快速搞定docker部署Filebeat、Elasticsearch、Logstash与Kibana
本文介绍使用docker安装部署Filebeat与Elasticsearch、Logstash、Kibana(简称ELK)全家桶7.5.1。如果熟悉框架的话,直接copy配置文件与docker命令,简单删减和修改路径,即可快速启动整个链路。
安装docker环境以及常用docker命令,请点击跳转查看
简单的ELK数据平台是这样的流程:
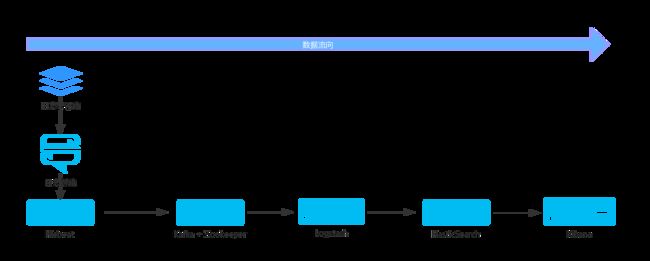
由于Kafka并不是ELK中必须的组件,所以本博客跳过部署Kafka,直接将Filebeat数据打到logstash上。关于Kafka的相关知识,以后再作详细讲解。
本文中的配置环境是这样的:
Filebeat在A机器上采集日志,ELK部署在B机器上。其中Elasticsearch与Logstash都采用的是单节点安装。
版本选择
写此文的时候,Filebeat和ELK最新的版本为7.6.1,不过笔者看了Filebeat 7.6.1的发布日志,发现该版本属于一个紧急bugfix版本——因为7.6.0的bug导致k8s pods的标签/注解存在问题。但是7.6.1的稳定性依旧不敢保证,毕竟笔者的项目接下来service mesh化是要结合k8s的,为了减小风险,退而求其次,选择7.5.2。后来因为踩坑又换到7.5.1,原因在下面说明。
filebeat7.6.0的bug对应issue–>点此跳转
filebeat7.5.2在搭建之后运行几小时之后,会出现filebeat io timeout的问题。官方论坛有人提出从7.5.1升级到7.5.2之后也出现了同样的问题,但是笔者并没有找到官方给出有效的解决方案。另外出于时间成本考虑没有时间去查找问题,所以选择版本为7.5.1。目前数据流已经稳定运行两周了。
按照官方说明,只要全家桶不是升级到8.0,都是可以轻松升级的。所以系统稳定后随时可以升级。
安装Elasticsearch
Elasticsearch是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。
# 创建自定义的网络(用于连接到连接到同一网络的其他服务(例如Logstash和Kibana))
docker network create somenetwork
# 运行 elasticsearch
docker run --restart=always --log-driver json-file --log-opt max-size=100m --log-opt max-file=2 -d --name elasticsearch --net somenetwork -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.5.1
# 查看容器状态
docker ps
# 检测 elasticsearch 是否启动成功
curl 127.0.0.1:9200
安装Logstash
Logstash作为Elasicsearch常用的实时数据采集引擎,可以采集来自不同数据源的数据,并对数据进行处理后输出到多种输出源,是Elasticstack的重要组成部分。
增加logstash的声明文件,logstash.yml。编辑内容如下
# 配置文件读取路径
path.config: /home/ec2-user/docker_config/logstash/conf.d/*.conf
# 日志输出路径
path.logs: /var/log/logstash
在上面配置文件读取路径中,增加一个测试文件test.conf,内容如下:
input {
beats {
port => 5044
}
}
filter {
if "java-logs" in [tags]{
grok {
# grok正则化会按照顺序许匹配送进来的日志,当碰到第一个匹配成功的日志就break掉这个循环。
match => {
# 分别是服务器记录行为日志,不带参数参数的请求,带参的get请求,带参的post请求,兼容旧版的记录行为日志。这里的格式就跟具体业务的日志有关了
"message" => ["%{TIMESTAMP_ISO8601:logtime} %{DATA} %{LOGLEVEL:loglevel} %{DATA:classpath} - %{DATA:logcontent} %{DATA:logcontent} %{DATA:logcontent} %{DATA:logcontent} %{DATA:logcontent} %{WORD:logdata}",
"%{TIMESTAMP_ISO8601:logtime} %{DATA} %{LOGLEVEL:loglevel} %{DATA:classpath} - REQUEST DATA : uri=%{URIPATHPARAM:request};client=%{IP:clientIp}];&&&&%{DATA:common_param}&&&&;耗时:%{NUMBER:costtime}ms",
"%{TIMESTAMP_ISO8601:logtime} %{DATA} %{LOGLEVEL:loglevel} %{DATA:classpath} - REQUEST DATA : uri=%{URIPATH:request}\?%{DATA:get_param};client=%{IP:clientIp}];&&&&%{DATA:common_param}&&&&;耗时:%{NUMBER:costtime}ms",
"%{TIMESTAMP_ISO8601:logtime} %{DATA} %{LOGLEVEL:loglevel} %{DATA:classpath} - REQUEST DATA : uri=%{URIPATHPARAM:request};client=%{IP:clientIp};payload=%{DATA:payload}];&&&&%{DATA:common_param}&&&&;耗时:%{NUMBER:costtime}ms",
"%{TIMESTAMP_ISO8601:logtime} %{LOGLEVEL:loglevel} %{DATA} %{DATA:classpath} : %{DATA:logcontent} %{DATA:logcontent} %{DATA:logcontent} %{DATA:logcontent} %{DATA:logcontent} %{WORD:logdata}"]
}
# 过滤完成之后删除多余字段,节约磁盘空间。
remove_field => ["@version","host.name"]
}
# 拆分common_param字段(采用ruby插件)
ruby {
code => "
if !event.get('common_param').nil? then
array1 = event.get('common_param').split('%')
array1.each do |temp1|
if temp1.nil? then
next
end
array2 = temp1.split('=')
key = array2[0]
value = array2[1]
if key.nil? then
next
end
event.set(key, value)
end
end
"
# 移除message字段
remove_field => [ "message" ]
}
# 如果是debug级别日志,直接抛弃掉这条日志
if [loglevel] !~ "(ERROR|WARN|INFO)" {
drop { }
}
# 抛弃掉grok解析失败的日志
if "_grokparsefailure" in [tags] {
drop { }
}
# 使用日志时间替换logstash的时间戳
date {
match => ["logtime", "yyyy-MM-dd HH:mm:ss.SSS"]
target => "@timestamp"
}
}
}
output {
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "filebeat-logstash-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}
grok过滤的message对应的五种日志形式示例:
2020-03-04 13:25:27.488 [http-nio-9000-exec-11] INFO com.xxx.classpath - oper log b peron login 231148
2020-03-04 14:19:34.428 [http-nio-9000-exec-8] INFO com.xxx.classpath - REQUEST DATA : uri=/url;client=10.13.180.91];&&&®ion=TW%platform=2%version=unknown%mobileModel=unknown%osVersion=unknown%connectType=unknown%uuid=unknown&&&&;耗时:6ms
2020-03-07 08:09:51.890 [http-nio-9000-exec-3] INFO com.xxx.classpath - REQUEST DATA : uri=/url?offset=10&playerUserUuid=231002;client=10.13.180.36];&&&®ion=unknown%platform=1%version=unknown%mobileModel=unknown%osVersion=unknown%connectType=unknown%uuid=unknown&&&&;耗时:126ms
2020-03-02 09:55:28.196 [http-nio-9000-exec-4] INFO com.xxx.classpath - REQUEST DATA : uri=/url;client=10.13.180.91;payload={“ticket”:“xxx”}];&&&®ion=TW%platform=3%version=unknown%mobileModel=unknown%osVersion=unknown%connectType=unknown%uuid=unknown&&&&;耗时:45ms
2020-03-03 03:05:33.634 INFO 13175[io-9000-exec-12] com.xxx.classpath : oper log c peron login 254264
记得要映射logstash.yml中的两个路径。
docker run --restart=always --log-driver json-file --log-opt max-size=100m --log-opt max-file=2 -it -d -p 5044:5044 --name logstash --net somenetwork -v /home/ec2-user/docker_config/logstash/logstash.yml:/usr/share/logstash/config/logstash.yml -v /home/ec2-user/docker_config/logstash/conf.d/:/home/ec2-user/docker_config/logstash/conf.d/ -v /home/ec2-user/docker_logs/logstash:/var/log/logstash logstash:7.5.1
查看容器运行状态
docker ps
写logstash配置,grok插件是必须要学会的。关于grok插件的讲解,可以查看笔者的另一篇博客《轻松掌握Logstash的grok插件》
安装Kibana
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用Kibana搜索、查看、交互存放在Elasticsearch索引里的数据,使用各种不同的图表、表格、地图等Kibana能够很轻易地展示高级数据分析与可视化。
# 在本例中,Kibana使用默认配置
# 运行 Kibana
docker run --restart=always --log-driver json-file --log-opt max-size=100m --log-opt max-file=2 -d --name kibana --net somenetwork -p 5601:5601 kibana:7.5.1
# 查看容器启动状态
docker ps
安装Filebeat
Filebeat是本地文件的日志数据采集器,可监控日志目录或特定日志文件,并将它们转发给Elasticsearch或Logstatsh进行索引、Kafka等。带有内部模块(Apache,Nginx,System和MySQL等),可通过一个指定命令来简化通用日志格式的收集,解析和可视化。
filebeat.yml配置,更多配置选项可以查看官网,简洁明了,点我跳转
filebeat.inputs:
- type: log
enabled: true
# 需要收集的日志所在的位置,可使用通配符进行配置
paths:
- /home/ec2-user/jenkins/logs/server-api/*.log
# 这个文件记录日志读取的位置,如果容器重启,可以从记录的位置开始取日志
registry_file: /home/ec2-user/docker_config/filebeat_registry
# 为每个项目标识,或者分组,可区分不同格式的日志
tags: ["java-logs"]
exclude_lines: ['.*uri=/basic/time/current;.*']
# 日志输出配置
output.logstash:
# 内网B机器的ip:port
hosts: ['10.13.180.42:5044']
enabled: true
docker运行filebeat,映射需要的配置文件
docker run --restart=always --log-driver json-file --log-opt max-size=100m --log-opt max-file=2 --name filebeat -d -v /home/ec2-user/docker_config/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml -v /home/ec2-user/jenkins/logs/server-api/:/home/ec2-user/jenkins/logs/server-api/ -v /home/ec2-user/filebeat_collect/:/home/ec2-user/filebeat_collect/ -v /home/ec2-user/docker_config/filebeat_registry:/home/ec2-user/docker_config/filebeat_registry docker.io/store/elastic/filebeat:7.5.1
启动Kibana查看数据
如果没有配置Kibana所在服务器域名的话,可以浏览器访问"ip:5601"来访问,不过值得注意的是Kibana自身没有安全限制,一般采用网关鉴权限制或者第三方安全插件,可以谷歌搜索下。
进入Kibana,点击下面Discover菜单。

作为初学者,直接输入"*",然后点击"next step"。先别理会是什么,看看数据建立初始成就感很重要。
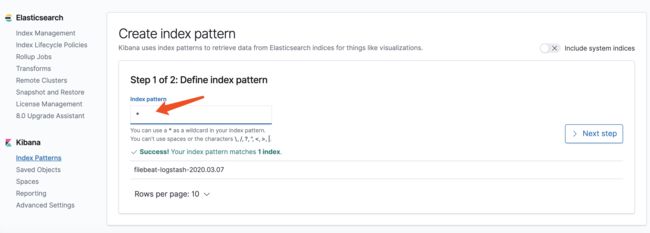
选择@timestamp作为时间坐标。点击"Create index pattern"。然后再次查看Discover菜单,就发现日志数据输出到kibana了。

Kibana常用功能说明:
- Discover 数据搜索查看
- Visualize 图标制作
- Dashboard 仪表盘制作
- Timelion (新版本在Visualize下)时序数据的高级可视化分析
- DevTools 开发者工具
- Management 配置
总结
本文采用最简单粗暴的docker命令行进行构建,更好的构建方式是采用docker compose方式,读者可以自行改写。
最后,限于笔者经验水平有限,欢迎读者就文中的观点提出宝贵的建议和意见。如果想获得更多的学习资源或者想和更多的是技术爱好者一起交流,可以关注我的公众号『全菜工程师小辉』后台回复关键词领取学习资料、进入后端技术交流群和程序员副业群。同时也可以加入程序员副业群Q群:735764906 一起交流。
