hadoop中压缩与解压详解
概述
本文会从一下几点介绍压缩也解压
1. 什么是压缩、解压?
2. hadoop中的压缩 、解压格式有哪些?
3. 有什么优缺点?
4. 应用场景有哪些?
5. 如何使用?
6. LzoCodec和LzopCodec区别
7. Hive中的使用
大家可以带着上述几个问题来进行学习、思考。
1 什么是压缩、解压
用一句最直白的话概述,压缩就是通过某种技术(算法)把原始文件变下,相应的解压就是把压缩后的文件变成原始文件。嘿嘿是不是又可以变大又可以变小。
- 想要对hadoop中压缩,解压进行深刻的认识,可以从该路线进行思考:hdfs ==> map ==> shuffle ==> reduce
2 hadoop中的压缩格式
| 压缩格式 | UNIX工具 | 算 法 | 文件扩展名 | 可分割 |
|---|---|---|---|---|
| DEFLATE | 无 | DEFLATE | .deflate | No |
| gzip | gzip | DEFLATE | .gz | No |
| LZ4 | 无 | LZ4 | .LZ4 | NO |
| bzip | bzip | bzip | .bz2 | YES |
| LZO | lzop | LZO | .lzo | YES if indexed |
| Snappy | 无 | Snappy | .snappy | NO |
一个简单的案例对于集中压缩方式之间的压缩比和压缩速度进行一个感观性的认识
测试环境:
8 core i7 cpu
8GB memory
64 bit CentOS
1.4GB Wikipedia Corpus 2-gram text input- 压缩比
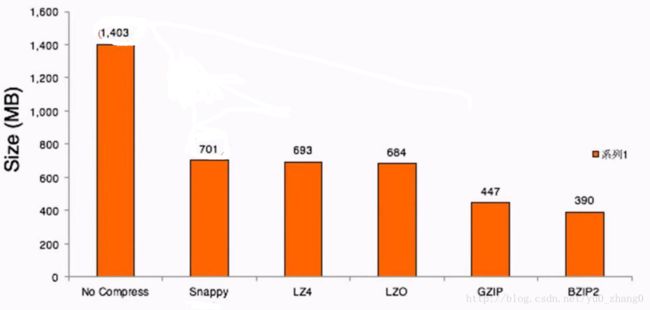
压缩时间
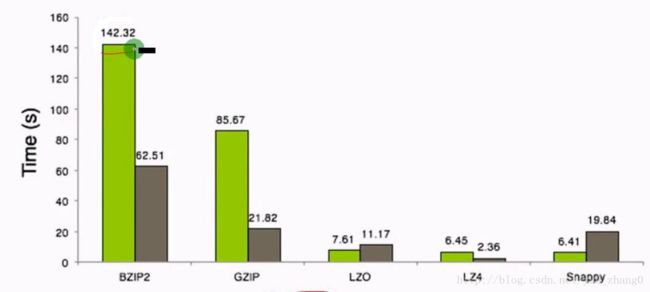
可以看出压缩比越高,压缩时间越长,压缩比:Snappy < LZ4 < LZO < GZIP < BZIP2gzip:
优点:压缩比在四种压缩方式中较高;hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;有hadoop native库;大部分linux系统都自带gzip命令,使用方便。
缺点:不支持split。lzo压缩
优点:压缩/解压速度也比较快,合理的压缩率;支持split,是hadoop中最流行的压缩格式;支持hadoop native库;需要在linux系统下自行安装lzop命令,使用方便。
缺点:压缩率比gzip要低;hadoop本身不支持,需要安装;lzo虽然支持split,但需要对lzo文件建索引,否则hadoop也是会把lzo文件看成一个普通文件(为了支持split需要建索引,需要指定inputformat为lzo格式)。- snappy压缩
优点:压缩速度快;支持hadoop native库。
缺点:不支持split;压缩比低;hadoop本身不支持,需要安装;linux系统下没有对应的命令。 - bzip2压缩
优点:支持split;具有很高的压缩率,比gzip压缩率都高;hadoop本身支持,但不支持native;在linux系统下自带bzip2命令,使用方便。
缺点:压缩/解压速度慢;不支持native。
3 优缺点
对于压缩的好处可以从两方面考虑:Storage + Compute;
1. Storage :基于HDFS考虑,减少了存储文件所占空间,提升了数据传输速率;
2. Compute:基于YARN上的计算(MapReduce/Hive/Spark/….)速度的提升。
在hadoop大数据的背景下,这两点尤为重要,怎样达到一个高效的处理,选择什么样的压缩方式和存储格式(下篇博客介绍)是很关键的。
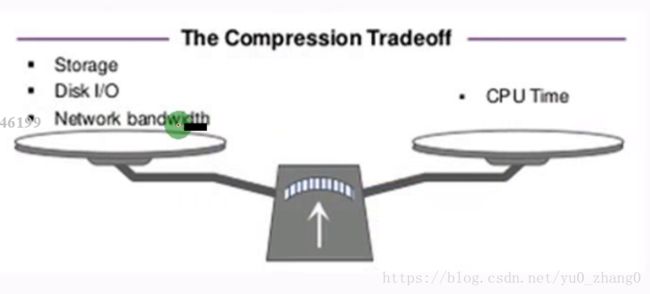
从这幅图带领大家进一步认识压缩于解压的优缺点,看到这幅图后你们有一定自己的认识吗?
优点:减少存储空间(HDFS),降低网络带宽,减少磁盘IO
缺点:既然存在优点,那必然存在缺点,那就是CPU啦,压缩和解压肯定要消耗CPU的,如果CPU过高那肯定会导致集群负载过高,从而导致你的计算缓慢,job阻塞,文件读取变慢一系列原因。
总结:
1. 不同的场景选择不同的压缩方式,肯定没有一个一劳永逸的方法,如果选择高压缩比,那么对于cpu的性能要求要高,同时压缩、解压时间耗费也多;选择压缩比低的,对于磁盘io、网络io的时间要多,空间占据要多;对于支持分割的,可以实现并行处理。
2. 分片的理解:举个例子,一个未压缩的文件有1GB大小,hdfs默认的block大小是64MB,那么这个文件就会被分为16个block作为mapreduce的输入,每一个单独使用一个map任务。如果这个文件是已经使用gzip压缩的呢,如果分成16个块,每个块做成一个输入,显然是不合适的,因为gzip压缩流的随即读是不可能的。实际上,当mapreduce处理压缩格式的文件的时候它会认识到这是一个gzip的压缩文件,而gzip又不支持随即读,它就会把16个块分给一个map去处理,这里就会有很多非本地处理的map任务,整个过程耗费的时间就会相当长。
lzo压缩格式也会是同样的问题,但是通过使用hadoop lzo库的索引工具以后,lzo就可以支持splittable。bzip2也是支持splittable的。
4 压缩在MapReduce中的应用场景
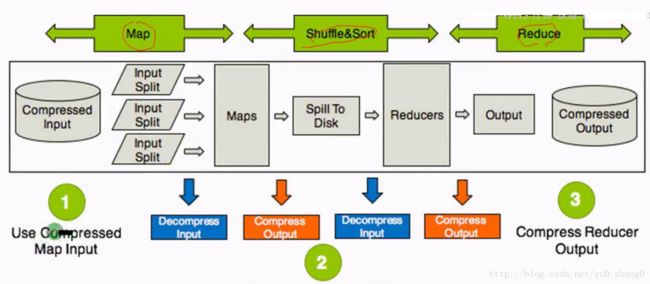
在hadoop中的应用场景总结在三方面:输入,中间,输出。
整体思路:hdfs ==> map ==> shuffle ==> reduce
- Use Compressd Map Input:从HDFS中读取文件进行Mapreuce作业,如果数据很大,可以使用压缩并且选择支持分片的压缩方式(Bzip2,LZO),可以实现并行处理,提高效率,减少磁盘读取时间,同时选择合适的存储格式例如Sequence Files,RC,ORC等;
- Compress Intermediate Data:Map输出作为Reducer的输入,需要经过shuffle这一过程,需要把数据读取到一个环形缓冲区,然后读取到本地磁盘,所以选择压缩可以减少了存储文件所占空间,提升了数据传输速率,建议使用压缩速度快的压缩方式,例如Snappy和LZO.
- Compress Reducer Output:进行归档处理或者链接Mapreduce的工作(该作业的输出作为下个作业的输入),压缩可以减少了存储文件所占空间,提升了数据传输速率,如果作为归档处理,可以采用高的压缩比(Gzip,Bzip2),如果作为下个作业的输入,考虑是否要分片进行选择。
5 中间压缩的配置和最终结果压缩的配置
可以使用Hadoop checknative检测本机有哪些可用的压缩方式
5.1 配置文件的修改
- core-site.xml codecs
io.compression.codecs
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec, #zlib->Default
org.apache.hadoop.io.compress.BZip2Codec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec,
org.apache.hadoop.io.compress.Lz4Codec,
org.apache.hadoop.io.compress.SnappyCodec,
- mapred-site.xml (switch+codec)
#支持压缩
mapreduce.output.fileoutputformat.compress
true
#压缩方式
mapreduce.output.fileoutputformat.compress.codec
org.apache.hadoop.io.compress.BZip2Codec
- 中间压缩:中间压缩就是处理作业map任务和reduce任务之间的数据,对于中间压缩,最好选择一个节省CPU耗时的压缩方式(快)
hadoop压缩有一个默认的压缩格式,当然可以通过修改mapred.map.output.compression.codec属性,使用新的压缩格式,这个变量可以在mapred-site.xml 中设置
mapred.map.output.compression.codec
org.apache.hadoop.io.compress.SnappyCodec
This controls whether intermediate files produced by Hive
between multiple map-reduce jobs are compressed. The compression codec
and other options are determined from hadoop config variables
mapred.output.compress*
- 最终压缩:可以选择高压缩比,减少了存储文件所占空间,提升了数据传输速率
mapred-site.xml 中设置
mapreduce.output.fileoutputformat.compress.codec
org.apache.hadoop.io.compress.BZip2Codec
6计算WC使用不同的压缩格式
1.使用Bzip2压缩方式
- input.txt文件
[hadoop@hadoop data]$ cat input.txt
hello java
hello hadoop
hello hive
hello sqoop
hello hdfs
hello spark- mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.output.fileoutputformat.compressname>
<value>truevalue>
property>
<property> <name>mapreduce.output.fileoutputformat.compress.codecname> <value>org.apache.hadoop.io.compress.BZip2Codecvalue>
property>
configuration>[hadoop@hadoop data]$ hdfs dfs -ls /
Found 3 items
-rw-r--r-- 3 hadoop supergroup 70 2018-03-01 12:48 /input.txt
drwx-wx-wx - hadoop supergroup 0 2018-03-01 12:57 /tmp
drwxr-xr-x - hadoop supergroup 0 2018-03-01 14:42 /user- 计算wc
命令:
[hadoop@hadoop mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount /input.txt /wc/output
查看结果:
[hadoop@hadoop mapreduce]$ hdfs dfs -ls /wc/output
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2018-03-02 15:54 /wc/output/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 77 2018-03-02 15:54 /wc/output/part-r-00000.bz2
.bz2出现成功2snappy压缩格式
mapred-site.xml
<property>
<name>mapreduce.output.fileoutputformat.compressname>
<value>truevalue>
property>
<property> <name>mapreduce.output.fileoutputformat.compress.codecname>
<value>org.apache.hadoop.io.compress.SnappyCodecvalue>
property>[hadoop@hadoop mapreduce]$ hdfs dfs -ls /wc/output_snappy
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2018-03-02 16:11 /wc/output_snappy/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 63 2018-03-02 16:11 /wc/output_snappy/part-r-00000.snappyLZO压缩方式
mapred-site.xml
<property>
<name>mapreduce.output.fileoutputformat.compressname>
<value>truevalue>
property>
<property> <name>mapreduce.output.fileoutputformat.compress.codecname>
<value>com.hadoop.compression.lzo.LzoCodecvalue>
property>[hadoop@hadoop mapreduce]$ hdfs dfs -ls /wc/output_lzo
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2018-03-02 16:29 /wc/output_lzo/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 66 2018-03-02 16:29 /wc/output_lzo/part-r-00000.lzo_deflate注意:com.hadoop.compression.lzo.LzopCodec这样配置会生成.lzo结尾的文件。
7 LzoCodec和LzopCodec区别:
- LzoCodec比LzopCodec更快, LzopCodec为了兼容LZOP程序添加了如 bytes signature, header等信息
- 如果使用 LzoCodec作为Reduce输出,则输出文件扩展名为”.lzo_deflate”,它无法被lzop读取;
- 如果使用LzopCodec作为Reduce输出,则扩展名为”.lzo”,它可以被lzop读取
- 生成lzo index job的”DistributedLzoIndexer“无法为 LzoCodec即 “.lzo_deflate”扩展名的文件创建index
”.lzo_deflate“文件无法作为MapReduce输入,”.LZO”文件则可以。
综上所述得出最佳实践:map输出的中间数据使用 LzoCodec,reduce输出使用 LzopCodec
8 Hive中设置压缩方式
SET hive.exec.compress.output=true; //默认不支持压缩
SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.BZip2Codec; //设置最终以bz2存储注意:不建议再配置文件中设置
- BZip2整合Hive
[hadoop@hadoop data]$ du -sh page_views.dat
19M page_views.dat
创建表:
create table page_views(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
加载数据:
load data local inpath "/home/hadoop/data/page_views.dat" overwrite into table page_views;
hive:
SET hive.exec.compress.output=true;
SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.BZip2Codec;
create table page_views_bzip2
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"- snappy整合Hive
SET hive.exec.compress.output=false;
SET hive.exec.compress.output=true;
SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
create table page_views_Snappy
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
as select * from page_views;
hdfs dfs -du -h /user/hive/warehouse/hive.db/page_views_snappy/000000_0.snappy
大小:8.4