吃瓜笔记 | Momenta王晋玮:让深度学习更高效运行的两个视角
主讲人:王晋玮 | Momenta合伙人
屈鑫 编辑整理
量子位 出品 | 公众号 QbitAI
2月1日晚,量子位·吃瓜社联合Momenta带来吃瓜社第五期:让深度学习更高效运行的两个视角。
作为顶尖的自动驾驶公司,Momenta一直专注于打造自动驾驶大脑,基于深度学习的环境感知、高精度地图、驾驶决策技术,让无人驾驶成为可能。
本期主讲人王晋玮是特征点定位专家、深度学习模型加速专家、Momenta合伙人。他从优化计算量和访存量两个角度出发,提出缩短计算时间,加速完成推理任务的优化方法。
量子位应读者要求,将精彩内容整理如下:
class="video_iframe" data-vidtype="2" allowfullscreen="" frameborder="0" data-ratio="1.7647058823529411" data-w="480" scrolling="no" data-src="http://v.qq.com/iframe/player.html?vid=e0547ad6ccw&width=670&height=376.875&auto=0" style="display: none; width: 670px !important; height: 376.875px !important;" width="670" height="376.875" data-vh="376.875" data-vw="670"/>
△ 分享视频回放
基本背景
首先提一下需要了解的背景。
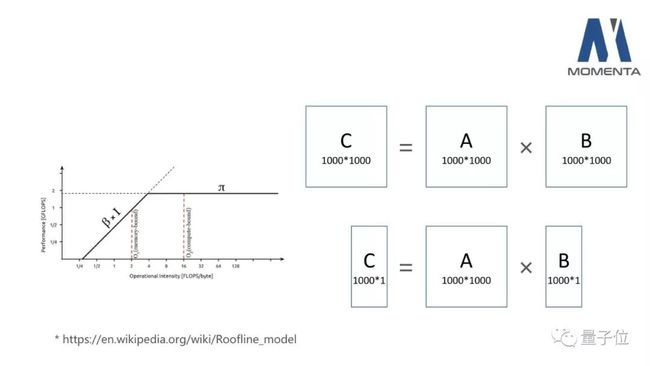
第一个是Roofline Model。这个Model是指计算机上的一个应用,它占用了两类最主要的资源:算术逻辑单元的计算资源,存储器的带宽资源。这里的计算资源以FLOPS来表示;带宽资源以byte/s表示。
Roofline model是说什么呢?横轴是Operational Intensity,就是计算的密度,单位是FLOPS/byte;纵轴是performance,也就是性能,单位是FLOPS。
图中有一条折线,这个折线开始的时候是随着计算密度的增加而增加,最终会稳定在一个固定的performance上。这个意思是:当这个应用程序的计算密度大于一定值之后,将会变成一个受算术逻辑单元的计算量所限制的程序;而这个计算密度如果小于一定值,将会变成一个受存储器带宽所限制的程序。
这里折线的拐点非常重要。这个拐点跟硬件很相关,它实际上表示的是硬件的理论计算能力和它的内存带宽之间的一个比值。
举两个具体的例子,第一个是矩阵乘矩阵,矩阵C等于A乘B,而A跟B分别是一千乘一千的矩阵。假设存储和计算都是用float 32位来表示,这样一个计算将会做1000乘1000乘1000的浮点乘加,也就是2G FLOPS的运算。我们要读取A和B,然后计算出来C,把它写回去,最少的存储器访问就是三个矩阵的大小,也就是12个MB。
另外一个是矩阵乘向量,也就是矩阵A乘向量B,等于向量C,这时候维度还是1000的情况下,它的计算量就是1000乘1000的浮点乘加,也就是2M。而存储器访问的话最少大约是1000乘于1000个浮点数,也就是4MB。
可以明显地看到上面乘矩阵的操作,它的计算量是2G,访存量是12M,那么它的这个计算量除以访存量,也就是刚刚提到的计算密度,大概是200左右。下面这个矩阵和向量中,它的计算量是2M,访存量是4M,那它的计算量除以访存量大约就只有0.5,显然这两个就是非常不同的程序。
上面矩阵乘矩阵,是一个典型的受计算量约束的程序;而下面矩阵乘向量则是一个典型的受存储器带宽所约束的程序。
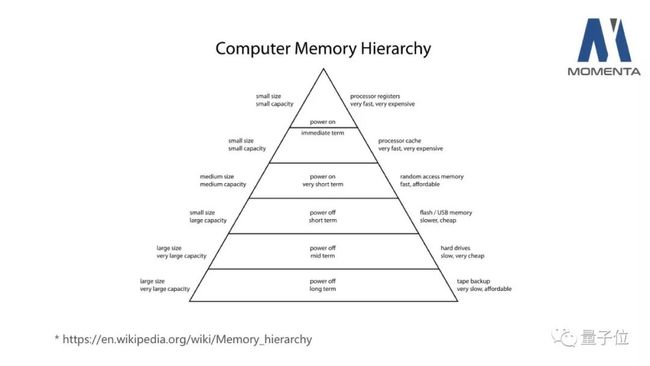
另外一个要介绍的背景是,计算机的存储器体系结构、存储器层次结构。
计算机中CPU的速度非常快,存储器通常跟不上它,所以为了让CPU能稳定地工作,存储器被划分为多个层级,最上层是最快,同时也最贵,也是容量最小的寄存器,它紧紧围绕在这个算术逻辑单元附近,可以被这个计算指令直接使用。
往下一层是缓存,它的容量比计算器大很多,但是速度大概慢一个量级,延时大概高一个量级。再往下是主存,也就是通常所说的内存,它一般是在处理器的芯片之外,容量就非常大,延迟可能会比这个CPU的主频要低100倍,甚至更多。我们主要关注上面三个:寄存器、缓存和主存。
 列举一些典型的可以用深度学习部署的一些硬件:英伟达的Tesla V100,是目前最强的计算卡,它可以提供120T的FLOPS的计算性能,基于TensorCore。提供HBM2作为主存,带宽是900GB/s,同时还有20MB的片上共享存储和16MB的片上缓存,一共36MB的片上存储。
列举一些典型的可以用深度学习部署的一些硬件:英伟达的Tesla V100,是目前最强的计算卡,它可以提供120T的FLOPS的计算性能,基于TensorCore。提供HBM2作为主存,带宽是900GB/s,同时还有20MB的片上共享存储和16MB的片上缓存,一共36MB的片上存储。
中间是英伟达的Xavier,是最近推出的SoC,它提供大概30T的计算性能,同时使用LPDDR4作为主存,带宽大概是137GB/s。
右边是一个典型的嵌入式设备:树莓派3,它采用普通的一款ARM芯片,运行在1.2G Hz,峰值计算能力是38.4G FLOPS。同时使用LPDDR2作为它的内存,带宽大约3.6GB/s,同时它还会有512KB的片上缓存。
对比这三个硬件,不管是计算性能,还是内存带宽,片上的缓存,它们都非常的悬殊。
两个视角:计算量和访存量
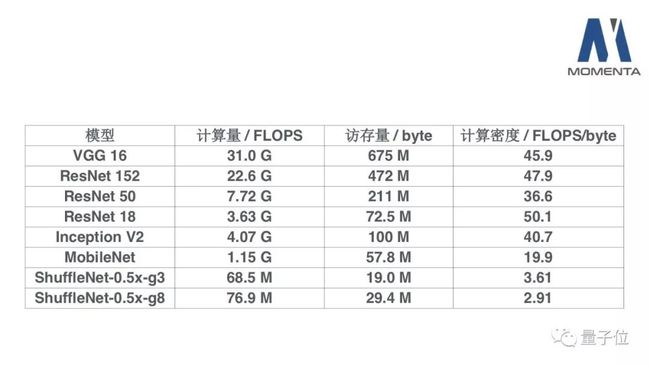
我们通过计算量和访存量来评判深度学习模型的性能。
计算量是我们非常熟知的一个性能,但通常对访存量关注比较少。事实上根据我们前面提到的,访存量的值会非常严重地影响模型的性能。为了简便计算,我们这里忽略缓存的存在,因为一般需要加速的产品都是嵌入式设备,这种设备上它的片上存储是相对较少的。
假定以Fp32作为计算和存储的单元,我们可以计算出模型的计算量和访存量,以及计算密度。这里计算访存量的规则是:对每一个Operator或者是layer,计算所有输入的Tensor、所有参数的Tensor,还有输出Tensor的总大小作为访存量。
表格里列出来的访存量,实际上是经过了一些优化之后的结果,并不是原始模型中的结果。后面会提到一些基本的优化操作。
先看这个表格中第四列的数值,也就是计算密度。一些大模型,比如VGG 16、ResNet,或者是Inception,他们的计算密度都非常大,都在30或者40或者50这个量级。事实上VGG 16的访存量中绝大部分是被最后巨大的全连接层占据了。如果去掉那个全连接,或者是像ResNet中,先做ROI pooling,然后再接全连接,这种形式的访存量会降到170M到180M,它的计算密度是非常大的。
而通常我们说的小模型,计算量虽然非常小,但它访存量却并没有显著地小于大模型,同时计算密度会显著变小。例如ShuffleNet 0.5x,它使用3个group形式时计算密度只有3.61,如果是8个group形式,也就是计算被拆得更散的情况下,它的计算密度只有2.91。
这就是说,小模型部署在这些硬件上,通常都是被存储带宽所限制住了,而不是被计算量所限制住。
后面以这两个视角作为出发,来看一些目前已经非常常见或者是用得非常好的一些深度学习模型的加速的手段。
Bottleneck
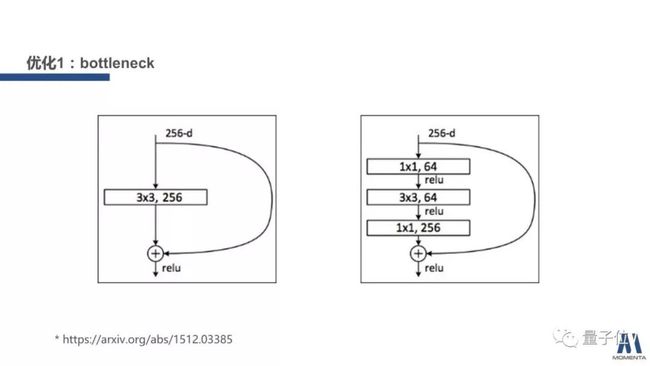 第一个方法是bottleneck。bottleneck这样的结构,在GoogLeNet系列的论文,以及ResNet论文里面都有提到,这里截取ResNet论文中的一张图作为例子。在ResNet里,我们只采用一个3×3的卷积,就会有256个channel的输入,然后输出256 channel,再跟自己做一个加和,过一个relu。
第一个方法是bottleneck。bottleneck这样的结构,在GoogLeNet系列的论文,以及ResNet论文里面都有提到,这里截取ResNet论文中的一张图作为例子。在ResNet里,我们只采用一个3×3的卷积,就会有256个channel的输入,然后输出256 channel,再跟自己做一个加和,过一个relu。
这样就能计算:假设feature map是56×56的情况下,左边的结构中,计算量大约是3.7G,访存量大约是8.8M。如果采用bottleneck结构,也就是把它拆成一个1×1的卷积,把channel数降低,再做3×3的卷积,然后通过1×1的卷积把channel数恢复回来。也就是右边这张图,它对应的计算量是大约0.43G,对应的访存量大约是9.9M。
所以经过这样一个操作之后,计算量被显著降低,将近有十倍之多。同时访存量却没有什么降低,反而上升了一些。
总结一下bottleneck这样的结构:大幅减少计算量,同时访存量不变,或者是小幅上升,所以计算密度会大幅下降。
从计算量的角度来看,它不失为一个优化模型的非常好的手段。
Depthwise卷积
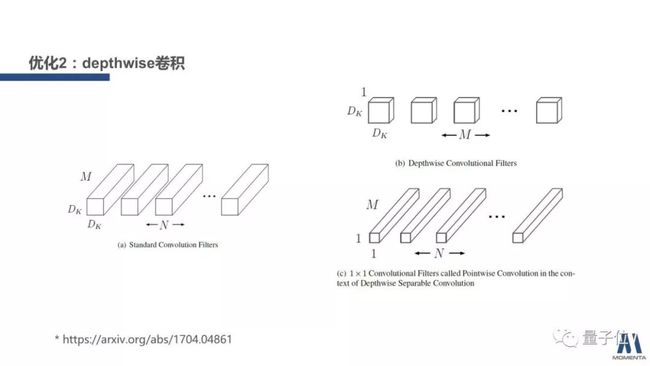 另外一个方法是depthwise卷积。
另外一个方法是depthwise卷积。
例如把一个3×3,若干个channel输出的卷积拆成两部分。第一部分是depthwise,它只做空间上的关联,在每一个channel上独立地进行卷积,就只有一个channel。第二部分是pointwise,只在不同channel之间做关联。经过这样的拆解后,同样会使计算量大幅减小,访存量小幅上升,所以计算密度大幅下降。
这两个结构为什么都会导致计算密度的下降呢?
计算密度从感性上来理解,就是加载一个数字,我们可以用它来进行多少次运算。举个简单的例子,假设采用3×3的卷积核,那当我们加载进输入的一个点,在一个输出的channel上它会进行9次运算(卷积核3×3)。但对于一个1×1的卷积来说,将9次运算减少到了1次。而对depthwise卷积来说,我们相当于将单次卷积的输出channel数减少到1。
再回过头来看刚刚这张表格。
刚才我们提到VGG16访存量主要是被最后的全连接所占据了,如果去掉它的话,我们把计算密度认为是160左右。由此可以看到VGG16的计算密度是显著高于其它几个,因为它的结构非常简单,它的内部都是3×3的卷积,属于这个计算密度最高的一种结构。
其它的一些模型,比如ResNet 152或者ResNet 50,因为它或多或少地引入了bottleneck,导致计算密度会有一些下降。ResNet18的里面没有bottleneck结构,或者bottleneck结构也是由3×3的卷积来完成的,所以它的计算密度相对比较高。Mobilenet和Shufflenet等等,它们里面根本就没有大规模3×3卷积,只有depthwise的3×3卷积和1×1卷积。
其实前面两种方法也都是非常优秀的方法,为什么说他们降低了计算密度,但也是很实用的方法?回到刚才我们提到的三个典型的硬件:Tesla V100、Xavier和树莓派。
在树莓派这样一个典型的嵌入式神经网络的场景下,需要小模型,同时它内存带宽资源又相对比较富裕(回想Roofline Model的折线拐点位置),相比于GPU而言,在这样的设备上还是有很大的价值。这样的操作其实本质上是用存储器的带宽资源去换取一些计算资源来提升模型性能。
FFT / Winograd的卷积算法
 然后我们来提下面一个优化:FFT / Winograd的卷积算法。这种方法跟前两种相比区别在哪?它是指通过某种线性变换将feature map和卷积核变换到另外一个域,空间域下的卷积在这个域下变为逐点相乘,再通过另一个线性变换将结果变换到空间域。FFT卷积采用傅里叶变换处理feature map和卷积核,傅里叶逆变换处理结果;Winograd卷积使用了其他的线性变换。
然后我们来提下面一个优化:FFT / Winograd的卷积算法。这种方法跟前两种相比区别在哪?它是指通过某种线性变换将feature map和卷积核变换到另外一个域,空间域下的卷积在这个域下变为逐点相乘,再通过另一个线性变换将结果变换到空间域。FFT卷积采用傅里叶变换处理feature map和卷积核,傅里叶逆变换处理结果;Winograd卷积使用了其他的线性变换。
具体而言FFT将空间意义上的实数变换到频域上的复数,最后在复数上做逐点相乘,然后再把这个频率的复数变化为这个空间域的实数。
Winograd则是一直在实数域上进行变换。事实上由于FFT需要复数乘法,如果没有特殊指令支持的话需要用实数乘法来模拟,实数的浮点计算量可能下降的不多。因此FFT也没有Winograd实用。
从计算量和访存量的角度来分析Winograd/FFT变换的卷积算法。它在实际上会大幅减少计算量,计算量减少的值是由这个图像分块大小决定的。同时对访存量的影响和cache容量有关,如果实现得好,不会大幅提高访存量,但会有一定程度的精度损失。
FFT/Winograd的变换,它本质上是一个由精度换取速度的方法。
总结一下FFT和Winograd变化,它实际上是可以实现极高的一个加速比,举个例子,Winograd变换对于3×3卷积,最高可以实现9倍的加速比,但精度损失严重。当然我们实际上不会用那么大,可能会用到6倍,那么这时候精度损失还是可以接受的。
其他方法
简单列举一些其他方法。
 第一个是稀疏化。它的缺点是工程实现较难,需要fine tune,不易于解耦模型研究和部署加速。另外稀疏矩阵运算的实际效率往往也不高。
第一个是稀疏化。它的缺点是工程实现较难,需要fine tune,不易于解耦模型研究和部署加速。另外稀疏矩阵运算的实际效率往往也不高。
那么在工程上如何解决呢?通过结构化稀疏,通过一些方式保证稀疏矩阵中0以一定的规律出现,例如同一列、同一行、某些块等,尽量提高稀疏矩阵运算的效果。
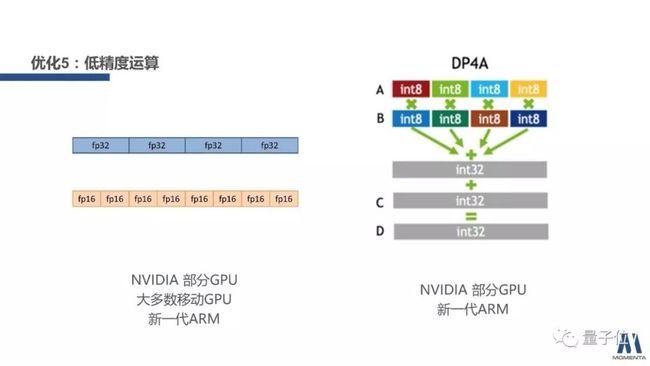 另外一个是低精度运算。低精度运算具体而言就是使用更低位宽,实现成倍降低的访存量,同时使部分处理器上性能成倍提高。
另外一个是低精度运算。低精度运算具体而言就是使用更低位宽,实现成倍降低的访存量,同时使部分处理器上性能成倍提高。
举个例子,fp16相比fp32,一半的位宽,几乎没有精度损失;Int8相比fp32,1/4的位宽,采用正确的方式进行量化后也几乎没有精度损失。缺点是目前支持的硬件不多,新一代的ARM处理器和部分英伟达的GPU支持。
Graph层面
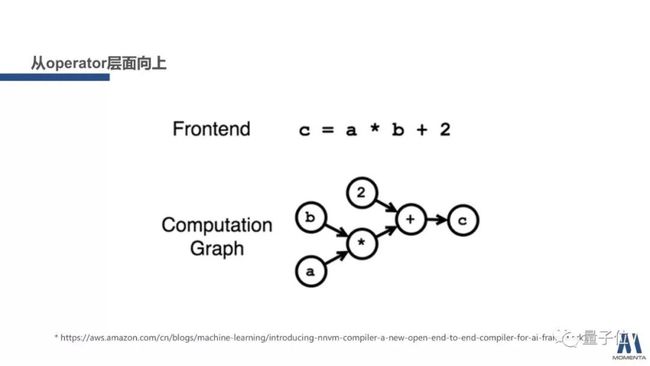
前面都在说operator层面。
现在从operator层面往上走,来到graph的层面,引入计算图的概念:computation graph。具体而言,计算图是什么?就是以某种语言来表述一个计算的过程,比如说上面这个C等于A乘B加二,会对应一个计算图,这个计算图明确给出了计算过程中的数据流向和依赖关系。
首先介绍一下NNVM Compiler,它是由mxnet的作者们提出的一个神经网络的一个中间表示。它包括两部分:NNVM和TVM。NNVM主要做的是graph层面的表示,它通过表示节点和节点之间的连接关系,把Operator连接成一个computation graph,再通过TVM来优化每一个节点,来生成最终可执行的代码。
另外一个非常有价值的工作,是英伟达推出的TensorRT,TensorRT是专门针对英伟达GPU的神经网络部署工具。在TensorRT中能做非常多,并且能够进行非常好的Operator和Tensor的融合操作。非常感谢NNVM和TensorRT这两个已有的成果,为Momenta做后面的研发提供了非常非常宝贵的借鉴参考价值。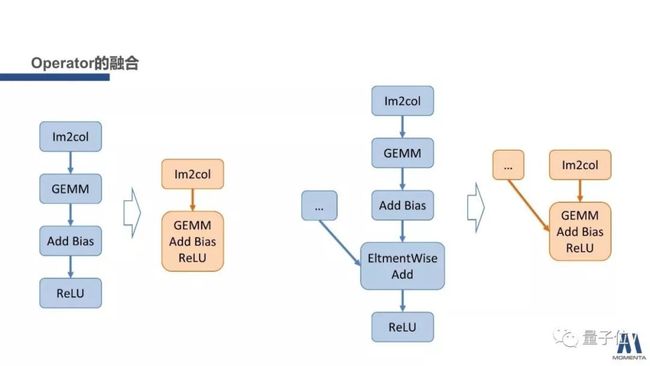
再往下看,从Operator层面向上看到graph这个层面,我们能做什么事情。相比于前面的bottleneck、depthwise卷积这些优化手段,Operator层面以上,也就是graph能做的事情就比较有意思。
举个例子,最左边这个蓝色的连接关系是caffe中非常常见的计算过程:计算一个卷积,并且在后面加一个ReLU的操作。经过分析可以发现,加Bias和ReLU这两个操作都是逐点进行的。我们完全可以修改这个矩阵乘的代码,在矩阵乘算完一个结果之后,顺便加bias,并做一个ReLU。可以把矩阵乘和Bias和ReLU三个操作合并为一个操作。
还有很多可以进行的融合操作,BN或scale和conv的融合,shuffle channel和depthwise conv的融合、Momenta提出的SENet中Excitation和conv的融合、通过合理分配存储地址消除concat和slice等
为什么我们要做这个Operator的融合?因为能够减少从低层memory向高层memory的搬运。例如relu向gemm的融合,如果不融合,计算gemm和relu时都至少需要将数据从cache搬入register,再搬回cache。而融合的话,只需要搬入register再搬回cache一次即可。搬运数据的指令和延迟都是可以节约的开销。
Operator的粒度
 另外一个想讨论的概念是Operator的粒度。粒度是一个非常值得讨论的问题,首先定义下什么是粒度:一个operator完成多复杂的任务。
另外一个想讨论的概念是Operator的粒度。粒度是一个非常值得讨论的问题,首先定义下什么是粒度:一个operator完成多复杂的任务。
举个例子,左边那个蓝色的是一个粗粒度的计算图,先做了一个包含channel在里面的一个Pooling,然后再做一个channel在里面的Depthwise的卷积。蓝色是一个粗粒度的op的计算图,如果采用细粒度的op,它会被展开成右图的样子。展开成右图这个样子以后,会有很多优势。
首先这个计算图会变得更复杂,同时每一个operator的粒度会更细,这也意味着你暴露给了这个计算图的优化器更多的细节,这样的这个计算图优化器就会有更多的优化余地。例如右边,通过合理选择op执行顺序,可以尽量避免pooling和depthwise conv之间对主存的访问,降低内存带宽压力。
上一个例子不那么合适,但是比较直观。举另外一个例子:我们在一个卷积后面接一个卷积,这时候仍然可以把这个卷积的粒度拆的更细,但是这次我们不在channel这个维度拆细,而在空间这个维度上把它拆细。
我们可以通过把卷积2的输出在空间上分片。比方说卷积2最后输出了一个16乘16的feature map,然后我们把它拆成四个8乘8的feature map作为输出。
通过这样的一个拆分,可以把粗粒度的卷积变成右边这样一个形式,它们有多个,就是空间上的这样一个分块,每一个分块计算最终的结果,跟前面的例子是一样的。Conv1Tile1和Conv2Tile1,Conv1Tile2和Conv2Tile2,它们的数据交换是远小于前面Conv1和Conv2之间的数据交换。毕竟空间维度更小,也就是缓存可能就可以把它放进去了,就意味着少了数据交换。
我们付出的代价是说Conv1的tile可能有重叠,导致额外的计算。同时这种情况下细粒度可能带来了计算效率的下降。但同样,op和op之间往来的数据变少,可以尽量完全使用cache而避免访问主存,降低内存带宽压力。
所以对于Operator粒度来说,并不是说粒度粗就一定好,或者粒度细就一定好,也是从计算量和访存量两个角度,同时在影响深度学习的性能。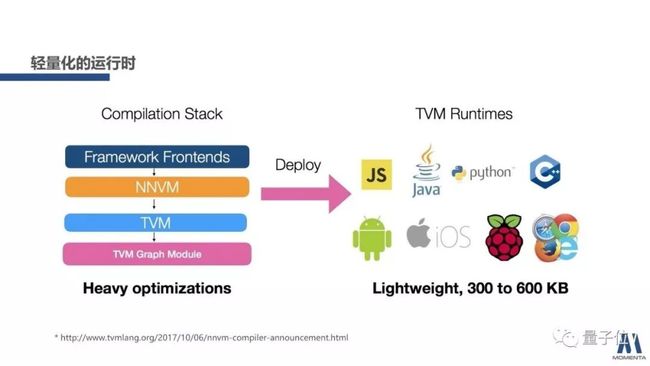
另外一个值得提的概念是轻量化的运行时。不管是TensorFlow或者是NNVM,它们都有轻量化的一个形式。拿NNVM来举例,可以看到前面提到的优化的过程,比如说我拿到了一个粗粒度的表示,那我决定要不要把它拆分成细粒度?可以通过一些启发式的方法,拆或不拆都测一遍,看看哪个性能更高。
优化的过程其实是一个蛮费劲的过程,它会比较复杂,但事实上如果我们拿到的是一个静态的计算图,graph以及operator的优化过程和输入数据无关,所以完全可以将优化过程从模型的执行器(运行时)中抽离出来,作为一个独立的部分。经过复杂的优化过程,计算图上每个节点跟原来可能都不一样,但是它的执行性能确实比原来更好。
那轻量化的运行时是有什么好处?运行时仅需提供用到的operator,不需要负责优化工作,因此可以做到非常轻量,同时优化后可能变得复杂的计算图也不会引入过多的开销。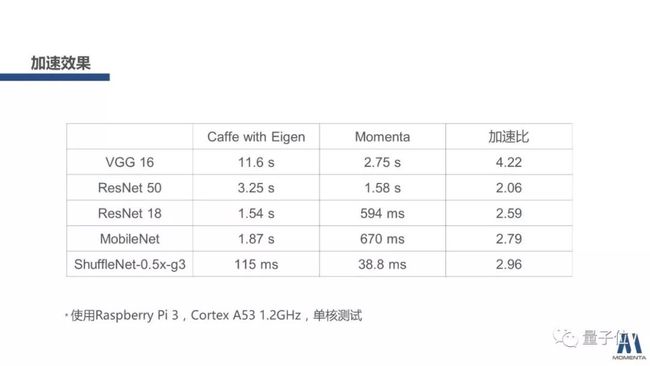
最后列举一下,Momenta通过前面提到的这些方法,做出来的一些加速的效果,这里用树莓派3作为测试,配置cortex A53,1.2G Hz,所有的测试都是在一个CPU核心上完成的。
总结

总结一下前面提到的深度学习模型性能运算优化。
我们提供两个视角:除了大家普遍采用的计算量的角度以外,另一个是访存量的视角。可以通过网络结构设计优化计算量,比如说bottleneck、depthwise的卷积。也可以通过Winograd、稀疏化、低精度运算等优化计算量。但是其中的低精度运算并不是优化了计算量,而是优化了设备能提供的计算量的上限,同时也可以通过低精度运算、计算图优化等手段来优化访存量。
最后一点是可以通过轻量化运行时来避免一些额外的开销,比如在部署的时候,避免编译优化这样一个比较复杂的模型的开销。
Q&A
访存量如何进行估算?
前面提到访存量的估算是要计算每一个layer,每个layer访存量是它的输入的数量,输出的数量和权重的数量总和。估算的话,可能跟真实的访存量差异较大,确实是这样。
我们在这里提到的计算过程是忽略了缓存的存在的,这样做的原因是,在通常我们需要比较严格的优化深度学习性能的一些平台,比如嵌入式平台,比如前面提到的树莓派,它一共有512K的片上的存储,同时四个CPU核心,如果只用一个CPU核心的话,那意味着只能占用128K的缓存,如果多占了那么其他核心就会遭殃了,那么128K缓存可以存什么呢?一个256 channel的一个feature map,然后浮点数存储,那一共就只能存128个点,这其实非常非常少的。
所以说通常在嵌入式这个场景下,大多数情况下它片上缓存是不够用。所以我们这里采用了一个忽略掉片上缓存的一个方法,因为片上访存一旦不够用,那意味着就是你下次读取的时候上一次已经被挤出去了,所以实际上是一直在读取主存的过程。另外忽略这片上缓存也有这样一个目的:估算方便。我们其实提到了很多利用片上缓存来进行访存量优化的过程。到那个时候,其实估算就不能再这样进行了。
有一些开源库,我们还需要关注这些优化吗?
事实上是这样,比方说我前面提到的这些优化,比方说这个计算图级别优化,其实NNVM做了一些,但是他并没有做到极致,还有很多我们认为可优化的地方,它其实里面并没有提供。当然NNVM可能只是为了建立一个这样的平台,让大家去贡献代码,做这样一个开源社区的概念。当然就是说如果要追求极致性能的话,有时候还是需要关注这样的一个优化的手段。
为什么还要自己做优化的原因就是,开源的框架和工具提供了很好的概念和借鉴意义,概念其实是相通的,但是我们自己的实现通常会更好一些。毕竟在业界追求极致的性能有时候还是有必要的。
Operator融合的方法可以在caffe或者TensorFlow的框架层面做吗?
caffe的话我就不推荐了,如果要做operator融合,是需要这个框架本身就是以计算图为基础搭建出来的,而caffe并不是。caffe把operator按执行顺序排成数组,相当于是计算图的拓扑排序后的结果。在这种框架上做operator融合,是非常费劲的,需要恢复成计算图来分析数据依赖关系。TensorFlow本身它是一个计算计算图的框架,当然可以做这样的事情,但是TensorFlow本身也提出了一个底层:XLA。这个XLA它其实也在做类似的事情。其实也就是说TensorFlow本身其实是提供了一些类似的操作。
相关学习资源
以上就是此次Momenta关于深度学习模型加速分享的全部内容。在量子位公众号(QbitAI)界面回复“180208”可获得完整版PPT以及视频回放链接。
Momenta正在招人
Momenta 2018年新年招聘季已开启,戳“阅读原文”了解热招岗位详情。
— 完 —
加入社群
量子位AI社群13群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot5入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot5,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态