ResNeXt、SENet、SE-ResNeXt论文代码学习与总结
ResNeXt - Aggregated Residual Transformations for Deep Neural Networks
还是先上图最直观:

左边是ResNet50,右边是ResNeXt group=32的bottleneck结构。
ResNeXt就是在ResNet的基础上采用了inception的思想,加宽网络(resnet-inception是网络还是inception的,但采用了残差思想)
而且ResNeXt有3中形式:
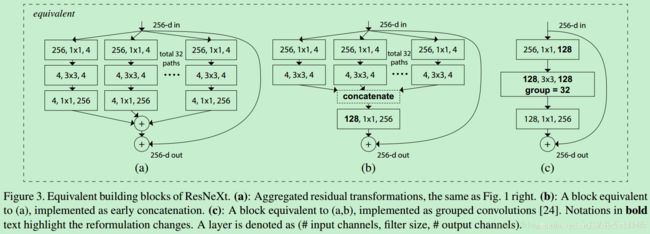
本地cpn代码中用的是第三种,而github上常用的是第二种
下面对核心代码的学习进行总结
def Build_ResNext(self, input_x):
# only cifar10 architecture
# 由于是用在cifar10上 所以很多部分被精简 不能有太多stride
input_x = self.first_layer(input_x, scope='first_layer')
x = self.residual_layer(input_x, out_dim=64, layer_num='1') # 核心部分
def residual_layer(self, input_x, out_dim, layer_num, res_block=blocks):
# split + transform(bottleneck) + transition + merge
for i in range(res_block):
# input_dim = input_x.get_shape().as_list()[-1]
input_dim = int(np.shape(input_x)[-1])
if input_dim * 2 == out_dim:
flag = True
stride = 2
channel = input_dim // 2
else:
flag = False
stride = 1
# 第一次stride=2,split_layer相当于b中包括concatenate与其之前所有操作
x = self.split_layer(input_x, stride=stride, layer_name='split_layer_'+layer_num+'_'+str(i))
# 相当于最后一步
x = self.transition_layer(x, out_dim=out_dim, scope='trans_layer_'+layer_num+'_'+str(i))
if flag is True :
pad_input_x = Average_pooling(input_x)
pad_input_x = tf.pad(pad_input_x, [[0, 0], [0, 0], [0, 0], [channel, channel]]) # [?, height, width, channel]
else :
pad_input_x = input_x
input_x = Relu(x + pad_input_x)
return input_x
def split_layer(self, input_x, stride, layer_name):
with tf.name_scope(layer_name) :
layers_split = list()
for i in range(cardinality) :
splits = self.transform_layer(input_x, stride=stride, scope=layer_name + '_splitN_' + str(i))
layers_split.append(splits)
return Concatenation(layers_split)
def transform_layer(self, x, stride, scope):
with tf.name_scope(scope) :
x = conv_layer(x, filter=depth, kernel=[1,1], stride=stride, layer_name=scope+'_conv1')
x = Batch_Normalization(x, training=self.training, scope=scope+'_batch1')
x = Relu(x)
x = conv_layer(x, filter=depth, kernel=[3,3], stride=1, layer_name=scope+'_conv2')
x = Batch_Normalization(x, training=self.training, scope=scope+'_batch2')
x = Relu(x)
return x
Squeeze-and-Excitation Networks(简称SENet)
开篇介绍了inception和inside-outside网络(网络中考虑空间中上下文信息)
这些都是空间上来提升网络。
本文作者希望能在其他层面考虑,比如特征间通道之间的关系
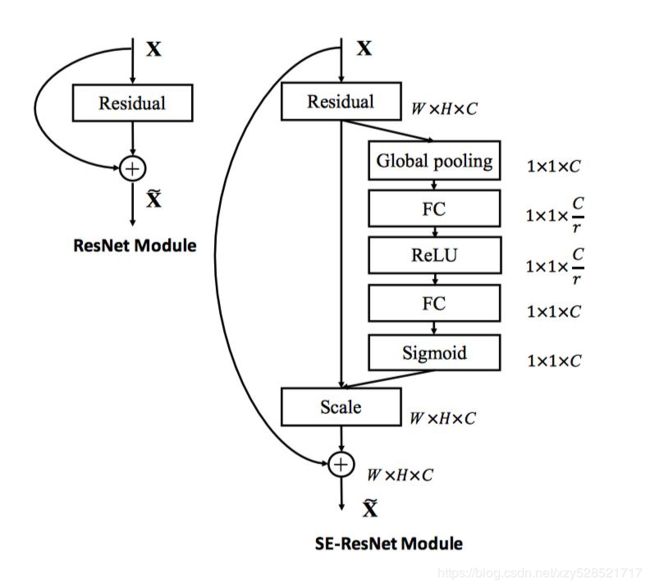
SE核心操作:
这里我们使用 global average pooling 作为 Squeeze 操作。紧接着两个 Fully Connected 层组成一个 Bottleneck 结构去建模通道间的相关性,并输出和输入特征同样数目的权重。我们首先将特征维度降低到输入的 1/16,然后经过 ReLu 激活后再通过一个 Fully Connected 层升回到原来的维度。这样做比直接用一个 Fully Connected 层的好处在于:1)具有更多的非线性,可以更好地拟合通道间复杂的相关性;2)极大地减少了参数量和计算量。然后通过一个 Sigmoid 的门获得 0~1 之间归一化的权重,最后通过一个 Scale 的操作来将归一化后的权重加权到每个通道的特征上
这里的SE操作是连在resnet原本的bottleneck之后
代码可以说非常好理解了
def se_resnet_bottleneck(l, ch_out, stride):
shortcut = l
l = Conv2D('conv1', l, ch_out, 1, activation=BNReLU)
l = Conv2D('conv2', l, ch_out, 3, strides=stride, activation=BNReLU)
l = Conv2D('conv3', l, ch_out * 4, 1, activation=get_bn(zero_init=True))
squeeze = GlobalAvgPooling('gap', l)
squeeze = FullyConnected('fc1', squeeze, ch_out // 4, activation=tf.nn.relu)
squeeze = FullyConnected('fc2', squeeze, ch_out * 4, activation=tf.nn.sigmoid)
data_format = get_arg_scope()['Conv2D']['data_format']
ch_ax = 1 if data_format in ['NCHW', 'channels_first'] else 3
shape = [-1, 1, 1, 1]
shape[ch_ax] = ch_out * 4
l = l * tf.reshape(squeeze, shape)
out = l + resnet_shortcut(shortcut, ch_out * 4, stride, activation=get_bn(zero_init=False))
return tf.nn.relu(out)
def GlobalAvgPooling(x, data_format='channels_last'):
"""
Global average pooling as in the paper `Network In Network
`_.
Args:
x (tf.Tensor): a 4D tensor.
Returns:
tf.Tensor: a NC tensor named ``output``.
输出一个(输入channel维的向量)这个方法主要就是在参数量大的时候降维有点类似全连接层的操作
"""
assert x.shape.ndims == 4
data_format = get_data_format(data_format)
axis = [1, 2] if data_format == 'channels_last' else [2, 3]
return tf.reduce_mean(x, axis, name='output')
SE-ResNeXt
SE-ResNeXt tensorflow
就是把senet中bottleneck换成ResNeXt的bottleneck
具体代码就是在ResNeXt代码的residual_layer中transition后加入squeeze_excitation_layer
以上全都是Resnet的变种
只研究Resnet变种的原因:

相对于层数,参数少,准确率高,层数深