MapReduce简介
继上一节的HDFS,这一节来学习并行计算框架MapReduce。
作为Hadoop的又一核心概念,HDFS解决了数据的存储的问题,而MapReduce自然解决的是并行计算的问题。
目录:
- Hadoop的优势与概念
- Map和Reduce函数
- MapReduce体系结构:Client,JobTracker, TaskTracke,Task
- 工作流程
- shuffle过程详解:Map和Reduce端各自的shuffle过程
- 应用程序执行过程
- 统计词频例子
- 总结
首先,相对于在此之前诸如MPI之类的并行计算框架,MapReduce有什么优势呢?
在集群架构上,传统框架大抵采用的是共享式(共享内存/存储),容错性低,而MapReduce就不共享。
传统计算框架采用刀片服务器、高速网等设备,价格昂贵,而MapReduce只需要普通的PC机就可以了,便宜,扩展性又好。
在适用场合上,传统并行计算框架适用于实时的、细粒度计算和计算密集型。但是MapReduce更适合批处理、非实时,数据密集型的计算。
MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce。
程序运行在分布式系统上,完成海量数据的计算。
MapReduce采用分而治之策略,一个存储在分布式文件系统中的大规模数据集,会被切分为许多独立的分片,这些分片可以被多个Map任务并行处理。
MapReduce设计的一个理念就是”计算向数据靠拢“,而不是”数据向计算靠拢“。因为移动数据需要大量的网络传输开销。
MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave。
Map和Reduce函数:
| 函数 | 输入 | 输出 | 说明 |
|---|---|---|---|
| Map | < K1,v1> 如:<行号,”abc”> |
List(< k2,v2>) 如:<”a”,1><”b”,1><”c”,1> |
对于每一个输入的键值对< k1,v1>都变成一批键值对 |
| Reduce | < k2,List(v2)> 如:< “a”, <1,1,1>> |
< k3, v3> 如:< “a”, 3> |
输入一个键值对,输出一批键值对 |
MapReduce的体系结构:
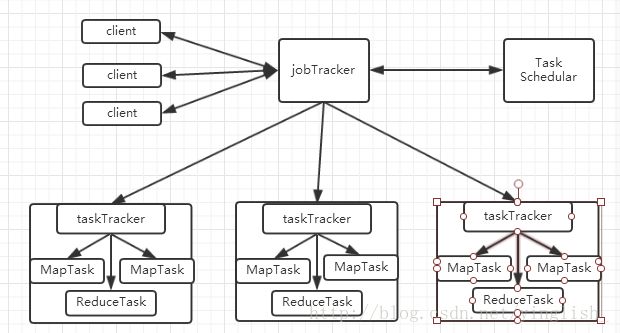
Client:用户编写的MapReduce程序通过Client提交到JobTracker端
JobTracker:负责资源控制和作业调度;负责监控所有TaskTracker与Job的健康状况,一旦出现失败,就把相应的任务转移到其他节点;JobTracker会跟踪任务的执行进度、资源使用量等信息,并把这些信息告诉任务调度器(TaskTracker),而调度器会在资源出现空闲的时候,选择合适的任务去使用这些资源。
TaskTracker:会周期地通过“心跳”将本节点上的资源使用情况和任务运行进度汇报给JobTracker,同时接收jobTracker发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)
TaskTracker使用”slot”(槽)等量划分本节点上的资源量(CPU、内存等)。一个Task获取到一个Slot后才有机会运行。而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为MapSlot和ReduceSlot,分别提供给mapTask和reduceTask使用。
Task:分为MapTask和ReduceTask两种,均有TaskTracker启动。
工作流程:
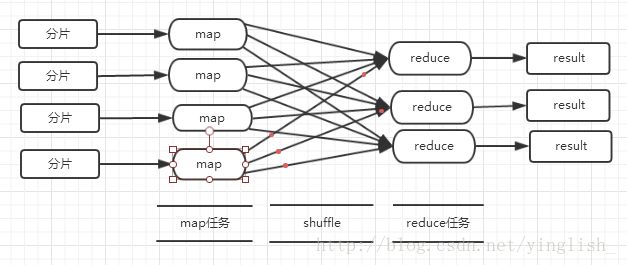
不同的Map/Reduce任务之间不会进行通信。
HDFS以固定大小的block为基本的单位存储数据 ,而对于MapReduce来讲,其处理单位是split。split是一个逻辑概念,它只包含一些元数据信息,比如数据起始位置、数据长度、数据所在节点等。它的划分方法完全由用户自己决定。block与split是两个不同的东西,但是为了减少寻址开销,我们一般一个分片就是一个block大小(一个分片也可以是一个半block,但是如果两个块不在同一个机架上,那么我们就需要去寻找另一台机子),split的多少就决定了map任务的数目。而reduce任务的数目取决于集群中可用的reduce任务槽(slot),通常设置比reduce任务槽数目少一点点的reduce任务个数,预留系统资源处理可能发生的错误。
shuffle过程详解:
在Hadoop这样的集群环境中,大部分的Map和Reduce任务是执行在不同节点上的,shuffle的过程就需要完整地从MapTask端拉取数据到Reduce端。在跨节点拉取数据的时候,我们当然希望能尽可能地减少对带宽的不必要消耗,减少IO对任务的影响。
Map端的shuffle过程:
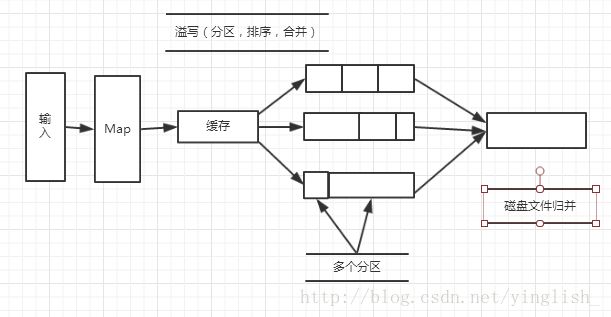
每个Map任务分配有一个缓存,默认是100MB,当Map任务的输出达到了溢写比例(一般为0.8)时,就会发生溢写操作:把缓存中数据写入磁盘。在写入的时候,会根据数据所在区分开(分区),再排序,如果用户有定义合并操作,还会进行合并。map任务全部结束之前会进入归并操作,归并成一个大文件,写入本地磁盘。举个例子来了解合并combine和归并merge的区别,两个键值对< “a”,1>< “a”,1>,进行合并操作,会得到< “a”, 2>,归并得到:< “a”, <1,1>>
reduce端的shuffle过程:
reduce任务通过RPC向JobTracker询问map任务是否已经完成,若完成,则领取数据,放入缓存,来自不同Map机器,先归并,多个溢写文件归并成一个或多个大文件,文件中的键值对是排序的,再合并,写入磁盘。当Map操作中的数据不多时,Map操作不需要溢写到磁盘,直接在缓存中归并,然后输出给Reduce。
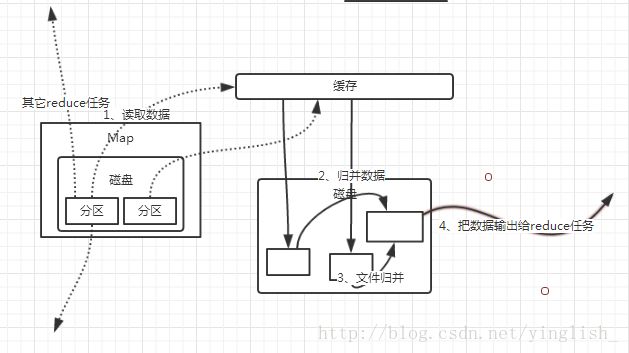

整个应用程序的执行过程如上:对于一个用户程序,主节点将为各个节点分配Map或者reduce任务,map节点一般从HDFS中获取数据,将其切分为分片,各节点读取各自的分片 ,计算后放入缓存,缓存渐渐满了后进行溢写操作(shuffle),溢写到本地磁盘上,Reduce节点再去远程读取数据,(shuffle)执行完操作后输出文件。
举一个统计词频的例子:
我们将文件处理为< indexOfLine, text>的键值对,经过Map操作后,一个键值对变成了多个:< aWord, 1>

在shuffle阶段,会进行分区、排序操作,如果没有定义合并,同一个键的值就不会计算。
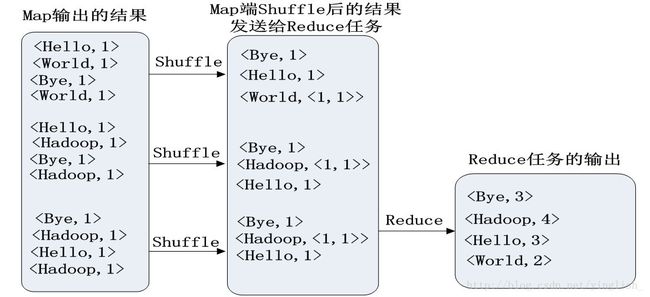
总结:
MapReduce将复杂的,运行于大规模集群上的并行计算过程高度抽象到了两个函数:Map和Reduce。
整个过程可以概括为:Map映射,Reduce归约。
具体过程为:从分布式文件系统中读入数据,执行Map任务输出中间结果,通过shuffle将中间结果分区排序整理后发送给Reduce任务,执行reduce任务后再将结果写入分布式文件系统。在这个过程中,Shuffle阶段非常关键。
但是我们也可以看到,两个子阶段严重地降低了Hadoop的性能:1、map阶段产生的结果要写入磁盘,虽然提高了系统的可靠性,但是增加了IO开销。2、shuffle阶段采用的是HTTP远程拷贝Map节点上的结果数据。