Hadoop学习笔记(7)-简述MapReduce计算框架原理
1. MapReduce基本编程模型和框架
1.1 MapReduce抽象模型
大数据计算的核心思想是:分而治之。如下图1所示。把大量的数据划分开来,分配给各个子任务来完成。再将结果合并到一起输出。
注:如果数据的耦合性很高,不能分离,那么这种并行计算就不适合了。

图1:MapReduce抽象模型
1.2 Hadoop的MapReduce的并行编程模型
如下图2所示,Hadoop的MapReduce先将数据划分为多个key/value键值对。然后输入Map框架来得到新的key/value对,这时候只是中间结果,这个时候的value值是个值集合。再通过同步障(为了等待所有的Map处理完),这个阶段会把相同key的值收集整理(Aggregation&Shuffle)在一起,再交给Reduce框架做输出组合,如图2中每个Map输出的结果,有k1,k2,k3,通过同步障后,k1收集到一起,k2收集到一起,k3收集到一起,再分别交给Reduce,通过Reduce组合结果。
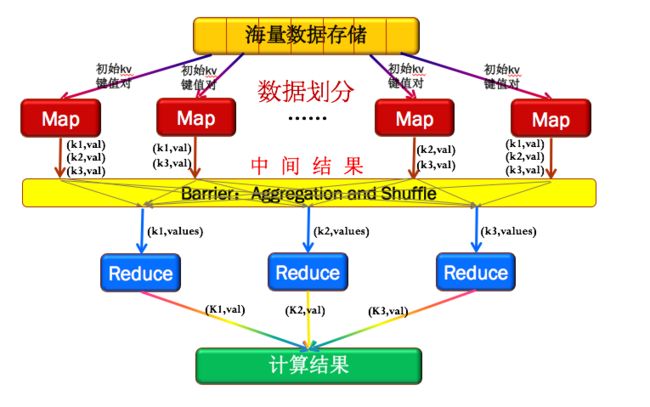
图2:Hadoop的MapReduce的框架
1.3 Hadoop的MapReduce的完整编程模型和框架
图3是MapReduce的完整编程模型和框架,比模型上多加入了Combiner和Partitioner。
1)Combiner
Combiner可以理解为一个小的Reduce,就是把每个Map的结果,先做一次整合。例如图3中第三列的Map结果中有2个good,通过Combiner之后,先将本地的2个good组合到了一起(红色的(good,2))。好处是大大减少需要传输的中间结果数量量,达到网络数据传输优化,这也是Combiner的主要作用。
2)Partitioner
为了保证所有的主键相同的key值对能传输给同一个Reduce节点,如图3中所有的good传给第一个Reduce前,所有的is和has传给第二个Reduce前,所有的weather,the和today传到第三个Reduce前。MapReduce专门提供了一个Partitioner类来完成这个工作,主要目的就是消除数据传入Reduce节点后带来不必要的相关性。
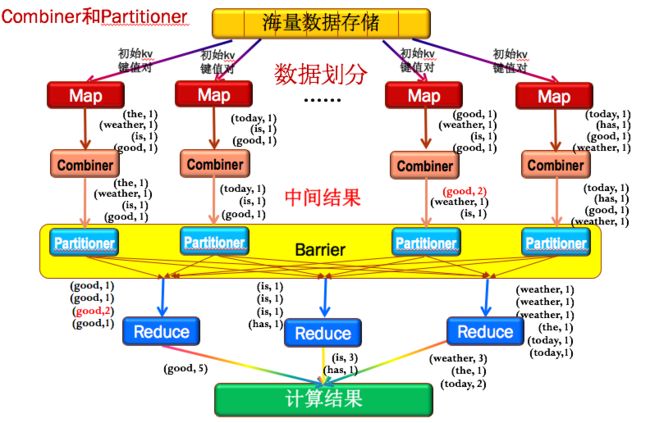
图3:Hadoop的MapReduce的完整编程模型和框架
2.Hadoop系统架构
图4是Hadoop系统的基本组成框架。从逻辑上看,Hadoop系统的基本组成架构包括分布式存储和并行计算两部分。
1)分布式存储框架(分布式文件系统HDFS)
Hadoop使用NameNode作为分布式存储的主控节点,用以存储和管理分布式文件系统的元数据,同时使用DataNode作为实际存储大规模数据从节点。
2)并行计算框架(MapReduce)
Hadoop使用JobTracker作为MapReduce框架的主控节点,用来管理和调度作业的执行,用TaskTracker管理每个计算从节点上任务的执行。
为了实现Hadoop设计的本地化计算,数据节点DataNode和计算节点TaskTracker将放在同个节点,每个从节点也是同时运行DataNode和TaskTracker,从而让每个TaskTracker尽量处理存储在本地DataNode上的数据。
数据主控节点NameNode与作业执行节点JobTracker即可以设置在同一个节点上,也可以考虑负载较高时,而设置在两个节点上。
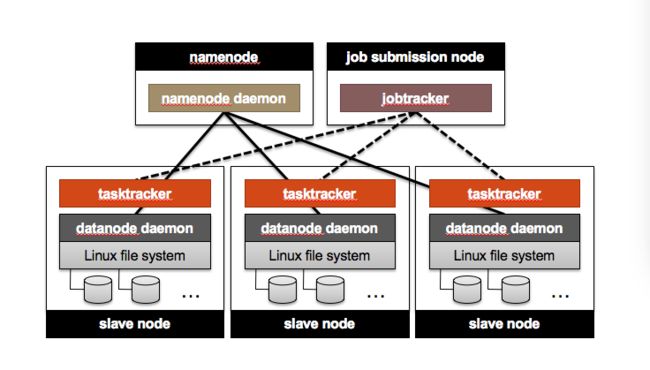
图4:Hadoop系统的基本组成框架
3.Hadoop MapReduce程序执行过程

图5:Hadoop MapReduce程序执行过程
MapReduce的整个工作过程如上图所示,它包含如下4个独立的实体:
1)客户端,用来提交MapReduce作业。
2)jobtracker,用来协调作业的运行。
3)tasktracker,用来处理作业划分后的任务。
4)HDFS,用来在其它实体间共享作业文件。
MapReduce整个工作过程有序地包含如下工作环节:
1)作业的提交
2)作业的初始化
3)任务的分配
4)任务的执行
5)进程和状态的更新
6)作业的完成
有关MapReduce的详细工作细节,请见:《Hadoop权威指南(第二版)》第六章MapReduce工作机制。
4.MapReduce执行框架的组件和执行流程
图6是MapReduce执行框架的组件和执行流程,下面足一做解释。
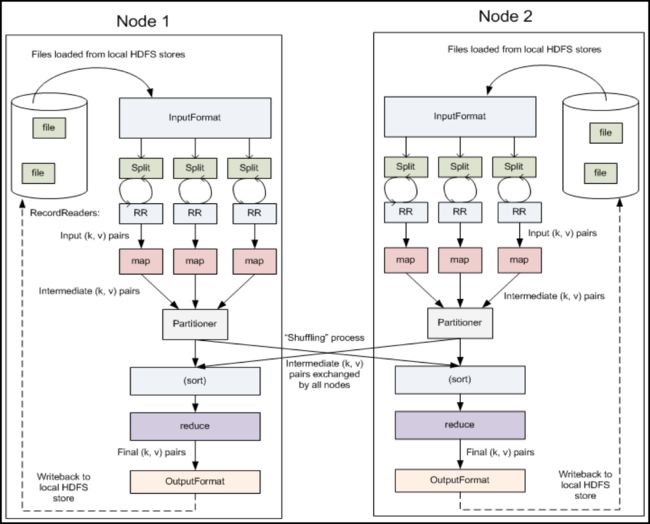
图6:MapReduce执行框架的组件和执行流程
4.1 文件输入格式InputFormat
1)定义了数据文件如何分割和读取
2)InputFile提供了以下一些功能
- 选择文件或者其它对象,用来作为输入
- 定义InputSplits,将一个文件分开成为任务
- 为RecordReader提供一个工厂,用来读取这个文件
3)有一个抽象的类FileInputFormat,所有的输入格式类都从这个类继承这个类的功能以及特性。当启动一个Hadoop任务的时候,一个输入文件所在的目录被输入到FileInputFormat对象中。FileInputFormat从这个目录中读取所有文件。然后FileInputFormat将这些文件分割为一个或者多个InputSplits。
4)通过在JobConf对象上设置JobConf.setInputFormat设置文件输入的格式
2)接口定义

图7:InputFormat接口定义
4.2 输入数据分块InputSplits
1)InputSplit定义了输入到单个Map任务的输入数据
2)一个MapReduce程序被统称为一个Job,可能有上百个任务构成
3)InputSplit将文件分为64MB的大小
- 配置文件hadoop-site.xml中的mapred.min.split.size参数控制这个大小
4)mapred.tasktracker.map.taks.maximum用来控制某一个节点上所有map任务的最大数目
4.3 数据记录读入RecordReader(RR)
1)InputSplit定义了一项工作的大小,但是没有定义如何读取数据
2)RecordReader实际上定义了如何从数据上转化为一个(key,value)对的详细方法,并将数据输出到Mapper类中
3)TextInputFormat提供了LineRecordReader
4.4 Mapper
1)每一个Mapper类的实例生成了一个Java进程(在某一个InputSplit上执行)
2)有两个额外的参数OutputCollector以及Reporter,前者用来收集中间结果,后者用来获得环境参数以及设置当前执行的状态。
3)现在用Mapper.Context提供给每一个Mapper函数,用来提供上面两个对象的功能
4.5 Combiner
1)合并相同key的键值对,减少partitioner时候的数据通信开销
2)conf.setCombinerClass(Reduce.class)
4.6 Partitioner & Shuffle
在Map工作完成之后,每一个 Map函数会将结果传到对应的Reducer所在的节点,此时,用户可以提供一个Partitioner类,用来决定一个给定的(key,value)对传输的具体位置
4.7 Sort
传输到每一个节点上的所有的Reduce函数接收到得Key,value对会被Hadoop自动排序(即Map生成的结果传送到某一个节点的时候,会被自动排序)
4.8 Reducer
1)做用户定义的Reduce操作
2)最新的编程接口是Reducer.Context
4.9 文件输出格式OutputFormat
1)说明
写入到HDFS的所有OutputFormat都继承自FileOutputFormat
每一个Reducer都写一个文件到一个共同的输出目录,文件名是part-nnnnn,其中nnnnn是与每一个reducer相关的一个号(partition id)
FileOutputFormat.setOutputPath()
JobConf.setOutputFormat()
2)接口定义
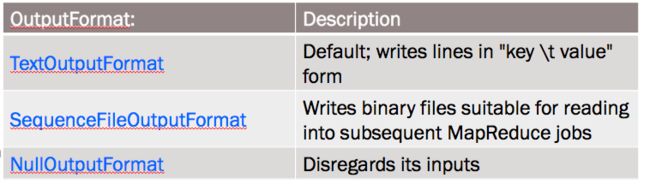
图8:OutputFormat接口定义
4.10 RecordWriter
TextOutputFormat实现了缺省的LineRecordWriter,以”key/value”形式输出一行结果。
5. 容错处理与计算性能优化
1)主要方法是将失败的任务进行再次执行
2)TaskTracker会把状态信息汇报给JobTracker,最终由JobTracker决定重新执行哪一个任务
3)为了加快执行的速度,Hadoop也会自动重复执行同一个任务,以最先执行成功的为准(投机执行)
4)mapred.map.tasks.speculative.execution
5)mapred.reduce.tasks.speculative.execution
6. 参考内容
[1] 《深入理解大数据-大数据处理与编程实践》
[2] 导师云计算课程PPT
[3] Poll的笔记:http://www.cnblogs.com/maybe2030/p/4593190.html#_label3
XianMing