跬步千里 —— 阿里云Redis bitfield命令加速记
link:https://developer.aliyun.com/article/757841
在一次阿里云客户问题解决中,通过给Redis添加bitfield_ro命令,解决了Redis官方bitfield命令无法加速执行的问题,实现高性能访问并向客户交付了满意的答卷。本文详细描述了阿里云是怎么通过挖掘产品中每一点细小的功能改进和使用体验,并持续地反馈社区的全过程的记录。
1. 问题
阿里云某客户发现自己使用读写分离实例,master的cpu特别高,而读写分离中承担读流量的slave节点却相对空闲。用户CPU打满后,访问到主节点的的线上服务受到了较大影响。
1.1 读写分离原理
Redis读写分离实例的原理是:key统一写入到master,然后通过主从复制同步到slave,用户的请求通过proxy做判断,如果是写请求,转发到master;如果是读请求,分散转发到slave,这种架构适合读请求数量远大于写请求数量的业务,读写分离架构示意图如下所示。
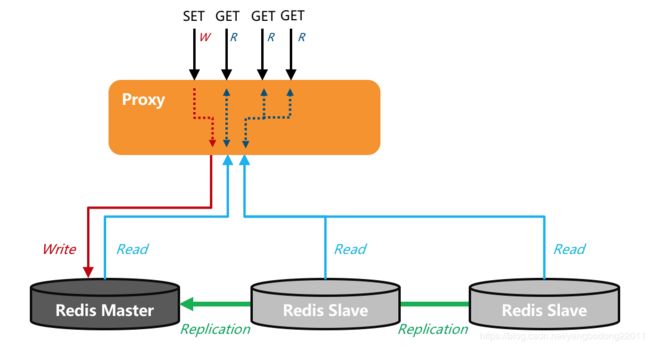
图1. 阿里云Redis读写分离版读写命令转发示例
1.2 bitfield命令
经过和客户沟通查看后,客户使用了大量的bitfield做读取,首先介绍一下这个命令的用法和场景,bitfield 是针对bitmap数据类型操作的命令,bitmap通常被用来在极小空间消耗下通过位的运算(AND/OR/XOR/NOT)实现对状态的判断,常见的使用场景例如:
- 通过bitmap来记录用户每天应用登录状态,即如果$ID用户登录,就SETBIT logins:20200404 I D 1 , 表 示 用 户 ID 1,表示用户 ID1,表示用户ID在20200404这一天登录了,通过BITCOUNT logins:20200404可以得到这一天所有登录过的用户数量;通过对两天的记录求AND,可以判断哪个用户连续两天登录了,即BITOP AND logins:20200404-05 logins:20200404 logins:20200404。
- 判断用户是否阅读了共同的文章,观看了共同的视频等。
- 前一阵子,答题领奖活动非常火爆,“答对12道题的同学有机会瓜分奖池”,这种如果使用bitmap来实现,就非常容易判断出用户是否全部答对。
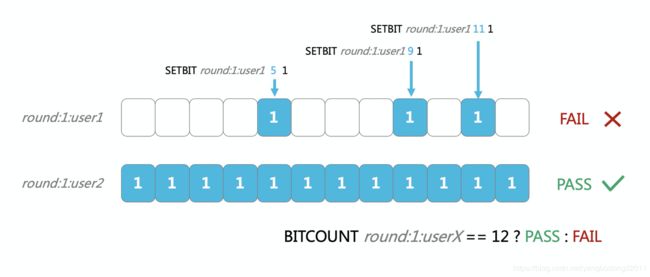
图2. 一个使用Redis BITMAP设计的答题游戏系统
答题系统设计如:
- 每个用户每轮答题,设置一个key,比如user1在第一轮答题的key是 round:1:user1
- 每答对一道题,设置相关的bit为1,比如user1答对了第5题,那么就设置第5个bit为1就可以了,如: SETBIT round:1:user1 5 1 ;如果用户1在第一轮答对了第9题,那么就把第9个bit设置为1,SETBIT round:1:user1 9 1;值得注意的是,bitfield默认bit都是0,答错可以不设置
- 计算用户总共答对了几道题,就可以使用 BITCOUNT 命令统计1的bit个数。如user1答对了3道题,user2在第一轮全部答对,那么user2就有机会参与答题(第1轮)的后续玩法
可见,Redis的bitmap接口可以用非常高的存储效率和计算加速效果。回到bitfiled命令,它的语法如下所示:
BITFIELD key
[GET type offset] // 获取指定位的值
[SET type offset value] // 设置指定位的值
[INCRBY type offset increment] // 增加指定位的值
[OVERFLOW WRAP|SAT|FAIL] // 控制INCR的界限
1.3 读写分离实例处理bitfield的问题
从上文可知,bitfield的子命令中,GET命令是读属性,SET/INCRBY命令为写属性,因此Redis将其归类为写属性,从而只能被转发到master实例,如下图所示为bitfield的路由情况。

图3. 处理BITFIELD命令的问题
这就是为什么客户使用了读写分离版,而只有master节点cpu使用高,其余slave节点却没有收到这个命令的打散的原因。
2 思路和处理
2.1 解决方案
- 方案一:改造Redis内核,将bitfield命令属性标记为读属性,但是当其包含SET/INCRBY等写属性的子命令时候,仍旧将其同步到slave等。此方案优点是外部组件(proxy和客户端)不需要做修改,缺点是需要对bitfiled命令做特殊处理,破坏引擎命令统一处理的一致性。
- 方案二:增加bitfield_ro命令,类似于georadius_ro命令,用来只支持get选项,从而作为读属性,这样就避免了slave无法读取的问题。此方案优点是方案清晰可靠,缺点是需要proxy和客户端做适配才能使用。
经过讨论,最终采取了方案二,因为这个方案更优雅,也更标准化。
2.2 添加bitfield_ro
{"bitfield_ro",bitfieldroCommand,-2,
"read-only fast @bitmap",
0,NULL,1,1,1,0,0,0},
完成之后,下图是在slave上执行bitfield_ro命令,可以看到被正确执行。
tair-redis > SLAVEOF 127.0.0.1 6379
OK
tair-redis > set k v
(error) READONLY You can't write against a read only replica.
tair-redis > BITFIELD mykey GET u4 0
(error) READONLY You can't write against a read only replica.
tair-redis > BITFIELD_RO mykey GET u4 0
1) (integer) 0
2.3 Proxy转发
为了保持用户不做代码修改,我们在proxy上对bitfiled命令做了兼容,即如果用户的bitfield命令只有get选项,proxy会将此命令转换为bitfield_ro分散转发到后端多个节点上,从而实现加速,用户不用做任何改造即可完成加速,如下图所示。
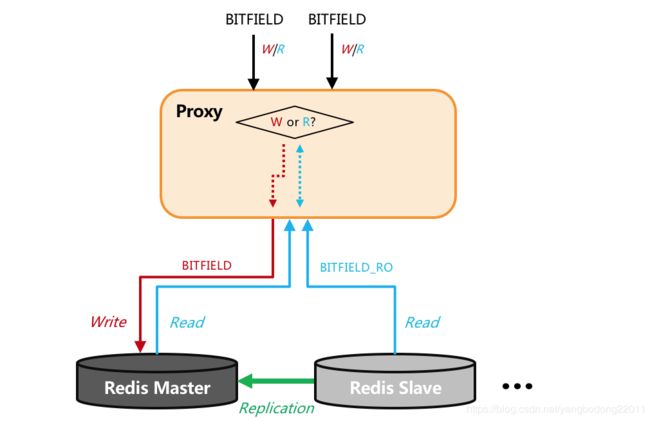
图4. 添加BITFIELD_RO命令后处理BITFIELD逻辑流程
2.4 贡献社区
我们将自己的修改回馈给了社区,并且被Redis官方接受(https://github.com/antirez/redis/pull/6951)

值得一提的是,阿里云在国内是最大的Redis社区contributer,如在新发布的Redis-6.0rc中,阿里云的贡献排第三,仅次于作者和Redis vendor(Redis Labs)。阿里云仍旧在不断的回馈和贡献社区。

图5. Redis6.0 RC commit数目榜
3. 引申和讨论
3.1 总结
阿里云Redis通过增加bitfield_ro命令,解决了官方bitfield get命令无法在slave上加速执行的问题。
除过bitfield命令,阿里云Redis也同时对georadius命令做了兼容转换,即在读写分离实例上,如果georadius/georadiusbymember命令没有store/storedist选项,将会被自动判断为读命令转发到slave加速执行。
3.2 思考
我们思考读写分离版的场景,为什么用户需要读写分离呢?为什么不是用集群版呢?我们做一下简单对比,比如设置社区版的服务能力为K,那么表的对比如下(我们只添加了增强版Tair的主备做对比,集群版可以直接乘以分片数):
| Redis社区版集群 | Redis社区版读写分离 | Redis(Tair增强版)主备 | |
|---|---|---|---|
| 写(key均匀情况) | K*分片数 | K | K*3 |
| 读(key均匀情况) | K*分片数 | K*只读节点数 | K*3 |
| 写(单key或热key) | K(最坏情况) | K | K*3 |
| 读(单key或热key) | K(最坏情况) | K*只读节点数 | K*3 |
表1. Redis社区版(集群/读写分离)和增强版(主备)简单场景对比
可见,其实读写分离版属于对单个key和热key的读能力的扩展的一种方法,比较适合中小用户有大key的情况,它无法解决用户的突发写的瓶颈,比如在这个场景下,如果用户的bitfield命令是写请求(子命令中带有INCRBY和SET),就会遇到无法解决的性能问题。
从表的对比看,这种情况下,用户如果能把key拆散,或者把大key拆成很多小key,就可以使用集群版获得良好的线性加速能力。大key带来的问题包含但不仅限于:
- 大key会造成数据倾斜,使得Redis的容量和服务能力不能线性扩展
- 大key意味着大概率这个key是热点
- 一旦不小心针对大key有range类的操作,会出现慢查询,还容易打爆带宽
这也是Tair增强版在阿里集团内各个应用建议的:“避免设计出大key和慢查,能避免90%以上的Redis问题”。
但是在实际使用中,用户仍旧不可避免的遇到热点问题,比如抢购,比如热剧,比如超大型直播间等;尤其是很多热点具备“突发性”的特点,事先并不知晓,冲击随时可达。Redis增强版的性能增强实例(https://help.aliyun.com/document_detail/145957.html)具备单key在O(1)操作40~45w ops的服务能力和极强的抗冲击能力,单机主备版就足够应对一场中大型的秒杀活动!同时如果用户没有大key,增强性能集群版能够近乎赋予用户千万甚至几千万OPS的服务能力,这也是Tair作为阿里重器,支持每次平稳渡过双11购物节秒杀的关键,欢迎大家试用!