10.3应用:通过拆分-应用-联合
1.GroupBy方法最常见的目的是apply(应用)
如图10-1所示, apply将对象拆分成多块,然后在每一块上调用传递的函数,之后尝试将每一块拼接到一起

2.示例:小费数据集(见图10-2)

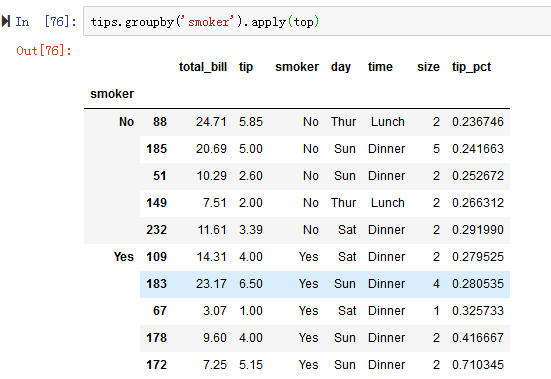
操作1:利用特定列中选出最大值所在行的函数,按组选出小费百分比(tip-pct)最高的五组(见图10-3)

操作2:按照smoker进行分组,之后调用apply(见图10-4)
注:DataFrame.apply(func,axis=0,broadcast=None,raw=False,reduce=None,result_type=None,args=(),**kwds)
Apply a function along an axis of the DataFrame.
补充说明:top函数在DataFrame的每一行分组上被调用,之后使用pandas. concat将函数结果粘贴在一起,并使用分组名作为各组的标签。因此结果包含一个分层索引,该分层索引的内部层级包含原DataFrame的索引值
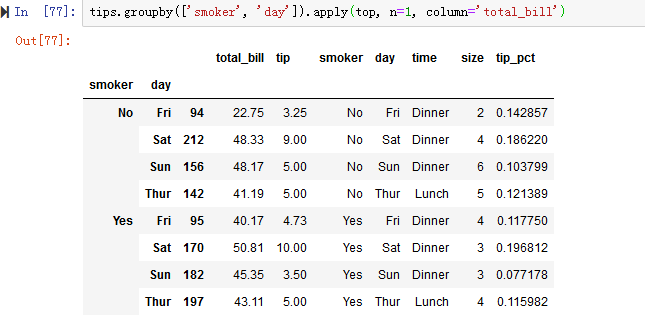
操作3:不仅向apply传递函数,还传递其他参数或关键字(见图10-5)
提示: 除了基础的使用机制,还需要一些创造力才能充分地使用apply
传递函数的内部发生的事情取决于你自己,函数只需要返回一个pandas对象或一个标量值。
本节后续主要讲解如何使用groupby解决多种问题,例如:在GroupBy对象上调用了describe方法(见图10-6)

10.3.1 GroupBy示例:压缩分组键
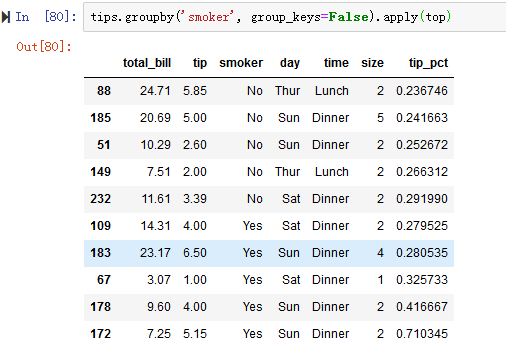
1.通过向groupby传递group_keys=False来禁用分层索引(见图10-8)
在之前的例子中,你可以看到所得到的对象具有分组键所形成的分层索引以及每个原始对象的索引(见图10-7)

10.3.2 GroupBy示例:分位数与桶分析
1.利用pandas一些工具,尤其是cut和qcut,与groupby方法一起使用这些函数可以对数据集更方便地进行分桶或分位分析
示例:一个简单的随机数据集和一个使用cut的等长桶分类(见图10-9)

注:pandas.cut(x,bins,right=True,labels=None,retbins=False,precision=3, include_lowest=False,duplicates='raise')
Bin values into discrete intervals.
2.cut返回的Categorical对象可以直接传递给groupby
示例:计算出data2列的一个统计值集合(见图10-10)

注:DataFrame.unstack(level=-1,fill_value=None)
Pivot a level of the (necessarily hierarchical) index labels, returninga DataFrame having a new level of column labels whose inner-most levelconsists of the pivoted index labels. If the index is not a MultiIndex,the output will be a Series (the analogue of stack when the columns arenot a MultiIndex).The level involved will automatically get sorted.
3.使用qcut计算出等大小的桶,传递labels=False来获得分位数数值(见图10-11)

注:pandas.qcut(x,q,labels=None,retbins=False,precision=3,duplicates='raise')
Quantile-based discretization function. Discretize variable into equal-sized buckets based on rank or based on sample quantiles.
10.3.3 GroupBy示例:使用指定分组值填充缺失值
1.使用单一修正值或来自于其他数据的值来输入(填充)到null值(NA)
示例:使用平均值来填充NA值(见图10-12)

注:DataFrame.fillna(value=None,method=None,axis=None,inplace=False, limit=None,downcast=None,**kwargs)
Fill NA/NaN values using the specified method
2.对数据分组后使用按组变化的填充值来输入(填充)到null值(NA)
对数据分组后使用apply和一个在每个数据块上都调用fillna的函数
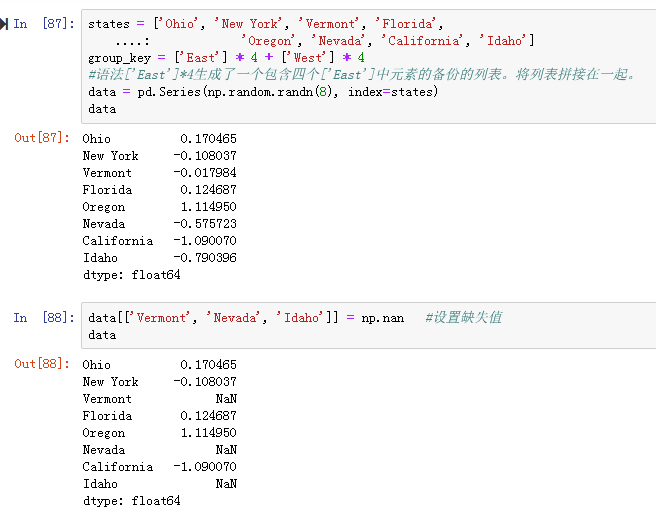
示例:对美国分为东部地区和西部地区的样本数据使用分组的平均值填充NA值(见图10-13,图10-14)
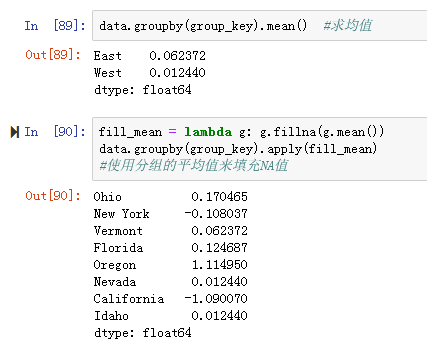
3.当数据分组时已经在代码中为每个分组预定义了填充值,利用每个分组都有一个内置的name属性(见图10-15)

10.3.4 GroupBy示例:随机采样与排列
1.“抽取”
使用Series的sample方法,从大数据集中抽取随机样本(有或没有替换)以用于蒙特卡罗模拟目的或某些其他应用程序
示例:构造一副英式扑克牌并加以抽取(见图10-16)

从每个花色中随机抽取两张牌(见图10-17)
由于花色是牌名的最后两个字符,我们可以基于这点进行分组,并使用apply

10.3.5 GroupBy示例:分组加权平均和相关性
1.在groupby的拆分-应用-联合的范式下,DataFrame的列间操作或两个Seriese之间的操作,可以做到分组加权平均
示例1:使用一个包含分组键和权重值的数据集分组加权平均(见图10-18)
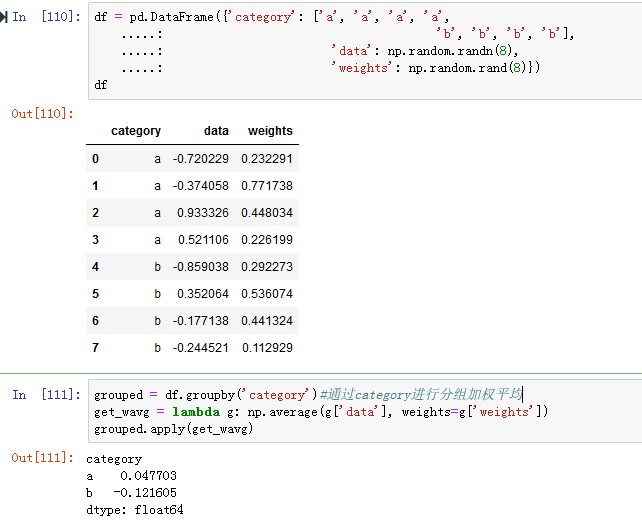
注:numpy.average(a,axis=None,weights=None,returned=False)
Compute the weighted average along the specified axis.
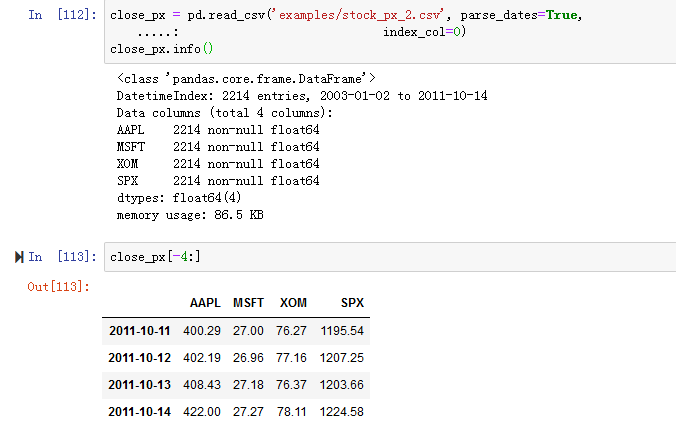
示例2:读入一个从雅虎财经上获得的数据集,该数据集包含一些标普500 (SPX符号)和股票的收盘价(见图10-19)
雅虎财经数据集请浏览:雅虎财经获得的数据集
https://github.com/wesm/pydata-book/blob/2nd-edition/examples/stock_px_2.csv
注:标准普尔500指数英文简写为S&P 500 Index,是记录美国500家上市公司的一个股票指数,为美国投资组合指数的基准
计算一个DataFrame,包含标普指数(SPX)每日收益的年度相关性(通过百分比变化计算)(见图10-20)

计算内部列相关性(见图10-21)

10.3.6 GroupBy示例:逐组线性回归
1.逐组线性回归
在与前一个示例相同的主题中,只要该函数返回一个pandas对象或标量值,就可以使用groupby执行更复杂的按分组统计分析
示例:定义regress(回归)函数(使用statsmodels计量经济学库),该函数对每个数据块执行普通最小二乘(OLS)回归,计算AAPL在SPX回报上的年度线性回归(见图10-22)
