目标检测算法横向比较,包括backbone、特征融合、loss、proposal/anchor/heatmap、NMS、正负样本设置等
目标检测算法发展移步:目标检测算法
本文从算法改进的方向,进行横向比较,包括backbone,特征融合、loss、proposal/anchor/heatmap、NMS、正负样本设置等
Reference:Object Detection in 20 Years: A Survey
Table of Contents
Backbone改进
DenseNet
ResNeXt(group convolution)
SENet(Squeeze-and-Excitation Networks)
特征融合方法
Processing flow
Element-wise operation
番外:如何在分辨率和感受野之间折中——dilated convolution
anchor或候选框生成
faster-RCNN中
YOLO
SSD
FPN
RetinaNet
RefineDet
Anchor-Free的“候选框”
DenseNet
CornerNet
FCOS
前景、背景样本阈值的设置
faster-RCNN
YOLO
SSD
FPN
RetinaNet
RefineDet
DenseNet
CornerNet
FCOS
Hard Negative Mining问题
NMS
1.传统NMS
2.SoftNMS
IoU-guided NMS
Head,sub-network,Loss和训练
Faster-RCNN
SSD
RetinaNet
RefineDet
其他
localization的改进
多尺度问题
context priming
pretraining的作用/training from scratch
加速方法
用segmentation改进detection任务
Backbone改进
Backbone的改进有以下几个方向:变深(resnet系列)、变宽(Inception系列)、变小(mobile、shuffle等)、利用特征(densenet、senet等)以及针对检测专门设计的backbone(比如darknet)。
模型进化史:VGG->GoogLeNet/ResNet->DenseNet->ResNeXt->SENet
maskRCNN用的ResNet进化版:ResNeXt
为了加速,会使用加速的模型:MobileNet,LightHead RCNN
DenseNet
DenseNet是一个更密集的ResNet,即每层都会接受前面所有的层的输出,可以实现特征重用。
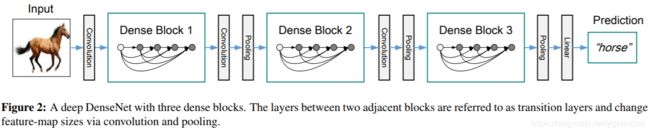
与ResNet使用sum连接不同的是,DenseNet使用concatenate,为了保证concat之后的尺寸,接了一个1x1的卷积层,然后又接了一个2×2 average pooling layer。
需要注意的是,每个Dense Block里虽然是BN-Relu-Conv的顺序,但实际上BN还是接在conv层后激活函数之前的,只不过把第一个Conv放在了外面,BN作用于concat之后的特征上。
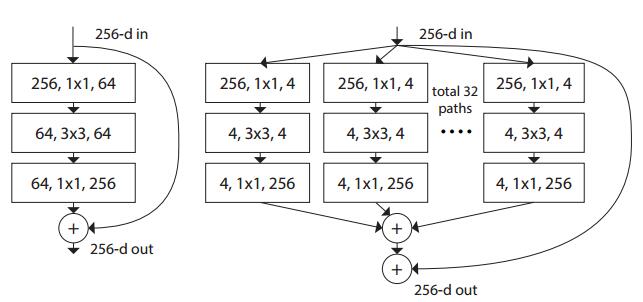
ResNeXt(group convolution)
下图左为resnet,右图为ResNeXt(格式: in channels, filter size, out channels)。主要是分组进行了卷积,最后再concatenate在一起,这种改进会让参数更少,但是分类accuracy增加了。与Inception V4相比,ResNeXt效率更高,但准确率不一定有V4好,因为它丢掉了不同感受野的卷积。
SENet(Squeeze-and-Excitation Networks)
SENet假设了卷积之后各特征图的重要程度不同,于是要给各channel加一个attention权重
squeeze和excitation正是为了生成这个attention weight。
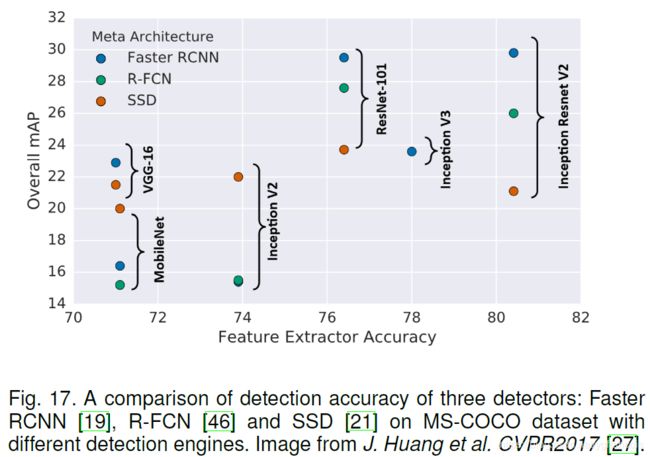
注意:以上的网络都是针对图像识别任务创建的,而并不是针对检测任务创建的,检测任务除了分类还有bbox的回归,所以由上图可以发现,并不是越强的网络(对于分类任务而言)在检测任务上就越强,如图中的ResNet101的feature extractor accuracy比Inception Resnet v2差很多,但是前者基于SSD框架的检测mAP却比后者强很多。
除了这些网络之外,与这些网络同时使用的还有FPN(非常重要),我们在特征融合里方法里说明。
特征融合方法
Invariance不变性和equivariance等变性是图像特征表达的两个要素,也是目标检测任务同时需要考虑的。
分类任务中比较看重invariance,不论物体出现在图像中的什么位置,都能识别出来。旨在学习到high-level的语义信息。
localization任务比较看重equivariance,物体在图像中进行了平移,localization的结果也应该做对应的平移。旨在判别位置和尺寸scale。
因为CNN网络有很多的卷积层和池化层,所以越深层的特征层有stronger invariance和less equivariance,而低层网络虽然语义特征比较差但是含有更丰富的edge和contour信息。所以为了在获得 invariance的同时获得equivariance,可以融合多层特征层,之前提到的FPN就是为了做这个。
Processing flow
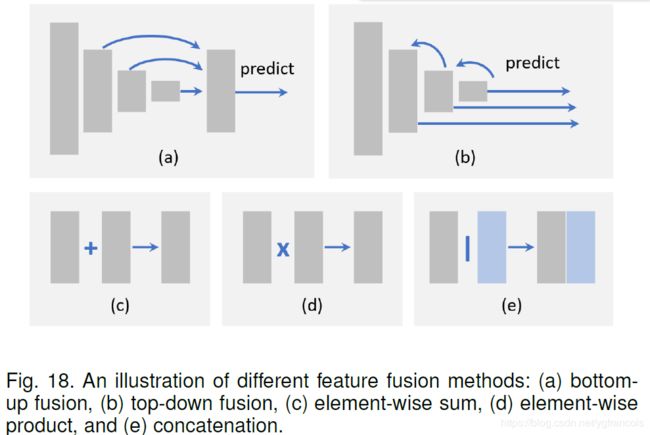
有bottom-up fusion和top-down fusion两种特征融合形式。
bottom-up fusion在SSD里使用到,做法是最后多层特征层都生成Anchor传到输出层进行box选择,除此之外还在RSSD等SSD的衍生网络上得到使用。
top-down fusion在FPN网络里使用,它是将高层的特征层通过up-sampling传回低层,与低层融合后生成低层的特征层,让低层的特征层拥有了语义特征,最后也是基于最后多层特征层生成的Anchor进行筛选。FPN技术是结合feature extractor 一起使用的,所以在后面得到广泛应用,包括mask-RCNN,RetinaNet等state-of-the-art的模型。
两种融合形式也可以“一起食用,味道更佳”,例如RefineDet就是结合了SSD的bottom-up fusion和FPN技术。
为了完成不同layer之间的bottom-up和top-down,需要对特征图的尺寸做适配。例如通过1*1卷积来适配channel,通过up-sampling和down-sampling完成shape适配。做下采样时,mask-RCNN使用了双线性插值(一般的下采样是最近邻插值),弥补了一些proposal边框坐标处于非整数情况时的误差。另外也可以使用RefineDet里使用转置卷积(或称作fractional strided convolution)来完成替代上采样,转置卷积也需要进行参数的训练,虽然可能带来性能上的提升,但是训练资源要求会变多。
Element-wise operation
上图c、d、e展示了特征图之间融合的3种方法。element-wise sum是直接将数组/矩阵对应位置相加,element-wise product则是相乘,注意,乘相比加而言有个好处是,乘法可以抑制或者突出某些特定区域的特征,这有利于小目标的检测。e是直接将两组特征在channel方向叠加在一起,这种方法肯定是accuracy最好的,因为叠加的过程种没有信息的丢失,可以集成不同区域的上下文信息,但是缺点是大大增加了内存占用。
番外:如何在分辨率和感受野之间折中——dilated convolution

越低分辨率的特征层越难用于检测小物体,提升分辨率最好的方法就是去掉pooling层,或减小下采样的尺度,但是这种方法会使特征层像素点的感受野变小,从而可能导致miss掉某些大目标。
当然之前所说的特征融合可以解决这个问题,除此之外还有一个方法,就是使用dilated convolution空洞卷积。空洞卷积最早在语义分割任务里使用,空洞卷积相比普通卷积的感受野更大,去掉pooling 不会影响大目标的检测(去掉pooling 保证了高分辨率),同时卷积核的参数也没有增加(不过最后得到的feature map比原来大了,所以后续的网络部分可能会有计算量的增加)。SSD在VGG-16的基础上,删除了fc8,将fc6,fc7换成了卷积层,为了维持分辨率,删除了pool5,而是在fc6上使用空洞卷积来维持感受野。RFB-SSD在Inception module的每个分支后面增加一个相应的dilated convolution。
anchor或候选框生成
anchor的想法最初由faster-RCNN提出,后来在众多算法上都得到了沿用,如SSD, YOLO2, mask-RCNN,RetinaNet,RefineDet等,在18年8月CornerNet出来之后,anchor-free的算法大有占据未来的趋势,不过anchor-based的方法目前还是主流。anchor是人为预设的一组多种scale*多种ratio的参考框,尽量覆盖所有scale(大小)和ratio(形状)的的检测框,每个参考框负责检测与其IOU大于阈值 (训练预设值,常用0.5或0.7) 的目标,anchor技术将问题转换为"这个固定参考框中有没有认识的目标,目标框偏离参考框多远"。
faster-RCNN中
anchor在RPN网络里的特征图上使用,使用3*3 sliding window在特征图上滑窗,每个窗口中心为anchor中心(映射到原图上),生成3scale(128*128,256*256,512*512)*3ratio(2:1,1:1,1:2)=9个anchors,共20000多个anchor,去除其中超过image边界的anchor,大概剩6000个anchor,再经过NMS处理生成较好的2000个anchor。这里最小的anchor尺寸为128*128,实际上很难cover很多小目标。
YOLO

yolo v1没有anchor设置,而是直接将原始图片划分为7*7个grid,每个格子预测B个框,原文设置B=2,所以一张图片会预测98个框。如果某目标的ground truth的中心落在某个格子内,该格子负责检测该目标,由于每个格子预测2个box,所以最后网络针对这个格子会输出2*(4+1)+20 =30个值。其中4是box的坐标(x,y,w,h);1是box的confidence score,如果格子包含目标则置信分是box和gt的IOU,如果格子不包含目标则置信度为0;20是分类的数量。
有人可能要问,这30个值是网络最后一起输出的,那么和每个格子又有什么联系呢?实际上(x,y,w,h)中,(x,y)是指box中心点离对应格子左上角顶点的位移,且单位是相对于单元格的比例;(w,h)是box的长宽对应整个image的比例。(x,y)的性质让网络朝着假设的方向训练。
YOLO检测框的设置方式会有2个问题:1. 一个box只预测一个物体,所以对于邻近小目标很难检测。2.没有设置先验框,而是从图像里学习到检测框,会导致特殊形状box(unusual aspect ratios)难以检测到。
SSD
SSD采用了类似anchor的方法,设置prior box,不同的是SSD在6个不同的特征图上设置了候选框(faster-RCNN只在一个特征图上处理),分别是Conv4_3,Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2,这6层的特征shape分别是 : (38, 38), (19, 19), (10, 10), (5, 5), (3, 3), (1, 1)。
SSD将候选框的scale与特征层挂钩,这是因为越高层特征,每个像素感受野越大,越适合检测大目标;而越低层特征层,感受野越小,越适合检测小目标。引入scale公式:,sk表示先验框大小相对于图片的比例,即一个特征图一个scale,论文中m=5是特征层的个数(Conv4_3单独考虑),Smin=0.2,Smax=0.9。
ratio设置5个尺度:,特别的,对于ratio=1的情况,额外设置一种scale:。对应的框的长宽:
所以总共有6种不同形状的候选框,但是在实现时,Conv4_3,Conv10_2和Conv11_2层仅使用4个先验框,它们不使用长宽比为 的先验框。SSD的候选框和faster-rcnn一样,都是以特征图的像素点为单位,以特征层像素点映射到原图的感受野中心为中心,每个像素点生成4个或6个候选框,所以一张图片的总候选框数为:(38x38+3x3+1x1)x 4 + (19x19+10x10+5x5)x 6 = 8732个候选框。
候选框的数量比RPN少了很多,虽然尺寸比例不如RPN的多,但是在多个特征层上进行了候选框选取,anchor的尺寸最小有60的,最大有284的,小尺度anchor多且密,大尺度anchor则比较稀疏,更合理。同时感受野也都是大于anchor大小的,且训练过程种,不忽略跨边界anchor,效果更好。
SSD存在的问题是,1. anchor的设置没有对齐感受野,像素中心的位移对小目标IOU影响比较大。 2. anchor的尺寸都是人工设计的,并不一定能够覆盖所有可能的目标。当对付COCO数据存在很多小于60尺寸的小目标时,性能不够用。
另外,小物体需要依靠低特征层和小尺寸检测框,但是小尺寸检测框由于处在低特征层会导致特征提取不足,同时由于感受野有限,所以可能难以检测出物体,这个问题在FPN里得到了比较好的解决。
FPN
之前提到,SSD是bottom-up的特征融合方式,FPN则是top-down形式。与SSD相同的是候选框的scale与特征层挂钩,即越高层的特征层的像素感受野越大,设置的候选框scale应该越大。FPN在resnet50 head之后接了5层卷积,经过top-down之后输出{P2, P3, P4, P5, P6} 5个feature map,在每个feature map上使用RPN生成anchor,每个feature map的scale分别是{32, 64, 128, 256, 512},每个feature map的每个位置有三种ratio{1:2, 1:1, 2:1},所以每个feature map 上有3种尺寸不同的anchor,共15种不同anchor。
虽然p2 feature map的anchor只有32,但是FPN通过特征层top-down的方法,将深层特征传回给了浅层,弥补了浅层特征感受野不够大的问题。
RetinaNet
类似于FPN,区别在于从{P3, P4, P5, P6, P7} 拉出5个feature map进行检测,每个level的基础scale仍然分别是{32, 64, 128, 256, 512},每个feature map的每个位置有三种ratio{1:2, 1:1, 2:1},不过在此基础上,每个level使用了3种scale{2^0, 2^(1/3), 2^(2/3)},所以每个feature map有9种anchor,总共45种anchor,覆盖32-813像素的区域。提升了AP。
同样尺度为32的anchor,FPN用P2进行检测,而RetinaNet用P3进行检测,这是因为FPN的前景阈值是0.7需要anchor更密集,RetinaNet前景阈值是0.5 anchor相对稀疏。
RefineDet
如图RefineDet是类似于faster-RCNN+FPN的方法,不同的是第一阶段生成bbox时使用的是SSD的方法而不是RPN。
RefineDet在4个Feature layers(VGG-16是conv4_3, conv5_3, conv_fc7, conv6_2;resnet101是res3b3,res4b22,res5c,res6)上分别提取anchor,与faster-rcnn和其他之前的算法不同的是,不再每个像素点都对应一组anchor,而是分别设置stride size 8,16,32,64,每个feature layer的scale是stride size的4倍(只有一种scale),同时对应3种ratio:0.5,1,2。
Anchor-Free的“候选框”
DenseNet
DenseNet是像素级别的检测,feature map的每个像素(x,y)都要完成1.是否在GT内的分类;2.离检测框距离的回归(4个距离,分别是该像素点离GT左上角点和右下角点的x,y距离)。 所以每个像素点的训练目标都是5维vector:(s,x-xt,y-yt,x-xb,y-yt)。注:s是confidence score(我没有在论文里找到densebox每个像素点对应的置信分数怎么算,也没有细看代码,请大佬赐教),xt,yt是指GT的top left坐标,xb、yb指bottom right。
CornerNet
FCOS
前景、背景样本阈值的设置
faster-RCNN
- 把每个标定的ground-truth box与其重叠最大的anchor box记为前景样本。(保证每个ground-truth box至少对应一个正样本anchor)
- 剩余的anchor box与某个ground-truth box重叠大余0.7的记为前景样本。(每个ground-truth box可能会对应多个正样本anchor。但每个正样本anchor 只可能对应一个grand-truth box)
- 与任意一个标记ground-truth box重叠小于0.3的anchor box记为背景样本。
- 其余的舍弃。
这些前景和背景样本用于RPN的训练
YOLO
yolo1中每张图片只有98个框,框是否为前景由对应的格子内是否有目标中心点决定。前景和背景涉及到置信度的计算(YOLO的loss里包含了置信度一项,置信度为0也要参与训练)。
YOLO处理置信度:对于98个boxes,首先将小于置信度阈值的值归0,然后分类别地对置信度值采用NMS,这里NMS处理结果不是剔除,而是将其置信度值归为0。最后才是确定各个box的类别,当其置信度值不为0时才做出检测结果输出。参考:https://zhuanlan.zhihu.com/p/32525231
SSD
- 对每一个GT,将与其IOU最大的先验框设为前景样本。
- 剩余的先验框中,与任意一个GT的IOU大于0.5的设为前景样本。
- 剩余的设为背景样本。
注:为了保证正负样本比例,对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
FPN
同Faster-RCNN。
RetinaNet
- IOU>0.5 设置为前景样本;
- IOU<0.4 设置为背景样本;
- 其余忽略。
RefineDet
同SSD
DenseNet
DenseNet比较特殊,特征图有5个通道,第一个通道以gt box中心为圆心,作半径为r的圆,圆面积是box面积的0.3(文中只说了圆的scaling factor是box size的0.3,面积是我猜的,没看代码,如有错误请指正),该圆内被作为是GT。其余4个通道就以正常的GT box边界为GT。
由于算法是直接对像素点预测分类和回归,所以不存在IoU。
CornerNet
FCOS
Hard Negative Mining问题
目标检测任务中,正负样本数量往往是失衡的,负样本很多,但实际上很多负样本是很容易被区分的背景样本,这些样本是没有价值的。easy negative的样本提供的loss很少,然而当很多这样的样本集合起来,会导致loss更新的方向受到影响。HNM正是为了解决这种正负样本失衡的问题。
在Faster-RCNN,YOLO里是直接规定正样本和负样本之间的比例(Faster-RCNN里训练RPN时,是从NMS之后的proposal里选出正负样本1:1的256个样本,如果正样本不足128个,用负样本补),但这并不是最好的方法,因为负样本中有easy negative也有hard negative,且由于easy negative样本很多,选中多数easy negative样本的概率很高,这样会影响网络的性能。最好的办法是从负样本中选出hard negative的负样本进行训练。
SSD将confidence loss从大到小排列,从中选取loss最大的样本,且保证负样本:正样本=3:1。
OHEM只保留部分loss最高的样本,完全忽略了简单样本;OHEM+保留最高样本的同时保证负:正=3:1。实践发现前者比后者好,所以更大的原因是sample占了主导。
RefineDet中使用了“anchor refinement module”来过滤easy negative,不过论文种提到,即使使用了级联的方法,ODM的负样本仍然很多,所以还是采用了SSD类似的方法:在negative anchors里面选loss最高的anchor,保证negative:positive=3:1。另外,对于ODM的训练,使用的refined anchor box,如果其negative confidence大于阈值(0.99),就将其舍弃。
RetinaNet中则是对传统的cross entropy loss做了改进,即focal loss,让其更focus在hard、错分类的样本上,从而并不需要hard negative mining。
NMS
以下内容参考:https://zhuanlan.zhihu.com/p/48169867
1.传统NMS
将bbox按照得分从大到小排列,取出bbox中得分最高的bbox,并在剩下的bboxes中去掉与该bbox IoU大于一定阈值的(如0.5、0.7等)bbox,相当于去掉重复的bbox。然后迭代选取,直到bbox被取完。这种原始NMS有缺陷:
- 得分最高的并不一定是最好的框。
- 难以handle两个object离得很近的情况,即相邻物体很容易被抑制。
- 并没有抑制False Positive值(IoU过高容易产生误检,过低容易漏检)
2.SoftNMS
传统NMS直接将所有大于阈值的框都抑制掉,会导致邻近物体被抑制。SoftNMS不再是将这些框直接抑制掉,而是减少他们的置信分,实际上传统NMS是SoftNMS的一种特殊情况,即直接将大于IOU阈值的框的置信分降为0。下图左为传统NMS,右图为SoftNMS(线性加权)。
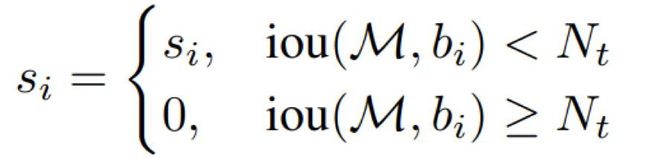
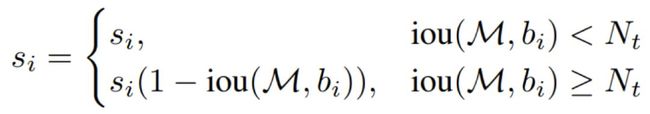
另外还有一种高斯加权法: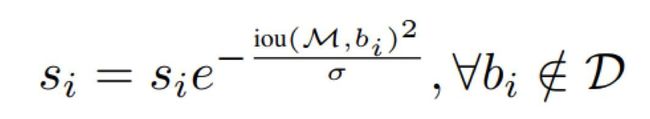
以下是代码演示:

注意:SoftNMS在训练过程中还是用传统的NMS,而在inference过程中使用SoftNMS,作者实验发现在训练过程中使用SoftNMS作用不大。soft-NMS也是一种贪心算法,并不能保证找到全局最优的检测框分数重置。
IoU-guided NMS
传统的NMS只考虑了分类置信度,如Faster-RCNN用在RPN网络里,是将anchors按照前景分数从大到小排列后进行NMS,这个过程中并没有用到定位信息。IoU-Net同时考虑定位置信度,实际上就是在NMS的过程中,将候选框按照定位置信度,即IoU的值从大到小排列,再进行NMS,不过在进行NMS的过程中,会对分类置信度做一个调整:NMS会剔除几个IoU非极大值,但是在这些IoU非极大值对应的候选框中,可能会有某些候选框的分类置信分比IoU极大值对应的候选框的分类置信分大,就将这个分类置信分赋值给该IoU极大值对应的候选框。相当于以定位置信度为标准,同时保留分类置信度的效果。
Head,sub-network,Loss和训练
对于two-stage和one-stage的方法,loss和训练过程往往差距比较大。two-stage方法需要针对RPN网络(first-stage)设置二分类loss(用于判断检测框里是否含有物体)+定位loss,在second stage阶段设置一对多分类或softmax分类loss(用于做最后的物体分类)+定位loss(级联回归,让box更精确)。在训练过程上,two-stage往往也要分多步骤训练,例如先训练RPN,再训练fast-rcnn网络。
Faster-RCNN

Faster-RCNN的RPN network,在特征图基础上接3*3卷积,每个3*3区域生成1*1*256的特征,然后分支两部分,分别接 1*1的卷积层,用于将通道数改成18和36。
分类分支得到尺寸WxHx18,9个anchor都含有前景和背景的softmax二分类,文中从该特征向量里对每个像素点通过softmax输出9个前景得分和9个背景得分,18个得分在训练阶段会用于分类网络的训练(交叉熵),在训练fast-rcnn阶段和最终的推理阶段前景得分会用于选取候选框,包括NMS过程;在前向传递过程中,会将所有输入anchor的得分求出来之后,经过剔除、过滤和NMS之后将anchor按前景得分从大到小排列,取前post_nms_topN(e.g. 300)作为输出结果(使用分类分数选出前景anchor后才进行回归)。
回归分支得到尺寸WxHx36,每个anchor预测4个值,分别是anchor中心距离gt中心的两个距离+anchor的长宽与gt长宽的比值。
RPN的Loss如下,其中分类loss使用log loss,回归loss采用smooth L1 loss,该loss让loss过小的框对优化的影响更小,让loss过大的框按L1的数量级产生影响。smoothL1(即Lreg)前乘的是1或0,1意味着是前景样本,0是背景样本(背景样本不提供loss进行bbox回归训练)
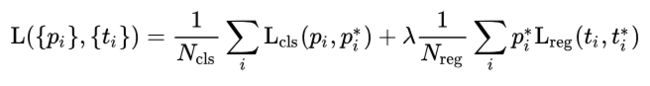
在fast-RCNN的网络训练阶段,使用RPN网络产生的proposal作为输入,经过ROI Pooling Layer。最后的回归loss和RPN网络的一样,采用smooth L1,分类loss采用softmax,只不过与RPN只有0,1两个label不同的是,这里的softmax做的是最终分类类别数的分类。
两个阶段的训练输入的anchor的数量和比例都是不同的,设置的IoU也不同。
对于RPN的训练过程:
cfg.py
# IOU >= thresh: positive example
__C.TRAIN.RPN_POSITIVE_OVERLAP = 0.7 # >0.7 fg 用在算 conf_cls 的
# IOU < thresh: negaxtive example
__C.TRAIN.RPN_NEGATIVE_OVERLAP = 0.3 # <0.3 bg
# NMS threshold used on RPN proposals
__C.TRAIN.RPN_NMS_THRESH = 0.7 # NMS 阶段的阈值参数,与上一个0.7区分开~
# 现在进行 NMS...
# Number of top scoring boxes to keep before apply NMS to RPN proposals
__C.TRAIN.RPN_PRE_NMS_TOP_N = 12000
# Number of top scoring boxes to keep after applying NMS to RPN proposals
__C.TRAIN.RPN_POST_NMS_TOP_N = 2000
# Proposal height and width both need to be greater than RPN_MIN_SIZE (at orig image scale)
__C.TRAIN.RPN_MIN_SIZE = 16
# Max number of foreground examples
__C.TRAIN.RPN_FG_FRACTION = 0.5 # RPN 阶段,fg:bg samples 1:1 各128 random choice
# Total number of examples
__C.TRAIN.RPN_BATCHSIZE = 256 # fg128 + bg128RPN的训练不会使用所有的anchor,先去除IoU在0.3和0.7之间的anchor(不参与训练),再将box按分类得分排列,取前12000名(train的过程取12000,test过程取6000),再去除过小的anchor和超出边界的anchor,接着使用NMS去除重复box,保留NMS之后分类得分前2000名的anchor(train的过程保留2000个,test过程保留300个),从剩下的anchor中选256个anchor(positive:negative=1:1,如果positive不足128,用negative补齐)。
fast-rcnn的训练:
# Minibatch size (number of regions of interest [ROIs])
__C.TRAIN.BATCH_SIZE = 128
# Fraction of minibatch that is labeled foreground (i.e. class > 0)
__C.TRAIN.FG_FRACTION = 0.25 # fg:bg == 1:3
# Overlap threshold for a ROI to be considered foreground (if >= FG_THRESH)
__C.TRAIN.FG_THRESH = 0.5 # iou > 0.5 then be fg
# Overlap threshold for a ROI to be considered background (class = 0 if
# overlap in [LO, HI))
__C.TRAIN.BG_THRESH_HI = 0.5
__C.TRAIN.BG_THRESH_LO = 0.1 # iou: 0.1~0.5, then be bg
# Use horizontally-flipped images during training?
__C.TRAIN.USE_FLIPPED = True
# Train bounding-box regressors
__C.TRAIN.BBOX_REG = True
# Overlap required between a ROI and ground-truth box in order for that ROI to
# be used as a bounding-box regression training example
__C.TRAIN.BBOX_THRESH = 0.5 # 和上面的判断 fg bg 的0.5区分开,这个0.5是考虑是否对该box进行coord reg....训练fast-rcnn时,batch_size是128(不再是256),前景样本只占0.25(不再是0.5),前景样本要求的IoU变成0.5(不再是0.7),背景样本要求的IoU变成0.1到0.5之间(不再是0.3以下),bbox回归可以设置训练或不训练,仍然是只对前景样本训练。
test阶段:
# Testing options
## NMS threshold used on RPN proposals
__C.TEST.RPN_NMS_THRESH = 0.7
## Number of top scoring boxes to keep before apply NMS to RPN proposals
__C.TEST.RPN_PRE_NMS_TOP_N = 6000
# 现在进行 NMS...
## Number of top scoring boxes to keep after applying NMS to RPN proposals
__C.TEST.RPN_POST_NMS_TOP_N = 300
# Proposal height and width both need to be greater than RPN_MIN_SIZE (at orig image scale)
__C.TEST.RPN_MIN_SIZE = 16
# Overlap threshold used for non-maximum suppression (suppress boxes with
# IoU >= this threshold)
__C.TEST.NMS = 0.3 # detector 完了之后再最后来一次NMS,剔除一些冗余的检测~test阶段主要是RPN网络的设置会有一些不同,NMS的阈值还是0.7,不过NMS前后保留的anchor变成了6000和300,当输出300个proposal之后,再进行一次阈值比较低的NMS(0.3),进一步过滤候选框。之后将候选框输入到fast-rcnn里,regression subnet算出每个ROI的坐标调整量,对输出的坐标进行一个调整,同时classification subnet进行分类。
参考:https://zhuanlan.zhihu.com/p/49897496
SSD
ssd是one-stage算法,不再有RPN这种网络的训练。而是直接进入到最终的多类别分类+bbox回归。
注意这里的分类类别是c+1,+1是表示背景样本种类。N是成功匹配gt的生成的候选框的数量(如果N=0,设置loss为0),即只有当有成功匹配gt的候选框时才会进行优化。alpha参数用于调整回归和分类loss的权重,文中使用交叉验证法时将alpha设置为1。
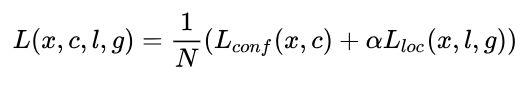
对于候选框坐标的回归方法,与faster-rcnn的方法和公式类似。


多分类loss(置信度loss)如下,其中c是类别置信度预测值,为softmax计算得到的值。

SSD训练时对anchors进行了hard negative mining,先统计前景样本的个数n,再从anchors中按照置信度loss选出3*n个背景样本,这里的置信度loss就是softmax分类loss,不过是针对背景样本的(分类实际上做的是c+1分类,包括分类为背景样本),softmax的输出是类别概率值,是背景样本的概率越小(实际上本身通过IoU判断出是背景样本),则背景样本置信度loss就大,这些就是难以被区分的背景样本,使用这些hard样本对分类subnet的训练影响更大。
在test过程中,每一个feature map的multibox layer直接输出box,将所有feature map的box合在一起进行总的nms,获得检测框结果。
RetinaNet
SSD的head和subnet与Faster-RCNN的RPN类似,RetinaNet的分类subnet和回归subnet不再共用3*3卷积层,而是各自使用了4个3*3卷积层加3*3的卷积输出层(filter个数和输出变量数量相同)。
RetinaNet在one-stage算法上迈出重大一步,即提出了focal loss作为分类loss用于解决正负样本不均衡问题。bbox的回归仍然使用smooth L1 loss。
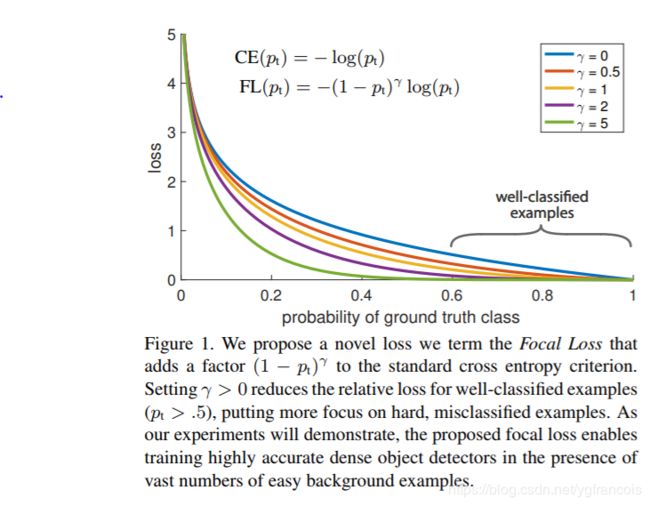

针对class imbalance的常用方法是用一个权重参数α∈[0,1]对于类1,1-α对于类-1。实际应用上,α一般被设定为类频率的逆或者作为超参数,通过交叉验证设定。为了标记方便,定义αt,相似的定义Pt。文中使用α balanced focal loss,比裸focal loss效果好些。文中α=0.25,γ=2效果最好。
在训练过程中,将与anchor IoU最大(在IoU>0.5前提下)的gt的label 赋给anchor,IoU<0.4的设置为背景样本,0.4
对class subnet进行训练时,由于Focal Loss的优越性,不再像SSD需要使用hard negative mining,而是将用IoU过滤过的所有anchors输入分类网络进行训练(不像Faster-RCNN一样需要进行NMS)。对于分类,这里虽然是多分类任务,但是使用了多个sigmoid,而不是softmax。
对于regression subnet,输入也是同样的anchors,使用的仍然是smooth L1 Loss,不过当anchor是背景样本时,loss会被抑制。
在inference过程中,为了提速,在每个FPN level上,将置信度小于0.05的anchor去除,然后选择1k top-scoring的box,最后将所有feature map level的box合并一起进行NMS(阈值为0.5)输出最终的box。
RefineDet
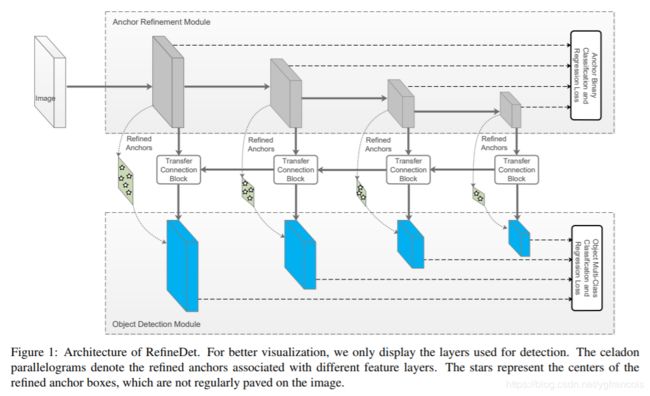
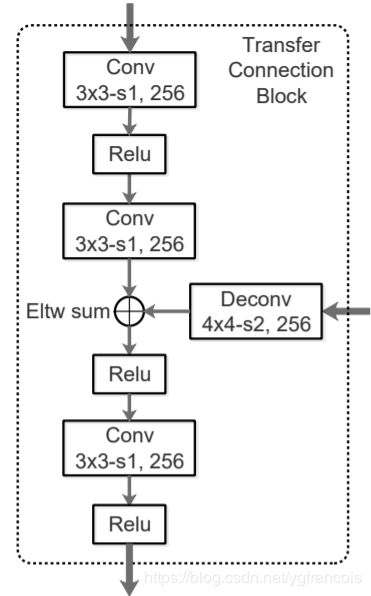
RefineDet融合了Faster-RCNN两步式的方法,和SSD bottom-up的anchor生成方法,并在ARM(anchor refinement module第一个ssd)做粗略的anchor refine和二分类区分前景背景,在ODM(object detection module)里输入refined anchor,做精细的回归和多分类。同时结合了FPN网络的特性,ODM从ARM继承的特征使用了top-down的形式。
Loss Function如下,虽然是两步的方法,但是训练确实一体的。

对于ARM,参与anchor提取的4个feature map,每个anchor单元(单元数量不再对应pixel数量,而是有一个stride)提取3个anchor(3种ratio,scale根据层固定,是每层stride的4倍),每个anchor预测4个offsets值和2个confidence score,分别对应smooth L1 loss和cross entropy loss。训练过程会先对所有anchor通过IoU分类(最高IoU的anchor和IoU超过0.5的anchor被作为前景样本),然后使用hard negative mining选取负样本(3:1,且负样本按loss排列)
对于ODM,4个feature层由ARM对应的feature map通过FPN传过来,输入的anchor是由ARM过滤过的anchor,即refined positive anchor,refined hard negative anchor,对于refined hard negative anchor,在传入ODM之前还要去除置信度过高的box,文中设置该阈值为0.99。对于分类使用softmax loss,回归仍然是smooth L1 loss。
Inference过程中,ARM先通过分类选出需要被refine的box,包括positive anchor和hard negative anchor(confidence score>0.99),然后对这些anchor进行refine(location和size)获得refined anchor。然后ODM使用这些anchor最为输入,获取置信度最高的400个detections(同时做location和size的二次修正),然后对这400个detection进行分类NMS,即对每种类别分别设置阈值为0.45的NMS,分类别做NMS可以防止重叠较大的两种不同object被NMS抑制掉。NMS后剩200个high confident detections。
其他
UnitBox在DenseBox的基础上,将框回归的L2 loss改成了IoU loss。L2 loss可能导致某一个坐标特别接近真实值,而另几个则效果不好。
localization的改进
1. bounding box refinement
在RPN类似网络选择proposal时,需要设置IoU阈值来选前景样本(训练阶段有,inference阶段由于没有gt所以不存在这个步骤,于是训练的好坏会直接影响最后生成的proposal质量,如果IoU太低会导致生成的proposal质量低,如果IoU太高会导致生成的proposal过拟合且出现mismatch)
Cascade RCNN为了解决这个问题尝试了设置多个IoU阈值(0.5,0.6,0.7),级联递进的方法。详见:https://blog.csdn.net/qq_21949357/article/details/80046867
2. 改进Loss Function:传统的坐标regression loss并不总能奏效,因为越低的regression error并不代表越大的IoU,特别是当目标有一个 large aspect ratio时。另外传统的regression方法没有提供localization的confidence,当邻近物体比较多时,很难是NMS handle这个问题。
UnitBox里使用IoU loss替代了L2 loss改进候选框位置回归:Liou = 1 - IoU
GIou loss比IoU loss的效果更好:Lgiou = 1 - GIoU,其中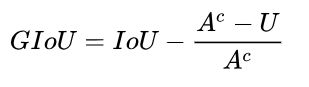 ,Ac是包围候选框和gt的最小矩形框的面积,U是候选框和gt的并集面积。
,Ac是包围候选框和gt的最小矩形框的面积,U是候选框和gt的并集面积。
IoU-guided NMS:传统的NMS只考虑了分类置信度,如Faster-RCNN用在RPN网络里,是将anchors按照前景分数从大到小排列后进行NMS,这个过程中并没有用到定位信息。IoU-Net同时考虑定位置信度,实际上就是在NMS的过程中,将候选框按照定位置信度,即IoU的值从大到小排列,再进行NMS,不过在进行NMS的过程中,会对分类置信度做一个调整:NMS会剔除几个IoU非极大值,但是在这些IoU非极大值对应的候选框中,可能会有某些候选框的分类置信分比IoU极大值对应的候选框的分类置信分大,就将这个分类置信分赋值给该IoU极大值对应的候选框。相当于以定位置信度为标准,同时保留分类置信度的效果。
probabilistic inference framework:
多尺度问题
context priming
pretraining的作用/training from scratch
之前大部分的任务的backbone都使用了在large scale数据集(如ImageNet)上pre-trained模型,但实际上,这种预训练也是有局限的。最主要的问题是,预训练做的是分类任务,和object detection不一样,包括他们的loss functions 和 scale/category distributions,分类任务对目标的位置不敏感,而检测任务当图像翻转后输出的结果不一样,之前的backbone里也提到,并不是分类任务上表现好,检测任务就一定好。同时,使用预训练模型无法随意修改网络。另外,预训练基于的训练集一般是RGB数据集,难以在RGB-D任务或3D数据集上得到沿用。
Kaiming大神在 “Rethinking imagenet pre-training”里比较了随机初始化参数和使用pre-trained模型的区别,发现不使用预训练模型得到的accuracy也不差,甚至更好。所以预训练参数只是加速了模型训练的收敛,毕竟预训练也是要花时间的,这里只是使用迁移学习节约了时间,但是对精度反而可能是负作用。
为了training from scratch能收敛,需要加一些trick,例如Dense connection和Batch Normalization。
加速方法
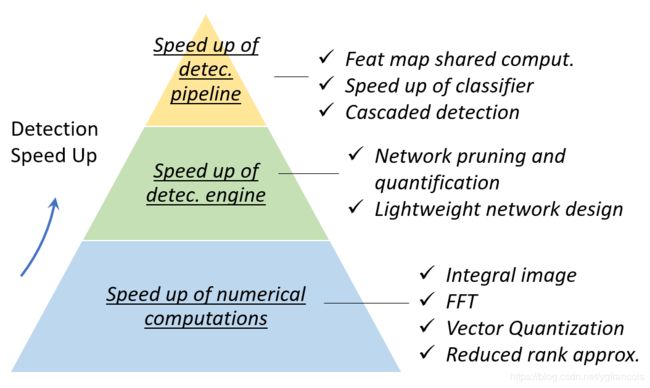
- Feature Map Shared Computation:特征图共享
- Speed up of Classifiers:替换SVM类的核方法分类器
- Cascaded Detection:如人脸识别里的MTCNN,级联方法除了可以加速之外,也可以用于选取hard example、生成上下文信息、和提升localization accuracy。
- Network Pruning and Quantification:剪枝、量化和蒸馏,这是所有深度学习任务通用的加速方法。剪枝和量化见https://blog.csdn.net/ygfrancois/article/details/86716811#%E5%8F%82%E6%95%B0%E9%87%8F%E5%8C%96,知识蒸馏是指在一个训练好的复杂的网络基础上,使用其output训练出多个student简单网络,详见https://zhuanlan.zhihu.com/p/24337627。
- Lightweight Network Design
 除以上图中方法外,还有Bottle-neck Design,Neural Architecture Search等方法。
除以上图中方法外,还有Bottle-neck Design,Neural Architecture Search等方法。 - Numerical Acceleration
用segmentation改进detection任务
segmentation可以改进Detection任务的原因:
- helps category recognition:同种物体是有特定形状的,segmentation往往能反应出object的形状特征。
- helps accurate localization:直觉上,人的视觉是直接识别出物体的位置和形状,而不是识别出一个框。对于特殊形状如扁长型,box的localization回归比较难,segmentation可以提供帮助。
- Segmentation can be embedded as context:分割方法可以引入上下文因素,object的背景会有天空、水面、草地、墙面等,如对飞机的检测,引入天空的上下文,会有助于其分类。
加入segmentation的方法:
- Learning with enriched features:加一个segmentation特征提取网络提取特征后融入原有网络,这种方法会带来额外计算量。
- Learning with multi-task loss functions:代表性网络就是mask-RCNN,与原来的网络共用特征提取网络,额外增加一个segmentation head,训练的时候将segmentation loss加入总loss一起训练,如果任务不需要segmentation,inference阶段再将segmentation branch抑制,不会影响速度。但是这种方法需要有segmentation标注的图片。