C和嵌入式
1 嵌入式领域的C语言
假定掌握了C语言基础,了解学习C在嵌入式领域的应用有哪些特殊之处。工作中遇到的基础知识问题请自行解决,推荐阅读《C程序设计》、《C和指针》、《C陷阱与缺陷》,最好还能理解编译、汇编、链接、运行等过程。
推荐一个博客:https://blog.csdn.net/zhzht19861011/article/details/45508029
以下章节列出项目开发用到最多或者最需要关注的地方。
2 硬件知识
能够看懂基本的电路原理图,理解UART、IIC、SPI、CAN等常见总线通讯,能够查阅手册,能够将原理图和手册结合映射,落实到代码。硬件知识和阅读手册的能力在工作中学习积累。
3 C 语言嵌入式系统编程:软件架构
3.1 模块划分
模块划分的"划"是规划的意思,意指怎样合理的将一个很大的软件划分为一系列功能独立的部分合作完成系统的需求。
C 语言作为一种结构化的程序设计语言,在模块的划分上主要依据功能。
C 语言模块化程序设计需理解如下(但不仅限于)概念:
a) 模块即是一个.c 文件和一个.h 文件的结合,头文件(.h)中是对于该模块接口的声明;
b) 某模块提供给其它模块调用的外部函数及数据需在.h 中文件中冠以 extern 关键字声明;
c) 模块内的函数和全局变量需在.c 文件开头冠以 static 关键字声明;
d) 永远不要在.h 文件中定义变量!定义变量和声明变量的区别在于定义会产生内存分配的操作,是汇编阶段的概念;声明则只是告诉包含该声明的模块在链接阶段从其它模块寻找外部函数和变量。
一个嵌入式系统通常包括两类模块:
a) 硬件驱动模块,一种特定硬件对应一个模块;
b) 软件功能模块,其模块的划分应满足低偶合、高内聚的要求。
3.2 多任务还是单任务
所谓"单任务系统"是指该系统不能支持多任务并发操作,宏观串行地执行一个任务。而多任务系统则可以宏观并行(微观上可能串行)地"同时"执行多个任务。
多任务的并发执行通常依赖于一个多任务操作系统(OS),多任务OS 的核心是系统调度器,它使用任务控制块(TCB)来管理任务调度功能。TCB包括任务的当前状态、优先级、要等待的事件或资源、任务程序码的起始地址、初始堆栈指针等信息。调度器在任务被激活时,要用到这些信息。此外,TCB 还被用来存放任务的"上下文"(context)。任务的上下文就是当一个执行中的任务被停止时,所要保存的所有信息。通常,上下文就是计算机当前的状态,也即各个寄存器的内容。当发生任务切换时,当前运行的任务的上下文被存入 TCB,并将要被执行的任务的上下文从它的TCB 中取出,放入各个寄存器中。
究竟选择多任务还是单任务方式,依赖于软件的体系是否庞大。
3.3 单任务程序典型架构
- 从CPU复位时的指定地址开始执行;
- 跳转至汇编代码 startup 处执行;
- 跳转至用户主程序 main 执行,在main 中完成:
a.初试化各硬件设备;
b.初始化各软件模块;
c.进入死循环(无限循环),调用各模块的处理函数;
3.4 中断服务程序
中断是嵌入式系统中重要的组成部分,但是在标准C 中不包含中断。许多编译开发商在标准C 上增加了对中断的支持,提供新的关键字用于标示中断服务程序 (ISR),类似于__interrupt、#program interrupt 等。当一个函数被定义为 ISR的时候,编译器会自动为该函数增加中断服务程序所需要的中断现场入栈和出栈代码。
中断服务程序需要满足如下要求:
a) 不能返回值;
b) 不能向 ISR 传递参数;
c) ISR应该尽可能的短小精悍;
d) printf(char * lpFormatString,…)函数会带来重入和性能问题,不能在 ISR 中采用。
e) …
3.5 C 的面向对象化
在面向对象的语言里面,出现了类的概念。类是对特定数据的特定操作的集合体。类包含了两个范畴:数据和操作。而 C 语言中的 struct 仅仅是数据的集合,我们可以利用函数指针将 struct 模拟为一个包含数据和操作的"类"。
我们可以利用 C 语言模拟出面向对象的三个特性:封装、继承和多态,但是更多的时候,我们只是需要将数据与行为封装以解决软件结构混乱的问题。C 模拟面向对象思想的目的不在于模拟行为本身,而在于解决某些情况下使用 C 语言编程时程序整体框架结构分散、数据和函数脱节的问题。
软件结构是软件的灵魂!结构混乱的程序面目可憎,调试、测试、维护、升级都极度困难。
4 C 语言嵌入式系统编程:内存操作
4.1 内存分配
4.1.1 数据放哪里
栈空间:局部变量、函数形参、自动变量(调用后释放)
堆空间:malloc、realloc、calloc分配空间
数据段:.bss:保存未初始化的全局变量
.rodata:常量
.data(静态数据区):全局变量、static修饰的局部变量
4.1.2 内存分配方式
(1)从全局数据区分配
(2)在栈上创建
(3)在堆上创建
4.1.3 常见的内存错误
(1)内存分配未成功,却使用了它
(2)内存分配虽然成功,但是尚未初始化就引用它
(3)内存分配成功并已经初始化,但操作越过了内存的边界
(4)忘记了释放内存,造成了内存泄漏
(5) 释放了内存却继续使用它
4.1.4 字节序和位序、位域
4.1.4.1 比特序 / 位序
我们知道一个字节有8位,也就是8个比特位。从第0位到第7位共8位。比特序就是用来描述比特位在字节中的存放顺序的。
(1)比特序分为两种:LSB 0 位序和MSB 0 位序。
LSB是指 least significant bit,MSB是指 most significant bit。
LSB 0 位序是指:字节的第0位存放数据的least significant bit,即我们的数据的最低位存放在字节的第0位。
MSB 0 位序是指:字节的第0位存放数据的most significant bit,即我们的数据的最高位存放在字节的第0位。
所以说对于代码:char *ch = 0x96; // 0x96 = 1001 0110

指针ch到底指向哪里呢?不难知道,如果是LSB 0 位序则显然指针ch指向最右边的也是最低位的0.
而如果是MSB 0 位序则显然指针ch指向最左边的也是最高位的1.
(2)小端CPU通常采用的是LSB 0 位序,但是大端CPU却有可能采用LSB 0 位序也有可能采用的是MSB 0 位序
(3)推荐的标准是MSB 0 位序。
4.1.4.2 大小端和字节序
术语“端”是指:在内存中的一个较大的数据,它是由各个可以被单独寻址的部分组成,这些组成部分在该数据中是以怎样的顺序存放的呢?而这个问题涉及到“端”的概念,CPU是大端还是小端决定了这些组成部分的存放顺序。这些组成部分可能是16或32位的字、8位的字节、甚至是比特位。
0x0A0B0C0D在大小端存储器上的排列顺序:
小端
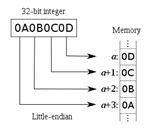
大端

很显然“小端”机器符合“高高低低”的原则,即高位字节或字存放在高地址,低位字节或字存放在低地址。
另外“小端”机器中,数据在CPU的寄存器和内存中的存放顺序是一致的。
4.1.4.3 任务
a) 查阅手册弄清楚MPC5744P字节序和位序(包括寄存器、RAM、FLASH等)、传感器报文的字节序和位序;
b) 网络查询位域的概念,弄清楚在MPC5744P的状况;
4.2 数据指针
在嵌入式系统的编程中,常常要求在特定的内存单元读写内容,汇编有对应的 MOV 指令,而除 C/C++以外的其它编程语言基本没有直接访问绝对地址的能力。在嵌入式系统的实际调试中,多借助 C 语言指针所具有的对绝对地址单元内容的读写能力。
以指针直接操作内存多发生在如下几种情况:
a) 某I/O 芯片被定位在CPU的存储空间而非I/O 空间,而且寄存器对应于某特定地址;
b) 两个 CPU 之间以双端口 RAM 通信,CPU 需要在双端口 RAM 的特定单元(称为 mail box)书写内容以在对方 CPU 产生中断;
c) 读取在 ROM或 FLASH 的特定单元所烧录的汉字和英文字模。
unsigned char *p = (unsigned char *)0xF000FF00;
*p=11;
以上程序的意义为在绝对地址0xF0000+0xFF00(80186使用16位段地址和16 位偏移地址)写入 11。
在使用绝对地址指针时,要注意指针自增自减操作的结果取决于指针指向的数据类别。上例中 p++后的结果是 p= 0xF000FF01,若p 指向 int,即:int *p = (int *)0xF000FF00;
p++(或++p)的结果等同于:p = p+sizeof(int),而 p-(或-p)的结果是 p = p-sizeof(int)。
同理,若执行:long int *p = (long int *)0xF000FF00;
则p++(或++p)的结果等同于:p = p+sizeof(long int) ,而p-(或-p)的结果是p = p-sizeof(long int)。
记住:CPU 以字节为单位编址,而 C 语言指针以指向的数据类型长度作自增和自减。理解这一点对于以指针直接操作内存是相当重要的。
4.3 函数指针
首先要理解以下三个问题:
a) C语言中函数名直接对应于函数生成的指令代码在内存中的地址,因此函数名可以直接赋给指向函数的指针;
b) 调用函数实际上等同于"调转指令+参数传递处理+回归位置入栈",本质上最核心的操作是将函数生成的目标代码的首地址赋给 CPU的 PC寄存器;
c) 因为函数调用的本质是跳转到某一个地址单元的 code 去执行,所以可以"调用"一个根本就不存在的函数实体。
typedef void (*lpFunction) ( ); /* 定义一个无参数、无返回类型的函数指针类型*/
/* 定义一个函数指针,指向 CPU 启动后所执行第一条指令的位置*/
lpFunction lpReset = (lpFunction)0xF000FFF0;
lpReset(); /* 调用函数 */
在以上的程序中,我们根本没有看到任何一个函数实体,但是我们却执行了这样的函数调用:lpReset()。
记住: 函数就是指令的集合;你可以调用一个没有函数体的函数,本质上只是换一个地址开始执行指令!
4.4 关键字 const
const 意味着"只读"。它限定一个变量不允许被改变,产生静态作用。它要求其所修饰的对象为常量,不可对其修改和二次赋值操作(不能作为左值出现)。看几个例子:
const int a;
//同上面的代码行是等价的,都表示一个常整形数。
int const a;
/* const具有"左结合"性,即const修饰*,那么,不难理解,该句表示一个指向整数的常指针,a指向的整数可以修改,但指针a不能修改。*/
int *const a;
/* 与下面的这一行等价,根据"左结合"性,const修饰的是(*a),也即是一个整数,所以,这两句表示指针指向一个常整数。*/
const int *a;
int const *a;
/*根据"左结合"性质,第一个const修饰(*),第二个const修饰(a),因此,这句话表示一个指向常整数的常指针。*/
int const *a const;
合理的使用const关键字,不仅能够让编译器很好的保护相应的数据,还能够直观的向代码的阅读者传递有用信息。
任务:整理以下使用情形,
修饰局部变量、修饰常量静态字符串、常量指针与指针常量、修饰函数的参数、修饰全局变量。
4.5 关键字 volatile
volatile是一个类型修饰符(type specifier).volatile的作用是作为指令关键字,确保本条指令不会因编译器的优化而省略,且要求每次直接读值。 volatile的变量是说这变量可能会被意想不到地改变,这样,编译器就不会去假设这个变量的值了。
譬如如下代码:
int a,b,c;
a = inWord(0x100); /*读取 I/O 空间 0x100 端口的内容存入 a 变量*/
b = a;
a = inWord (0x100); /*再次读取 I/O 空间0x100端口的内容存入 a 变量*/
c = a;
很可能被编译器优化为:
int a,b,c;
a = inWord(0x100); /*读取 I/O 空间 0x100 端口的内容存入 a 变量*/
b = a;
c = a;
但是这样的优化结果可能导致错误,如果 I/O 空间 0x100 端口的内容在执行第一次读操作后被其它程序写入新值,则其实第2次读操作读出的内容与第一次不同,b和c 的值应该不同。在变量a的定义前加上 volatile 关键字可以防止编译器的类似优化。
volatile 变量可能用于如下几种情况:
• 并行设备的硬件寄存器(如:状态寄存器,例中的代码属于此类);
• 一个中断服务子程序中会访问到的非自动变量(也就是全局变量);
• 多线程应用中被几个任务共享的变量。
4.6 关键字 static
static在面向过程编程中的使用场景包括三种:
- 修饰函数体内的变量(局部)
- 修饰函数体外的变量(全局)
- 修饰函数
第一种情况,static延长了局部变量的生命周期,static的局部变量,并不会随着函数的执行结束而被销毁,当它所在的函数被再次执行时,该静态局部变量会保留上次执行结束时的值。即改变了局部变量的存储域,从栈变为了全局(静态)存储区。
对于后面的两种情况,static是对它修饰的对象进行了作用域限定,static修饰的函数以及函数外的变量,都是只能在当前的源文件中被访问,其它的文件不能直接访问。
任务:思考在哪些场合必须用到static,在哪些场合使用static更好,好处是什么。
4.7 总结
本节主要讲述了嵌入式系统C编程中内存操作的相关技巧。掌握并深入理解关于数据指针、函数指针、动态申请内存、const及volatile关键字等的相关知识,是一个优秀的C语言程序设计师的基本要求。当我们已经牢固掌握了上述技巧后,我们就已经学会了C语言的99%,因为C语言最精华的内涵皆在内存操作中体现。
5 定时器
没有硬件或软件定时器的世界是无法想像的,比如:
(1) 没有定时器,一个操作系统将无法进行时间片的轮转,于是无法进行多任务的调度;
(2) 没有定时器,一个多媒体播放软件将无法运作,因为它不知道何时应该切换到下一帧画面;
(3) 没有定时器,一个网络协议将无法运转,因为其无法获知何时包传输超时并重传之,无法在特定的时间完成特定的任务。
裸机系统也需要定时器,用于延时、调度周期性任务、超时检测管理等功能。
6 嵌入式系统软件的分类
按软件复杂程度来分类,嵌入式系统有:循环轮询系统;有限状态机系统;前后台系统;单处理器多任务系统;多处理器多任务系统。
循环轮询系统:最简单的软件结构是循环轮询,程序依次检查系统的每一个输入条件,一旦条件成立就进行相应的处理。由于不可确定性,对于大量的I/O服务的应用,不容易实现;大的程序不便于调试。因此合适于慢速和非常快速的简单系统,很少用到。
有限状态机系统:优点:简单易用,状态间关系直观看到,便于编程;可以快速执行;只是通过改变输出功能来改变机器的响应。缺点:任何时刻系统只能有一个状态,无法表示并发性,不能描述异步并发系统;在系统部件多时,状态数随之增加,导致复杂性显著增长;对于大的应用系统,难于调试。
前后台系统:后台:一个一直在运行的系统。 前台:是由一些中断处理过程组成。
当有一前台事件(外部事件)发生时,引起中断,于是将暂停后台的运行而进行前台处理,处理完毕后又回到后台(通常称为主程序)。
单处理器多任务系统、多处理器多任务系统是操作系统范畴,暂时不用。
有限状态机系统和前后台系统通常是同时考虑和综合设计的,就是有限状态机系统也会用到前后台,前后台系统也会用到有限状态机。
7 阅读FlexCAN、J1939源码
7.1 分析代码结构、调用关系;
7.2 比较CAN0、CAN1、CAN2各自的驱动代码有什么特点,有什么不同,查阅手册说明初始化、发送、接收各语句的意思,说明为什么要这样写;
此项考察基本的代码分析能力,查阅手册的能力,驱动代码和手册结合的能力,后期拓展到分析整个工程。
个人最终目标是能够自主查阅手册、编写驱动,根据功能需求自主设计代码结构。