deepspeech2 代码之特征提取
特征工程
CONTEXT
- 读取wav
- 制作频谱矩阵
- Dataset类
- Dataloader类
data_loader.py
SpectrogramDataset
BucketingSampler & DistributeBucketingSampler
AudioDataLoader
from data.data_loader import AudioDataLoader, SpectrogramDataset, BucketingSampler, DistributedBucketingSampler
train_dataset = SpectrogramDataset(audio_conf=audio_conf, manifest_filepath=args.train_manifest, labels=labels,
normalize=True, augment=args.augment)
test_dataset = SpectrogramDataset(audio_conf=audio_conf, manifest_filepath=args.val_manifest, labels=labels,
normalize=True, augment=False)
if not args.distributed:
train_sampler = BucketingSampler(train_dataset, batch_size=args.batch_size)
else:
train_sampler = DistributedBucketingSampler(train_dataset, batch_size=args.batch_size,
num_replicas=args.world_size, rank=args.rank)
train_loader = AudioDataLoader(train_dataset,
num_workers=args.num_workers, batch_sampler=train_sampler)
test_loader = AudioDataLoader(test_dataset, batch_size=args.batch_size,
num_workers=args.num_workers)
1. 读取wav
import librosa
import scipy.io.wavfile as wav
def load_audio(path):
# sound, _ = torchaudio.load(path, normalization=True)
# sound, sr = librosa.load(path,sr=16000)
sr,sound = wav.read(path)
#sound = sound.numpy().T
sound = np.array(sound,dtype=np.float32)
if len(sound.shape) > 1:
¦ if sound.shape[1] == 1:
¦ ¦ sound = sound.squeeze()
¦ else:
¦ ¦ sound = sound.mean(axis=1) # multiple channels, average
return sound
此处可以读取wav可以用wav , librosa 和 torchaudio 效果有一定区别
输出为(n,)矩阵
2. 特征图解析
class AudioParser(object):
def parse_transcript(self, transcript_path):
"""
:param transcript_path: Path where transcript is stored from the manifest file
:return: Transcript in training/testing format
"""
raise NotImplementedError
def parse_audio(self, audio_path):
"""
:param audio_path: Path where audio is stored from the manifest file
:return: Audio in training/testing format
"""
raise NotImplementedError
基本解析类
class SpectrogramParser(AudioParser):
def __init__(self, audio_conf, normalize=False, augment=False):
"""
Parses audio file into spectrogram with optional normalization and various augmentations
:param audio_conf: Dictionary containing the sample rate, window and the window length/stride in seconds
:param normalize(default False): Apply standard mean and deviation normalization to audio tensor
:param augment(default False): Apply random tempo and gain perturbations
"""
super(SpectrogramParser, self).__init__()
self.window_stride = audio_conf['window_stride'] #定义滑窗步长
self.window_size = audio_conf['window_size'] #定义滑窗大小
self.sample_rate = audio_conf['sample_rate'] #定义SR
self.window = windows.get(audio_conf['window'], windows['hamming']) #选择滑窗类型
self.normalize = normalize
self.augment = augment
self.noiseInjector = NoiseInjection(audio_conf['noise_dir'], self.sample_rate,
audio_conf['noise_levels']) if audio_conf.get(
'noise_dir') is not None else None
self.noise_prob = audio_conf.get('noise_prob')
def parse_audio(self, audio_path):
if self.augment:
y = load_randomly_augmented_audio(audio_path, self.sample_rate)
else:
y = load_audio(audio_path)
if self.noiseInjector:
add_noise = np.random.binomial(1, self.noise_prob)
if add_noise:
y = self.noiseInjector.inject_noise(y)
n_fft = int(self.sample_rate * self.window_size)
win_length = n_fft
hop_length = int(self.sample_rate * self.window_stride)
# STFT 短时傅里叶变化
D = librosa.stft(y, n_fft=n_fft, hop_length=hop_length,
win_length=win_length, window=self.window)
spect, phase = librosa.magphase(D) #计算复数图谱的幅度值和相位值
# S = log(S+1)
spect = np.log1p(spect)
spect = torch.FloatTensor(spect)
if self.normalize:
mean = spect.mean()
std = spect.std()
spect.add_(-mean)
spect.div_(std)
return spect
def parse_transcript(self, transcript_path):
raise NotImplementedError
windows = {'hamming': scipy.signal.hamming, 'hann': scipy.signal.hann,
'blackman': scipy.signal.blackman,'bartlett': scipy.signal.bartlett}
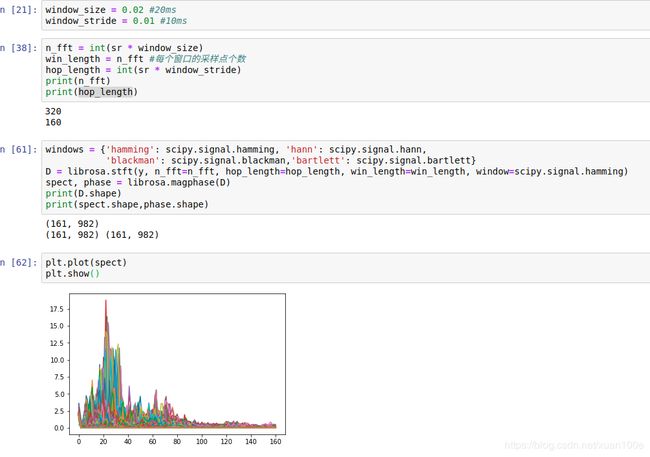
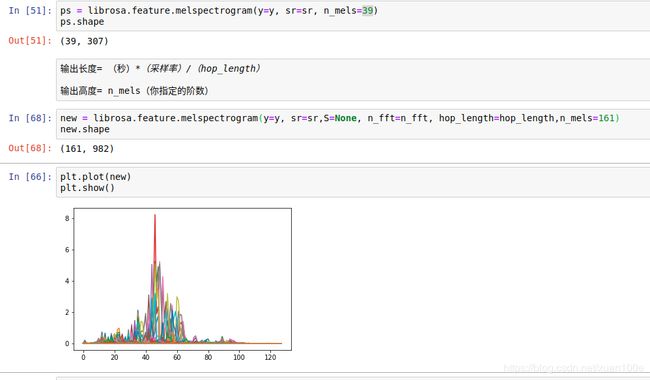
此外还有 mfcc fbank mel等提取方式
3.Dataset类构建
from torch.utils.data import Dataset
class SpectrogramDataset(Dataset, SpectrogramParser):
def __init__(self, audio_conf, manifest_filepath, labels, normalize=False, augment=False):
"""
Dataset that loads tensors via a csv containing file paths to audio files and transcripts separated by
a comma. Each new line is a different sample. Example below:
/path/to/audio.wav,/path/to/audio.txt
...
:param audio_conf: Dictionary containing the sample rate, window and the window length/stride in seconds
:param manifest_filepath: Path to manifest csv as describe above
:param labels: String containing all the possible characters to map to
:param normalize: Apply standard mean and deviation normalization to audio tensor
:param augment(default False): Apply random tempo and gain perturbations
"""
with open(manifest_filepath) as f:
ids = f.readlines()
ids = [x.strip().split(',') for x in ids] #ids [data_path.wav,data_path.txt]....
self.ids = ids
self.size = len(ids)
self.labels_map = dict([(labels[i], i) for i in range(len(labels))])
super(SpectrogramDataset, self).__init__(audio_conf, normalize, augment)
def __getitem__(self, index):
sample = self.ids[index]
audio_path, transcript_path = sample[0], sample[1]
spect = self.parse_audio(audio_path)
transcript = self.parse_transcript(transcript_path)
return spect, transcript
def parse_transcript(self, transcript_path): #此处构建 txt 文本
with open(transcript_path, 'r', encoding='utf8') as transcript_file:
transcript = transcript_file.read().replace('\n', '')
transcript = list(filter(None, [self.labels_map.get(x) for x in list(transcript)]))
return transcript
def __len__(self):
return self.size
构造一个 频谱图 和 txt 的生成器
4. DataLoader 类构建
padding 每个batch的sample 在其后补0
def _collate_fn(batch):
def func(p):
return p[0].size(1)
# 选择时长最长的 batch最为longest_sample
batch = sorted(batch, key=lambda sample: sample[0].size(1), reverse=True)
longest_sample = max(batch, key=func)[0]
freq_size = longest_sample.size(0) #拿到mel值
minibatch_size = len(batch)
max_seqlength = longest_sample.size(1)
inputs = torch.zeros(minibatch_size, 1, freq_size, max_seqlength)
input_percentages = torch.FloatTensor(minibatch_size)
target_sizes = torch.IntTensor(minibatch_size)
targets = []
for x in range(minibatch_size):
sample = batch[x]
tensor = sample[0]
target = sample[1]
seq_length = tensor.size(1)
inputs[x][0].narrow(1, 0, seq_length).copy_(tensor)
input_percentages[x] = seq_length / float(max_seqlength)
target_sizes[x] = len(target)
targets.extend(target)
targets = torch.IntTensor(targets)
return inputs, targets, input_percentages, target_sizes
class AudioDataLoader(DataLoader):
def __init__(self, *args, **kwargs):
"""
Creates a data loader for AudioDatasets.
train_dataset,
num_workers=args.num_workers,
batch_sampler=train_sampler
"""
super(AudioDataLoader, self).__init__(*args, **kwargs)
self.collate_fn = _collate_fn
把data_source 切分成 [i:i+batch_+size] 为一块 的若干块 在通过shuffle随机打乱 yield 迭代取出
class BucketingSampler(Sampler):
def __init__(self, data_source, batch_size=1):
"""
Samples batches assuming they are in order of size to batch similarly sized samples together.
把data_source 切分成 [i:i+batch_+size] 为一块 的若干块 在通过shuffle随机打乱 yield 迭代取出
"""
super(BucketingSampler, self).__init__(data_source)
self.data_source = data_source
ids = list(range(0, len(data_source)))
self.bins = [ids[i:i + batch_size] for i in range(0, len(ids), batch_size)]
def __iter__(self):
for ids in self.bins:
np.random.shuffle(ids)
yield ids
def __len__(self):
return len(self.bins)
def shuffle(self, epoch):
np.random.shuffle(self.bins)
5. TODO
至此数据处理工作全部完成
下一章将开始讲解模型处理部分