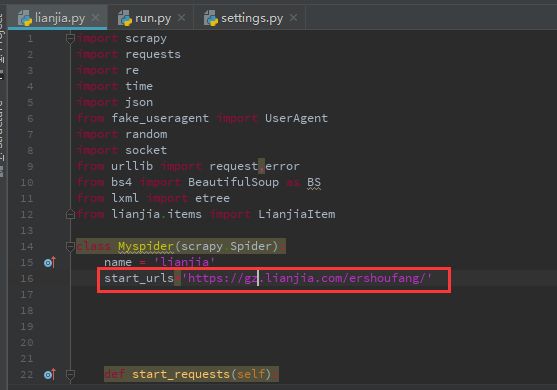
name = 'lianjia'
start_urls='http://nj.lianjia.com/ershoufang/'
def start_requests(self): # 此函数可以不用定义,直接使用预定义的start_requests函数即可,预定义函数可以自动为start_urls列表中的每个URL链接进行抓取,并得到相应的response
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 \
Safari/537.36 SE 2.X MetaSr 1.0'
headers = {'User-Agent': user_agent}
yield scrapy.Request(url=self.start_urls, headers=headers, method='GET', callback=self.get_area_url)
def get_area_url(self, response):
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 \
Safari/537.36 SE 2.X MetaSr 1.0'
headers = {'User-Agent': user_agent}
page = response.body.decode('utf-8') # 解码
soup=BS(page,'lxml') # html解析
area_list = soup.find('div', {'data-role':'ershoufang'}).find_all("a") # 地区列表
for area in area_list:
area_pin =area['href']
area_url = self.start_urls.rstrip('/ershoufang/')+ area_pin# 地区URL列表
# print(area_url)
yield scrapy.Request(url=area_url, headers=headers, method='GET', callback=self.house_info, meta={'id':area_pin})
# 获取经纬度信息
# 方法二:通过网页URL本身信息获取
def get_Geo(self,url): # 进入每个房源链接抓经纬度
p = requests.get(url)
contents = etree.HTML(p.content.decode('utf-8'))
temp = str(contents.xpath('// html / body / script/text()'))
# print(latitude,type(latitude))
time.sleep(3)
regex = '''resblockPosition(.+)''' # 匹配经纬度所在的位置
items = re.search(regex, temp)
content = items.group()[:-1] # 经纬度
lng_lat = content.split('\'')[1].split(',')
longitude = lng_lat[0]
latitude = lng_lat[1].split('\\')[0]
return longitude, latitude
# 获取列表页面
def get_page(self,url):
# 两种设置headers的方法,方法一:
# headers = {
# 'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
# "(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
# 'Referer': GLOBAL_start_urls+'/ershoufang/',
# 'Host': GLOBAL_start_urls.split('//')[1],
# 'Connection': 'keep-alive',
# }
# 方法二:使用fake-useragent第三方库
headers = {
'User-Agent': UserAgent().random,
'Referer': self.start_urls,
'Host': self.start_urls.split('//')[1].rstrip('/ershoufang/'),
'Connection': 'keep-alive'
}
timeout = 60
socket.setdefaulttimeout(timeout) # 设置超时,设置socket层的超时时间为60秒
try:
req = request.Request(url, headers=headers)
response = request.urlopen(req)
page = response.read().decode('utf-8')
response.close() # 注意关闭response
except error.URLError as e:
print(e.reason)
time.sleep(random.random() * 3) # 自定义,设置sleep()等待一段时间后继续下面的操作
return page
# for 南京、广州、杭州、合肥、青岛、深圳等地
def house_info(self,response):
page = response.body.decode('utf-8') # 解码
soup = BS(page, 'lxml') # html解析
if soup.find('div', class_='page-box house-lst-page-box'):
pn_num = json.loads(soup.find('div', class_='page-box house-lst-page-box')['page-data']) # 获取最大页数以及当前页
max_pn = pn_num['totalPage'] # 获取最大页数,'curPage'存放当前页
for i in range(1,max_pn+1):
temp_url=''.join(self.start_urls.rstrip('/ershoufang/')+response.meta['id'])+'pg{}'.format(str(i))
req=requests.get(temp_url)
soup=BS(req.text,'lxml')
if soup.find('ul',class_='sellListContent'):
all_li=soup.find('ul',class_='sellListContent').find_all('li')
for li in all_li:
house_url=li.find('a')['href']
try:
item = LianjiaItem()
page=self.get_page(house_url)
soup=BS(page,'lxml')
temp = soup.find('div', class_='areaName').text.split('\xa0')
item['district'] = temp[0].strip('所在区域') # 区域名
item['street'] = temp[1] # 街道名
if temp[2]:
item['position_info'] = temp[2] # 地理位置附加信息,有些二手房为空
item['community'] = soup.select('.communityName')[0].text.strip('小区名称').strip('地图')
# 社区名
try: # 有些城市没有小区的信息
communityUrl = self.start_urls.rstrip('/ershoufang/') + \
soup.find('div', class_='communityName').find('a')['href']
except Exception:
communityUrl = None
item['community_url'] = communityUrl
item['house_url'] = house_url # 租房网址
item['title'] = soup.select('.main')[0].text # 标题
item['total_price'] = soup.select('.total')[0].text + '万' # 总价
item['unit_price'] = soup.select('.unitPriceValue')[0].text # 单价
temp = soup.find('div', class_='tax').text.split()
if len(temp) > 1:
item['shoufu'] = temp[0].strip('首付') # 首付
item['tax'] = temp[1].strip('税费').strip('(仅供参考)') # 税费
else:
# temp=首付及税费情况请咨询经纪人
item['shoufu'] = temp[0]
item['tax'] = temp[0]
# 户型信息,此信息差异较大,不提取
# temp = soup.find('div', id='infoList').find_all('div', class_='col')
# for i in range(0, len(temp), 4):
# item[temp[i].text] = {}
# item[temp[i].text]['面积'] = temp[i + 1].text
# item[temp[i].text]['朝向'] = temp[i + 2].text
# item[temp[i].text]['窗户'] = temp[i + 3].text
hid = soup.select('.houseRecord')[0].text.strip('链家编号').strip('举报')
item['house_id'] = hid
# hid:链家编号
try: # 有些城市没有小区的信息
rid = soup.find('div', class_='communityName').find('a')['href'].strip(
'/xiaoqu/').strip('/')
item['community_id'] = rid
except Exception:
item['community_id'] = None
# rid:社区ID
# 以下为获取小区简介信息,方法一:
# temp_url = '{}/ershoufang/housestat?hid={}&rid={}'.format(GLOBAL_start_urls,hid, rid)
# temp = json.loads(requests.get(temp_url).text)
# item['小区均价'] = temp['data']['resblockCard']['unitPrice']
# item['小区建筑年代'] = temp['data']['resblockCard']['buildYear']
# item['小区建筑类型'] = temp['data']['resblockCard']['buildType']
# item['小区楼栋总数'] = temp['data']['resblockCard']['buildNum']
# item['小区挂牌房源在售'] = temp['data']['resblockCard']['sellNum']
# item['小区挂牌房源出租房源数'] = temp['data']['resblockCard']['rentNum']
# # 获取小区经纬度的第三种方法
# item['经度'],item['纬度'] = temp['data']['resblockPosition'].split(',')
item['bulid_year'] = soup.find('div', class_='area').find('div',
class_='subInfo').get_text() # 建造年代
# # 以下提取基本信息中的基本属性:房屋户型、所在楼层、建筑面积、套内面积、房屋朝向、建筑结构、装修情况、别墅类型、产权年限
# all_li = soup.find('div', class_='base').find('div', class_='content').find_all('li')
# for li in all_li:
# item[li.find('span').text] = li.text.split(li.find('span').text)[1]
# # 以下提取基本信息中的交易属性:挂牌时间、交易权属、上次交易、房屋用途、房屋年限、产权所属、抵押信息、房本备件
# all_li = soup.find('div', class_='transaction').find('div', class_='content').find_all('li')
# for li in all_li:
# item[li.find('span').text] = li.text.split(li.find('span').text)[1]
# 以上两个部分可以合并,提取基本信息,包括基本属性和交易属性:
all_li = soup.find('div', class_='introContent').find_all('li')
temp_dict={}
for li in all_li:
temp_dict[li.find('span').text] = li.text.split(li.find('span').text)[1]
item['base_info']=temp_dict
# 经纪人信息,该信息有可能为空:
if soup.find('div', class_='brokerInfoText fr'):
# 姓名
item['broker'] = soup.find('div', class_='brokerInfoText fr').find('a',
target='_blank').text
item['broker_id'] = soup.find('div', class_='brokerName').find('a')['data-el']
temp = soup.find('div', class_='brokerInfoText fr').find('span', class_='tag first')
if temp.find('a'):
item['broker_commit_url'] = temp.find('a')['href']
# 评分
item['broker_score'] = temp.text.split('/')[0].strip('评分:')
# 评价人数
item['commit_num'] = temp.text.split('/')[1].strip('人评价')
else:
item['broker_commit_url'] = '暂无评价'
# 联系电话,输出结果:'phone': '4008896039转8120'
item['broker_phone'] = soup.find('div', class_='brokerInfoText fr').find('div',
class_='phone').text
else:
print('无经纪人信息')
# 获取二手房经纬度的方法
item['longtitude'], item['latitude'] = self.get_Geo(house_url)
if communityUrl: # 有些城市没有小区的信息,判断小区URL是否存在
soup2 = BS(self.get_page(communityUrl), 'lxml')
CommunityInfo = soup2.find_all('div', class_='xiaoquInfoItem')
if soup2.find('span', class_='xiaoquUnitPrice'):
item['community_unit_price'] = soup2.find('span', class_='xiaoquUnitPrice').text + '元/㎡'
else:
item['community_unit_price'] = '暂无参考均价'
# 以下为获取小区简介信息,方法二:
temp_dict={}
for temp in CommunityInfo:
temp_dict[temp.find('span', class_='xiaoquInfoLabel').text] = \
temp.find('span', class_='xiaoquInfoContent').text
item['CommunityInfo']=temp_dict
else:
item['community_unit_price'] = None
item['CommunityInfo'] = None
except Exception:
pass
yield item # 这里一定要对item进行yield/return操作,不然pipelines接收不到item数据
# yield和return有什么区别,暂时未知
此处的代码与我上篇的代码大体一致,可以参考【Python3】南京链家二手房信息采集的解释,此处不再赘述。
此处需要注意,lianjia.py中item的条目要与items.py文件中定义的字段一致,如果lianjia.py的item在items.py中未定义,那么有可能最终获取的信息不全
对于name,start_urls以及parse(此处我并未使用parse,而是与使用自定义的函数代替,如get_area_url、house_info等)的解释,可以参考官方文档的解释
第三件事情
下面引用一下官方文档对pipelines的解释:
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
以下是item pipeline的一些典型应用:
- 清理HTML数据
- 验证爬取的数据(检查item包含某些字段)
- 查重(并丢弃)
- 将爬取结果保存到数据库中
可见pipelines是用来定义数据保存的方法的,想要对爬取的数据进行保存,在spider文件(lianjia.py)中必须使用yield item或者return item吧数据传递给pipeline。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from scrapy.conf import settings
from .items import LianjiaItem
class LianjiaPipeline(object):
def __init__(self):
host = settings['MONGODB_HOST']
port = settings['MONGODB_PORT']
db_name = settings['MONGODB_DBNAME']
# 链接数据库
client = pymongo.MongoClient(host=host,port=port)
# 数据库登录需要帐号密码的话,此处我采用默认的无密码登录
# self.client.admin.authenticate(settings['MINGO_USER'], settings['MONGO_PSW'])
tdb = client[db_name]
self.post = tdb[settings['MONGODB_DOCNAME']]
def process_item(self, item, spider):
if isinstance(item,LianjiaItem):
try:
info = dict(item) # 把item转化成字典形式
if self.post.insert(info): # 向数据库插入一条记录
print('bingo')
else:
print('fail:')
print(info)
except Exception:
pass
# return item # 会在控制台输出原item数据,可以选择不写
pipeline.py文件主要参考Python爬取链家北京二手房数据,作者在文中附有代码,有需要的可以参考一下。
还有一件事情
# -*- coding: utf-8 -*-
# Scrapy settings for lianjia project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'lianjia'
SPIDER_MODULES = ['lianjia.spiders']
NEWSPIDER_MODULE = 'lianjia.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'lianjia (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'lianjia.middlewares.LianjiaSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'lianjia.middlewares.LianjiaDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'lianjia.pipelines.LianjiaPipeline': 300,
}
# 分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。此处引自官网解释。
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
MONGODB_HOST = '127.0.0.1' # 默认主机IP
MONGODB_PORT = 27017 # 默认端口号
MONGODB_DBNAME = 'lianjia' # 数据库名
MONGODB_DOCNAME = 'BOOK' # 表名
# MONGO_USER = "zhangsan"
# MONGO_PSW = "123456"
在setting文件中配置MongoDB的IP和端口,并在pipeline.py文件中对其进行引用。
最后一件事
最后一件事就是运行文件,获取南京链家的二手房信息,有两种方法,
方法一
键入lianjia.py所在的目录,用命令行运行
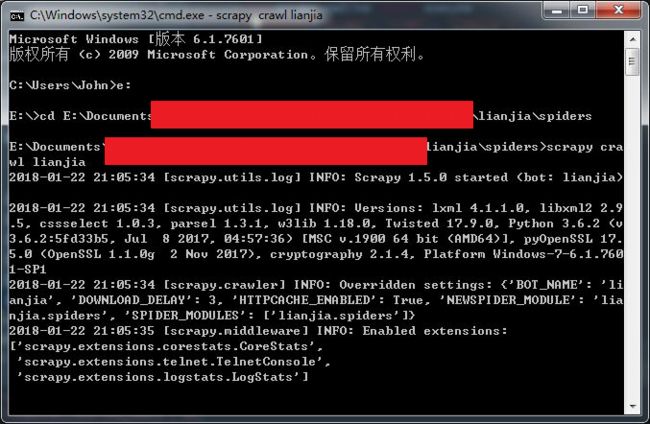
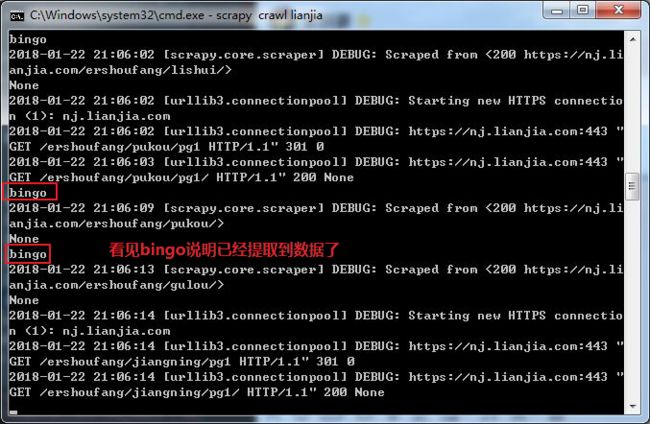
方法二
如我的工程文件所示,建立一个run.py文件,代码如下:
from scrapy.cmdline import execute
# execute(['scrapy', 'crawl', 'lianjia'])
execute('scrapy crawl lianjia'.split(' '))
刚开始我们的robot3t界面应该是这样的:
请忽略Collection中的“nanjing”表,这是我后来修改的
剩下的事就交给计算机去解决吧。中途我们可以用robot3t来看看我们的数据,双击'BOOK'吧,可看到数据

注意这里的“BOOK”不用预先定义,运行程序时如果不存在会自己创建,
点击右侧的数据区域查看每条数据的内容
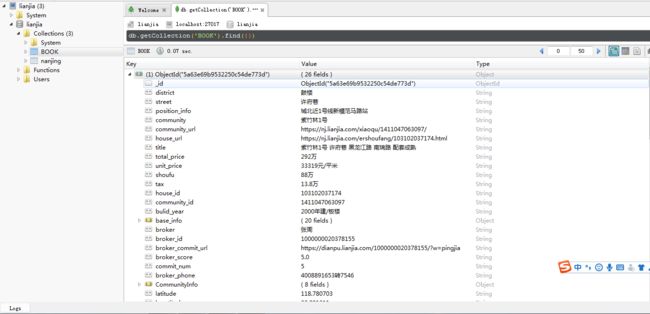
MongoDB数据结果展示
最后,不知道是不是我的计算机比较渣渣还是数据量太大,这个代码运行了三天两夜了,终于抓完了。。。
查看一下统计信息


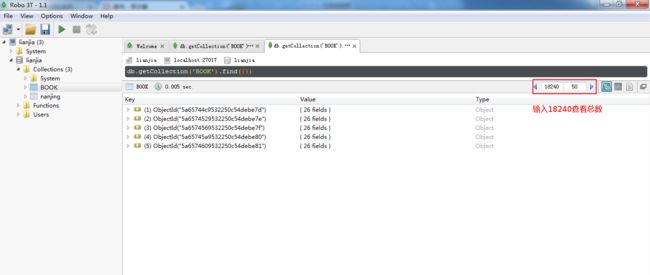
看看南京有多少二手房信息

显示 20738,这与我们抓取的还差2K+啊,只是怎么回事呢?,关于这个问题,有如下两个原因:
- 在程序运行时中途断网,导致少抓了一些房源信息(幸好及时发现,不然就白干了...)
-
因为我这里是通过抓取区域的URL信息提取的二手房信息,不够准确,精确的做法是接着往下提取每条街道的二手房URL信息
 image.png
image.png
 image.png
image.png
To be continued
关于其他城市的信息抓取,粗略试了一下,可以爬取北京、广州、杭州、合肥、青岛、深圳等地的二手房信息。有些城市,像上海情况比较特殊,改动比较大,暂不支持,有兴趣可以自己玩玩。。



另,如果有任何问题,欢迎邮件交流:[email protected]。
爬虫系列文章:
南京链家爬虫系列文章(一)——工具篇
南京链家爬虫系列文章(二)——scrapy篇
南京链家爬虫系列文章(三)——MongoDB数据读取
南京链家爬虫系列文章(四)——图表篇