docker生态系统核心技术
前言:
容器生态系统包含核心技术、支持技术和平台技术
核心技术:
容器规范:通过定义规范保证了容器的可移植性和互操作性。
Runtime环境:为容器运行提供底层的运行环境。Docker默认的runtime是runc
容器管理工具:提供管理容器的API命令,例如Docker Engine
容器定义工具:镜像定义语法和容器定义语法,例如dockerfile
Registry:存放Images的仓库
容器OS:专门运行容器的操作系统。以前玩Docker都是在CentOS之类的Linux上玩的,其实还有专门运行容器的操作系统,更专业更轻量。
支持技术:
网络:解决方案来管理容器与容器,容器与其他实体之间的连通性和隔离性
服务发现:动态变化的微服务在做扩容或减容时如何让client能够访问容器提供的服务
监控:监督容器的状态
数据管理:对Docker挂载文件(磁盘)的管理,保证数据持久化与容器迁移。
日志管理:字面意思,重点在多宿主机集群拓扑下日志收集。
安全性:对容器镜像进行扫描,发现潜在安全漏洞
平台技术:
容器编排平台:包括容器管理、调度、集群定义、服务发现等。主流的编排引擎有docker swarm、 kubernetes、mesos
容器管理平台:架构在编排引擎上层的平台,抽象的一层,隐藏了底层对多种引擎的支持。
基于容器的Pass平台:直接使用的容器平台,使用户只关注产品开发,不用操心容器相关的东西。目前我还没有接触过类似的平台。
Docker基本已成为容器的代名词,所以我们对于容器的学习也是基于Docker开始的。我本身已经是一个Docker使用者,前面也有几篇介绍Docker的博文(从Docker的原理和安装开始),本次系统的学习容器是想查漏补缺,更加系统和深层的掌握容器。
----------------------------------------Docker镜像和容器-----------------------------------------------------------
Docker的Linux镜像为什么要比Linux系统镜像要小?甚至都不如mq、elk等一些组件那么大。

Linux操作系统是由内核空间和用户空间构成的。

对于Docker镜像来说,直接使用宿主机的Kernel部分,镜像本身只需要提供rootfs部分就可以了,而对于精简的LinuxOS镜像来说,只需要提供最基本的命令、工具和程序库就可以了,所以像docker的centos镜像就可以做的非常小。
但是这种设计也带来了一个弊端,那就是镜像对Kernel的调用需要受到宿主机Kernel的制约。例如如果容器对 kernel版本有要求(比如应用只能在某个 kernel 版本下运行),则不建议用容器,这种场景虚拟机可能更合适。
Docker容器使用的是分层结构,由最上面一层可写容器层与下面若干只读镜像层组成。
这样的分层结构最大的特性是 Copy-on-Write:
1 新数据会直接存放在最上面的容器层。
2 修改现有数据会先从镜像层将数据复制到容器层,修改后的数据直接保存在容器层中,镜像层保持不变。
3 如果多个层中有命名相同的文件,用户只能看到最上面那层中的文件。
分层结构使镜像和容器的创建、共享以及分发变得非常高效,而这些都要归功于 Docker storage driver。正是 storage driver实现了多层数据的堆叠并为用户提供一个单一的合并之后的统一视图,但实际应用中storage driver具体实现不需要我们操心,通过docker info可以看到storage driver的默认实现,Linux中默认的driver都是接受过测试和考验的,不建议修改。

可读写的Container层一旦容器重启会重置,所以对于mysql、redis等需要固化存储的容器需要通过volume的方式将宿主机存储mount到容器中。《Dockerfile命令和实践》中有过介绍。
以前使用Docker,一直认为Docker的Image的命名方式是“镜像名:版本号”,现在发现这种理解是错误的,正确的编排应该是Image的镜像名=“仓库名:Tag”。
仓库名Repository,代表镜像存放的位置;tag是人为设置的标签,只是我们约定俗成用V1、V2.0等方式来代表版本号。其中Repository分为共有仓库、私有仓库和本地;Tag默认是latest。repository的完整格式为:[registry-host]:[port]/[username]/xxx
只有 Docker Hub上的镜像可以省略 [registry-host]:[port]。
Repository公有仓库是Docker Hub,开放注册的,使用起来比较方便,但是也存在很多问题:
1公有仓库是开发的,产品的私密性和敏感内容得不到保护;
2由于在Internet上,上传下载的速率受限
作为企业级仓库,我们建议自己搭建一个私有的Repository
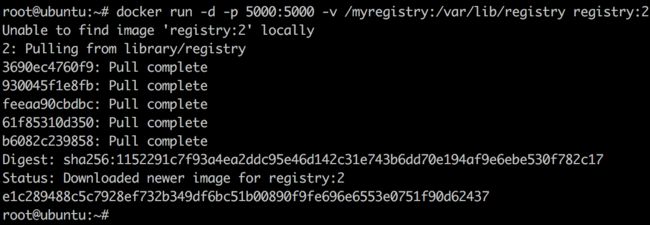
以前进入执行中的容器我只会通过docker exec命令,其实还有个docker attach命令也可以达到同样的效果。attach直接进入容器 启动命令 的终端,不会启动新的进程;exec则是在容器中打开新的终端,并且可以启动新的进程。当然如果只是想知道容器启动命令的输出,可以通过docker logs –f instance_name的方式,查看容器日志。
----------------------------------------Docker镜像和容器-----------------------------------------------------------
----------------------------------------Docker资源限制------------------------------------------------------------------
Docker容器资源限制:
Docker默认不会对容器所占资源进行限制的,宿主机有都少都可以被某一个容器全部霸占。
1内存限制:
$docker run –m 2048M ImageName
对某个镜像启动一个容器,物理内存大小限制为2G。我们都知道可用内存=物理内存+Swap缓冲区,Docker中默认Swap与物理内存大小相等,也就是说上面的容器最大可用内存为4G(2G+2G),如果限制Swap为1G,命令修改为
$docker run –m 2048M –memory-swap=3072MImageName
2 CPU限制
上面内存限制在容器中是相互独立并且隔离的,也就是说“独占”,而容器对于宿主机CPU的限制只发生在CPU资源竞争是按权重进行分配(也就是说不存在竞争的话,容器依然可以全享CPU资源)。
$docker run –name “A” –c 512 Image1
$docker run –name “B” –c 1024 Image2
以上两个容器,当宿主机CPU资源紧张时,A竞争到的CPU资源只有B的一半。当然如果B是休眠的,A仍然可以独享CPU。
3磁盘IO限制 Block IO
Docker对磁盘IO的限制,既有隔离上限制,也有共享上的竞争。
竞争:
--blkio-weight配置权重,与CPU的一样,也是竞争关系
限制:
--device-read-bps,限制读某个设备的 bps。
--device-write-bps,限制写某个设备的 bps。
--device-read-iops,限制读某个设备的 iops。
--device-write-iops,限制写某个设备的 iops。
----------------------------------------Docker资源限制------------------------------------------------------------------
----------------------------------------单宿主机网络和存储-----------------------------------------------------------
Docker的网络:
无论是虚拟化还是容器化,最复杂的部分都是网络部分,Docker中的网络分为两大部分:单宿主机网络和跨宿主机网络。
本章节先只介绍单宿主机网络:
单宿主机网络情况,在docker run启动容器时,可以通过--network=none这种方式指定容器的网卡。

none网络:字面意思,容器不带网卡,无法与外界通过网络交互。
host网络:宿主机内的容器直接共享宿主机的网络,容器的网络配置与宿主机完全一致。
bridge网络:默认的网络,容器创建时,docker会自动从 172.17.0.0/16 中分配一个 IP给容器,容器内网卡eth0通过veth pair与宿主机的docker0这个linux brigde相连。

PS:处在两个Bridge之间的容器是无法相互访问的,需要通过docker network connect BridgeName ContainerName/ID创建一个容器与bridge之间的虚拟网卡。

Docker内嵌了DNS Server,容器之间可以通过容器名替代IP进行相互通信。因为容器的IP对于容器之间来说没有任何意义,因为IP是在容器启动后才获取的(启动时虽然可以指定ip,但是我们不建议那么做),所以从业务编排的角度来讲容器名(相当于容器的host name)对上层应用更有意义。
Docker的存储:
以前使用Volume是将宿主机的文件或目录通过“-v宿主机path 容器path”的方式mount到容器内,这种方式使用起来虽然简单,但是可移植性并不好,每次使用都需要保证宿主机该目录或文件存在。
其实Docker还支持更简单的“-v容器path”的方式把宿主机文件mount到容器内,使用者无需关心宿主机具体的实现(本质是在宿主机/var/lib/docker/volumes/目录下),只需要告诉容器“我要固化存储”既可。
同一个宿主机下容器间如何共享存储的?第一个可以想到的方案是把宿主机上的一个路径mount到需要共享的容器内,这样这些容器就可以共享存储了。但这样同样带来业务编排上的难度,因为我们无法保证宿主机某路径一定是存在的。
我们可以用命令“docker create –name volume_name –v容器path”先创建一个磁盘容器,然后在需要共享该磁盘的docker容器启动时使用“—volumes-from volume_name”参数绑定磁盘。这样在业务编排时就不需要考虑宿主机目录是否存在的问题了。
----------------------------------------单宿主机网络和存储-----------------------------------------------------------
----------------------------------------Docker组群-----------------------------------------------------------------------
Docker Host 组群:
对单一Docker宿主机进行操作对于自己玩个Demo还是可以接受,但是生产级别的使用往往是需要很多个宿主机形成集群来使用的。这就需要引入Docker Machine来批量安装和配置。
Docker Machine支持Linux、OpenStack、VMWare、公有云等一切支持Docker的宿主机载体,对于每一类载体我们成为Provider,对于每一个载体我们成为machine,Docker Machine使用相应的driver安装和配置docker host(这一个与OpenStack的设计思想有异曲同工之妙)。
安装:
首先要在集群中选取一个作为Docker Machine的Server(也可以叫Master or Controller):
先在Server上安装好Docker Machine的控制端,Docker Machine的官方文档在https://docs.docker.com/machine/install-machine,控制端安装好后就可以通过Server来安装和配置其它Worker(也可以叫computeror slaver)了。
然后准备好Master、Slaver之间连接的工作:
创建machine要求能够无密码登陆远程主机,需要通过命令将ssh key拷贝到slaver上。
$ssh-copy-id slaver_ip
最后在Master上创建Slaver:
$docker-machine create –driver generic–generic-ip-address=slaver_ip slaverName
其中—driver这里根据slaver宿主机的provider来配置,宿主机如果是普通的LinuxOS,这里配置为generic。
slaverName是使用者自定义的宿主机的逻辑名称。
通过同样的方式可以添加N多的宿主机到Docker machine集群中来。
可以通过docker-machine ls来给集群阅兵

配置:
上面已经把Docker Machine的集群环境搭建好了,下面我们来看下如何来进行宿主机的配置和使用。
假设没有Docker Machine,我们操作每个宿主机都要通过ssh等远程登陆到宿主机,然后去执行创建容器等命令,有了Docker Machine后,我们只需要登陆到Master中,想操作哪个宿主机先切换到该宿主机的运行环境中,然后执行相应命令。
先执行eval $(docker-machine env host1)切换到host1这台worker的运行环境,然后后续所有的docker命令效果都相当于直接在host1上操作。如果要操作其它宿主机只需要再执行次上面eval命令即可。
其它常用的docker-machine命令:
$docker-machine config workerName //查看machine的配置
$docker-machine scp worker1:pathworker2:path //把worker1上的文件copy到worker2上
$docker-machine stop/start/restartworkerName
----------------------------------------Docker组群-----------------------------------------------------------------------
----------------------------------------跨主机网络-----------------------------------------------------------------------
Docker跨主机网路有Overlay,Macvlan,Flannel,Weave和 Calico等方案,实现原理各不相同,我们先简单了解下Overlay和Macvlan的原理。
Overlay:
Libnetwork是Docker容器网络库,最核心的内容是其定义的Container Network Model,将容器网络抽象成以下3个组件:
Sandbox:容器的网络栈,包含容器的interface、路由表、DNS设置
Network:实现是Linux Bridge、VLAN,同一Network可以直接通信
Endpoint:典型实现是veth pair,将Sandbox接入Network,一个Endpoint只能属于一个Network,也只能属于一个Sandbox。

那么如何使容器跨宿主机网络通信呢?
首先需要一个服务注册中心,我本人比较熟悉的组件有ZooKeeper,Spring Cloud里有Eureka,而Docker里使用了一种我不太熟悉的服务注册组件Consul,对其内部原理暂时不需要了解,只需要知道可以提供服务注册功能就好。
安装:
docker run -d -p 8500:8500 -h consul --nameconsul progrium/consul -server -bootstrap
容器启动后,可以通过 http://192.168.56.101:8500 访问 Consul。
然后修改Worker宿主机的配置文件/etc/systemd/system/docker.service

红框部分左边是consul的注册地址,右边是宿主机自己的连接地址。
修改后需要重启宿主机才可以生效。
在宿主机worker1中创建overlay网络:
$docker network create –d overlay ov_net1
-d是指定driver为overlay的实现方式(docker支持overlay和macvlan两种方式), ov_net1是给overlay起的名称。
这里注意个细节,创建出的ov_net1的作用域是global的:
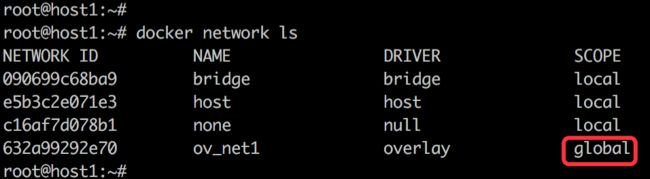
这样在其它worker中通过docker network ls都可以看的到这个global的网络。(这些信息是由Consul来维护和管理的)
$docker network inspect查看这个global的网络,可以看到
Subnet:10.0.0.0/24
Gateway:10.0.0.1
Docker自动为ov_net1分配了IP空间,在create的时候可以通过—subnet修改默认的网段。
如果多个容器启动的时候通过--network ov_net1指定同一个网络,他们就可以获得一个10.0.0.0/24 IP的网卡,通过该网卡可以跨宿主机通信。
docker会为每个 overlay网络创建一个独立的network namespace,其中会有一个 linux bridge br0,endpoint还是由 veth pair实现,一端连接到容器中(即 eth0),另一端连接到 namespace 的 br0上。br0除了连接所有的 endpoint,还会连接一个 vxlan 设备,用于与其他 host建立vxlan tunnel。容器之间的数据就是通过这个 tunnel 通信

Overlay是具有隔离性的,我们可以把它理解为一个VLAN。例如再创建一个global的overlay
$docker network create –d overlay ov_net2
基于ov_net2启动一个容器,那么这个容器是无法访问ov_net1中的容器的,当然可以通过“docker network connect ov_net2 ov_net1中容器名称”的方式来连接网络。
Macvlan:
混杂模式;
混杂模式就是接收所有经过网卡的数据包,包括不是发给本机的包。默认情况下网卡只把发给本机的包(包括广播包)传递给上层程序,其它的包一律丢弃。
macvlan不需要创建 Linux bridge,而是直接通过以太interface连接到物理网络,为保证多个容器的MAC地址的网络包都可以从某一物理网卡通过,我们需要打开网卡的混杂模式。
$ip link set eth0 promisc on
创建 macvlan 网络: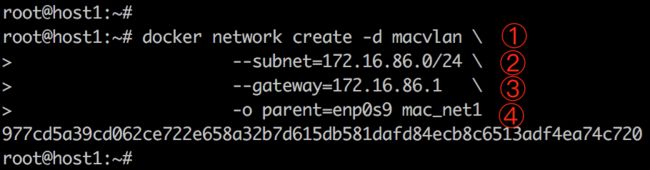
其中subnet和gateway是需要手工指定的,-o parent是打开混杂模式的网卡。
容器启动的时候需要指定IP和网络:
$docker run –it –name ContainerName–ip=172.16.86.6 –network mac_net1 ImageName
容器间通过ip是可以相互ping的通的,但是通过容器名是ping不通的,因为macvlan不具备DNS功能。
macvlan会独占主机的网卡,也就是说一个网卡只能创建一个 macvlan网络
我们通过一个表格来平行对比下各种方案:

----------------------------------------跨主机网络-----------------------------------------------------------------------
----------------------------------------跨主机存储-----------------------------------------------------------------------
Docker跨主机存储:
前面学习了Docker的跨主机网络,具体过程是先准备支持跨主机网络的组件,然后用相应的driver来docker create network,然后容器启动时绑定这里创造的网络既可。
Docker跨主机存储也是同样的过程,先准备支持跨主机存储的组件,然后用相应的driver来docker create,然后容器启动时绑定这里创造的存储集客。
案例存储Driver采用Rex-Ray
先搭建 backend 服务,然后在宿主机上安装好 Rex-Ray ,这里比较重要的是修改 Rex-Ray 的配置 /etc/rexray/config.yml :
1使用VirtualBox作为backend,生产上选择更健壮的backend,例如Ceph
2 endpoint是backend服务端口
3 volumePath是backend上存储的目录
4 SATA是controller的名字,不用修改。
通过$docker volume create –driver rexray –name=volumeName –opt=size-2
创建一个2G大小名称为volumeName的rexray存储。
然后宿主机上启动容器的时候只要通过-v volumeName:/tmp/data这种方式就可以将rexray存储绑定到容器的相应路径上了。
这样在其它宿主机上也可以mount相同的volume了,跨主机存储就得以实现了。
----------------------------------------跨主机存储-----------------------------------------------------------------------
----------------------------------------------------Docker监控-----------------------------------------------------------
Docker自带了几个监控命令,例如ps,top,stats但是输出都比较简单,如果要向达到生产级别的监控需要引入更加强大的工具。而这些工具分为开源派和收费派两大派系。
介绍一个开源工具Sysdig(System+Dig),logo是一个铲子:

其前身是一个专门对Linux内核系统的System+Dig的工具,后来由于Docker的兴起sysdig又引入了对容器的支持。
设计图如下:

从图中可以把sysdig分为两大部分:用户部分和内核部分。
内核部分有个Sysdig-probe,就像一个探头一样插入内核内采集相关的信息;
用户部分有scap、sinsp、sysdig三部分组成。
Scap负责抓捕控制和转存文件,负责数据采集;sinsp负责数据分析、设置过滤和输出格式;sysdig负责响应命令行解析采集的数据。
Sysdig可以直接以Docker镜像的方式进行安装:
$ docker run -i -t --name sysdig --privileged -v /var/run/docker.sock:/host/var/run/docker.sock -v /dev:/host/dev -v /proc:/host/proc:ro -v /boot:/host/boot:ro -v /lib/modules:/host/lib/modules:ro -v /usr:/host/usr:ro sysdig/sysdig
前面说过sysdig前身是监控linux的,所以sysdig命令默认的作用域是宿主机,如果想监控具体的容器,需要通过container.name=XXX的方式进行限定,例如监控centos1这个容器:
$sysdig container.name=centos1
Sysdig可用的命令包括网络、磁盘IO、进程和CPU、应用、性能和错误等方面,具体命令案例请参考《Sysdig的常用命令》
开源派里有一张图可以表达各自的能力和优势:

Sysdig 提供了的丰富的分析和挖掘功能,是 Troubleshooting 的神器。
cAdvisor 一般不会单独使用,通常作为其他监控工具的数据收集器,比如 Prometheus。
Weave Scope 流畅简洁的操控界面是其最大亮点,而且支持直接在 Web 界面上执行命令。
Prometheus 的数据模型和架构决定了它几乎具有无限的可能性。Prometheus 和 Weave Scope 都是优秀的容器监控方案。除此之外,Prometheus 还可以监控其他应用和系统,更为综合和全面。
收费派里价格各不相同,能力也有大小,其中做的做的不错的是Scout、DataDog,但是就像DataDog的费用,$15每个宿主机的价格对于大型拓扑来说并不是一个小数目,这里就不再详细介绍了。
----------------------------------------------------Docker监控-----------------------------------------------------------
----------------------------------------------------Docker日志管理-----------------------------------------------------
Docker自带的日志方式有2种:docker log或者attach到容器中查看控制台,这两种方式都有一定的弊端,而且对于Docker集群来说我们更需要一个集中式的日志管理平台,就像Spring Cloud微服务那样,我们通过ELK《ELK-ElasticSearch+Logstash+Kibana》来实现日志的采集、存储和查询,Docker的日志管理我们仍然可以依靠ELK来实现。
可以通过$docker info | grep ‘Logging Driver’命令来查看宿主机的logging driver。
容器启动时可以使用—log-driver指定logging driver,如果要设置宿主机默认的logging driver,需要修改Docker daemon的启动脚本,指定—log-driver参数。
Docker的日志driver除开json-file、journald,还有syslog、awslogs、splunk、gcplogs、gelf、fluentd。
Filebeat的配置文件为/etc/filebeat/filebeat.yml;
以json-file为例,日志文件在/var/lib/docker/containers/
Out吐流的URL,可以是直接吐给ElasticSearch,也可以吐给Logstash处理一把再由Logstash送给ElasticSearch,无论哪种设计都是一个http://ip:port/网络服务地址。
除开ELK,集中式日志管理又出来个后起之秀Graylog,一个组件顶替ELK3个组建的作用,而且提供更加直观的可视化界面。后续有时间还是要多了解一下Graylog。