Keras LSTM的参数input_shape, units等的理解
之前一直对LSTM的参数理解有误, 特别是units参数, 特此更正.
input = Input(shape=(100,), dtype='float32', name='main_input')
lstm1 = Bidirectional(LSTM(100, return_sequences=True))(input)
dropout1 = Dropout(0.2)(lstm1)
lstm2 = Bidirectional(LSTM(100, return_sequences=True))(dropout1)
lstm3 = Bidirectional(LSTM(100))(lstm2)
dropout2 = Dropout(0.2)(lstm3)
output = Dense(242, activation="softmax", name="main_output")(dropout2)如上是一个三层LSTM的网络,中间有两层dropout,最后是一层全连接层.
首先说一说LSTM的input shape, 这里的代码先定义了input的尺寸, 实际上也可以使用第一层(注意只有第一层需要定义)LSTM的参数input_shape或input_dim来定义. 官方文档给出的input shape是3维: (Batch_size, Time_step, Input_Sizes), 其中Time_step是时间序列的长度, 对应到语句里就是语句的最大长度; Input_Sizes是每个时间点输入x的维度, 对于语句来说,就是一个字的embedding的向量维度.
在给出的例子里, shape=(100, ), 没有定义batch_size和Input_Sizes.
在没有定义batch_size的情况下, 可以通过model.fit中的batch_size参数进行定义, 但是这种方法无法再使用model.train_on_batch()函数. 如果这里定义了batch_size,那么在test的时候, 也要保证有该batch_size的数据, 否则会出现错误, 这样对只预测一个样本的问题无法兼容. 比较好的方法是将Batch_size设置为None, 这样不需要实现设置固定的batch_size,且可以调用train_on_batch.
在没有定义Input_Sizes的情况下, 我尝试的训练, 会将其默认为1处理.
另外, input_length指的也是输入句子的长度,即Time_step. 如下两种定义方式,表达的内容相同:
model = Sequential()
model.add(LSTM(32, batch_input_shape=(None, 10, 64)))
model = Sequential()
model.add(LSTM(32, input_length=10, input_dim=64))LSTM的第一个参数units此处设置为100, 指的不是一层LSTM有100个LSTM单元. 在很多LSTM的框图里,会将LSTM单元按时间顺序排开, 句子长度多少就设置多少单元,实际上一层LSTM每个"单元"共享参数, 所以其实只有一个单元的参数量. LSTMCell也实际上指的是一层LSTM. 这里的units=100指的是这个LSTM单元内的隐藏层尺寸. 如下图所示,每个单元内会有三个门,对应了4个激活函数(3个 sigmoid,1个tanh), 即有4个神经元数量为100的前馈网络层.
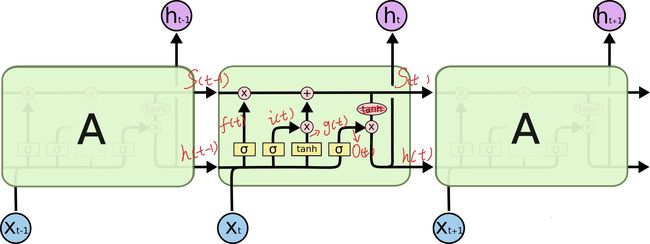
理论上这个units的值越大, 网络越复杂, 精度更高,计算量更大.