推荐系统-冷启动方案
最近调研了一些冷启动方案,现汇总如下
商品冷启动
商品冷启动一般在item的embedding上优化
Graph Embedding
在Graph Embedding I2I的基础上,加入商品的Side Information,进一步提升Embedding的泛化学习能力,更好地解决长尾以及商品冷启动问题
《Hybrid Item-Item Recommendation via Semi-Parametric Embedding》
前言
2019 IJCAI (阿里机器智能技术和优酷人工智能平台)
本文提出了一种半参表示框架, 它结合商品的行为信息和内容信息,以达到在维持行为丰富 item 上表现的同时,缓解新发商品上的冷启动问题。另外本文引入 sDAE 来帮助学习更强力的内容表示,以达到更鲁棒的效果。3 个真实数据集、3类对比推荐算法、4 种评价指标上的对比实验,验证了该算法的可靠性和鲁棒性。
半参向量表示(SPE)
同时使用行为和内容信息来建模商品表示: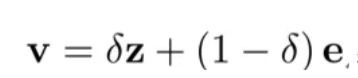 ,其中, v 为商品的向量表示; z 为商品的行为信息表示部分, 每个商品的行为表示各自不同; e 为内容信息表示部分, 通过特征输入
,其中, v 为商品的向量表示; z 为商品的行为信息表示部分, 每个商品的行为表示各自不同; e 为内容信息表示部分, 通过特征输入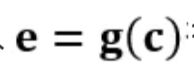 得到, c 为商品的内容输入向量(商品的文本、描述、类目等); δ 为两者之间的权重大小, 由当前item上的历史统计信息(商品曝光、点击次数等)决定。若当前item行为丰富, δ较大, 最终的向量由z主导; 而新品 item 行为信息少, δ 较小,模型对行为信息的权重加大。
得到, c 为商品的内容输入向量(商品的文本、描述、类目等); δ 为两者之间的权重大小, 由当前item上的历史统计信息(商品曝光、点击次数等)决定。若当前item行为丰富, δ较大, 最终的向量由z主导; 而新品 item 行为信息少, δ 较小,模型对行为信息的权重加大。
行为向量 z 和内容向量 e 分别为模型中非参数化向量和参数化向量, 结合两者,作者将其称作半参向量表示。相似度计算: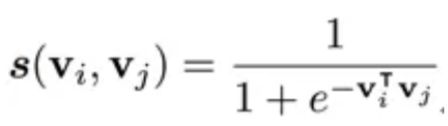 ,为了学习更鲁棒的内容向量表示,对参数化向量表示,引入深度学习中的多层降噪自动编码机(stacked denoise autoencoder, sDAE)。
,为了学习更鲁棒的内容向量表示,对参数化向量表示,引入深度学习中的多层降噪自动编码机(stacked denoise autoencoder, sDAE)。
Stacked and Reconstructed Graph Convolutional Networks for Recommender Systems
2019 IJCAI ?star-gcn.pdf
作者提出了一个图卷积网络(STAR-GCN)架构,用于学习节点表示,以提高推荐系统的性能,特别是在冷启动场景中。 STAR-GCN采用了一叠GCN编码器 - 解码器以对中间过程进行监督来改进最终的预测效果。与one-hot编码节点输入的图卷积矩阵完成模型不同,STAR-GCN学习低维用户和商品隐变量作为输入来限制模型空间的复杂性。此外,STAR-GCN可以通过重构masked的输入节点embedding为新节点生成节点embedding,这本质上解决了冷启动问题。
用户冷启动
社交网络挖掘好友
当一个新用户通过微博或者Facebook账号登录网站时, 我们可以从社交网站中获取用户的好友列表,然后给用户推荐好友在网站上喜欢的物品。 从而我们可以在没有用户行为记录时就给用户提供较高质量的推荐结果,部分解决了推荐系统的冷启动问题。
《DropoutNet: Addressing Cold Start in Recommender Systems》
nips2017 链接
【背景】
要处理冷启动问题,我们必须使用content信息。但是想要整个系统的推荐效果较好,我们也必须使用preference信息。目前最好的方法,就是二者结合形成的Hybrid方法,但是往往有多目标函数,训练复杂。
如何把content和preference的信息都结合起来,同时让训练过程更简单?
针对冷启动问题,本文不是引入额外的内容信息和额外的目标函数,而是改进整个学习过程,让模型可以针对这种缺失的输入来训练。
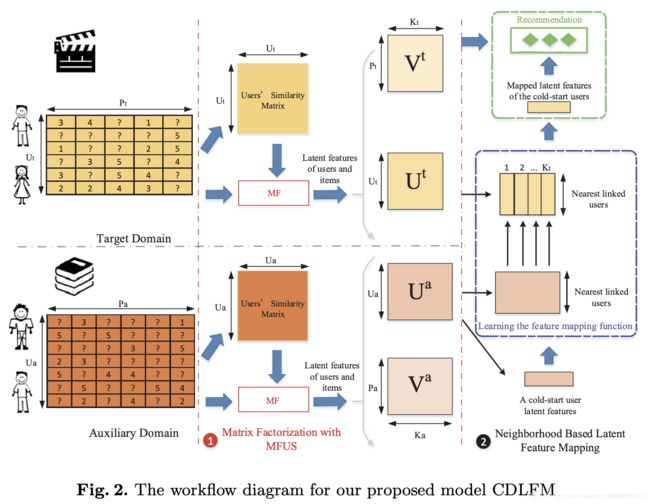
基于邻居用户特征映射的跨领域推荐
链接
- 找到目标用户的最近邻用户(辅助领域中有相似评分行为的用户)
- 使用邻居用户的潜在特征来学习潜在特征映射函数
- 基于映射函数和目标用户在辅助领域的潜在特征来预测其在目标领域的特征,从而生成推荐
Crowd-based Filtering
基于人群属性来推荐的方法,其通过将用户按照性别、年龄段、收货城市等粗粒度的属性划分为若干个人群,然后为基于每个人群的行为数据挑选出该人群点击率高的TopK个商品作为该人群感兴趣的商品。(hot的基础上划分group)
Attribute2I
链接
将用户的静态属性(年龄、性别、常住地、LBS位置)以及宝贝的特征融合进来,对商品打分。
将用户的各种属性组合起来作为一个Key(比如:F_19-25_1_N_UNK_北京市),然后去检索,新增一种召回类型。
以下几个方案思想一致:先推几个商品,根据这几个商品去判断用户偏好
基于代表性(2017)
使用有代表性的项目和用户子集,即依赖那些能够“代表”项目和用户的用户。代表性用户的兴趣偏好线性组合能与其他用户的无限接近。例如,基于代表性的矩阵因子分解(RBMF,Representative Based Matrix Factorization),其实是矩阵因子分解方法的扩展,其附加约束条件是m个项应该由k个项的线性组合表示,如下面的目标函数所示:

当新用户进入平台时,要求新用户对这k个项进行评级,并用它来推断其他m-k项的评级。
Bandit算法
多臂老虎机
MeLU: Meta-Learned User Preference Estimator for Cold-Start Recommendation
KDD 2019
本文提出了一种新的推荐系统,解决了基于少量样本物品来估计用户偏好的冷启动问题。为了确定用户在冷启动状态下的偏好,现有的推荐系统,如Netflix,最初向用户提供商品;我们称这些物品为候选证据。然后根据用户选择的物品提出建议。以往的推荐研究有两个局限性:(1)消费了少量商品的用户推荐不佳,(2)候选证据不足,无法识别用户偏好。为了克服这两个限制,我们提出了一种基于元学习的推荐系统MeLU。从元学习中,MeLU可以通过几个例子快速地采用新任务,通过几个消费项来估计新用户的偏好。此外,我们提供了一个证据候选选择策略,以确定自定义偏好估计的区分项目。我们用两个基准数据集对MeLU进行了验证,与两个比较模型相比,该模型的平均绝对误差至少降低了5.92%。我们还进行了用户研究实验来验证证据选择策略。