Apollo 配置中心介绍
一、前言
最近我司进行基础架构升级,将配置中心从 Spring Cloud Config 迁移至 Apollo。趁此机会也学习下 Apollo,本文主要知识来自于我对官方 Wiki 的学习,如有错误,欢迎勘误。

Apollo(阿波罗)来自于携程研发的分布式配置中心,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景。
Apollo 服务端 基于 Spring Boot 和 Spring Cloud 开发,因此对于 Spring Cloud 项目能够很好的结合。官方提供 Java 和 .NET 两种语言的不依赖任何框架的客户端,另外还提供了 API 接口,便于其他语言或整合到自有框架中使用。由此看来,Apollo 接入到项目中是较为容易的。
演示环境:106.12.25.204:8070
账号/密码:apollo/admin
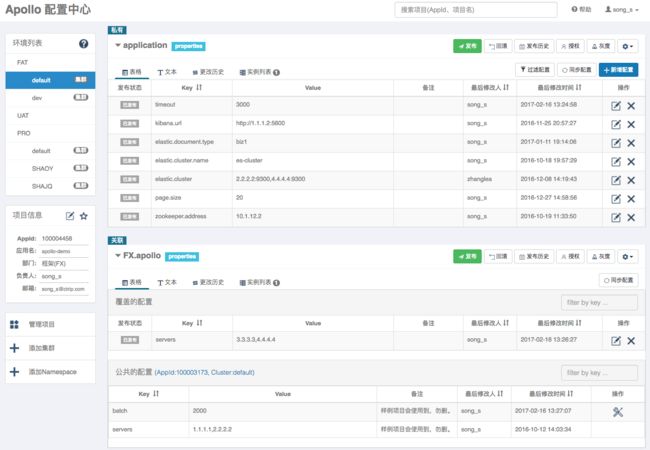
二、主要特点
2.1 Feature
(1)统一管理不同环境、不同集群的配置
- Apollo提供了一个统一界面集中式管理不同环境(environment)、不同集群(cluster)、不同命名空间(namespace)的配置。
- 同一份代码部署在不同的集群,可以有不同的配置。
- 通过命名空间(namespace)可以很方便的支持多个不同应用共享同一份配置,同时还允许应用对共享的配置进行覆盖。
(2)配置修改实时生效
用户在 Apollo 修改完配置并发布后,客户端能实时(1秒)接收到最新的配置,并加载到应用程序。
(3)版本发布管理
所有的配置发布都有版本概念,从而可以方便的支持配置的回滚。
(4)灰度发布
支持配置的灰度发布,比如点了发布后,只对部分应用实例生效,等观察一段时间没问题后再推给所有应用实例。
(5)权限管理、发布审核、操作审计
-
应用和配置的管理都有完善的权限管理机制,对配置的管理还分为了编辑和发布两个环节,从而减少人为的错误。
-
所有的操作都有审计日志,可以方便的追踪问题。
(6)客户端配置信息监控
- 可以方便的看到配置在被哪些实例使用。
(7)提供 Java 和 .Net 原生客户端
- 提供了 Java 和 .Net 的原生客户端,方便应用集成。
- 支持 Spring Placeholder,Annotation 和 Spring Boot 的 ConfigurationProperties,方便应用使用(需要Spring 3.1.1+)
- 同时提供了 HTTP 接口,非 Java 和 .Net 应用也可以方便的使用
(8)提供开放平台 API
- Apollo 自身提供了比较完善的统一配置管理界面,支持多环境、多数据中心配置管理、权限、流程治理等特性。
- 不过 Apollo 出于通用性考虑,对配置的修改不会做过多限制,只要符合基本的格式就能够保存。
- 在我们的调研中发现,对于有些使用方,它们的配置可能会有比较复杂的格式,如 xml, json,需要对格式做校验。
- 还有一些使用方如 DAL,不仅有特定的格式,而且对输入的值也需要进行校验后方可保存,如检查数据库、用户名和密码是否匹配。
- 对于这类应用,Apollo支持应用方通过开放接口在 Apollo 进行配置的修改和发布,并且具备完善的授权和权限控制。
(9)部署简单
- 配置中心作为基础服务,可用性要求非常高,这就要求 Apollo 对外部依赖尽可能地少
- 目前唯一的外部依赖是 MySQL,所以部署非常简单,只要安装好 Java 和 MySQL 就可以让 Apollo 跑起来
- Apollo 还提供了打包脚本,一键就可以生成所有需要的安装包,并且支持自定义运行时参数
2.2 能做哪些事
2.2.1 开关
(1)发布开关
发布开关一般用于发布过程中,比如:
- 有些新功能依赖于其它系统的新接口,而其它系统的发布周期未必和自己的系统一致,可以加个发布开关,默认把该功能关闭,等依赖系统上线后再打开。
- 有些新功能有较大风险,可以加个发布开关,上线后一旦有问题可以迅速关闭。
需要注意的是,发布开关应该是短暂存在的(1-2 周),一旦功能稳定后需要及时清除开关代码。
(2)实验开关
- 针对特定用户应用新的推荐算法。
- 针对特定百分比的用户使用新的下单流程。
- 有些重大功能已经对外宣称在某年某日发布,可以事先发到生产环境,只对内部用户打开,测试没问题后按时对全部用户开放。
实验开关应该也是短暂存在的,一旦实验结束了需要及时清除实验开关代码。
(3)运维开关
运维开关通常用于提升系统稳定性,比如:
-
大促前可以把一些非关键功能关闭来提升系统容量;
-
当系统出现问题时可以关闭非关键功能来保证核心功能正常工作。
运维开关可能会长期存在,而且一般会涉及多个系统,所以需要提前规划。
2.2.2 服务治理
(1)限流
服务就像高速公路一样,在正常情况下非常通畅,不过一旦流量突增(比如大促、遭受 DDOS 攻击)时,如果没有做好限流,就会导致系统整个被冲垮,所有用户都无法访问。
所以我们需要限流机制来应对此类问题,一般的做法是在网关或 RPC 框架层添加限流逻辑,结合配置中心的动态推送能力实现动态调整限流规则配置。
(2)黑白名单
对于一些关键服务,哪怕是在内网环境中一般也会对调用方有所限制,比如:
-
有敏感信息的服务可以通过配置白名单来限制只有某些应用或 IP 才能调用
-
某个调用方代码有问题导致超大量调用,对服务稳定性产生了影响,可以通过配置黑名单来暂时屏蔽这个调用方或 IP
一般的做法是在 RPC 框架层添加校验逻辑,结合配置中心的动态推送能力来实现动态调整黑白名单配置。
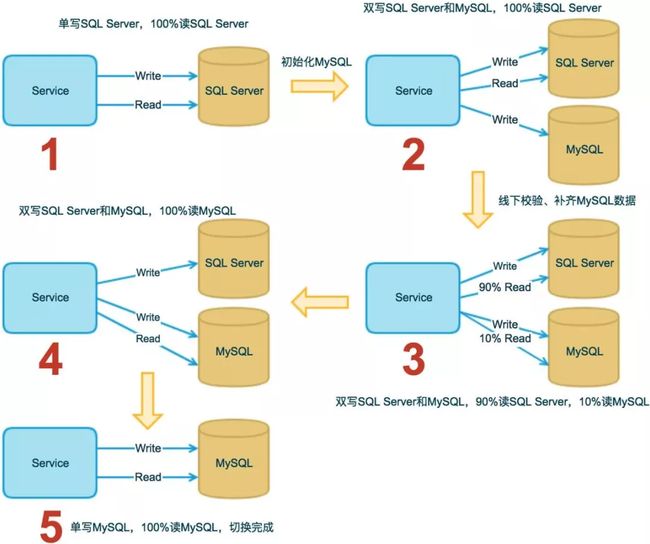
2.2.3 数据库迁移
数据库的迁移也是挺普遍的,比如:原来使用的 SQL Server,现在需要迁移到 MySQL,这种情况就可以结合配置中心来实现平滑迁移:
- 单写 SQL Server,100% 读 SQL Server;
- 初始化 MySQL;
- 双写 SQL Server 和 MySQL,100% 读 SQL Server;
- 线下校验、补齐 MySQL 数据;
- 双写 SQL Server 和 MySQL,90% 读 SQL Server,10% 读 MySQL;
- 双写 SQL Server 和 MySQL,100% 读 MySQL;
- 单写 MySQL,100% 读 MySQL;
- 切换完成。
上述的读写开关和比例配置都可以通过配置中心实现动态调整。
2.2.4 动态日志级别
服务运行过程中,经常会遇到需要通过日志来排查定位问题的情况,然而这里却有个两难:
-
如果日志级别很高(如:ERROR),可能对排查问题也不会有太大帮助
-
如果日志级别很低(如:DEBUG),日常运行会带来非常大的日志量,造成系统性能下降
为了兼顾性能和排查问题,我们可以借助于日志组件和配置中心实现日志级别动态调整。
https://github.com/ctripcorp/apollo-use-cases/tree/master/spring-cloud-logger
2.2.5 动态数据源
数据库是应用运行过程中的一个非常重要的资源,承担了非常重要的角色。
在运行过程中,我们会遇到各种不同的场景需要让应用程序切换数据库连接,比如:数据库维护、数据库宕机主从切换等。
https://github.com/ctripcorp/apollo-use-cases/tree/master/dynamic-datasource
2.3 公共组件的配置
公共组件是指那些发布给其它应用使用的客户端代码,比如 RPC 客户端、DAL 客户端等。
这类组件一般是由单独的团队(如中间件团队)开发、维护,但是运行时是在业务实际应用内的,所以本质上可以认为是应用的一部分。
这类组件的特殊之处在于大部分的应用都会直接使用中间件团队提供的默认值,少部分的应用需要根据自己的实际情况对默认值进行调整。
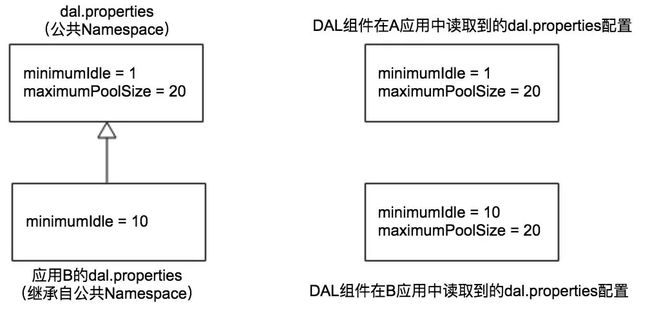
比如数据库连接池的最小空闲连接数量(minimumIdle),出于对数据库资源的保护,DBA 要求将全公司默认的 minimumIdle 设为 1,对大部分的应用可能都适用,不过有些核心 / 高流量应用可能觉得太小,需要设为 10。
针对这种情况,可以借助于 Apollo 提供的 Namespace 关联类型实现:
- 中间件团队创建一个名为
dal的公共 Namespace,设置全公司的数据库连接池默认配置 - dal 组件的代码会读取
dal公共 Namespace 的配置 - 对大部分的应用由于默认配置已经适用,所以不用做任何事情
- 对于少量核心 / 高流量应用如果需要调整 minimumIdle 的值,只需要关联
dal公共 Namespace,然后对需要覆盖的配置做调整即可,调整后的配置仅对该应用自己生效
 >
>
通过这种方式的好处是不管是中间件团队,还是应用开发,都可以灵活地动态调整公共组件的配置。
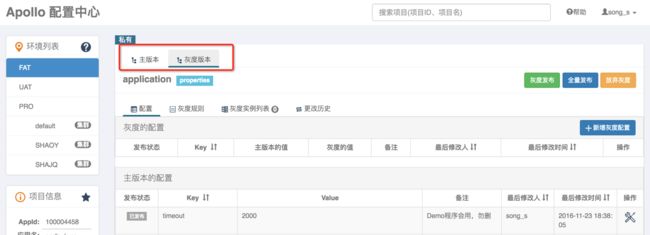
2.4 灰度发布
对于重要的配置一定要做灰度发布,先在一台或多台机器上生效后观察效果,如果没有问题再推给所有的机器。
对于公共组件的配置,建议先在一个或多个应用上生效后观察效果,没有问题再推给所有的应用。
2.5 发布审核
生产环境建议启用发布审核功能,简单而言就是如果某个人修改了配置,那么必须由另一个人审核后才可以发布,以避免由于头脑不清醒、手一抖之类的造成生产事故。
三、基本介绍
3.1 配置
既然 Apollo 是一款分布式配置中心,首先我们就得搞清楚什么是配置。配置通俗来说就是我们 Java 程序中的 .properties 文件或者是 .yaml 文件,配置一般有以下几个属性:
- 配置是独立于程序的只读变量
- 配置首先是独立于程序的,同一份程序在不同的配置下会有不同的行为。
- 其次,配置对于程序是只读的,程序通过读取配置来改变自己的行为,但是程序不应该去改变配置。
- 常见的配置有:数据库连接信息、线程池大小、缓冲区大小、服务器地址等。
- 配置伴随应用的整个生命周期
- 配置贯穿于应用的整个生命周期,应用在启动时通过读取配置来初始化,在运行时根据配置调整行为。
- 配置可以有多种加载方式
- 配置也有很多种加载方式,常见的有程序内部hard code,配置文件,环境变量,启动参数,基于数据库等
- 配置需要治理
- 权限控制
- 由于配置能改变程序的行为,不正确的配置甚至能引起灾难,所以对配置的修改必须有比较完善的权限控制
- 不同环境、集群配置管理
- 同一份程序在不同的环境(开发,测试,生产)、不同的集群(如不同的数据中心)经常需要有不同的配置,所以需要有完善的环境、集群配置管理
- 框架类组件配置管理
- 还有一类比较特殊的配置 - 框架类组件配置,比如CAT客户端的配置。
- 虽然这类框架类组件是由其他团队开发、维护,但是运行时是在业务实际应用内的,所以本质上可以认为框架类组件也是应用的一部分。
- 这类组件对应的配置也需要有比较完善的管理方式。
- 权限控制
3.2 基础模型
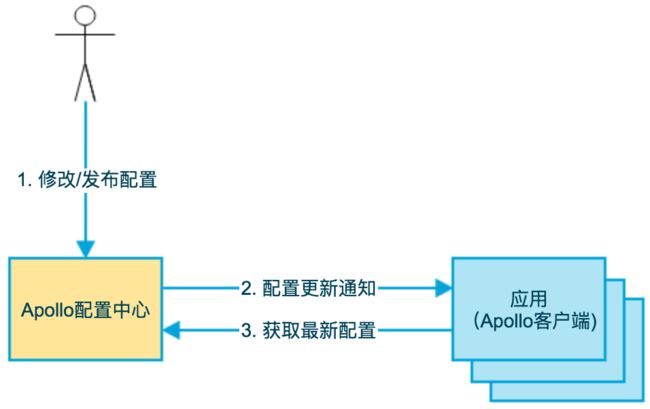
下图就是将 Apollo 进行抽象的模型图:
- 用户在配置中心对配置进行修改并发布
- 配置中心通知 Apollo 客户端有配置更新
- Apollo 客户端从配置中心拉取最新的配置、更新本地配置并通知到应用
3.3 核心概念
Apollo 支持以下 4 个维度管理 Key-Value 格式的配置
3.3.1 Application 应用
这个很好理解,就是实际使用配置的应用,Apollo 客户端在运行时需要知道当前应用是谁,从而可以去获取对应的配置。每个应用都需要有唯一的身份标识,也就是 appId。
我们认为应用身份是跟着代码走的,所以需要在代码中配置。
3.3.2 Environment 环境
即配置对应的环境,Apollo 客户端在运行时需要知道当前应用处于哪个环境,从而可以去获取应用的配置。
我们认为环境和代码无关,同一份代码部署在不同的环境就应该能够获取到不同环境的配置,所以环境默认是通过读取机器上的配置(server.properties 中的 env 属性)指定的。
Apollo 支持一下四种环境:
DEV开发环境FAT测试环境UAT仿真(预发)环境【注:即与线上完全一致的内网环境,用于回归测试等】PRO线上环境
3.3.3 Cluster 集群
即一个应用下不同实例的分组,比如典型的可以按照数据中心分,把上海机房的应用实例分为一个集群,把北京机房的应用实例分为另一个集群。
对不同的 cluster,同一个配置可以有不一样的值。集群默认是通过读取机器上的配置(server.properties 中的 idc 属性)指定的。
3.3.4 Namespace 命名空间
一个应用下不同配置的分组,可以简单地把 namespace 类比为文件,不同类型的配置存放在不同的文件中,如数据库配置文件,RPC 配置文件,应用自身的配置文件等。
3.4 Namespance
3.4.1 介绍
Namespace是配置项的集合,类似于一个配置文件的概念。Apollo 在创建项目的时候,都会默认创建一个“application”的Namespace。
我们知道 Spring Boot 项目都有一个默认配置文件 application.yml。在这里 application.yml 就等同于“application”的 Namespace。对于 90% 的应用来说,“application” 的 Namespace 已经满足日常配置使用场景了。
比如你的程序中有别的配置文件,例如 log4j,它是一个单独的配置文件,和 application.yml 不在一起,那么你就可以在新建一个 NameSpace,用于管理 log4j 的配置信息。
3.4.2 权限
对于 Apollo 客户端来说,Namespace 的获取权限分为两种:
- private (私有的)
- public (公共的)
对于 private 权限的 Namespace,只能被所属的应用获取到。一个应用尝试获取其它应用 private 的 Namespace,Apollo 会报“404”异常。对于 public 权限的 Namespace,能被任何应用获取。
3.4.3 类型
Namespace类型有三种:
- 私有类型
- 公共类型
- 关联类型(继承类型)
私有类型的 Namespace 具有 private 权限。例如上文提到的“application” Namespace 就是私有类型。
公共类型的 Namespace 具有 public 权限。公共类型的 Namespace 相当于游离于应用之外的配置,可以被多个应用所共享,所以公共的 Namespace 的名称必须全局唯一。
关联类型又可称为继承类型,关联类型具有 private 权限。关联类型的 Namespace 继承于公共类型的 Namespace,用于覆盖公共 Namespace 的某些配置。例如公共的 Namespace 有两个配置项:
k1 = v1
k2 = v2
然后应用 A 有一个关联类型的 Namespace 关联了此公共 Namespace,且覆盖了配置项 k1,新值为 v3。那么在应用 A 实际运行时,获取到的公共 Namespace 的配置为:
k1 = v3
k2 = v2
3.4.1 示例
举个例子,如下图所示,有三个应用:应用A、应用B、应用C。
-
应用 A 有两个私有类型的 Namespace:application 和 NS-Private,以及一个关联类型的 Namespace:NS-Public。
-
应用 B 有一个私有类型的 Namespace:application,以及一个公共类型的 Namespace:NS-Public。
-
应用 C 只有一个私有类型的 Namespace:application
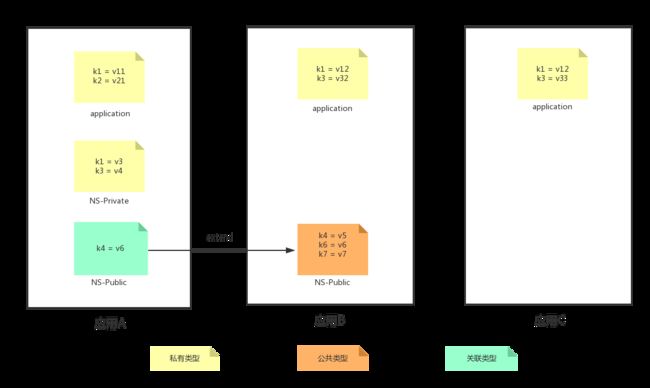
对于应用 A:
//application
Config appConfig = ConfigService.getAppConfig();
appConfig.getProperty("k1", null); // k1 = v11
appConfig.getProperty("k2", null); // k2 = v21
//NS-Private
Config privateConfig = ConfigService.getConfig("NS-Private");
privateConfig.getProperty("k1", null); // k1 = v3
privateConfig.getProperty("k3", null); // k3 = v4
//NS-Public,覆盖公共类型配置的情况,k4被覆盖
Config publicConfig = ConfigService.getConfig("NS-Public");
publicConfig.getProperty("k4", null); // k4 = v6 cover
publicConfig.getProperty("k6", null); // k6 = v6
publicConfig.getProperty("k7", null); // k7 = v7
对于应用 B:
//application
Config appConfig = ConfigService.getAppConfig();
appConfig.getProperty("k1", null); // k1 = v12
appConfig.getProperty("k2", null); // k2 = null
appConfig.getProperty("k3", null); // k3 = v32
//NS-Private,由于没有NS-Private Namespace 所以获取到default value
Config privateConfig = ConfigService.getConfig("NS-Private");
privateConfig.getProperty("k1", "default value");
//NS-Public
Config publicConfig = ConfigService.getConfig("NS-Public");
publicConfig.getProperty("k4", null); // k4 = v5
publicConfig.getProperty("k6", null); // k6 = v6
publicConfig.getProperty("k7", null); // k7 = v7
对于应用 C:
//application
Config appConfig = ConfigService.getAppConfig();
appConfig.getProperty("k1", null); // k1 = v12
appConfig.getProperty("k2", null); // k2 = null
appConfig.getProperty("k3", null); // k3 = v33
//NS-Private,由于没有NS-Private Namespace 所以获取到default value
Config privateConfig = ConfigService.getConfig("NS-Private");
privateConfig.getProperty("k1", "default value");
//NS-Public,公共类型的Namespace,任何项目都可以获取到
Config publicConfig = ConfigService.getConfig("NS-Public");
publicConfig.getProperty("k4", null); // k4 = v5
publicConfig.getProperty("k6", null); // k6 = v6
publicConfig.getProperty("k7", null); // k7 = v7
四、Spring Cloud Config
其实这点是最值得关注的,特别是做技术升级,Spring Cloud Config 用的好好的,为什么要花费时间去切换到 Apollo?单说 KPI 显然是说不过去,Apollo 自然是有击中 Spring Cloud Config 痛点的地方。
从我使用 Spring Cloud Config 的有限时间,以及对 Apollo 的简单了解来看,我觉得击中了这几个痛点:
- Spring Cloud Config 由于依赖于 Git,其对配置的版本控制仍有缺陷。因为我司所有微服务储存于同一个 config 仓库,因此使用 git 的版本回退,会导致影响到其他人的配置,所以 git 的版本控制往往被用于查看改动点了。
- 权限控制较弱,无法将修改、发布权限分离。Spring Cloud Config 修改后就及时生效,不存在发布的概念。再加上本质就是 git 仓库,因此权限控制功能不完备。
- 不支持灰度。这一点其实我觉得是一个很大的痛点,当前微服务基本都是集群部署,对于一些较大的影响点,能够灰度上线是较为重要的。
以上是我的个人总结,下面列出官方给出的对比表格:
| 功能点 | Apollo | Spring Cloud Config | 备注 |
|---|---|---|---|
| 配置界面 | 统一界面管理不同环境、不同集群配置 | 无,需要通过 git 操作 | |
| 配置生效时间 | 实时 | 重启生效,或手动refresh 生效 | Spring Cloud Config 需要通过 Git webhook,加上额外的消息队列才能支持实时生效 |
| 版本管理 | 界面上直接提供发布历史和回滚按钮 | 无,需要通过git操作 | |
| 灰度发布 | 支持 | 不支持 | |
| 授权、审核、审计 | 界面上直接支持,支持修改、发布权限分离 | 需要通过 git 仓库设置,且不支持修改、发布权限分离 | |
| 实例配置监控 | 可以方便的看到当前哪些客户端在使用哪些配置 | 不支持 | |
| 配置获取性能 | 快,通过数据库访问+缓存支持 | 较慢,需要从 git clone repository,然后从文件系统读取 | |
| 客户端支持 | 原生支持所有 Java 和 .Net 应用,提供 API 支持其它语言应用,支持 Spring annotation 获取配置 | 支持 Spring 应用,提供 annotation 获取配置 | Apollo 的适用范围更广一些 |
五、可用性设计
Apollo 当拉取到配置中心的配置后,会将其在本地文件系统中进行缓存,当 Apollo 服务宕机或网络故障时,使用本地缓存恢复配置。除此之外,配置中心作为 Apollo 服务核心,可用性要求即可,下表描述了在不同场景下 Apollo 的可用性情况:
| 场景 | 影响 | 降级 | 原因 |
|---|---|---|---|
| 某台 Config Service 下线 | 无影响 | Config Service 无状态,客户端通过 Eureka 连接其他 Config Service | |
| 所有 Config Service 下线 | 客户端无法读取最新配置,Portal无影响 | 客户端重启时,可以读取本地缓存配置文件 | |
| 某台admin service下线 | 无影响 | Admin Service 无状态,Portal 通过 Eureka 连接其它 Config Service | |
| 所有admin service下线 | 客户端无影响,portal无法更新配置 | ||
| 某台 Portal 下线 | 无影响 | Portal 域名通过 slb 绑定多台服务器,重试后指向指定可用的服务器 | |
| 所有 Portal 下线 | 客户端无影响,Portal 无法更新配置 | ||
| 某个数据中心下线 | 无影响 | 多数据中心部署,数据完全同步,Meta Server/Portal域名通过slb自动切换到其它存活的数据中心 |
六、架构设计
6.1 七大模块
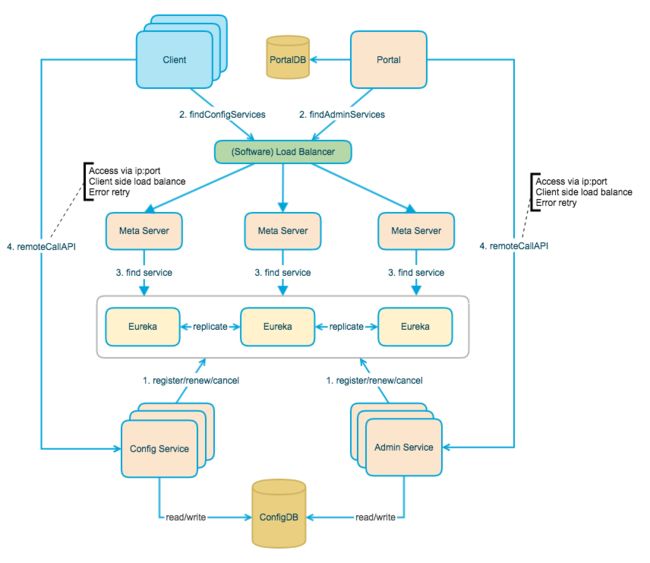
上图就是 Apollo 的主要架构设计,一共包含七个模块。其中四个模块是和功能相关的核心模块:
Config Service- 提供配置获取接口
- 提供配置推送接口(基于 HTTP Long Polling)
- 服务于 Apollo 客户端
Admin Service- 提供配置管理接口
- 提供配置修改发布接口
- 服务于管理界面 Portal
Client- Apollo 提供的客户端程序,为应用获取配置,支持实时更新
- 通过 MetaServer 获取 Config Service 的服务列表
- 使用客户端软负载 SLB 方式调用 Config Service
Portal- 提供 Web 界面供用户管理配置
- 通过 MetaServer 获取 Admin Service 的服务列表
- 使用客户端软负载 SLB 方式调用 Admin Service
另外三个模块是辅助服务发现的模块:
Eureka- 基于 Eureka 和 Spring Cloud Netflix 提供服务发现和注册
- Config Service 和 Admin Service 会向 Eureka 注册实例并保持心跳
- 为了简单起见,目前 Eureka 在部署时和 Config Service 是在一个JVM进程中的(通过 Spring Cloud Netflix)
MetaServer- Portal 通过域名访问 MetaServer 获取 Admin Service 的地址列表、
- Client 通过域名访问 MetaServer 获取 Config Service 的地址列表
- 相当于一个 Eureka Proxy,它就是为了封装服务发现的细节,对 Portal 和 Client 而言,永远通过一个 HTTP 接口获取Admin Service 和 Config Service 的服务信息,而不需要关心背后实际的服务注册和发现组件
- 逻辑角色,在部署时和 Config Service 是在一个 JVM 进程中的,所以IP、端口和 Config Service 一致
NginxLB- 和域名系统配合,协助 Portal 访问 MetaServer 获取 Admin Service 地址列表
- 和域名系统配合,协助 Client 访问 MetaServer 获取 Config Service 地址列表
- 和域名系统配合,协助用户访问 Portal 进行配置管理
个人总结下,Config Service 提供配置的读取、推送等功能,服务对象是 Apollo 客户端,Admin Service 提供配置的修改、发布等功能,服务对象是 Apollo Portal(管理界面)。二者自身都是多实例、无状态的,Apollo 通过 Eureka 实现服务的注册发现,因此这二者是会被注册到 Eureka 中。
在 Eureka 上层,Apollo 封装了 MetaServer 来实现 Eureka 的服务发现。Apollo 客户端通过域名访问 MetaServer 获取 Config Service 服务列表(IP + Port),而后直接通过 IP + Port 访问服务,同时在 Client 侧会做负载均衡和错误重试。同理 Apollo Portal 也通过域名访问 MetaServer 获取 Admin Service 服务列表(IP + Port),而后直接通过 IP + Port 访问服务,同时在 Portal 侧会做负载均衡和错误重试。
6.2 Apollo V1
如果不考虑分布式微服务架构中的服务发现问题,Apollo 的最简架构如下图所示:
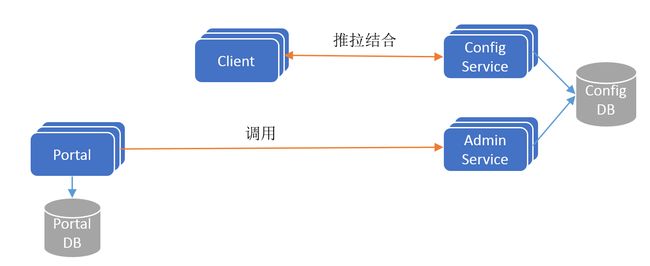
Config Service 是一个独立的微服务,服务于 Client 进行配置获取。Client 和 Config Service 保持长连接,通过一种推拉结合(push & pull)的模式,在实现配置实时更新的同时,保证配置更新不丢失。
Admin Service 是一个独立的微服务,服务于 Portal 进行配置管理。Portal 通过调用 Admin Service 进行配置管理和发布。
Config Service 和 Admin Service共享 ConfigDB,ConfigDB 中存放项目在某个环境中的配置信息。Config Service、Admin Service 和ConfigDB 三者在每个环境(DEV/FAT/UAT/PRO)中都要部署一份。
Protal 有一个独立的 PortalDB,存放用户权限、项目和配置的元数据信息。Protal 只需部署一份,它可以管理多套环境。
6.3 Apollo V2
为了保证高可用,Config Service 和 Admin Service 都是无状态以集群方式部署的,这个时候就存在一个服务发现问题:Client怎么找到 Config Service,Portal 怎么找到 Admin Service?
为了解决这个问题,Apollo 在其架构中引入了 Eureka,实现微服务间的服务注册和发现,更新后的架构如下图所示:
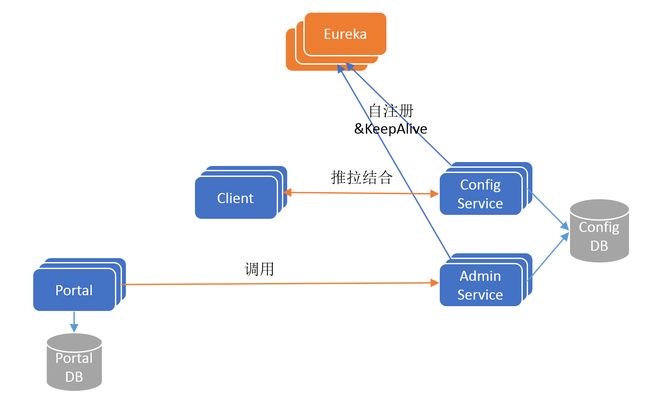
Config Service 和 Admin Service 启动后都会注册到 Eureka 服务注册中心,并定期发送保活心跳。Eureka采用集群方式部署,使用分布式一致性协议保证每个实例的状态最终一致。
6.4 Apollo V3
我们知道 Eureka 是自带服务发现的 Java 客户端的,如果 Apollo 只支持 Java 客户端接入,不支持其它语言客户端接入的话,那么 Client 和 Portal 只需要引入 Eureka 的 Java 客户端,就可以实现服务发现功能。
发现目标服务后,通过客户端软负载(SLB,例如 Ribbon)就可以路由到目标服务实例。这是一个经典的微服务架构,基于 Eureka 实现服务注册发现+客户端 Ribbon 配合实现软路由,如下图所示:
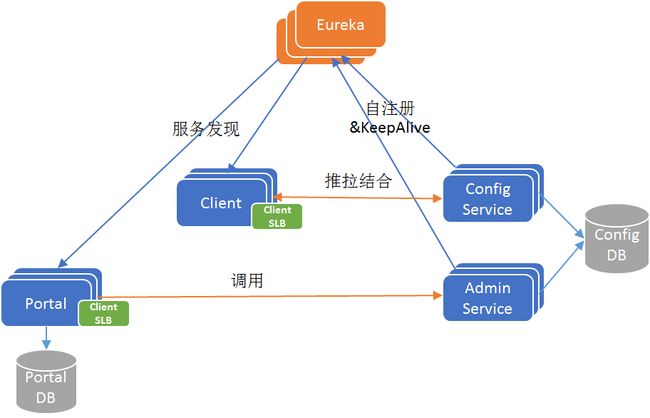
6.5 Apollo V4
在携程,应用场景不仅有 Java,还有很多遗留的 .Net 应用。Apollo 的作者也考虑到开源到社区以后,很多客户应用是非 Java 的。但是 Eureka(包括 Ribbon 软负载)原生仅支持 Java 客户端,如果要为多语言开发 Eureka/Ribbon 客户端,这个工作量很大也不可控。
为此,Apollo 的作者引入了 MetaServer 这个角色,它其实是一个 Eureka 的 Proxy,将 Eureka 的服务发现接口以更简单明确的 HTTP接口的形式暴露出来,方便 Client/Protal 通过简单的 HTTPClient 就可以查询到 Config Service 或 Admin Service 的地址列表。获取到服务实例地址列表之后,再以简单的客户端软负载(Client SLB)策略路由定位到目标实例,并发起调用。
现在还有一个问题,MetaServer 本身也是无状态以集群方式部署的,那么 Client 和 Protal 该如何发现 MetaServer 呢?
一种传统的做法是借助硬件或者软件负载均衡器,例如在携程采用的是扩展后的 NginxLB(也称 Software Load Balancer),由运维为 MetaServer 集群配置一个域名,指向 NginxLB 集群,NginxLB 再对 MetaServer 进行负载均衡和流量转发。Client和Portal 通过域名+ NginxLB 间接访问 MetaServer 集群。
引入 MetaServer 和 NginxLB 之后的架构如下图所示:
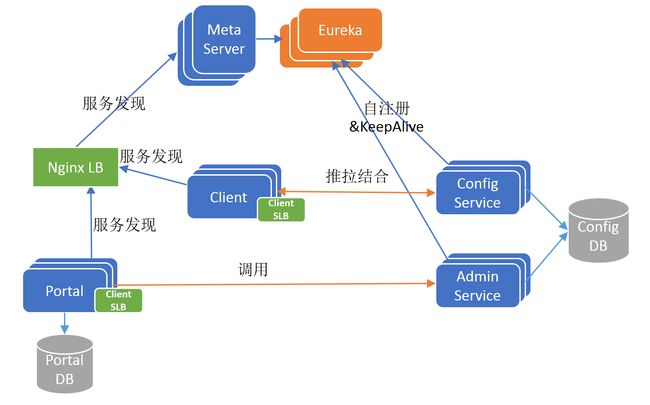
6.6 Apollo V5
V4 版本已经是比较完整的 Apollo 架构全貌,现在还剩下最后一个环节:Portal 也是无状态以集群方式部署的,用户如何发现和访问 Portal?答案也是简单的传统做法,用户通过域名+NginxLB 间接访问 Portal 集群。
所以 V5 版本是包括用户端的最终的 Apollo 架构全貌,如下图所示:
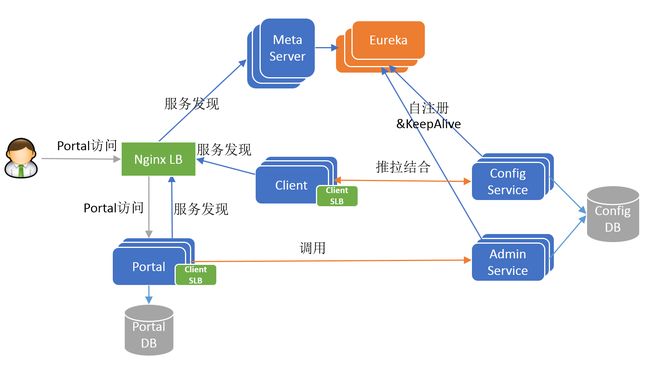
6.7 Why Eureka
为什么在 Apollo 中采用 Eureka 作为服务注册中心,而不是使用传统的 zookeeper/etcd ,有以下几方面的原因:
- 它提供了完整的 Service Registry 和 Service Discovery 实现
- 首先是提供了完整的实现,并且也经受住了 Netflix 自己的生产环境考验,相对使用起来会比较省心。
- 和 Spring Cloud 无缝集成
- 我们的项目本身就使用了 Spring Cloud 和 Spring Boot,同时 Spring Cloud还 有一套非常完善的开源代码来整合 Eureka,所以使用起来非常方便。
- 另外,Eureka 还支持在我们应用自身的容器中启动,也就是说我们的应用启动完之后,既充当了Eureka 的角色,同时也是服务的提供者,这样就极大的提高了服务的可用性。
- 这一点是我们选择 Eureka 而不是 zk、etcd 等的主要原因,为了提高配置中心的可用性和降低部署复杂度,我们需要尽可能地减少外部依赖。
- Open Source
- 由于代码是开源的,所以非常便于我们了解它的实现原理和排查问题。
七、服务端设计
7.1 实时推送
在 Apollo 配置中心中,一个重要的功能就是配置发布后实时推送到客户端。
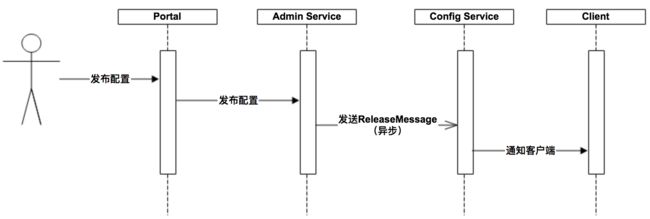
上图简要描述了配置发布的大致过程:用户首先在 Portal 操作配置发布,Portal 调用 Admin Service 的接口操作发布,Admin Service发布配置后,发送 ReleaseMessage 给各个 Config Service,Config Service 收到 ReleaseMessage 后,通知对应的客户端。
7.2 ReleaseMessage
Admin Service 在配置发布后,需要通知所有的 Config Service 有配置发布,从而 Config Service 可以通知对应的客户端来拉取最新的配置。
从概念上来看,这是一个典型的消息使用场景,Admin Service 作为 producer 发出消息,各个 Config Service 作为 consumer 消费消息。通过一个消息组件(Message Queue)就能很好的实现 Admin Service 和 Config Service 的解耦。
在实现上,考虑到 Apollo 的实际使用场景,以及为了尽可能减少外部依赖,我们没有采用外部的消息中间件,而是通过数据库实现了一个简单的消息队列。实现方式如下:
- Admin Service 在配置发布后会往 ReleaseMessage 表插入一条消息记录,消息内容就是配置发布的AppId+Cluster+Namespace,参见 DatabaseMessageSender
- Config Service 有一个线程会每秒扫描一次 ReleaseMessage 表,看看是否有新的消息记录,参见 ReleaseMessageScanner
- Config Service 如果发现有新的消息记录,那么就会通知到所有的消息监听器(ReleaseMessageListener),如NotificationControllerV2,消息监听器的注册过程参见 ConfigServiceAutoConfiguration
- NotificationControllerV2 得到配置发布的 AppId+Cluster+Namespace 后,会通知对应的客户端
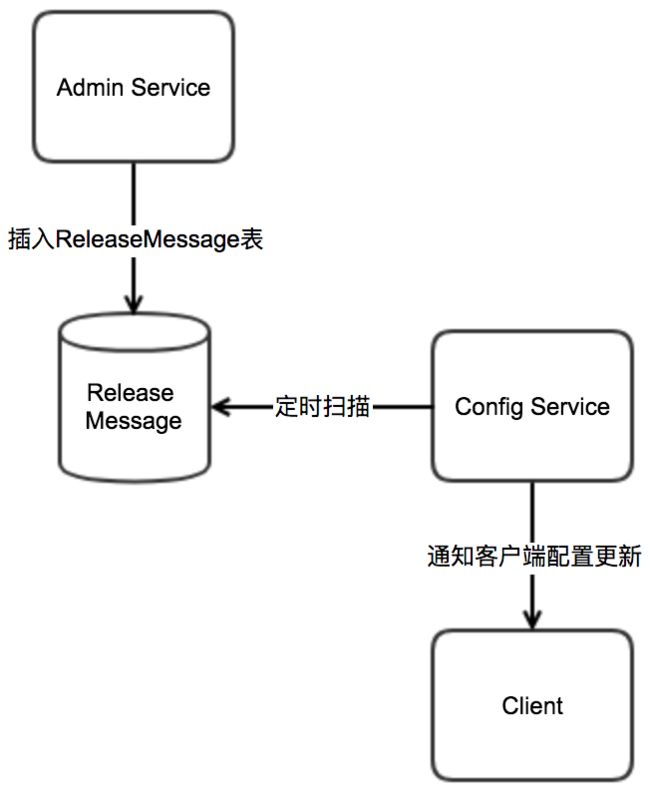
7.3 通知客户端
上节简要描述了 NotificationControllerV2 是如何得知有配置发布的,那 NotificationControllerV2 在得知有配置发布后是如何通知到客户端的呢?实现方式如下:
- 客户端会发起一个 HTTP 请求到 Config Service 的
notifications/v2接口,也就是NotificationControllerV2,参见RemoteConfigLongPollService - NotificationControllerV2 不会立即返回结果,而是通过 Spring DeferredResult 把请求挂起
- 如果在 60 秒内没有该客户端关心的配置发布,那么会返回 HTTP 状态码 304(Not Modified)给客户端
- 如果有该客户端关心的配置发布,NotificationControllerV2 会调用 DeferredResult 的setResult方法,传入有配置变化的namespace 信息,同时该请求会立即返回。客户端从返回的结果中获取到配置变化的 namespace 后,会立即请求 Config Service 获取该 namespace 的最新配置。
八、客户端设计
8.1 实现原理
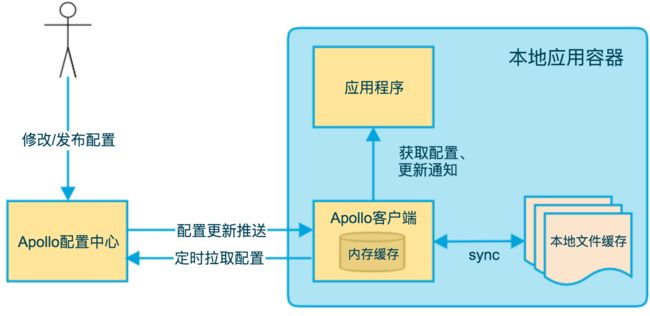
上图是 Apollo 客户端的实现原理图,首先 Apollo 客户端通过 HTTP Long Polling 和 Config Service 保持一个长连接,这个连接是 60s,如果在这 60s 内配置发生了更新,那么被保持的客户端就会立刻返回,并告知客户端有配置更新,然后客户端再去主动拉取更新;如果超过 60s,该长连接会中断,客户端返回 HTTP 304(Not Modified)。客户端收到返回的请求后,会立即重新发起长连接请求,以此往复。
除此以外,Apollo 提供了容错机制,防止长连接的推送机制失效导致配置无法更新,Apollo 客户端会定时主动向 Apollo 拉取配置,该定时频率默认为 5 分钟,可以通过修改 apollo.refreshInterval 属性来更改该默认值。
8.2 与 Spring 集成
Apollo 除了支持 API 方式获取配置,也支持和 Spring/Spring Boot 集成,集成原理简述如下。Spring 从 3.1 版本开始增加了ConfigurableEnvironment和PropertySource:
- ConfigurableEnvironment
- Spring 的 ApplicationContext 会包含一个 Environment(实现 ConfigurableEnvironment 接口)
- ConfigurableEnvironment 自身包含了很多个 PropertySource
- PropertySource
- 属性源,可以理解为很多个 Key - Value 的属性配置
在运行时的结构形如:
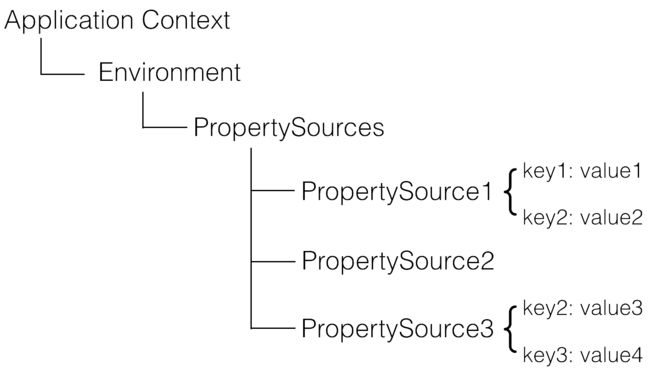
需要注意的是,PropertySource 之间是有优先级顺序的,如果有一个 Key 在多个 property source 中都存在,那么在前面的 property source 优先。所以对上图的例子:
- env.getProperty(“key1”) -> value1
- env.getProperty(“key2”) -> value2
- env.getProperty(“key3”) -> value4
在理解了上述原理后,Apollo 和 Spring/Spring Boot 集成的手段就呼之欲出了:在应用启动阶段,Apollo 从远端获取配置,然后组装成 PropertySource 并插入到第一个即可,如下图所示:
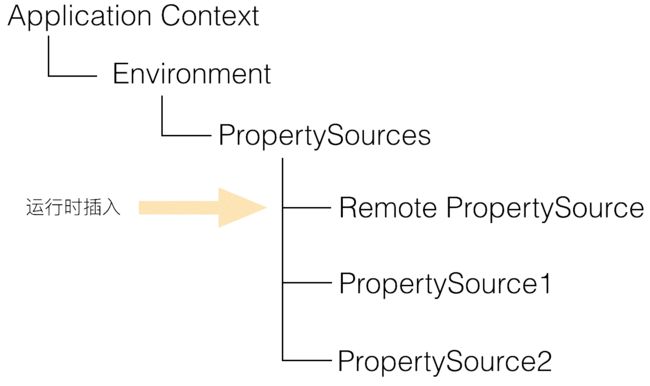
相关代码可以参考PropertySourcesProcessor
九、E-R Diagram
9.1 主体
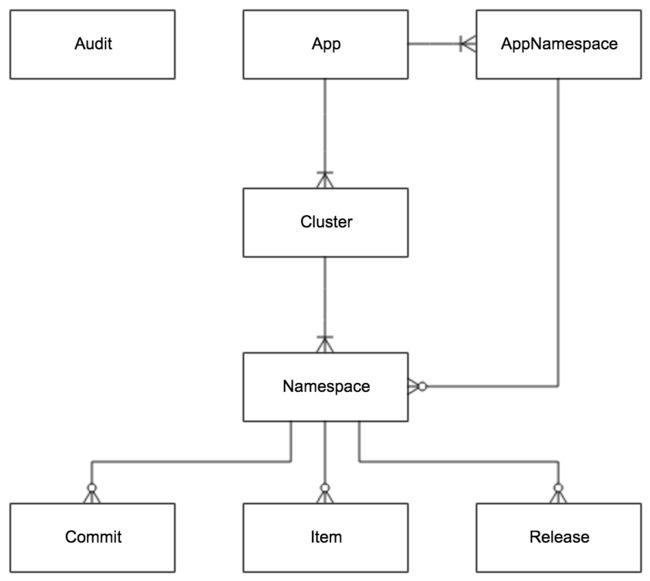
| Name | Desc |
|---|---|
| App | App 信息 |
| AppNamespace | App 下 Namespace 的元信息 |
| Cluster | 集群信息 |
| Namespace | 集群下的 Namespace |
| Item | Namespace 的配置,每个 Item 是一个 key-value 组合 |
| Release | Namespace 发布的配置,每个发布包含发布时该 Namespace 的所有配置 |
| Commit | Namespace 下的配置更改记录 |
| Audit | 审计信息,记录用户在何时使用何种方式操作了哪个实体 |
9.2 权限相关
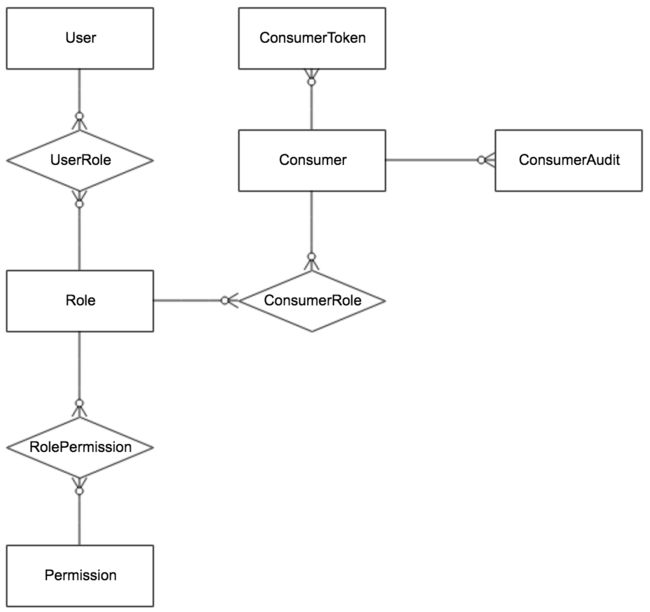
| Name | Desc |
|---|---|
| User | Apollo Portal 用户 |
| UserRole | 用户和角色的关系 |
| Role | 角色 |
| RolePermission | 角色和权限的关系 |
| Permission | 权限,对应到具体的实体资源和操作,如修改 NamespaceA 的配置,发布 NamespaceB 的配置等 |
| Consumer | 第三方应用 |
| ConsumerToken | 发给第三方应用的 token |
| ConsumerRole | 第三方应用和角色的关系 |
| ConsumerAudit | 第三方应用访问审计 |
十、参考资料
- Apollo WIKI
- 微服务架构~携程Apollo配置中心架构剖析
- 配置中心,让微服务更『智能』