3.zookeeper集群搭建
1.集群搭建说明
zookeeper集群的目的是为了保证系统的性能承载更多的客户端连接设专门提供的机制。通过集群可以实现以下功能:
- 读写分离:提高承载,为更多的客户端提供连接,并保障性能。
- 主从自动切换:提高服务容错性,部分节点故障不会影响整个服务集群。
半数以上运行机制说明:
集群至少需要三台服务器,并且强烈建议使用奇数个服务器。因为zookeeper 通过判断大多数节点的存活来判断整个服务是否可用。比如3个节点,挂掉了2个表示整个集群挂掉,而用偶数4个,挂掉了2个也表示其并不是大部分存活,因此也会挂掉。zk为了安全,必须达到多数仲裁。
多数仲裁的设计是为了避免脑裂(zk,已经采用了多数仲裁,所以不会出现),和数据一致性的问题 。
脑裂:由于网络延迟等各种因素,最终导致集群一分为二,各自独立运行(两个leader),集群就是坏的 。
2、集群搭建
这里搭建在同一台机器上是伪集群,如果分部在多个机器上,只需改zoo.cfg配置文件即可。
2.1、复制三份
cp -r zookeeper zookeeper2181
cp -r zookeeper zookeeper2182
cp -r zookeeper zookeeper2183
2.2、创建data目录,存储节点数据。
2.2.1、创建目录:
cd /usr/local/zookeeper/zookeeper2181/
mkdir data
cd /usr/local/zookeeper/zookeeper2182/
mkdir data
cd /usr/local/zookeeper/zookeeper2183/
mkdir data2.2.2、进入data目录中创建myid文件
#进入zookeeper2181中的data
echo 1 > myid
#进入zookeeper2182中的data
echo 2 > myid
#进入zookeeper2183中的data
echo 3 > myid2.2.3、编写zoo.cfg配置文件(如果是新下载的zookeeper,那么复制zoo_sample.cfg文件)
zookeeper2181
#zookeeper2181中 conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
# 数据快照文件所在路径
dataDir=/usr/local/zookeeper/zookeeper2181/data
# 服务器对应端口号
clientPort=2181
# 集群配置信息
# server:A=B:C:D
# A:是一个数字,表示这个是服务器的编号
# B:是这个服务器的ip地址
# C:Zookeeper服务器之间通信的端口(数据互通,必须的)
# D:Leader选举的端口
server.1=192.168.1.7:2881:3881
server.2=192.168.1.7:2882:3882
server.3=192.168.1.7:2883:3883
zookeeper2182
#zookeeper2182中 conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
# 数据快照文件所在路径
dataDir=/usr/local/zookeeper/zookeeper2182/data
# 服务器对应端口号
clientPort=2182
server.1=192.168.1.7:2881:3881
server.2=192.168.1.7:2882:3882
server.3=192.168.1.7:2883:3883zookeeper2183
#zookeeper2183中 conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
# 数据快照文件所在路径
dataDir=/usr/local/zookeeper/zookeeper2183/data
# 服务器对应端口号
clientPort=2183
server.1=192.168.1.7:2881:3881
server.2=192.168.1.7:2882:3882
server.3=192.168.1.7:2883:38832.3、启动集群
#在三个zookeeper的bin目录下,都执行该语句
./zkServer.sh start ../conf/zoo.cfg2.4、查看各个zookeeper状态
#在三个zookeeper的bin目录下,都执行该语句
./zkServer.sh status ../conf/zoo.cfg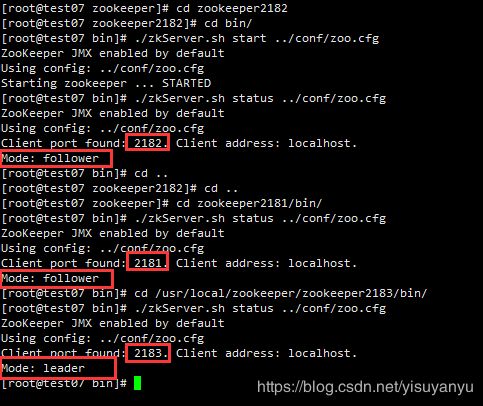
2.5、检查集群复制情况
#zookeeper2181的bin目录下
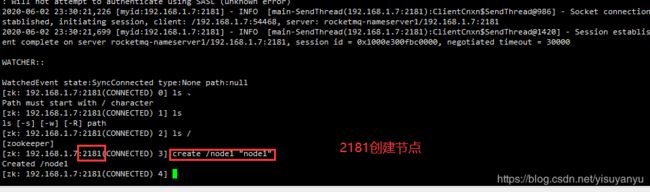
./zkCli.sh -server 192.168.1.7:2181
#zookeeper2182的bin目录下
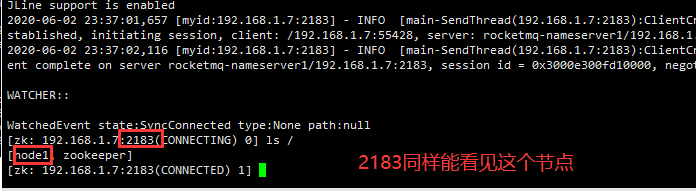
./zkCli.sh -server 192.168.1.7:2182
#zookeeper2183的bin目录下
./zkCli.sh -server 192.168.1.7:2183测试:在2181上创建一个节点,在2182上也能看到这个节点。

3.一致性协议——zab协议
3.1、zookeeper集群角色说明
zookeeper 集群中总共有三种角色,分别是leader(主节点)follower(子节点) observer(次级子节点)
| 角色 |
描述 |
| leader |
主节点,又名领导者。用于写入数据,通过选举产生,如果宕机将会选举新的主节点。 |
| follower |
子节点,又名追随者。用于实现数据的读取。同时他也是主节点的备选节点,并用拥有投票权。 |
| observer |
次级子节点,又名观察者。用于读取数据,与fllower区别在于没有投票权,不能选为主节点。并且在计算集群可用状态时不会将observer计算入内。只做数据读操作,不参与leader选举。 |
observer配置:
在集群中所有配置中加上observer后缀即可,示例如下:
server.3=192.168.1.7:2183:3883:observer
在zookeeper2183的配置文件中另外加上
peerType=observer
3.2、zookeeper集群通过zab实现数据一致性
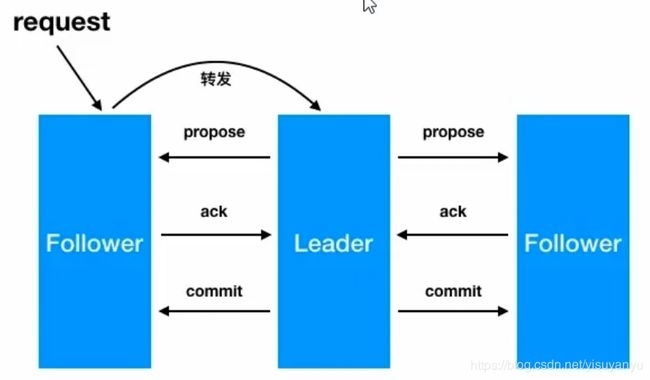
leader从客户端收到一个写请求(如果follwer接收客户端写请求,follower会转发给leader)leader生成一个新的事务并为这个事务生成一个唯一的ZXIDleader将事务提议(propose)发送给所有的follows节点follower节点将收到的事务请求加入到本地历史队列(history queue)中,并发送ack给leader,表示确认提议- 当
leader收到大多数follower(半数以上节点)的ack(acknowledgement)确认消息,leader会本地提交,并发送commit请求 - 当
follower收到commit请求时,从历史队列中将事务请求commit
3.3、leader的选举
3.3.1、服务器启动时的leader选举:
①每个server发出一个投票,由于是初始情况,server1和server2都会将自己作为leader进行投票,每次投票都会包含所推举的服务器的myid和zxid(事务id),使用(myid,zxid)表示,此时server1的投票为(1,0),server2的投票为(2,0),然后各自将投票发给集群中其他机器。
②集群中每台机器接受来自集群中各个服务器的投票。
③处理投票,针对每个投票,服务器都需要将别人的投票和自己的投票比较:
优先检查事务编号zxid,谁大谁优先。
如果zxid相同,比较myid,谁大谁优先。所以server2的myid大于server1的myid。
④统计投票,每次投票后服务器都会统计投票信息判断是否有半数机器接收到相同的投票信息,对于server1和server2而言都统计出集群中已经有两台机器接受了(2,0)的投票信息,因此便认为已经选出了leader
⑤改变服务器状态,一旦确定了leader,如果是follower就变为follew,leader就变为leadering。
3.3.2、服务器运行时的leader选举:
一旦leader机器故障后,整个集群将暂停服务重新选举
假设有2181、2182、2183,2182是leader
①变更状态,2181和2183变为looking,进入选举阶段。
②每个server都会投票给自己,例如2181投票给(1,5),1表示自己的myid,5表示事务id,2183投票(3,4)。
③接收来自各个服务器的投票,与启动时的投票类似
④处理投票,由于2181的zxid大于2183,所以2181成为leader
⑤统计投票,与启动时类似
⑥改变服务器状态,与启动时类似
3.4、java链接zookeeper集群
//连接集群
public static void main(String[] args) {
CountDownLatch countDownLatch=new CountDownLatch(1);
try{
ZooKeeper zooKeeper=new ZooKeeper("192.168.1.7:2181,192.168.1.7:2182,192.168.1.7:2183", 50000, new Watcher() {
@Override
public void process(WatchedEvent event) {
if(event.getState()== Watcher.Event.KeeperState.SyncConnected){
System.out.println("连接集群成功");
countDownLatch.countDown();
}
}
});
countDownLatch.await();
zooKeeper.close();
}catch (Exception e){
e.printStackTrace();
}
}