深度学习各种优化算法(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
標準梯度下降法:
彙總所有樣本的總誤差,然後根據總誤差更新權值
SGD隨機梯度下降:
mini batch代替全部樣本
曲面的某個方向更加陡峭的時候會被困住
Xt+1=Xt-α Δf(x1)
隨機抽取一個樣本誤差,然後更新權值 (每個樣本都更新一次權值,可能造成的誤差比較大)
批量梯度下降法:相當於前兩種的折中方案,抽取一個批次的樣本計算總誤差,比如總樣本有10000個,可以抽取1000個作爲一個批次,然後根據該批次的總誤差來更新權值。(常用)
momentum:
當前權值的改變會收到上一次權值的改變的影響,就像小球滾動時候一樣,由於慣性,當前狀態會受到上一個狀態影響,這樣可以加快速度。
SGD+momentum:
保持速度,不斷用梯度對其進行更新。利用摩擦係數使得速度慢慢減小,直到停在極小值點。相當於梯度的平滑移動。

Nesterov momantum:
包含當前速度和先前速度的誤差修正,加入權重化的速度差
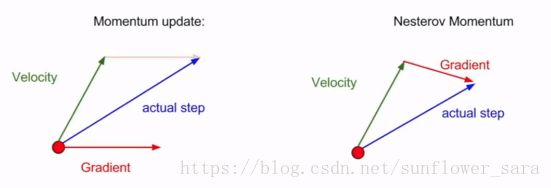

NAG(Nesterov Accelerated gradient)
與momentum相比,它更爲聰明,因爲momentum是一個路癡,它不知道去哪裏,而NAG則知道我們的目標在哪裏。也就是NAG知道我們下一個位置大概在哪裏,然後提前計算下一個位置的梯度。然後應用於當前位置指導下一步行動。
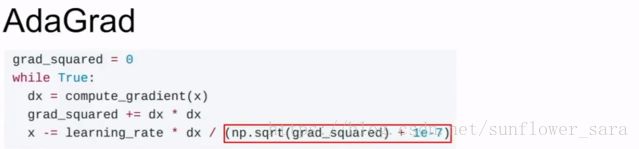
AdaGrad:
核心思想是對於常見的數據給予比較小的學習率去調整參數,對於不常見的數據給予比較大的學習率調整參數。它可以自動調節學習率,但迭代次數多的時候,學習率也會下降。
累加梯度的平方和再除掉
減慢大梯度方向的改變,加大小梯度方向的進步,自動調節學習率
但是時間太長的話,會造成步長太小,困在局部極值點
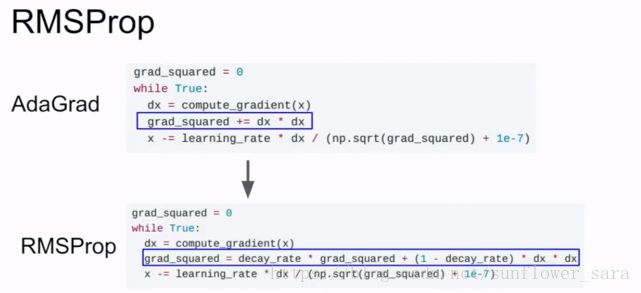
RMSprob :
採用前t-1次梯度平方的平均值 加上當前梯度的平方 的和再開放作爲分母
梯度平方+衰減,不會最後步長太小 &動量法 梯度+衰減
Adadelta :
不使用學習率
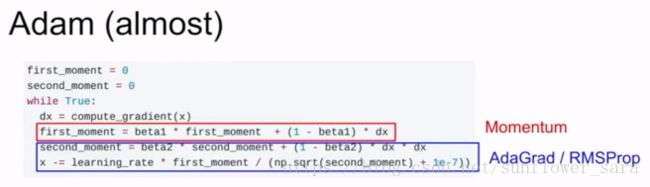
Adam :
會把之前衰減的梯度和梯度平方保存起來,使用RMSprob,Adadelta相似的方法更新參數
動量法+ Bias correct(動量的基於時間的無偏估計)+ RMSprob

深度學習筆記:優化方法總結(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
https://blog.csdn.net/u014595019/article/details/52989301
深度學習最全優化方法總結比較(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
https://blog.csdn.net/u012759136/article/details/52302426
Tensorflow的優化器比較
https://blog.csdn.net/qq_39422642/article/details/77471335
關於深度學習優化器 optimizer 的選擇,你需要了解這些
https://blog.csdn.net/g11d111/article/details/76639460
在很多機器學習和深度學習的應用中,我們發現用的最多的優化器是 Adam,爲什麼呢?
下面是 TensorFlow 中的優化器,
https://www.tensorflow.org/api_guides/python/train
在 keras 中也有 SGD,RMSprop,Adagrad,Adadelta,Adam 等:
https://keras.io/optimizers/
我們可以發現除了常見的梯度下降,還有 Adadelta,Adagrad,RMSProp 等幾種優化器,都是什麼呢,又該怎麼選擇呢?
在 Sebastian Ruder 的這篇論文中給出了常用優化器的比較,今天來學習一下:
https://arxiv.org/pdf/1609.04747.pdf
本文將梳理:
- 每個算法的梯度更新規則和缺點
- 爲了應對這個不足而提出的下一個算法
- 超參數的一般設定值
- 幾種算法的效果比較
- 選擇哪種算法
優化器算法簡述?
首先來看一下梯度下降最常見的三種變形 BGD,SGD,MBGD,
這三種形式的區別就是取決於我們用多少數據來計算目標函數的梯度,
這樣的話自然就涉及到一個 trade-off,即參數更新的準確率和運行時間。
1.Batch gradient descent
梯度更新規則:
BGD 採用整個訓練集的數據來計算 cost function 對參數的梯度:
θ=θ−α∇θJ(θ)θ=θ−α∇θJ(θ)
缺點:
由於這種方法是在一次更新中,就對整個數據集計算梯度,所以計算起來非常慢,遇到很大量的數據集也會非常棘手,而且不能投入新數據實時更新模型
我們會事先定義一個迭代次數 epoch,首先計算梯度向量 params_grad,然後沿着梯度的方向更新參數 params,learning rate 決定了我們每一步邁多大。
Batch gradient descent 對於凸函數可以收斂到全局極小值,對於非凸函數可以收斂到局部極小值。
-
2. Stochastic gradient descent
梯度更新規則:
和 BGD 的一次用所有數據計算梯度相比,SGD 每次更新時對每個樣本進行梯度更新, 對於很大的數據集來說,可能會有相似的樣本,這樣 BGD 在計算梯度時會出現冗餘, 而 SGD 一次只進行一次更新,就沒有冗餘,而且比較快,並且可以新增樣本。
缺點:
SGD 因爲更新比較頻繁,會造成 cost function 有嚴重的震盪,此外SGD對噪聲比較敏感。
BGD 可以收斂到局部極小值,當然 SGD 的震盪可能會跳到更好的局部極小值處。
當我們稍微減小 learning rate,SGD 和 BGD 的收斂性是一樣的。
3. Mini-batch gradient descent
梯度更新規則:
MBGD 每一次利用一小批樣本,即 n 個樣本進行計算, 這樣它可以降低參數更新時的方差,收斂更穩定, 另一方面可以充分地利用深度學習庫中高度優化的矩陣操作來進行更有效的梯度計算。
和 SGD 的區別是每一次循環不是作用於每個樣本,而是具有 n 個樣本的Batch。
超參數設定值:
n 一般取值在 50~200
缺點:
Mini-batch gradient descent 不能保證很好的收斂性,
①learning rate 如果選擇的太小,收斂速度會很慢,如果太大,loss function 就會在極小值處不停地震盪甚至偏離。
②有一種措施是先設定大一點的學習率,當兩次迭代之間的變化低於某個閾值後,就減小 learning rate,不過這個閾值的設定需要提前寫好,這樣的話就不能夠適應數據集的特點。此外,這種方法是對所有參數更新時應用同樣的 learning rate,如果我們的數據是稀疏的,我們更希望對出現頻率低的特徵進行大一點的更新。
③另外,對於非凸函數,還要避免陷於局部極小值處,或者鞍點處,因爲鞍點周圍的error 是一樣的,所有維度的梯度都接近於0,SGD 很容易被困在這裏。
鞍點:一個光滑函數的鞍點鄰域的曲線,曲面,或超曲面,都位於這點的切線的不同邊。
例如這個二維圖形,像個馬鞍:在x-軸方向往上曲,在y-軸方向往下曲,鞍點就是(0,0)
爲了應對上面的三點挑戰就有了下面這些算法。
[應對挑戰 1]
4. Momentum(動量法)
SGD 在 ravinesravines 的情況下容易被困住, ravinesravines就是曲面的一個方向比另一個方向更陡,這時 SGD 會發生震盪而遲遲不能接近極小值:
梯度更新規則:
Momentum 通過加入 γvt−1γvt−1 ,可以加速 SGD, 並且抑制震盪
vt=γvt−1+α∇θJ(θ)vt=γvt−1+α∇θJ(θ)
θ=θ−vtθ=θ−vt
當我們將一個小球從山上滾下來時,沒有阻力的話,它的動量會越來越大,但是如果遇到了阻力,速度就會變小。
加入的這一項,可以使得梯度方向不變的維度上速度變快,梯度方向有所改變的維度上的更新速度變慢,這樣就可以加快收斂並減小震盪。
超參數設定值:
一般 γγ取值 0.9 左右。
缺點:
這種情況相當於小球從山上滾下來時是在盲目地沿着坡滾,如果它能具備一些先知,例如快要上坡時,就知道需要減速了的話,適應性會更好。
5. Nesterov accelerated gradient(NAG)
梯度更新規則:
用 θ−γvt−1θ−γvt−1來近似當做參數下一步會變成的值,則在計算梯度時,不是在當前位置,而是未來的位置上
vt=γvt−1+α∇θJ(θ−γvt−1)vt=γvt−1+α∇θJ(θ−γvt−1)
θ=θ−vtθ=θ−vt
超參數設定值:
γγ仍然取值 0.9 左右。
效果比較:
藍色是 Momentum 的過程,會先計算當前的梯度,然後在更新後的累積梯度後會有一個大的跳躍。
而 NAG 會先在前一步的累積梯度上(brown vector)有一個大的跳躍,然後衡量一下梯度做一下修正(red vector),這種預期的更新可以避免我們走的太快。
NAG 可以使 RNN 在很多任務上有更好的表現。
目前爲止,我們可以做到,在更新梯度時順應 loss function 的梯度來調整速度,並且對 SGD 進行加速。
我們還希望可以根據參數的重要性而對不同的參數進行不同程度的更新。
[應對挑戰 2]
6. Adagrad
這個算法就可以對低頻的參數做較大的更新,對高頻的做較小的更新,也因此,對於稀疏的數據它的表現很好,很好地提高了 SGD 的魯棒性,例如識別 Youtube 視頻裏面的貓,訓練 GloVe word embeddings,因爲它們都是需要在低頻的特徵上有更大的更新。
梯度更新規則:
θt+1,i=θt,i−αGt,ii+ϵ−−−−−−−√gt,iθt+1,i=θt,i−αGt,ii+ϵgt,i
其中gt,igt,i爲:t 時刻參數 θiθi的梯度;GtGt是個對角矩陣, (i,i) 元素就是 t 時刻參數 θiθi 的梯度gt,igt,i的平方和。
Adagrad 的優點是減少了學習率的手動調節
超參數設定值:
一般 η 就取 0.01。
缺點:
它的缺點是分母會不斷積累,這樣學習率就會收縮並最終會變得非常小。
7. Adadelta
這個算法是對 Adagrad 的改進,
Δθt=−αE[g2]t+ϵ−−−−−−−−√gtΔθt=−αE[g2]t+ϵgt
和 Adagrad 相比,就是分母的GG換成了過去的梯度平方E[g2]tE[g2]t的衰減平均值。
這個分母相當於梯度的均方根 root mean squared (RMS) ,所以可以用 RMS 簡寫:
Δθt=−αRMS[g]tgtΔθt=−αRMS[g]tgt
其中 E 的計算公式如下,t 時刻的依賴於前一時刻的平均和當前的梯度:
E[g2]t=γE[g2]t−1+(1−γ)g2tE[g2]t=γE[g2]t−1+(1−γ)gt2
梯度更新規則:
此外,還將學習率 αα換成了 RMS[Δθ]RMS[Δθ],這樣的話,我們甚至都不需要提前設定學習率了:
超參數設定值:
γ 一般設定爲 0.9,
7. RMSprop
RMSprop 是 Geoff Hinton 提出的一種自適應學習率方法。
RMSprop 和 Adadelta 都是爲了解決 Adagrad 學習率急劇下降問題的。
梯度更新規則:
RMSprop 與 Adadelta 的第一種形式相同:
E[g2]t=0.9E[g2]t−1+0.1g2tE[g2]t=0.9E[g2]t−1+0.1gt2
θt+1=θt−αE[g2]t+ϵ−−−−−−−−√gtθt+1=θt−αE[g2]t+ϵgt
超參數設定值:
Hinton 建議設定 γγ爲 0.9, 學習率 αα爲 0.001。
8. Adam
這個算法是另一種計算每個參數的自適應學習率的方法。目前在DL領域,是最常見的優化器。
除了像 Adadelta 和 RMSprop 一樣存儲了過去梯度的平方 vtvt 的指數衰減平均值 ,也像 momentum 一樣保持了過去梯度 mtmt的指數衰減平均值:
如果 mtmt和 vtvt 被初始化爲 0 向量,那它們就會向 0 偏置,所以做了偏差校正,
通過計算偏差校正後的 mt 和 vt 來抵消這些偏差:
梯度更新規則:
θt+1=θt−αvt+ϵ−−−−−√mtθt+1=θt−αvt+ϵmt
超參數設定值:
建議 β1 = 0.9,β2 = 0.999,ϵ = 10e−8
實踐表明,Adam 比其他適應性學習方法效果要好。
效果比較?
下面看一下幾種算法在鞍點和等高線上的表現: 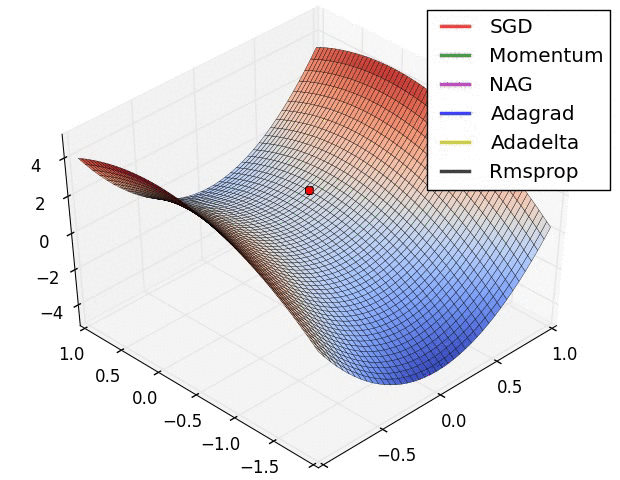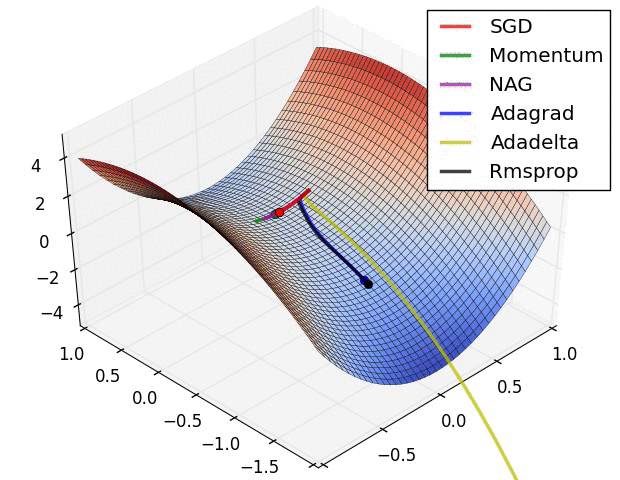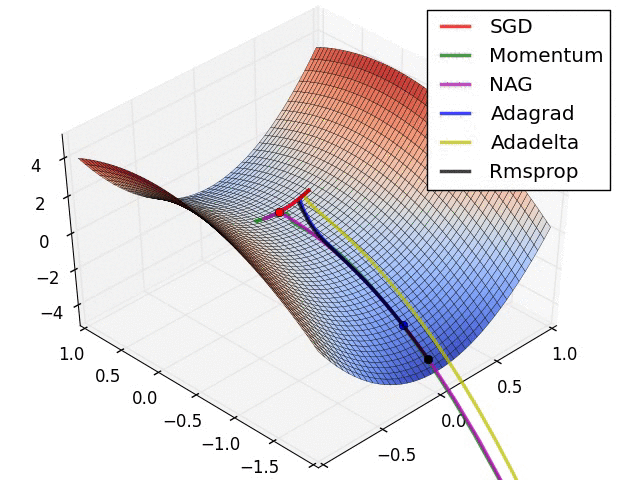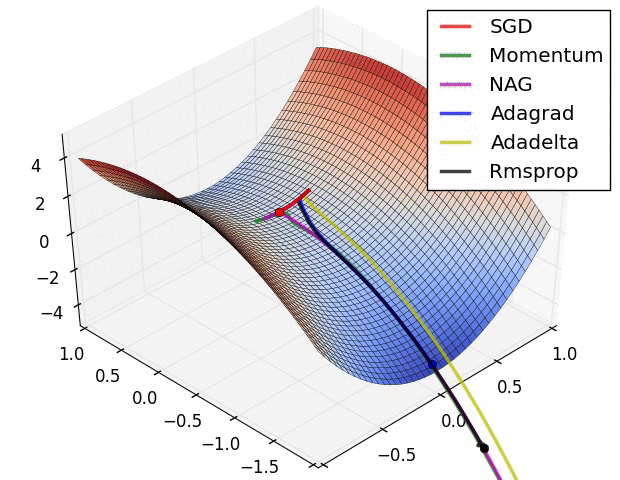
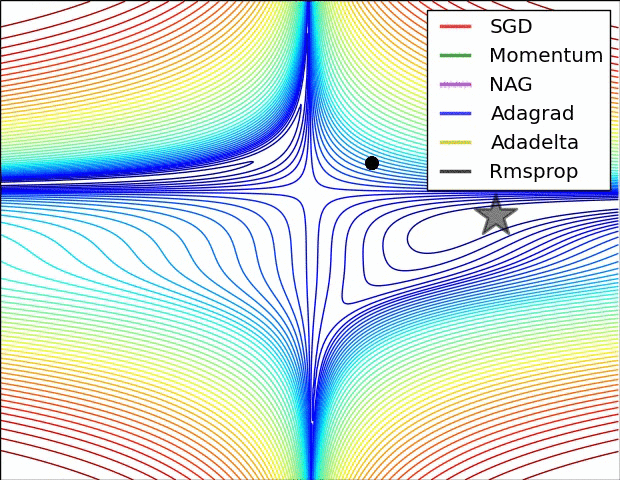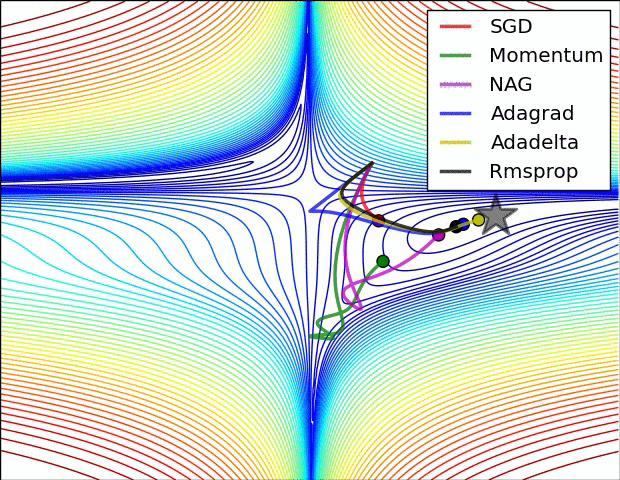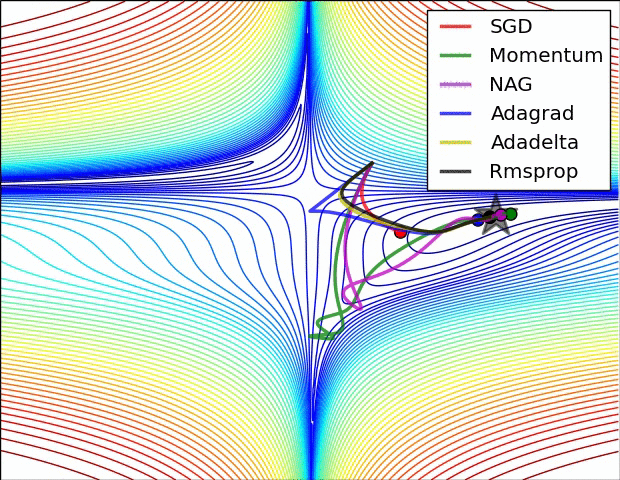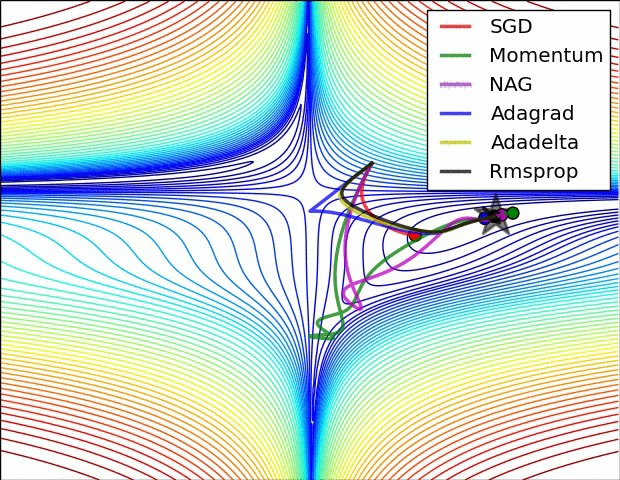
上面兩種情況都可以看出,Adagrad, Adadelta, RMSprop 幾乎很快就找到了正確的方向並前進,收斂速度也相當快,而其它方法要麼很慢,要麼走了很多彎路才找到。
由圖可知自適應學習率方法即 Adagrad, Adadelta, RMSprop, Adam 在這種情景下會更合適而且收斂性更好。
如何選擇?
如果數據是稀疏的,就用自適應方法,即 Adagrad, Adadelta, RMSprop, Adam。
RMSprop, Adadelta, Adam 在很多情況下的效果是相似的。
Adam 就是在 RMSprop 的基礎上加了 bias-correction 和 momentum。
隨着梯度變的稀疏,Adam 比 RMSprop 效果會好。
整體來講,Adam 是最好的選擇。
很多論文裏都會用 SGD,沒有 momentum 等。SGD 雖然能達到極小值,但是比其它算法用的時間長,而且可能會被困在鞍點。
如果需要更快的收斂,或者是訓練更深更復雜的神經網絡,需要用一種自適應的算法。
參考:
http://sebastianruder.com/optimizing-gradient-descent/index.html#fn:24
http://www.redcedartech.com/pdfs/Select_Optimization_Method.pdf
https://stats.stackexchange.com/questions/55247/how-to-choose-the-right-optimization-algorithm