深度学习的局部响应归一化LRN(Local Response Normalization)理解
1、其中LRN就是局部响应归一化:
这个技术主要是深度学习训练时的一种提高准确度的技术方法。其中caffe、tensorflow等里面是很常见的方法,其跟激活函数是有区别的,LRN一般是在激活、池化后进行的一中处理方法。
AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。AlexNet主要使用到的新技术点如下。
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
(3)在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
(4)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
其中LRN的详细介绍如下: (链接地址:tensorflow下的局部响应归一化函数tf.nn.lrn)
实验环境:windows 7,anaconda 3(Python 3.5),tensorflow(gpu/cpu)
函数:tf.nn.lrn(input,depth_radius=None,bias=None,alpha=None,beta=None,name=None)
函数解释援引自tensorflow官方文档
https://www.tensorflow.org/api_docs/python/tf/nn/local_response_normalization
The 4-D input tensor is treated as a 3-D array of 1-D vectors (along the last dimension), and each vector is normalized independently. Within a given vector, each component is divided by the weighted, squared sum of inputs within depth_radius. In detail,
sqr_sum[a, b, c, d] =
sum(input[a, b, c, d - depth_radius : d + depth_radius + 1] ** 2)
output = input / (bias + alpha * sqr_sum) ** beta
背景知识:
tensorflow官方文档中的tf.nn.lrn函数给出了局部响应归一化的论文出处
详见http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks
为什么要有局部响应归一化(Local Response Normalization)?
详见http://blog.csdn.net/hduxiejun/article/details/70570086
局部响应归一化原理是仿造生物学上活跃的神经元对相邻神经元的抑制现象(侧抑制),然后根据论文有公式如下
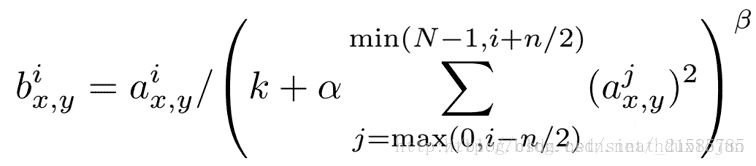
公式解释:
因为这个公式是出自CNN论文的,所以在解释这个公式之前读者应该了解什么是CNN,可以参见
http://blog.csdn.net/whiteinblue/article/details/25281459
http://blog.csdn.net/stdcoutzyx/article/details/41596663
http://www.jeyzhang.com/cnn-learning-notes-1.html
这个公式中的a表示卷积层(包括卷积操作和池化操作)后的输出结果,这个输出结果的结构是一个四维数组[batch,height,width,cha
nnel],这里可以简单解释一下,batch就是
批次数(每一批为一张图片),height就是图片高度,width就是图片宽度,channel就是通道数可以理解成一批图片中的某一个图片经
过卷积操作后输出的神经元个数(或是理解
成处理后的图片深度)。ai(x,y)表示在这个输出结构中的一个位置[a,b,c,d],可以理解成在某一张图中的某一个通道下的某个高度和某
个宽度位置的点,即第a张图的第d个通道下
的高度为b宽度为c的点。论文公式中的N表示通道数(channel)。a,n/2,k,α,β分别表示函数中的input,depth_radius,bias,alpha,beta,其
中n/2,k,α,β都是自定义的,特别注意一下∑叠加的方向是沿着通道方向的,即每个点值的平方和是沿着a中的第3维channel方向
的,也就是一个点同方向的前面n/2个通
道(最小为第0个通道)和后n/2个通道(最大为第d-1个通道)的点的平方和(共n+1个点)。而函数的英文注解中也说明了把input当
成是d个3维的矩阵,说白了就是把input的通道
数当作3维矩阵的个数,叠加的方向也是在
通道方向。
画个简单的示意图: 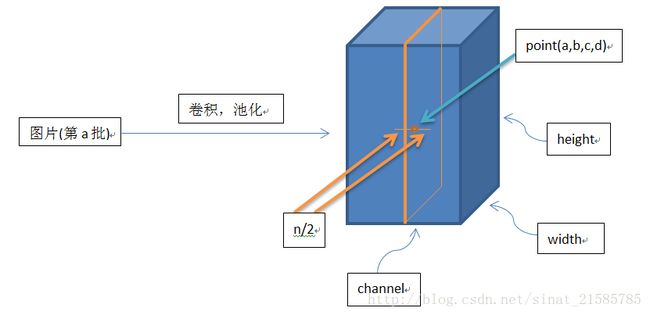
实验代码:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

结果解释:
这里要注意一下,如果把这个矩阵变成图片的格式是这样的 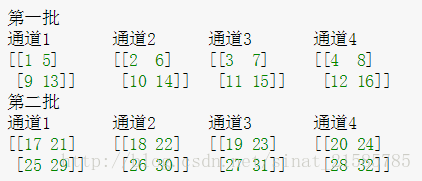
然后按照上面的叙述我们可以举个例子比如26对应的输出结果0.00923952计算如下
26/(0+1*(25^2+26^2+27^2+28^2))^1