3D目标检测算法详解_pointnet, pointnet++,frustum-pointnets,VoteNet
知识点回顾
什么是点云,如何获得点云。
- 点云包含了很多信息,除了3维坐标数据之外,还可能包括颜色、分类值、强度值、时间等。
- 点云数据可以由多种方法获得:1.直接由Lidar激光扫描出点云数据。 2.不同角度的2D图像组合成点云 3.由深度图(Depth Map)生成点云,即将图像坐标+深度信息从图像坐标系转换为世界坐标系。
- 点云和深度图都会出现深度信息的缺失,因为往往传感器只能捕捉物体表面的信息。
- .obj .off .ply格式都是3D mesh格式,即物体被划分成若干个微小单元(三角形,或其他形状)。点云格式有*.las ;*.pcd; *.txt等。
- voxel体素与2D中的pixel对应,是3D空间里一种标准的可处理的单位格式
- 点云数据有三大问题:无序性、稀疏性、信息有限(和稀疏性也相关,只能提供片面的几何信息)。
从3D点云到网格
点云数据与鸟瞰图
3D数据集汇总
ModelNet40
KITTI
SUN-RGBD
ScanNet
3D目标检测有很多种玩法,有纯基于RGB图像的,这种往往需要多个视角的图像作为输入;有纯基于3D点云的,如接下来要介绍的PointNet,PointNet++和VoteNet都是基于纯点云数据的;也有使用2D目标检测驱动3D检测的,如frustum-PointNet,就是先完成2D目标检测确定object位置,再找3D box。
PointNet
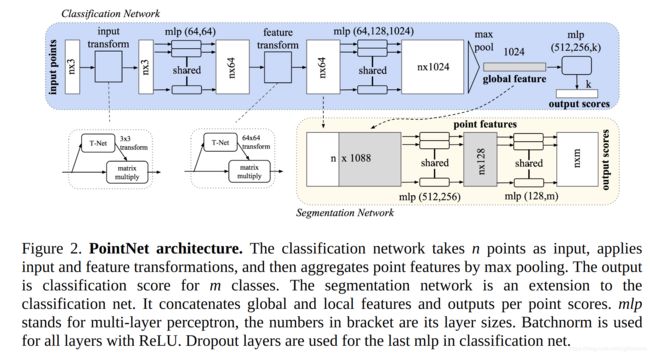
输入: B*N*3. B是batch size, n是点的个数, 3是每个点的特征数, 有些传感器或数据集可能还有点属性(旋转, 反射强度等)。训练的数据集是ModelNet40(包含40种室内家具的点云,由其CAD模型的surface数据得来)
T-net: 用于生成transformation矩阵(3*3尺寸用于对初始点云的处理,64*64用于对中间feature做处理), 接着和原始点云数据矩阵相乘做转换. T-net中有3层卷积+1层max_pool+2层FC+1层输出层, 输入shape B*N*3, 输出shape B*3*K (注:第一个transform里K=3, 第二个transform里K=64) .
input transform: 输入shape B*N*3, T-net shape B*3*K, 相乘之后输出shape B*N*K, 即B*N*3,与原始点云数据shape相同. input transform的作用相当于提取了原始点云数据或特征层里的特征, 对坐标空间进行了变换.(个人认为这么做是因为点云数据本身没有很强的顺序关系,对于卷积来说,相当于设定了点云数据的顺序关系,transform之后对位置空间进行了一个调整,有点类似于hough vote的图像空间转成坐标空间).
mlp: 两层卷积, filter都=64, 第一层kernel=[1,3], 第二层kernel=[1,1], 输出shape B*N*64
feature transform:与input transform类似,除了K=64
分类任务最后输出的output score shape为40(40类分类任务), 分割任务将global feature复制n份, 如图接在之前的特征层后, 最后输出shape为B*N*50 (我没有弄懂这里为啥是50不是40, 不应该是40类么?是不是因为分割任务可能会分割成其他物体?)
PointNet++
在PointNet中, 直接对输入的点云数据整体进行卷积和max_pooling,忽略了局部特征. 且特征提取忽略了密度不均匀的问题, PointNet++解决了这2个问题.
Hierarchical Point Set Feature Learning
三步: 采样中心点, 找邻点建局部区域, 提取局部区域特征
1. sampling layer: 该层的输入是原始点集N*(d+C), d为xyz坐标数据,C是点特征数据. 使用FPS算法从数据集中选出中心点集
FPS算法: 随机选取一个点加入中心点集合, 之后选择离中心点集合里的点最远的点加入中心点集合中, 迭代选取中心点(后面选取的点需要和之前中心点集合中所有的点做距离计算metric distance),直到中心点集中点的个数达到阈值.
2. grouping layer: 该层的输入是原始点集N*(d+C)和sampling出的中心点集N'*d(N'是中心点个数,中心点只需要d坐标信息,不需要特征信息). 该层的输出是点集(point sets)的groups, 每个点集的shape是N'*K*(d+C), 每个group对应一个局部区域, 共有N'个局部区域, K是中心点周围的点的个数. 不同的group的K的值不一样. 虽然每个group含有的点的数量可能不同,但是使用pointnet结构提取出来的特征是维度一致的(每层特征图使用了全局max pooling)
Ball query: 使用KNN选取中心点周围的点集也没有考虑到密度不均匀的问题. 文章使用了一种Ball query的方法,就是在中心点周围取一定半径里的所有点.
3. PointNet layer: 使用pointnet的网络提取局部区域的特征, 输入是grouping出的groups, 每个group的shape是N'*K*(d+C), 输出是N'*(d+C'), 邻点的坐标减去中心点的坐标,作为他们的新坐标. 点特征shape C被embedding成shape C', K个邻点被抽象成一个特征.
Robust Feature Learning under Non-Uniform Sampling Density
针对密度不均匀的问题,提出密度适应的特征学习方法: PointNet++ layer 替代PointNet layer
点云数据有密度不均匀的问题, 近多远少, 对于密度不均匀的数据使用相同尺寸的特征提取是不合适的(如卷积的感受野对远处的点集应该更大),文章使用了两种特征提取方法:
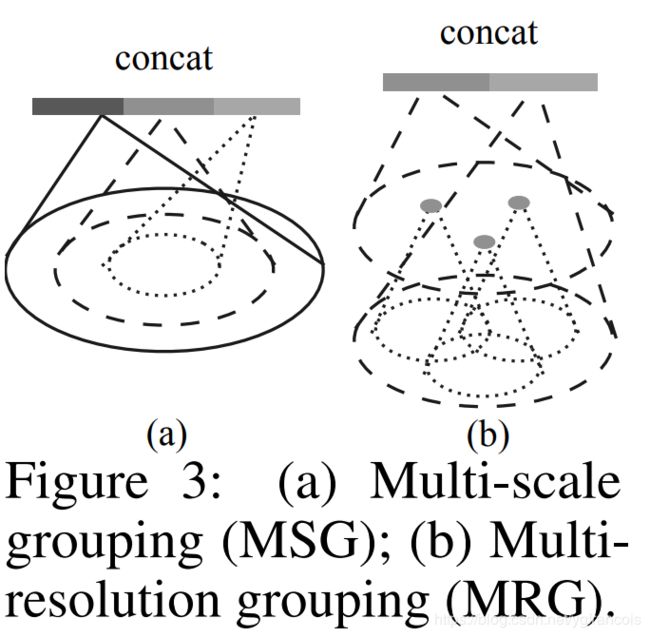
1. MSG(multi-scale grouping多尺度组合) 对每个group都用不同尺度大小的网络来提取特征,再叠加在一起
2. MRG (multi-resolution grouping多分辨率组合)每层对某个局部区域的特征提取由两部分组成: 基于上一层输出的特征提取到的特征+该区域对应的原始点集提取出的特征. 前者经过了两层特征提取,感受野更大, 适用于比较稀疏的点集. 而后者只做了一次适用于比较稠密的点集.
frustum-pointnets:以二维图像驱动三维点云中的物体检测
PointNet和PointNet++基于3D点云数据做分类和分割,f-pointnets基于RGB图像+深度信息使用pointnet和pointnet++的结构做了目标检测。f-pointnets考虑了室内和室外的场景,基于KITTI数据集和SUN RGB-D 3D detection benchmarks数据集进行了训练。
使用到2D RGB图像的原因是当时基于纯3D点云数据的3D目标检测对小目标检测效果不佳,所以f-pointnets先基于2D RGB做2D的目标检测来定位目标,再基于2d目标检测结果用其对应的点云数据视锥进行bbox回归的方法来实现3D目标检测。使用纯3D的点云数据,计算量也会特别大,效率也是这个方法的优点之一。

下图是该算法的架构图:
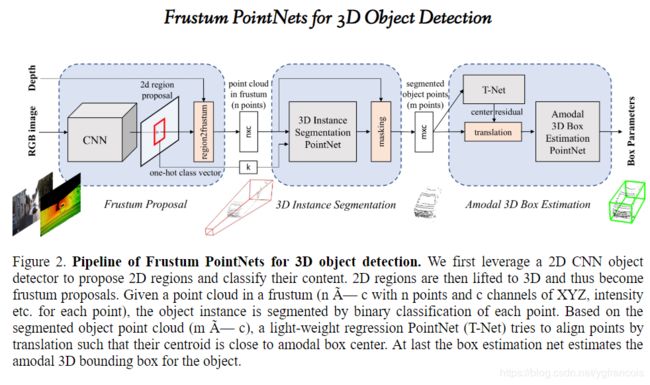
- 使用成熟的2D CNN目标检测器(Mask RCNN)生成2D检测框,并输出one-hot 分类向量(即基于2D RGB图像的分类)。
- frustum proposal generation视锥框生成: 2D检测框结合深度信息,找到最近和最远的包含检测框的平面来定义3D视锥区域frustum proposal。然后在该frustum proposal里收集所有的3D点来组成视锥点云(frustum point cloud)。由于视锥的方向会对其包含的点云数据影响很大,所以需要标准化视锥的方向,论文的做法是对视锥的坐标系进行旋转,直到视锥的中轴线和image plane垂直。这个视锥的标准化可以提升算法对旋转变化的性能。视锥坐标系变换的代码见provider.py,过程见下图。provider是一个数据生成器,除了坐标系的变换,也包括3D视锥点云的生成。
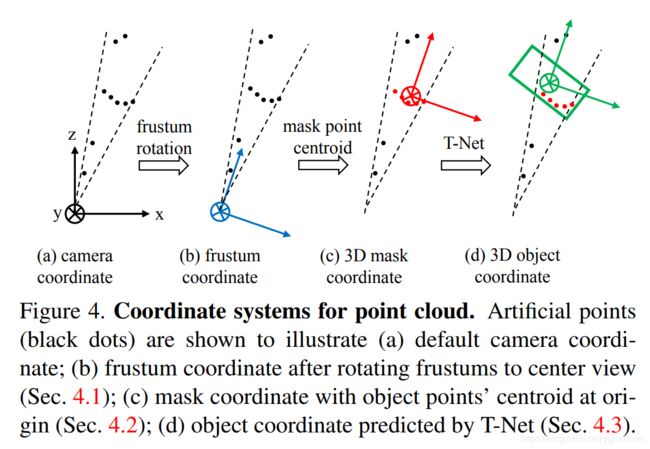
- 变换视锥的坐标系实际上就是变换点云的坐标系,从点云的角度来看,坐标系是z is facing forward, x is left ward, y is downward,frustum rotation实际上就是对点云数据绕y轴旋转,变换矩阵为[[cosval, -sinval],[sinval, cosval]],将其乘在y轴坐标上即可。其中正余弦的值由角度算来,旋转角度在kitti/prepare_data.py中定义,先找到2d box的中心点(x,y),给其任意添加一个深度z(由于是计算角度,不需要z的精确值,取个大于0的数即可),然后将(x,y,z)使用kitti/kitti_util.py里的project_image_to_rect转换成3D中心点(x',y',z')(该函数只转换了x,y,具体细节见代码)。之后frustum_angle = -1 * np.arctan2(box2d_center_rect[0,2],box2d_center_rect[0,0]),其中x'=box2d_center_rect[0,0], z'=box2d_center_rect[0,2]。(KITTI数据集README里描述了关于2d image数据和3D激光点云数据之间转换的calibration。
- 生成3D box(通过3d box的长宽高求出8个corner在3D space下的坐标),并获取包含在3D box里的3D点云(先要使用calibration里的转换函数将3D激光点云数据转换成3D rect数据)。
- 获得相应的3D点云后,,接下来是3D Instance Segmentation PointNet, 该部分实际上就是使用pointnet++的segmentation的网络架构进行分割,与pointnet++的区别是这里提前完成了检测,这里的segmentation是一个二分类。见下图左。之前2D生成出的one-hot class vector在feature propagation layers时与set abstraction layer的输出concat在一起,个人理解是这样可以给后面的分割添加一个先验,让分割更准确。需要注意的是,这里的分割除了获取3D segmentation之外,也是为下一步生成3D box过滤3D点云,因为之前的点云的范围比较大,会影响3D box的精度。
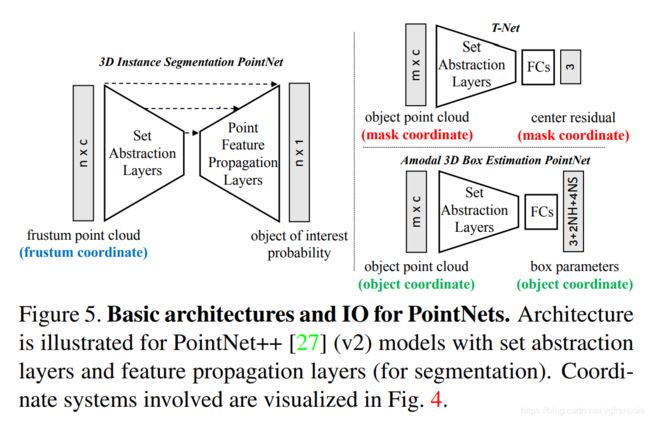
官方使用了两种网络来训练,v1是基于pointnet架构训练的模型,v2是基于pointnet++训练的模型。
Deep Hough Voting for 3D Object Detection in Point Clouds(2019)
f-pointnet 使用2D转3D的方法找object的中心,进行了一系列的坐标系转换。直接基于3D点云找中心比较困难,因为3D点云往往是object表面的点,且具有稀疏性,3D object的中心可能离这些点很远。本文使用了含有类似于传统Hough Voting机制的网络,来通过投票生成新的邻近中心点的点,再基于这些点分组和聚合,最后生成3D box。
广义霍夫变换和霍夫投票
参考:霍夫变换和霍夫投票
霍夫变换一般适用于有解析表达式的几何形状目标检测,例如直线、圆、椭圆等。变换的过程是将解析表达式表达的图像空间转换成参数空间,对于直线来说,直线上的每个点变换到参数空间中都是一条直线,这些直线共同的交点在参数空间中的坐标就是图像空间中的参数。寻找这个交点的方法就是霍夫投票,即统计参数空间中每个点被运用的次数(以空间中每个点的坐标为key,使用的次数为value),峰值点即为参数点,霍夫空间中的峰值点可能不严格的在同一个坐标上,需要允许一部分误差。
参考:广义霍夫投票,论文
广义霍夫变换可用于没有解析表达式、不规则形状的目标检测。没有解析表达式,无法直接将图像空间转换到参数空间进行投票;即使找到对应解析式,参数也必定很多,参数越多参数空间的复杂度指数增长。以下是广义霍夫变换的做法:
- 首先要适用于一个边缘模板,检测出图像的边缘点。这是因为边缘是检测和区分图形最重要的特征。
- 建立给定图形的R-table:
- 准备一个有k种角度
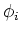 (
( 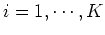 ) which increases from 0 to 180 degrees with increment
) which increases from 0 to 180 degrees with increment 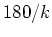 的表,k是梯度方向(即边缘某点切线的法向量)的分辨率。
的表,k是梯度方向(即边缘某点切线的法向量)的分辨率。 - 在2D图形里找到一个参考点
 (如:重心),对边缘上的每个点计算两个参数
(如:重心),对边缘上的每个点计算两个参数
- 准备一个有k种角度
- 投票:对于给定边缘点信息,我们通过查表然后计算出参考点位置,然后根据投票机制,确定投票最多的位置。
Deep Hough Voting
霍夫投票很适合点云数据,一是因为投票针对稀疏集合设计,二是因为其积累少量的局部信息以形成可靠的检测。为了将霍夫投票用于3D点云数据,本文做了以下调整:
- 兴趣点 (Interest points) 由深度神经网络来描述和选择,而不是依赖手工制作的特性。
- 投票 (Vote) 生成是通过网络学习的,而不是使用codebook(相当于R-table)。利用更大的感受野,可以使投票减少模糊,从而更有效。此外,还可以使用特征向量对投票位置进行增强,从而实现更好的聚合。
- 投票聚合 (Vote aggregation) 是通过可训练参数的点云处理层实现的。利用投票功能,网络可以过滤掉低质量的选票,并生成改进的 proposals。
- Object proposals 的形式是:位置、维度、方向,甚至语义类,都可以直接从聚合特征生成,从而减少了追溯投票起源的需要。
本文将以上步骤融合到了一个end-to-end的神经网络里:VoteNet。
VoteNet

利用3D点云数据完成投票
输入N*3的点云数据,输出M个种子点,每个种子点通过独立的投票模块独立生成一个投票,包含3D坐标值和一个high dimensional feature vector。这个过程主要分两步:
-
学习点云特征:使用PointNet++的网络架构
-
使用deep network完成Hough voting:不再使用创建codebook的方法,而是使用神经网络生成,这种方法更效率,且因为是end-to-end训练,也更准确。voting模块由一个MLP实现(FC+ReLU+BN),MLP输入种子点的feature(不包含种子点的坐标),输出三维坐标∆xi+特征offset,三维坐标由监督学习学得:
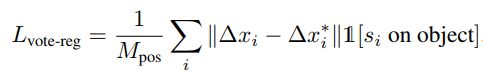 由seeds生成的votes比seeds本身更相近,这让聚合工作更容易。
由seeds生成的votes比seeds本身更相近,这让聚合工作更容易。
Object Proposal and Classification from Votes从投票里生成候选框和分类
- Vote clustering through sampling and grouping:通过采样和组合的方式完成vote聚类,采样和组合的方法和pointnet++的一样,即3D空间里的farthest point sampling,基于选中的K个sample,通过指定半径来划分组合。
- Proposal and classification from vote clusters:使用PointNet式的网络来从聚类中提出proposal
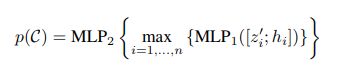 ,其中zi是投票的坐标,hi是vote feature,MLP1之后进行max-pooling,将尺寸归一化,再进入MLP2继续捕捉信息,最后输出proposal p,包含an objectness score, bounding box parameters (center, heading and scale parameterized) and semantic classification scores.
,其中zi是投票的坐标,hi是vote feature,MLP1之后进行max-pooling,将尺寸归一化,再进入MLP2继续捕捉信息,最后输出proposal p,包含an objectness score, bounding box parameters (center, heading and scale parameterized) and semantic classification scores.