记一次在deployment中添加灰度暂停功能
本文主要聊聊如何在k8s deployment中添加灰度暂停功能。因为是基于deployment原本支持的RollingUpdate更新方式 和 pause进行设计,所以文章中大篇幅会对deployment源码阅读分析。
k8s v1.16
deployment 目前处理逻辑
首先deployment是k8s暴露给用户的声明式API,用户通过定义spec(期待模板信息) 和 replicas(实例数)来告知期望状态, deploymentController作为控制循环将监听对应资源 尽力调整为用户期望状态。
k8s提供多种资源,各有特定的Controller,共同包含在kube-controller-manager组件中,运行在master节点上,与apiServer通信。
而驱动这些controller运作的重要部分为Informer,主要负责监听api-server的对象变化后同步到cache,并交给controller.queue去处理。
如何触发deployment更新流程
以下涉及到的主要结构体关系图大致如下
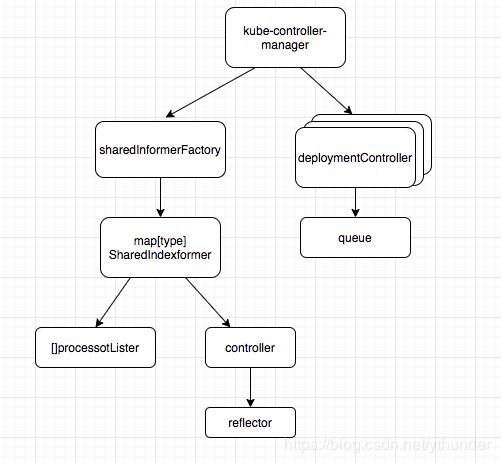
k8s的各组件使用Cobra库开发,入口为cmd/kube-controller-manager/controller-manager.go
command := app.NewControllerManagerCommand()
logs.InitLogs()
defer logs.FlushLogs()
if err := command.Execute(); err != nil {
os.Exit(1)
}
初始化command后,command.Execute()将执行command.Run定义的方法,Run的部分代码如下:
if err := StartControllers(controllerContext, saTokenControllerInitFunc, NewControllerInitializers(controllerContext.LoopMode), unsecuredMux); err != nil {
klog.Fatalf("error starting controllers: %v", err)
}
controllerContext.InformerFactory.Start(controllerContext.Stop)
close(controllerContext.InformersStarted)
以上,主要调用三个函数,调用顺序依次为NewControllerInitializers()、StartControllers、InformerFactory.Start,逐个看下:
//step1:
// NewConrollerInitializers返回map[Type]ControllerFunc,包含所有类型控制器启动func
// step2:
// 依次为每个类型调用启动每个类型的Controller,以下为deployment的
func startDeploymentController(ctx ControllerContext) (http.Handler, bool, error) {
dc, err := deployment.NewDeploymentController(
ctx.InformerFactory.Apps().V1().Deployments(),
ctx.InformerFactory.Apps().V1().ReplicaSets(),
ctx.InformerFactory.Core().V1().Pods(),
ctx.ClientBuilder.ClientOrDie("deployment-controller"),
)
go dc.Run(int(ctx.ComponentConfig.DeploymentController.ConcurrentDeploymentSyncs), ctx.Stop)
return nil, true, nil
}
// step3
// 启动总的sharedInformerFactory
func (f *sharedInformerFactory) Start(stopCh <-chan struct{}) {
f.lock.Lock()
defer f.lock.Unlock()
for informerType, informer := range f.informers {
if !f.startedInformers[informerType] {
go informer.Run(stopCh)
f.startedInformers[informerType] = true
}
}
}
上面step2中,关于ctx.InformerFactory.Apps().V1().Deployments()的部分,将调用以下,返回类型为deploymentInformer:
func (v *version) Deployments() DeploymentInformer {
return &deploymentInformer{factory: v.factory, namespace: v.namespace, tweakListOptions: v.tweakListOptions}
}
外层NewDeploymentController又调用以下,
dInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: dc.addDeployment,
UpdateFunc: dc.updateDeployment,
// This will enter the sync loop and no-op, because the deployment has been deleted from the store.
DeleteFunc: dc.deleteDeployment,
})
// 这两个都是func。
dc.syncHandler = dc.syncDeployment
dc.enqueueDeployment = dc.enqueue
先看Informer函数
// 以下为多层嵌套调用,不是顺序调用
//调用InformerFor(),第一个参数为Deployment类型对象,第二个参数调用defaultInformer
func (f *deploymentInformer) Informer() cache.SharedIndexInformer {
return f.factory.InformerFor(&appsv1.Deployment{}, f.defaultInformer)
}
// defaultInformer()调用NewFilteredDeploymentInformer
func (f *deploymentInformer) defaultInformer(client kubernetes.Interface, resyncPeriod time.Duration) cache.SharedIndexInformer {
return NewFilteredDeploymentInformer(client, f.namespace, resyncPeriod, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc}, f.tweakListOptions)
}
// NewFilteredDeploymentInformer返回sharedIndexInformer类型,包括ListFunc、WatchFun的初始化
func NewFilteredDeploymentInformer(client kubernetes.Interface, namespace string, resyncPeriod time.Duration, indexers cache.Indexers, tweakListOptions internalinterfaces.TweakListOptionsFunc) cache.SharedIndexInformer {
return cache.NewSharedIndexInformer(
&cache.ListWatch{
ListFunc: func(options metav1.ListOptions) (runtime.Object, error) {
if tweakListOptions != nil {
tweakListOptions(&options)
}
return client.AppsV1().Deployments(namespace).List(options)
},
WatchFunc: func(options metav1.ListOptions) (watch.Interface, error) {
if tweakListOptions != nil {
tweakListOptions(&options)
}
return client.AppsV1().Deployments(namespace).Watch(options)
},
},
&appsv1.Deployment{},
resyncPeriod,
indexers,
)
}
//InformerFor接受第一个参数类型(例如Deployment),第二个参数newFunc(创建cache.SharedIndexInformer)。
// 功能为 根据newFunc为Deployment创建特有的SharedIndexInformer,并将Map对应存入sharedInformerFactoy.informers
func (f *sharedInformerFactory) InformerFor(obj runtime.Object, newFunc internalinterfaces.NewInformerFunc) cache.SharedIndexInformer {
f.lock.Lock()
defer f.lock.Unlock()
informerType := reflect.TypeOf(obj)
informer, exists := f.informers[informerType]
if exists {
return informer
}
resyncPeriod, exists := f.customResync[informerType]
if !exists {
resyncPeriod = f.defaultResync
}
informer = newFunc(f.client, resyncPeriod)
f.informers[informerType] = informer
return informer
}
再看下AddEventHandler(),将调用AddEventHandlerWithResyncPeriod
// 如下,在Informer初始化时,已经向 sharedIndexInformer.processor.listeners[]中添加了回调函数
func (s *sharedIndexInformer) AddEventHandlerWithResyncPeriod(handler ResourceEventHandler, resyncPeriod time.Duration) {
// 将返回processorListener,其中p.handler为参数几种回调函数(AddFunc/DeleteFunc/UpdateFunc)
listener := newProcessListener(handler, resyncPeriod, determineResyncPeriod(resyncPeriod, s.resyncCheckPeriod), s.clock.Now(), initialBufferSize)
s.processor.addListener(listener)
}
上面step2中,下一步是dc.Run,主要代码为
for i := 0; i < workers; i++ {
go wait.Until(dc.worker, time.Second, stopCh)
}
dc.worker调用以下
func (dc *DeploymentController) processNextWorkItem() bool {
key, quit := dc.queue.Get()
if quit {
return false
}
defer dc.queue.Done(key)
err := dc.syncHandler(key.(string))
dc.handleErr(err, key)
return true
}
关于Informer启动
最后看下step3中的sharedInformerFactory.Start(),会对每个informer执行Run()。这里涉及到Informer的结构与功能
func (s *sharedIndexInformer) Run(stopCh <-chan struct{}) {
//step1. 初始化sharedIndexInformer.Controller
fifo := NewDeltaFIFO(MetaNamespaceKeyFunc, s.indexer)
cfg := &Config{
Queue: fifo,
ListerWatcher: s.listerWatcher,
ObjectType: s.objectType,
FullResyncPeriod: s.resyncCheckPeriod,
RetryOnError: false,
ShouldResync: s.processor.shouldResync,
Process: s.HandleDeltas,
}
func() {
s.controller = New(cfg)
s.controller.(*controller).clock = s.clock
s.started = true
}()
processorStopCh := make(chan struct{})
var wg wait.Group
defer wg.Wait() // Wait for Processor to stop
defer close(processorStopCh) // Tell Processor to stop
// step2. 执行启动mutationDetector.Run,以processorStopCh为退出标志
wg.StartWithChannel(processorStopCh, s.cacheMutationDetector.Run)
// step3. 执行processor.Run,以processorStopCh为退出标志
wg.StartWithChannel(processorStopCh, s.processor.run)
defer func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.stopped = true // Don't want any new listeners
}()
// step4. 执行启动controller.Run, 以stopCh为退出标志
s.controller.Run(stopCh)
}
先看step1,初始化sharedIndexInformer.controller
// keyFunc()参数为函数 根据对象返回ns/name信息
// knownObjects参数为informer.indexer 其初始化为NewIndexer(DeletionHandlingMetaNamespaceKeyFunc, indexers)将创建一个cache对象
/*
cache{
cacheStorage: NewThreadSafeStore(indexers, Indices{}),
keyFunc: keyFunc,
}
*/
func NewDeltaFIFO(keyFunc KeyFunc, knownObjects KeyListerGetter) *DeltaFIFO {
f := &DeltaFIFO{
items: map[string]Deltas{},
queue: []string{},
keyFunc: keyFunc,
knownObjects: knownObjects,
}
f.cond.L = &f.lock
return f
}
cfg := &Config{
Queue: fifo, //step1初始化的deltaFIFO
ListerWatcher: s.listerWatcher, //初始化时是某类型的List/Watch方法
ObjectType: s.objectType, //类型
FullResyncPeriod: s.resyncCheckPeriod, //cache数据全量重入一次队列的时间间隔?
RetryOnError: false,
ShouldResync: s.processor.shouldResync,
Process: s.HandleDeltas,
}
s.controller = New(cfg) //controller里基本只包含config
// config.Process处理函数功能如下
/* 处理obj中存储的需要处理的对象
1. 处理类型为sync/add/update时,如果对象存在于cache,则取出并更新。 如果不存在,则添加到cache。 处理类型为delete时,直接删除cache对象
2. 然后都调用distribute,把处理对象添加到sharedIndexInformer.sharedProcesser.listener数组中每个元素的addCh中
*/
func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error {
// from oldest to newest
for _, d := range obj.(Deltas) {
switch d.Type {
case Sync, Added, Updated:
isSync := d.Type == Sync
s.cacheMutationDetector.AddObject(d.Object)
if old, exists, err := s.indexer.Get(d.Object); err == nil && exists {
s.indexer.Update(d.Object)
s.processor.distribute(updateNotification{oldObj: old, newObj: d.Object}, isSync)
} else {
err := s.indexer.Add(d.Object)
s.processor.distribute(addNotification{newObj: d.Object}, isSync)
}
case Deleted:
s.indexer.Delete(d.Object)
s.processor.distribute(deleteNotification{oldObj: d.Object}, false)
}
}
return nil
}
在看step2. 执行启动mutationDetector.Run,以processorStopCh为退出标志
这个没太明白是什么
然后看step3,调用processor.Run()
func (p *sharedProcessor) run(stopCh <-chan struct{}) {
func() {
for _, listener := range p.listeners {
p.wg.Start(listener.run)
p.wg.Start(listener.pop)
}
p.listenersStarted = true
}()
<-stopCh
// listener.run如下,将for循环获取processLister.nextCh的内容,并根据事件类型调用对应的回调函数
func (p *processorListener) run() {
wait.Until(func() {
err := wait.ExponentialBackoff(retry.DefaultRetry, func() (bool, error) {
for next := range p.nextCh {
switch notification := next.(type) {
case updateNotification:
p.handler.OnUpdate(notification.oldObj, notification.newObj)
case addNotification:
p.handler.OnAdd(notification.newObj)
case deleteNotification:
p.handler.OnDelete(notification.oldObj)
default:
utilruntime.HandleError(fmt.Errorf("unrecognized notification: %T", next))
}
}
return true, nil
})
// the only way to get here is if the p.nextCh is empty and closed
if err == nil {
close(stopCh)
}
}, 1*time.Minute, stopCh)
}
最后是step4,s.controller.Run()。informer的主要运行逻辑都在这里
func (c *controller) Run(stopCh <-chan struct{}) {
...
// reflector存储了之前config中初始化的部分
r := NewReflector(
c.config.ListerWatcher,
c.config.ObjectType,
c.config.Queue,
c.config.FullResyncPeriod,
)
c.reflector = r
// r.Run中主要是调用ListWatcher接口,也是单起协程来循环处理的
wg.StartWithChannel(stopCh, r.Run)
// 主要从之前定义的队列中或者item并根据注册的处理方法处理
wait.Until(c.processLoop, time.Second, stopCh)
}
// 关于r.Run,最终调用
func (r *Reflector) ListAndWatch(stopCh <-chan struct{})
// 单独看下c.ProcessLoop函数
// 如下,将开启for循环,从queue中pop对象并对其执行c.config.Process函数(即初始化时注册的 HandleDeltas)
func (c *controller) processLoop() {
for {
obj, err := c.config.Queue.Pop(PopProcessFunc(c.config.Process))
...
}
}
总结(以deploymentController为例):
kube-controller-manager启动为:
1. 依次初始化各类型的controller,controller中会向全局sharedInformerFactory注册一些关注的Informer,例如deploymentController启动时会注册DeploymentInformer、ReplicasSetInformer、PodInformer三种。 其他controller如果需要,则无需重复注册。
2. 启动controller,启动一个loop循环执行processNextWorkItem,即从deployment.queue中获取item,并调用syncHandler处理(syncHandler被初始化为syncDeployment函数)
3. 启动informer,informer中包含两个重要部分
1) controller
启动reflector, 主要工作是调用List接口更新一次cache(在数据量大时,这里会做切片),然后循环调用watcher获取对象变更信息经过hash处理后存入deltaqueue。继而启动controller.processLoop,主要工作从deltafifo拿出节点执行HandlerDeltas。HandlerDeltas一则将数据更新到cache, 二则将数据分发给processor
1) sharedProcessor
processor这边由addChannal接收来自controller分发的数据,processor中有用户注册多种类型Event的回调处理函数。启动prcessor.run中,将不断从addChannal中 获取数据,并添加到buffer中。 另一个select从buffer中取数据后,调用已注册的相应的回调函数。 这些回调函数基本都有一个共同的操作就是调用enqueueDeployment()将deployment对象信息入队到deploy.queue中,供第2部分逻辑pop执行sync.
syncDeployment 同步逻辑
syncDeployment代码阅读
(其中会讲到 滚动更新过程的步长计算逻辑)
如何在deploy中添加灰度暂停
看这里之前请读清楚上面内容
如上,deploymentController将对每个更新后的deployment对象执行syncDeployment,其中有代码:
func (dc *DeploymentController) syncDeployment(key string) error {
...
//暂停态时,执行sync同步状态
if d.Spec.Paused {
return dc.sync(d, rsList)
}
...
//根据两种发布策略检查并更新deployment到最新状态
switch d.Spec.Strategy.Type {
case apps.RecreateDeploymentStrategyType:
return dc.rolloutRecreate(d, rsList, podMap)
case apps.RollingUpdateDeploymentStrategyType:
return dc.rolloutRolling(d, rsList)
}
滚动更新是一个多次滚动的过程,一个deployment的滚动更新通常会被多次执行syncDeployment,由代码又知:如果遇到deployment.spec.paused标志,将执行return dc.sync()从而不会进行下一次步长更新。
所以这次的灰度暂停,设计思路为:用户通过deployment.annotation设置期望灰度值,在到达灰度期望值后,设置paused来阻止下一次步长更新。
初版设计及测试
灰度数量通过annotation指定,下面函数获取灰度值
pkg/controller/deployment/util/deployment_util.go中添加逻辑
func Canary(deployment apps.Deployment) int32 {
//TODO 注释规范化 canaryStr支持数字和百分号
canaryStr := deployment.Annotations["canary"]
canary, _ := strconv.ParseInt(canaryStr, 10, 64)
return int32(canary)
}
在计算扩容数量时加入下列代码,会同时参考灰度期望值,保证本次扩容数量不超过灰度期望值。
pkg/controller/deploy/rolling.go添加
//rolloutRolling函数添加
if deploymentutil.IsCanaryComplete(d, allRSs, newRS) {
if err := dc.CanaryPauseDeployment(d); err != nil {
return err
}
}
//scaleDownOldReplicaSetsForRollingUpdate函数添加。如果newRs到达灰度值,那么需要调整maxUnavailable为0,防止旧实例缩容太多。(目的为:灰度暂停后,新实例+旧实例=期望实例数)
newRs := deploymentutil.FindNewReplicaSet(deployment, allRSs); if newRs != nil {
if *(newRs.Spec.Replicas) == deploymentutil.Canary(*deployment) {
maxUnavailable = 0
}
}
pkg/controller/deployment/util/deployment_util.go
//NewRSNewReplicas函数添加。计算newRs扩容数量时,参考灰度值。
// TODO(完成) canary和计算值间选择较小的
canary := Canary(*deployment)
oldActiveRs, _ := FindOldReplicaSets(deployment, allRSs)
if canary != 0 && len(oldActiveRs) > 0 && canary < *(deployment.Spec.Replicas) && *(newRS.Spec.Replicas) <= canary {
scaleUpCount = int32(integer.IntMin(int(scaleUpCount), int(canary-*(newRS.Spec.Replicas))))
}
// 判断达到灰度完成条件
func IsCanaryComplete(deployment *apps.Deployment, allRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet) bool {
var isCanaryComplete = false
canaryCount := Canary(*deployment)
if deployment.Spec.Strategy.Type == apps.RollingUpdateDeploymentStrategyType && canaryCount != 0 {
ReplicasCount := GetReplicaCountForReplicaSets(allRSs)
if *(newRS.Spec.Replicas) == canaryCount && ReplicasCount == *deployment.Spec.Replicas {
isCanaryComplete = true
}
}
return isCanaryComplete
}
最后在达到灰度条件时,打暂停标志
pkg/controller/deployment/sync.go添加
//添加函数
func (dc *DeploymentController) CanaryPauseDeployment(deployment *apps.Deployment) error {
dpCopy := deployment.DeepCopy()
dpCopy.Spec.Paused = true
_, err := dc.client.AppsV1().Deployments(dpCopy.Namespace).Update(dpCopy)
if err == nil {
dc.eventRecorder.Eventf(deployment, v1.EventTypeNormal, "CanaryPauseDeployment", "Pause Deployment %s", deployment.Name)
}
return err
}
遇到问题及原因(sync函数引起的比例扩缩问题)
在以上改动后,重新编译运行了kube-controller-manager组件,此时 kubectl edit deployment的模板信息使其滚动更新。
此时实例数为10,maxSurge为2,maxUavalible为1,灰度数量为3.
期望状态为: 新实例为3,旧实例为7, deployment.spec.paused为true
实际状态为: 新实例为3,旧实例为9,deployment.spec.paused为true
重读代码,发现是在暂停发起后,
错误原因解决方案
pkg/controller/deployment/sync.go添加
//减去逻辑 scale函数
allRSsReplicas := deploymentutil.GetReplicaCountForReplicaSets(allRSs)
allowedSize := int32(0)
if *(deployment.Spec.Replicas) > 0 {
allowedSize = *(deployment.Spec.Replicas) + deploymentutil.MaxSurge(*deployment)
deploymentReplicasToAdd := allowedSize - allRSsReplicas
//添加逻辑
//TODO(完成) allowedSize设置为目前deployment数-replicas参考数
var deploymentReplicasToAdd int32
oldDesired, ok := deploymentutil.GetDesiredReplicasAnnotation(newRS)
if ok {
deploymentReplicasToAdd = *(deployment.Spec.Replicas) - oldDesired
} else {
deploymentReplicasToAdd = 0
}