ELK的学习
为什么用到ELK:
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:
-
收集-能够采集多种来源的日志数据
-
传输-能够稳定的把日志数据传输到中央系统
-
存储-如何存储日志数据
-
分析-可以支持 UI 分析
-
警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。
ELK简介:
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
官方文档:
Filebeat:
https://www.elastic.co/cn/products/beats/filebeat
https://www.elastic.co/guide/en/beats/filebeat/5.6/index.html
Logstash:
https://www.elastic.co/cn/products/logstash
https://www.elastic.co/guide/en/logstash/5.6/index.html
Kibana:
https://www.elastic.co/cn/products/kibana
https://www.elastic.co/guide/en/kibana/5.5/index.html
Elasticsearch:
https://www.elastic.co/cn/products/elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/index.html
elasticsearch中文社区:
https://elasticsearch.cn/
Beats 作为日志搜集器
这种架构引入 Beats 作为日志搜集器。目前 Beats 包括四种:
-
Packetbeat(搜集网络流量数据);
-
Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据);
-
Filebeat(搜集文件数据);
-
Winlogbeat(搜集 Windows 事件日志数据)。
Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户。
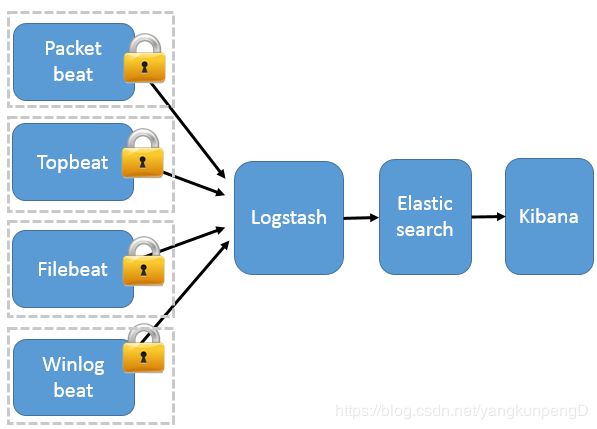
这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。
因此这种架构适合对数据安全性要求较高,同时各服务器性能比较敏感的场景。
FileBeat的工作方式:
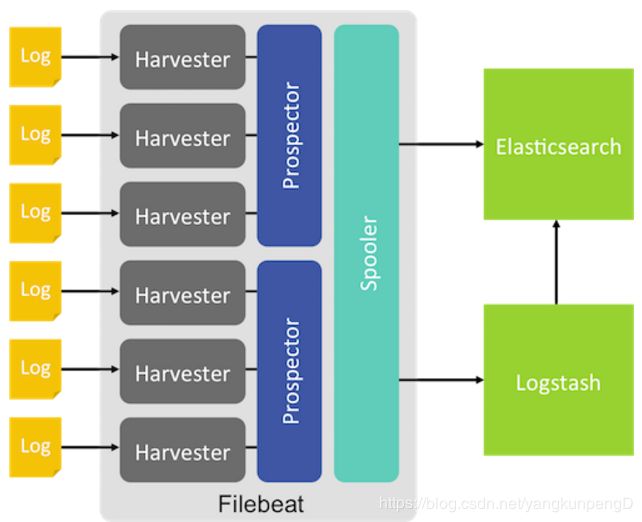
当FileBeat在服务器上启动后,它同时启动一个或者多个prospector来监视用户指定的日志文件目录。prospector然后针对每个日志文件,都启动一个harvester,每一个harvester监视一个文件的新增内容,并把新增内容送到spooler中。然后spooler来汇总这些events事件。然后把这些事件传送给logstash或者es。
Logstash工作流程
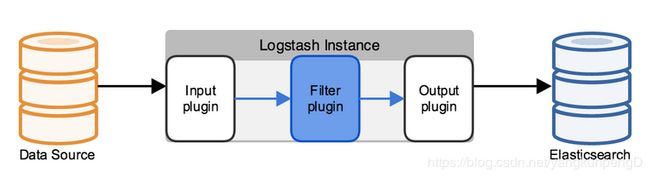
Logstash 工作的三个阶段:
Input 数据输入端,可以接收来自任何地方的源数据。
-
file:从文件中读取
-
syslog:监听在514端口的系统日志信息,并解析成RFC3164格式。
-
redis:从redis-server list 中获取
-
beat:接收来自Filebeat的事件
Filter 数据中转层,主要进行格式处理,数据类型转换、数据过滤、字段添加,修改等,常用的过滤器如下。
-
grok: 通过正则解析和结构化任何文本。Grok 目前是logstash最好的方式对非结构化日志数据解析成结构化和可查询化。logstash内置了120个匹配模式,满足大部分需求。
-
mutate: 在事件字段执行一般的转换。可以重命名、删除、替换和修改事件字段。
-
drop: 完全丢弃事件,如debug事件。
-
clone: 复制事件,可能添加或者删除字段。
-
geoip: 添加有关IP地址地理位置信息。
Output 是logstash工作的最后一个阶段,负责将数据输出到指定位置,兼容大多数应用,常用的有:
-
elasticsearch: 发送事件数据到 Elasticsearch,便于查询,分析,绘图。
-
file: 将事件数据写入到磁盘文件上。
-
mongodb:将事件数据发送至高性能NoSQL mongodb,便于永久存储,查询,分析,大数据分片。
-
redis:将数据发送至redis-server,常用于中间层暂时缓存。
-
graphite: 发送事件数据到graphite。http://graphite.wikidot.com/
-
statsd: 发送事件数据到 statsd。
filebeat安装
#下载及安装
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.5.4-amd64.deb
sudo dpkg -i filebeat_6.5.4_amd64.deb
#编辑配置信息
更改/etc/filebeat/filebeat.yml文件去设置连接信息
#启动
deb:
sudo /etc/init.d/filebeat start
直接tar.gz压缩包:
sudo ./filebeat -e -c filebeat.yml &
logstash安装
# 下载压缩包
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.5.4.tar.gz
# 解压
tar -zxvf logstash-6.5.4.tar.gz
# 启动
./bin/logstash -f xxxx.conf &
在后面加上&是以守护进程的方式启动
elasticsearch安装
# 下载压缩包
wget https://artifacts.elastic.co/downloads/downloads/elasticsearch/elasticsearch-6.5.4.tar.gz
# 解压
tar -zxvf elasticsearch-6.5.4.tar.gz
# 启动
su ES用户
./bin/elasticsearch -d
#测试 elasticsearch服务是否启动成功
localhost:9200
说明启动成功
#配置外网访问所遇到的问题
1.[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536] 意思是说你的进程不够用了
解决方案: 切到root 用户:进入到security目录下的limits.conf;执行命令 vim /etc/security/limits.conf 在文件的末尾添加下面的参数值:
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
前面的*符号必须带上,然后重新启动就可以了。执行完成后可以使用命令 ulimit -n 查看进程数
2.[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] 需要修改系统变量的最大值了
解决方案:切换到root用户修改配置sysctl.conf 增加配置值: vm.max_map_count=655360执行命令
sysctl p 这样就可以了,然后重新启动ES服务 就可以了
kibana安装
# 下载压缩包
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.5.4-linux-x86_64.tar.gz
# 解压
tar -zxvf kibana-6.5.4-linux-x86_64.tar.gz
# 启动
/bin/kibana &
注意:这时加上了&虽然执行了后台启动,但是还是有日志打印出来,使用ctrl+c可以退出。但是如果直接关闭了shell,这时服务也会停止,访问http://yourip:5601就失败了。
解决方法:
执行了/bin/kibana &命令后,不使用ctrl+c去退出日志,而是使用exit;这样即使关闭了shell窗口kibana服务也不会挂了。
#测试kibana服务是否启动成功
localhost:5601
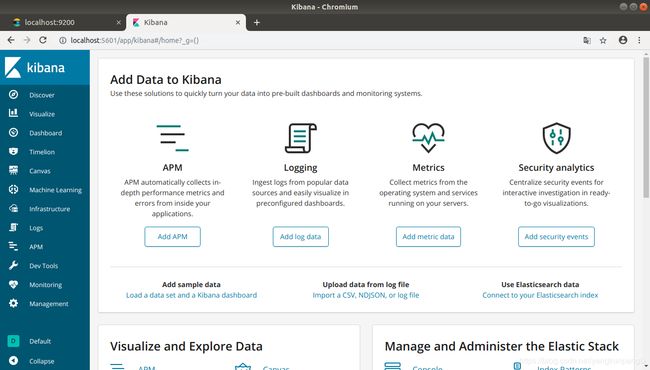
测试数据在ELK中的流通
目的:收集本机中geckodriver.log的日志在kibana中展示
首先配置filebeat监测日志的路径和分发到logstash
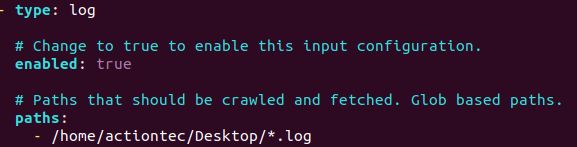

然后编写logstash的启动配置文件
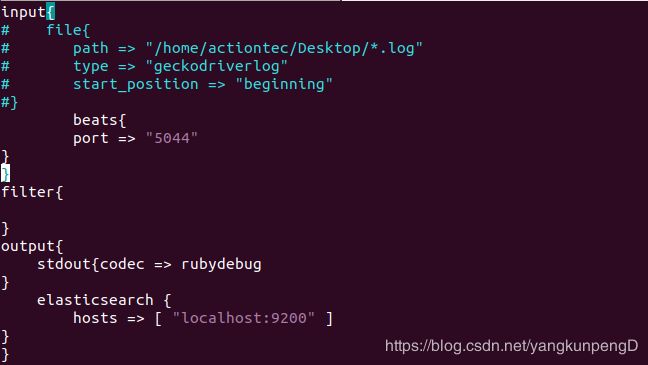
启动logstash去监听5044端口,启动elasticsearch服务,启动kibana服务,最后启动filebeat服务去监控日志文件。
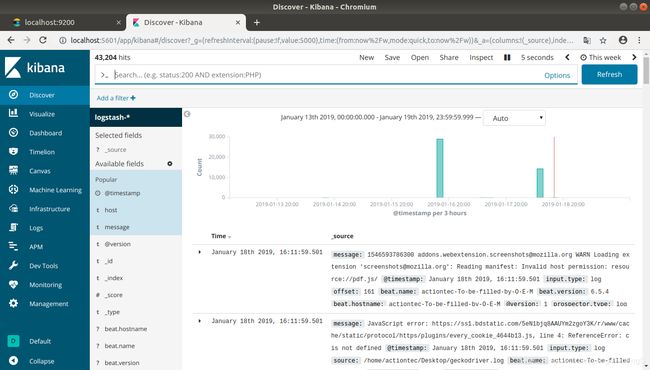
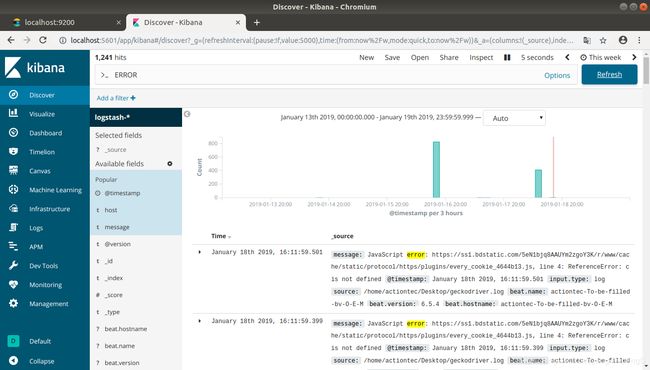
向geckodriver.log添加一条数据 echo "Hello world!">> geckodriver.log

kibana也增加了相应的一条信息。说明数据流通正常。
过滤出错误日志:
Logstash的filter模块
1、grok插件 grok插件有非常强大的功能,他能匹配一切数据,但是他的性能和对资源的损耗同样让人诟病。
filter{
grok{
#只说一个match属性,他的作用是从message 字段中吧时间给抠出来,并且赋值给另个一个字段logdate。
#首先要说明的是,所有文本数据都是在Logstash的message字段中中的,我们要在过滤器里操作的数据就是message。
#第二点需要明白的是grok插件是一个十分耗费资源的插件,这也是为什么我只打算讲解一个TIMESTAMP_ISO8601正则表达式的原因。
#第三点需要明白的是,grok有超级多的预装正则表达式,这里是没办法完全搞定的,也许你可以从这个大神的文章中找到你需要的表达式
#http://blog.csdn.net/liukuan73/article/details/52318243
#但是,我还是不建议使用它,因为他完全可以用别的插件代替,当然,对于时间这个属性来说,grok是非常便利的。
match => ['message','%{TIMESTAMP_ISO8601:logdate}']
}
}
2、mutate插件 mutate插件是用来处理数据的格式的,你可以选择处理你的时间格式,或者你想把一个字符串变为数字类型(当然需要合法),同样的你也可以返回去做。可以设置的转换类型 包括: "integer", "float" 和 "string"。
filter {
mutate {
#接收一个数组,其形式为value,type
#需要注意的是,你的数据在转型的时候要合法,你总是不能把一个‘abc’的字符串转换为123的。
convert => [
#把request_time的值装换为浮点型
"request_time", "float",
#costTime的值转换为整型
"costTime", "integer"
]
}
}3、ruby插件 官方对ruby插件的介绍是——无所不能。ruby插件可以使用任何的ruby语法,无论是逻辑判断,条件语句,循环语句,还是对字符串的操作,对EVENT对象的操作,都是极其得心应手的。
filter {
ruby {
#ruby插件有两个属性,一个init 还有一个code
#init属性是用来初始化字段的,你可以在这里初始化一个字段,无论是什么类型的都可以,这个字段只是在ruby{}作用域里面生效。
#这里我初始化了一个名为field的hash字段。可以在下面的coed属性里面使用。
init => [field={}]
#code属性使用两个引号进行标识,你的所有ruby语法都可以在里面进行。
#下面我对一段数据进行处理。
#首先,我需要在把message字段里面的值拿到,并且对值进行分割按照“|”。这样分割出来的是一个数组(ruby的字符创处理)。
#第二步,我需要循环数组判断其值是否是我需要的数据(ruby条件语法、循环结构)
#第三步,我需要吧我需要的字段添加进入EVEVT对象。
#第四步,选取一个值,进行MD5加密
#什么是event对象?event就是Logstash对象,你可以在ruby插件的code属性里面操作他,可以添加属性字段,可以删除,可以修改,同样可以进行树脂运算。
#进行MD5加密的时候,需要引入对应的包。
#最后把冗余的message字段去除。
code => "
array=event.get('message').split('|')
array.each do |value|
if value.include? 'MD5_VALUE'
then
require 'digest/md5'
md5=Digest::MD5.hexdigest(value)
event.set('md5',md5)
end
if value.include? 'DEFAULT_VALUE'
then
event.set('value',value)
end
end
remove_field=>"message"
"
}
}
4、date插件 这里需要合前面的grok插件剥离出来的值logdate配合使用(当然也许你不是用grok去做)。
filter{
date{
#还记得grok插件剥离出来的字段logdate吗?就是在这里使用的。你可以格式化为你需要的样子,至于是什么样子。就得你自己去看啦。
#为什什么要格式化?
#对于老数据来说这非常重要,应为你需要修改@timestamp字段的值,如果你不修改,你保存进ES的时间就是系统但前时间(+0时区)
#但你格式化以后,就可以通过target属性来指定到@timestamp,这样你的数据的时间就会是准确的,这对以你以后图表的建设来说万分重要。
#最后,logdate这个字段,已经没有任何价值了,所以我们顺手可以把这个字段从event对象中移除。
match=>["logdate","dd/MMM/yyyy:HH:mm:ss Z"]
target=>"@timestamp"
remove_field => 'logdate'
#还需要强调的是,@timestamp字段的值,你是不可以随便修改的,最好就按照你数据的某一个时间点来使用,
#如果是日志,就使用grok把时间抠出来,如果是数据库,就指定一个字段的值来格式化,比如说:"timeat", "%{TIMESTAMP_ISO8601:logdate}"
#timeat就是我的数据库的一个关于时间的字段。
#如果没有这个字段的话,千万不要试着去修改它。
}
}5、json插件,这个插件也是极其好用的一个插件,现在我们的日志信息,基本都是由固定的样式组成的,我们可以使用json插件对其进行解析,并且得到每个字段对应的值。
filter{
#source指定你的哪个值是json数据。
json {
source => "value"
}
#注意:如果你的json数据是多层的,那么解析出来的数据在多层结里是一个数组,你可以使用ruby语法对他进行操作,最终把所有数据都装换为平级的。
}
kibana查询语法
限定字段全文搜索:field:value
精确搜索:关键字加上双引号 filed:"value"
_exists_:http:返回结果中需要有http字段
_missing_: http:不能含有http字段
? 匹配单个字符
* 匹配0到多个字符
? * 不能用作第一个字符
模糊搜索
quikc~ brwn~ foks~
~:在一个单词后面加上~启用模糊搜索,可以搜到一些拼写错误的单词
first~ 这种也能匹配到 frist
还可以设置编辑距离(整数),指定需要多少相似度cromm~1 会匹配到 from 和 chrome
默认2,越大越接近搜索的原始值,设置为1基本能搜到80%拼写错误的单词
近似搜索
在短语后面加上~,可以搜到被隔开或顺序不同的单词"where select"~5 表示 select 和 where 中间可以隔着5个单词,可以搜到 select password from users where id=1
范围搜索
数值/时间/IP/字符串 类型的字段可以对某一范围进行查询length:[100 TO 200]
sip:["172.24.20.110" TO "172.24.20.140"]
date:{"now-6h" TO "now"}
tag:{b TO e} 搜索b到e中间的字符count:[10 TO *] * 表示一端不限制范围count:[1 TO 5} [ ] 表示端点数值包含在范围内,{ } 表示端点数值不包含在范围内,可以混合使用,此语句为1到5,包括1,不包括5可以简化成以下写法:age:>10
age:<=10
age:(>=10 AND <20)
优先级
quick^2 fox使用^使一个词语比另一个搜索优先级更高,默认为1,可以为0~1之间的浮点数,来降低优先级
逻辑操作
AND OR NOT
包含
+:搜索结果中必须包含此项-:不能含有此项+apache -jakarta test aaa bbb:结果中必须存在apache,不能有jakarta,剩余部分尽量都匹配到
分组(jakarta OR apache) AND jakarta
字段分组
title:(+return +"pink panther")host:(baidu OR qq OR google) AND host:(com OR cn)
转义特殊字符
+ - = && || > < ! ( ) { } [ ] ^ " ~ * ? : \ /
以上字符当作值搜索的时候需要用\转义\(1\+1\)\=2用来查询(1+1)=2