如何解决数据迁移和热点问题?
- 如何解决数据迁移和热点问题
- 1. 前言
- 2. 方案思路
- 3. 方案设计
- 4. 主流程
- 5. 如何扩容
- 6. 系统设计
1. 前言
上一篇文章 什么是数据库分库分表? 介绍了常规的分库分表的方案,各有优缺点:
-
hash取模方案:没有热点问题,但需要数据迁移。
-
range范围方案:不需要数据迁移,但有热点问题。
其实还有一个现实需求,能否根据服务器的性能以及存储高低,适当均匀调整存储呢?

2. 方案思路
hash是可以解决数据均匀的问题,range可以解决数据迁移问题,那我们可以不可以两者相结合呢?利用这两者的特性呢?
我们考虑一下数据的扩容代表着,路由key(如id)的值变大了,这个是一定的,那我们先保证数据变大的时候,首先用range方案让数据落地到一个范围里面。这样以后id再变大,那以前的数据是不需要迁移的。
但又要考虑到数据均匀,那是不是可以在一定的范围内数据均匀的呢?因为我们每次的扩容肯定会事先设计好这次扩容的范围大小,我们只要保证这次的范围内的数据均匀是不是就ok了。
[外链图片转存失败(img-IYg2fsLJ-1565765065322)(assets/640-1565763537250.webp)]
3. 方案设计
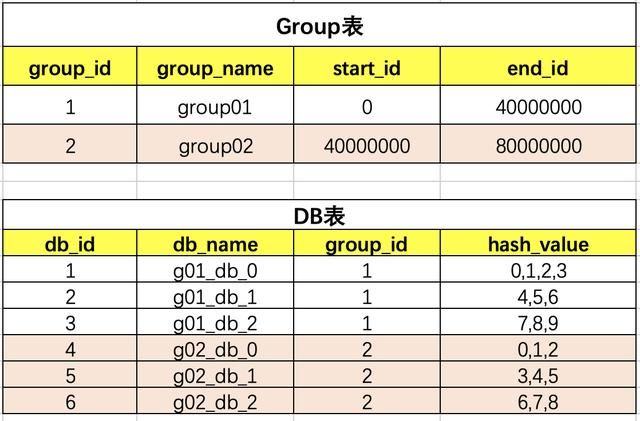
我们先定义一个group组概念,这组里面包含了一些分库以及分表,如下图

上图有几个关键点:
id=0~4000万肯定落到group01组中
group01组有3个DB,那一个id如何路由到哪个DB?
根据hash取模定位DB,那模数为多少?模数要为所有此group组DB中的表数,上图总表数为10。为什么要取表的总数?而不是DB总数3呢?
如id=12,id%10=2;那值为2,落到哪个DB库呢?这是设计是前期设定好的,那怎么设定的呢?
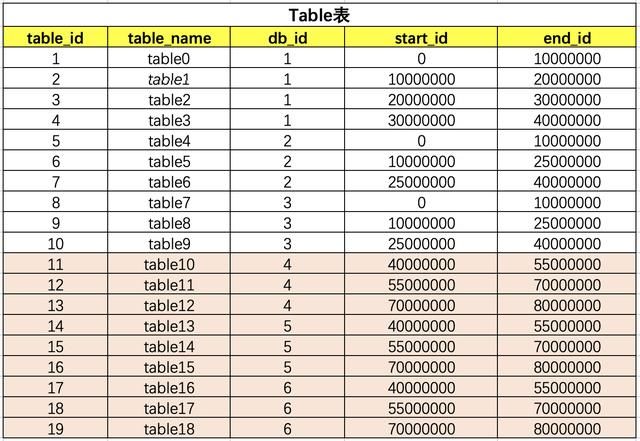
一旦设计定位哪个DB后,就需要确定落到DB中的哪张表呢?

4. 主流程
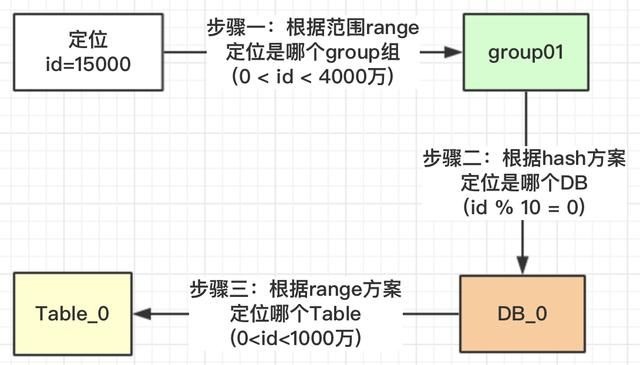
按照上面的流程,我们就可以根据此规则,定位一个id,我们看看有没有避免热点问题。
我们看一下,id在【0,1000万】范围内的,根据上面的流程设计,1000万以内的id都均匀的分配到DB_0,DB_1,DB_2三个数据库中的Table_0表中,为什么可以均匀,因为我们用了hash的方案,对10进行取模。
为什么对表的总数10取模,而不是DB的总数3进行取模?我们看一下为什么DB_0是4张表,其他两个DB_1是3张表?
在我们安排服务器时,有些服务器的性能高,存储高,就可以安排多存放些数据,有些性能低的就少放点数据。如果我们取模是按照DB总数3,进行取模,那就代表着【0,4000万】的数据是平均分配到3个DB中的,那就不能够实现按照服务器能力适当分配了。
按照Table总数10就能够达到,看如何达到

上图中我们对10进行取模,如果值为**【0,1,2,3】就路由到DB_0,【4,5,6】路由到DB_1,【7,8,9】路由到DB_2**。现在小伙伴们有没有理解,这样的设计就可以把多一点的数据放到DB_0中,其他2个DB数据量就可以少一点。DB_0承担了4/10的数据量,DB_1承担了3/10的数据量,DB_2也承担了3/10的数据量。整个Group01承担了【0,4000万】的数据量。
注意:小伙伴千万不要被DB_1或DB_2中table的范围也是0~4000万疑惑了,这个是范围区间,也就是id在哪些范围内,落地到哪个表而已。
上面一大段的介绍,就解决了热点的问题,以及可以按照服务器指标,设计数据量的分配。

5. 如何扩容
其实上面设计思路理解了,扩容就已经出来了;那就是扩容的时候再设计一个group02组,定义好此group的数据范围就ok了。

6. 系统设计

思路确定了,设计是比较简单的,就3张表,把group,DB,table之间建立好关联关系就行了。
group和DB的关系
table和db的关系
上面的表关联其实是比较简单的,只要原理思路理顺了,就ok了。小伙伴们在开发的时候不要每次都去查询三张关联表,可以保存到缓存中(本地jvm缓存),这样不会影响性能。

一旦需要扩容,小伙伴是不是要增加一下 group02 关联关系,那应用服务需要重新启动吗?
简单点的话,就凌晨配置,重启应用服务就行了。但如果是大型公司,是不允许的,因为凌晨也有订单的。那怎么办呢?本地jvm缓存怎么更新呢?
其实方案也很多,可以使用用zookeeper,也可以使用分布式配置,这里是比较推荐使用分布式配置中心的,可以将这些数据配置到分布式配置中心去。
到此为止,整体的方案介绍结束,希望对小伙伴们有所帮助。谢谢!!!
这边隐含了一个关键点,那就是路由key(如:id)的值是非常关键的,要求一定是有序的,自增的,这个就涉及到分布式唯一id的方案,下一篇文章会介绍如何设计一个分布式主键
整体的方案介绍结束,希望对小伙伴们有所帮助。谢谢!!!**
这边隐含了一个关键点,那就是路由key(如:id)的值是非常关键的,要求一定是有序的,自增的,这个就涉及到分布式唯一id的方案,下一篇文章会介绍如何设计一个分布式主键