docker笔记总结
docker笔记总结[超详细!!!]
转载,原博客地址:https://blog.csdn.net/qq_37026934/article/details/82939545
文章目录
- 1.0:什么是容器
- 2.0:lxc
- 2.1.0:虚拟化
- 2.1.1:主机级别的虚拟化
- 2.1.2:namespace
- 2.1.3:cgroup
- 2.1.0:虚拟化
- 3.0:docker特性
- 3.1.0:容器编排
- 4.0:docker使用
- 4.1.0:架构
- 4.1.1:docker_client
- 4.1.2:docker_host
- 4.1.3:docker registry
- 4.1.4:docker object
- 4.1.4.1:docker image
- 4.2.0:docker安装
-
- 4.2.1:docker环境
- 4.2.2:源
- 4.2.3:安装
- 4.2.4:docker常见操作
-
- 4.1.0:架构
- 5.0:docker镜像制作
- 5.1.0 基于容器制作镜像
- 5.3.0:镜像打包
- 6.0:docker网络
- 6.1.0 docker容器网络配置
- 6.2.0网络命名空间操作
- 7.0:docker 存储卷
- 7.1.0:docker的卷的种类
- 8.1.0:dockerfile
- 8.1.1:dockerfile格式
- 8.1.2:dockerfile工作逻辑
- 9.0:创建docker私有镜像仓库
- 9.1.0:容器安装docker-registry(docker-distribution)
- 9.1.1:yum安装docker-registry(docker-distribution)
1.0:什么是容器
容器是一种基础工具,泛指任何可以用于容纳其他物品的工具,可以部分或者完全封闭,被用于容纳,存储,运输物品,物体可以被放置在容器中,而容器可以保护内容。
2.0:lxc
lxc就是linux container 就是一系列的工具来实现创建容器,执行环境的脚本等等但是他对于容器的迁移,分发等等功能并没有那么好,所以后面就有了docker,docker就是lxc的增强版,它可以大规模的创建容器,他使用了一个概念就是镜像,他就是一个容器把执行的环境或者一种服务打包成一个文件我们可以直接安装,docker的业务逻辑也就是我们有一个镜像仓库,我们需要在一个主机上创建一个容器,我们不会激活模板安装,而是连接到镜像仓库将容器拖到本地启动。一个容器只运行一个进程(当然这个进程包括子进程一起),lxc是把一个容器当虚拟机用,运行多个进程,docker一个容器运行一个进程的好处是安全,简洁启动快速,为某个进程实现容器最小化配置(就是说这个容器要用bin我就只给你准备bin,不准备/src),但是我们的调试就要有专门的调试工具,如果要调试工具,就要再运行另一个进程,
2.1.0:虚拟化
2.1.1:主机级别的虚拟化
type 1
我们直接在硬件平台上装hypervisor,再在hypervisor上直接安装虚拟机不需要操作系统
type 2
就是我们首先要有一个os在os上安装vmm进行虚拟化,比如我们要用的vmware,这个依赖操作系统
2.1.2:namespace
我们使用虚拟化的目的是为了业务,为了业务我们会在虚拟机上运行软件,但是软件一般都是基于内核系统调用而实现的,所以我们必须要为虚拟机创建操作系统内核,而且虚拟机可以实现隔离环境,比如一个套接字如果我们有一个httpd和一个nginx他们都要用80端口怎么办我们就用虚拟机环境隔离,
我们为了简化这个架构,我们可以在硬件上直接提供一个隔离环境直接把进程跑在隔离环境内,我们隔离的其实是用户空间,我们隔离的有UTS,Mount,IPC,PID,USER,NET,内核中已经为我们创建这6种namespace,专门为这6种只有在内核3.8之后才把USER的namespace添加进来我们centos6用的是2.x的内核所以centos6已经被排除了,
这时我们已经隔离出了环境但是我们如果一个环境(也就是隔离出来的进程)他把所有的资源用到了cpu还好说(他把cpu占用了其他的隔离环境继续等待),但是内存用完了其他的隔离环境没有就只能被kill掉所以我们该有一种机制专门为此分配资源他就是cgroup
2.1.3:cgroup
cgroup全程control groups
在cgroup中可以分组,每一个组分配一定的资源,而namespace就是一个组我们可以用cgroup为他分配资源
但是至今他们的隔离还是没有虚拟机的好所以有的时候会开启selinux为内核的边界加固
3.0:docker特性
docker支持分层构建联合挂载,首先我们做一个最基础的centos镜像,我们可以基于centos之上装一个nginx镜像,他就是nginx镜像,他的nginx镜像只包含nginx不包含centos,他分2层,我们给他叠在一起,这叫做联合挂载,我们也可以用一个基础的centos镜像分别搭配nginx镜像,mariadb镜像,memcache镜像分成3个进项但是他们都共享一个底层的centos,因为每一层镜像都是只读的,但是我们再第一个容器里面改了东西那其他的镜像不是也改了吗?其实不是,docker有另外一个功能“写时复制”,就是在中间加上一个层,这个层对于本容器可读可写,如果要删就设置成不可见,如果要改我们就把它复制上来改然后就直接看这一层即可,但是为了容器迁移到其他主机或者容器出故障,我们一般就把这一层可更改的层放到共享存储上
3.1.0:容器编排
上面我们提到了分层构架联合挂载为此又出现了容器编排工具,在docker上可以用machine+swarm+compose来设计容器分层的启动逻辑比如启动nmp架构,或者K8S
而K8S为什么会那么火,因为K8S时google搞得,而google秘密搞容器搞了十几年作为秘密武器,docker出现后冲击google,所以google以十几年的经验出了K8S,而docker并没有大型项目的经验,而谷歌有,并且谷歌又主导了cncf委员会来指定标准。
4.0:docker使用
4.1.0:架构
docker有client端,
4.1.1:docker_client
Docker client是一个泛称,用来向指定的Docker daemon发起请求,执行相应的容器管理操作.它既可以是Docker命令行工具,也可以是任何遵循了Docker API的客户端
4.1.2:docker_host
docker_host端他是一个cs架构docker_daemon他是一个守护进程他监听在3种套接字上
1,一种ipv4套接字
2,ipv6套接字
3,unix套接字
docker_host时正真运行容器的主机,他有containers和images,其中images来自registry(registry默认本地没有自动到dockerhub上下载),然后container基于images创建,docker_host首先会把要用的images拉到本地在创建容器 他用http或者https与客户端交互,当docker daemon收到创建容器的命令的话就开始在本地创建容器,创建容器如果没有镜像就从registry上拉到本地(默认就是dockerhub),获得镜像后就存入本地,存储空间是专门的存储系统,
4.1.3:docker registry
默认是dokerhub,当然我们也可以自己创建,他不光提供仓库,他也提供认证,我们有多个仓库,一个仓库只放一种应用程序,比如nginx一个仓库,zabbix一个,但是我每个镜像的版本不同所以他用tag标记,所以应用程序的名字是应用名加上标签名,镜像是静态的,而容器是动态的有生命周期,镜像就像一个程序,容器就像一个进程 如果是本地的镜像他不用占带宽,docker repository一般分2类 顶级仓库,用户仓库(用户仓库格式 用户名/仓库名)
4.1.4:docker object
docker的对象我怕们可以对他使用增删改查,其中对象包括images,container,networks,volumes,plugins,这些对象我们都可以通过http协议访问(和openstack有些像)
4.1.4.1:docker image
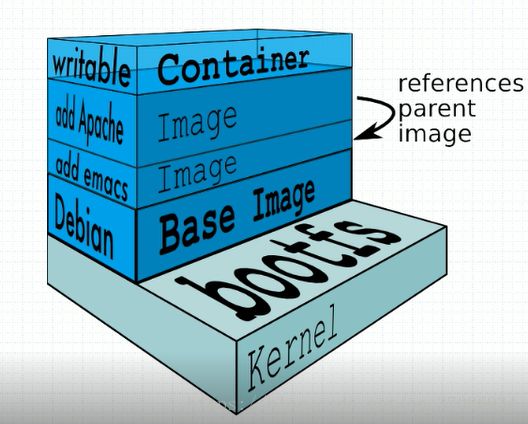
docker镜像含有启动容器所需要的文件系统及其内容,因此其用于创建并启动docker容器
docker镜像采用分层构建机制大体分成2部分
bootfs
用于引导文件系统包括bootloader和kernel(仅用于引导启动),容器启动完成后会被卸载以节约内存资源
rootfs
rootfs位于bootfs之上表现为docker容器的根文件系统
传统模式中系统启动后内核挂载rootfs时首先将其挂载为只读,然后自检其完整性然后将其挂载为读写模式
还有一种是docker用的,rootfs被内核挂载称为只读后通过联合挂载技术额外挂载一个可写层
其中bootfs挂载文件系统后就会被卸载,然后用一个最基础的os镜像加上一个emacs镜像(和vim一样是一个编辑器),再加上一个apache镜像,如果要对他更改就写入上面的读写层,如果删除容器,容器自己的可写层也会被删除,
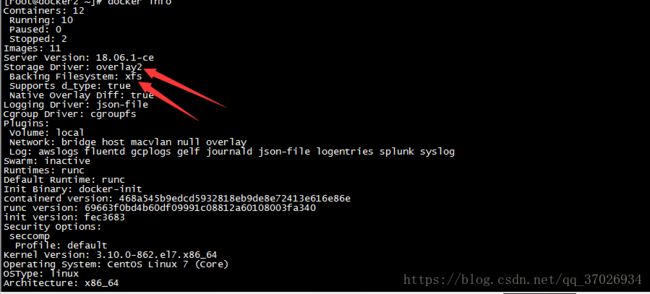
docker之所以能联合挂载是因为他的文件系统,在开始docker用的文件系统是aufs(高级多层次统一文件系统),用它来实现联合挂载,aufs不是linux的自带文件系统因为他的代码写得很烂,linus不让他收进自己的内核,但是ubuntu却把他收进内核,docker除了支持aufs之外支持btrfs,devicemapper(红帽开发但是作为联合挂载性能非常烂)和vfs等,现在我们用的是overlay2文件系统首先
overlay2
overlay2他是一个抽象的文件系统,他的底层是xfs,我们可以通过docker info查看
我们首先从docker_client发起http或者https请求像docker_daemon发送请求,然后docker_daemon首先从本地的storge driver查看本地有没有镜像,如果没有就从registry中下载该镜像并且保存到本地,如果没有特别的指定registry那么他就是docker hub上的镜像
4.2.0:docker安装
4.2.1:docker环境
因为docker用到了namespace和cgroup我们之前提到namespace种user项是在3.0之后加入的所以我们的内核至少要用3.10+的内核,系统我们用centos7.
4.2.2:源
我们cetos源种extra种就有docker的包,但是这里面的包很老,
所以我们用docker-ce社区版的源,阿里云yum源,清华大学yum源都有
4.2.3:安装
我们直接安装docker-ce社区版即可
他的配置文件在/etc/docker/daemon.json下我们首次创建没有因为只有他启动才会有,但是我们要配置docker的加速器所以我们就自己创建这个文件然后更改![]()
![]()
直接加上这一行把docker的镜像仓库改为docker中国的镜像,然后我们可以直接启动docker![]()
docker info查看docker最为详细的状态
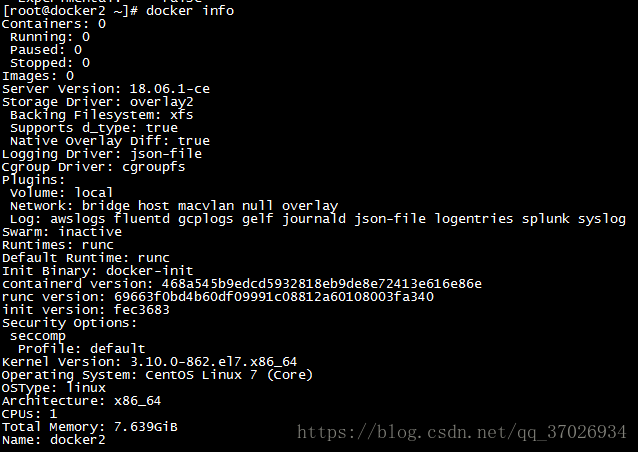
4.2.4:docker常见操作
docker search:搜索镜像 比如搜索nginx “docker search nginx”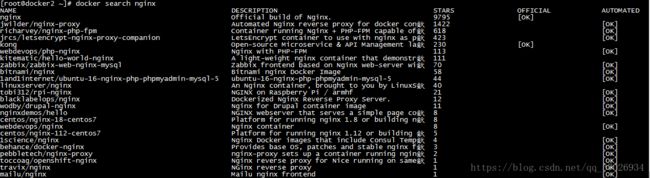
第一个nginx是根仓库后面jwilder是用户创建的镜像jwilder是用户后面是镜像名字:注意alpine版本的nginx,alpine是一个微型发行版,专门用来构建自己的镜像他只提供基础环境,
docker pull :下载镜像到本地
docker images:列出镜像![]()
docker rmi:删除镜像
docker image
docker ps :列出所有容器 ,现在有一个更规范的命令docker container ls (其中command表明我们镜像运行的默认服务)
docker network:查看本地网络
docker run:运行镜像
-- name指定名字
-it进入交替型模式
-h指定主机名
--rm 退出时删除容器
--dns指定dns地址
--network指定网络模式
--add-host 给hosts文件注入项例如 --add-host www.baidu.com:1.1.1.1
d后台运行
>例如

>因为我输入了-it启动后就自动进入交互模式
docker kill:直接强制停止docker
docker stop:停止
docker exec /docker container exec
docker container exec -it container_name /bin/sh
在后台运行这个容器,并且在这个容器运行/bin/sh/因为我们要进入shell
docker container logs:查看容器日志
5.0:docker镜像制作
如果我们需要自己制作镜像,我们可以通过dockerfile,基于容器(就是docker comit再最上面的那个读写层更改),docker hub automated builds(他也是基于dockerfile)
5.1.0 基于容器制作镜像
首先我们要先启动一个容器,在容器中做好你打算做的修改
例如我们在buzybox中制作,我们制作一个index的网页(他默认不存在),然后给他做成一个镜像
首先我们启动buzybox镜像![]()
我们开始创建网页![]()

然后我们要使这个容器运行所以我们再开一个shell 输入docker commit -p b1/ /commit就是专门制作镜像,-p是为了我们在制作镜像的时候暂停他不然他的数据又可能只保存一半,b1是容器的名字![]()
因为我们没有指定他的名字和仓库所以他名字是none repository也是none
我们可以给他打上标签,如果他有标签我们可以再打一遍覆盖原标签 我们用id是因为他没有名字honkytonkman是用户名httpd是仓库:后面的是版本
为标签重新打一个tag其实是一个引用和软连接一样,如果给源镜像删了为他重打的标签也没有了。我们再为他做一个镜像,让他打开就运行一个命令并且指定作者(在那个镜像基础上建) 其中-a指定作者,-c调用dockerfile后面因为我们要改的是开机执行的命令所以后加CMD,CMD后面再加一个列表里面跟命令(一个cmd就一个命令)
![]()
5.3.0:镜像打包
docker save命令可打包镜像,支持一次打包多个镜像打包成一个压缩文件 其中-o指定输出成什么文件![]()
然后我们可以传到另外一个主机上![]()
docker load直接加载压缩包 -i指定input文件 就行了
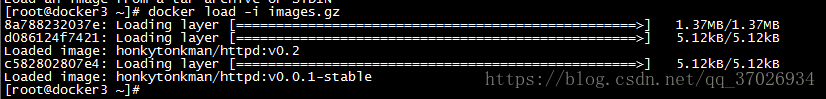

6.0:docker网络
namespace中的网络虚拟化可以将网卡分给一个特定的container,这个container可以通过这个网卡出去,也可以在主机内虚拟出一台交换机(网卡虚拟),再给每一台container虚拟出一个网卡,再给虚拟交换机虚拟出一个网卡,主机内的container通过这个交换机交换数据,如果container不在一个网段也可以通过一个容器给他配置成路由器(iptables)然后给他虚拟2个网卡,就可以做到数据包转发 ,还有一种是桥接,也是把网卡当成交换机,然后给本机虚拟出一个网卡,给container虚拟出一个网卡,当数据来了给虚拟交换机(网卡)然后arp请求container的mac地址
net方面的namspace主要对于tcp协议栈
namespace
6.1.0 docker容器网络配置
docker network ls查看容器网络
容器网路分3类
bridge;
默认网络,就是所有容器连接docker0容器都是172.17.0.0网段,每创建一个容器都会生成2个网卡一个连接在容器上一个连接在docker0交换机上
ifconfig中docker0就是一个软交换机,当创建容器额时候自动的创建了2个网卡一个再docker0交换机上,一个再容器上。我们可以通过brctl show(bridge-utils包的命令)查看可以看到docker0上关联了5个接口,以此证明他是一个交换机
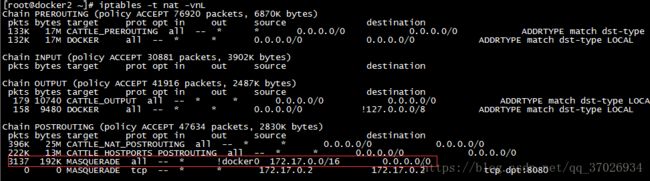
每一个容器网络默认是nat我们再用iptables查看 nat表 每当从任何接口进来只要不是docerk0口出去,源ip是172.17.0.0网段,目标是所有的网段都进行masquerade地址伪装
因为我们默认用的NAT bridge网络,而且他是snat,如果在别的服务器上有一台容器想访问他只能通过在他的宿主机上做dnat来进行端口地址转换,
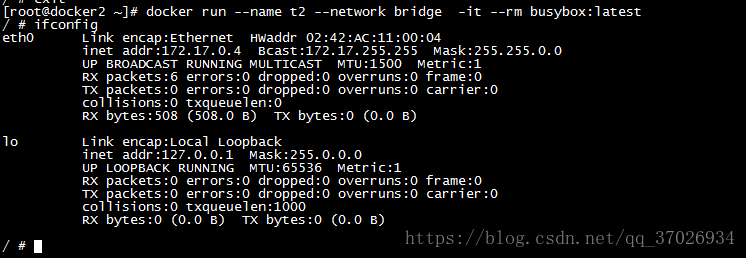
我们创建一个主机定义为bridge网络(其实不指定默认就是bridge)加上- -network选项指定 - -rm指定我们退出容器的时候删除 -it与容器交互
我们也可以自己的更改默认的docker0这台交换机的bridge ip我们可以更改配置文件/etc/docker/daemon.json中加上几行
docker的host端默认的监听在本地的sock地址(unix:///var/run/docker.sock)我们如果想从外地访问可以加上项让他监听在某一端口上 也是通过修改/etc/docker/daemon.json文件完成 那个unix://var/run/docker.sock要保留
这样我们可以通过别的docker主机通过docker -H ip:port command 来连接本地的docker daemon执行命令
例如



docker -H 192.168.10.1:27093 ps //通过27093这个端口连接远程docke daemon主机也就是docker host主机并且执行ps命令(这个ps也就是docker ps)
- 1
host:
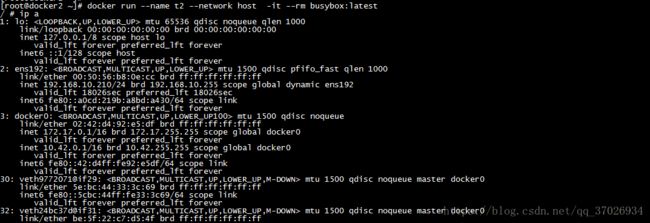
这里有一个新的概念,一个container有自己的6个namespace(UTS,Mount,IPC,PID,USER,NET)其中IPC,PID,NET是由这个container和主机共享的也就是说这个container可以直接用主机的tcp协议栈,这个就是host模式,当然多个container也可以共享协议栈
我们创建一个主机定义为host网络加上- -network选项指定 - -rm指定我们退出容器的时候删除 -it与容器交互 我们可以看到这个容器继承了主机的所有网卡,以后主机访问这个容器直接127.0.0.1即可
none:
就是什么也没有,没有网络没有网卡,只有loopback,不能执行网络通信,也就是封闭式网络
我们创建一个buzybox容器设置他的网络为封闭式的
我们创建一个主机定义为none网络加上- -network选项指定 - -rm指定我们退出容器的时候删除 -it与容器交互 我们可以看到这个容器只有loopback

6.2.0网络命名空间操作
我们可以通过 ip netns命令操作网络命名空间
查看网络空间![]()
我们添加一个网络命名空间
我们添加完网络命名空间后他默认只有lo网卡上的我们可以通过exec选项进行命令输入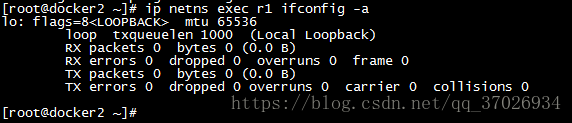
创建虚拟网卡 创建虚拟网卡用ip link命令 add选项是创建网卡 type指定类型后面veth是虚拟以太网卡类型 veth1.1是我们的一个网卡 peer name指定再创建一个网卡应为这样使用后相当于这两个网卡默认用网线连接在一起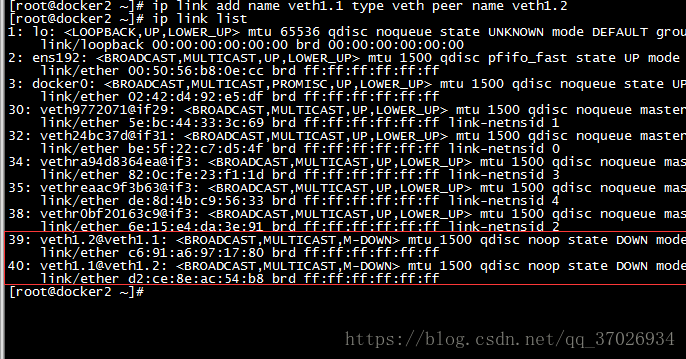
将veth1.2移到我们的名称空间中用ip link 命令加上set选项开始设置命名空间dev指定本地的网卡设备,netns指定命名空间![]()
查看命名空间的网络
我们将他改名字为eth0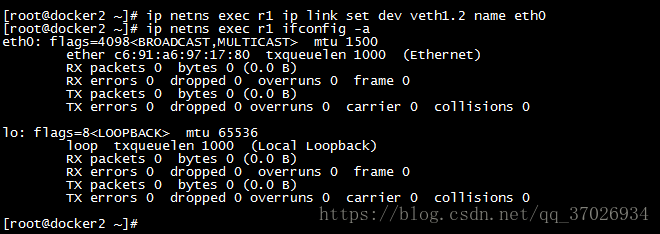
因为我们用了peer name所有默认他们2个接口用网线互联着在,接着我们直接给他们配置ip他们就可以通讯
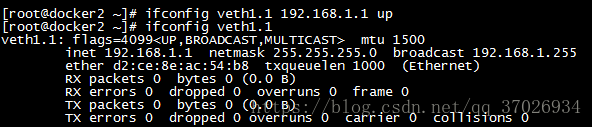
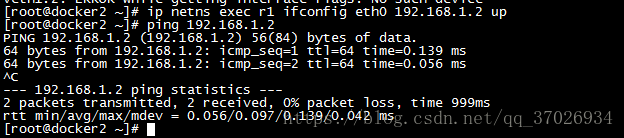
7.0:docker 存储卷
docker容器默认使用的存储卷是宿主机本地上的
docker目前在存储上存在的问题有
- 存储在联合文件系统中,不宜宿主机访问
- 容器间的数据共享不便
- 删除容器其数据会丢失
其解决方案是卷
卷是容器上一个或者多个目录,此类的目录可以绕过联合文件系统,与宿主机上的目录绑定关联,
volume在容器初始化的时候就创建了,由base image提供的卷中的数据会于此期间完成复制
当container的程序写在根上就会写入联合挂咋系统中,如果写在特定的目录中(这个目录要特别的指明了关联在其他的本地卷上),会自动的写到卷中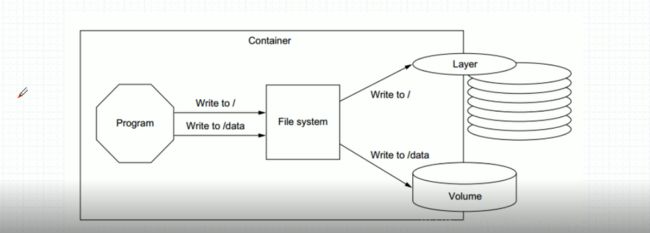
7.1.0:docker的卷的种类
bind mount volume
就是在宿主机上指定一个特殊的路径,再在容器中指定一个特殊的路径2者建立关联关系
例如docker run -it --name bbox2 -v /data/volumes/b2:/data busybox #将本地的/data/volumes/b2和容器中的/data相关联
docker-managed volume
我们只用在容器上指定一个特殊的目录,然后用docker daemon在宿主机上指定一个挂载点让他们相连接,不用你管,一般是在/var/lib/docker/vfs/dir/SOME_VLUME 中 我们在运行的docker宿主机的时候加上-v选项后跟容器内部的卷,他会自动的关联到宿主机本地 /var/lib/docker/vfs/dir/SOME_VLUME比如
docker run -it --name bbox1 -v /data busybox
如果我们要查看容器的详细信息我们可以用 ,一颗看到他是一个层级结构,我们可以调用出里面某个信息
docker inpect container_name
我们也可以查看固定的消息
比如查看networking里所有的消息
docker inspect -f {{.NetworkSettings}} t2 # 查看t2容器 networksetting下所有的项
查看networksettings中有的项
docker inspect -f {{.NetworkSettings.IPAddress}} t2 #引用容器下networksetting下ipaddress项
我们可以让一个容器共享另外一个容器的数据卷,我们加上–volumes-from选项后指定容器,也可以共享网络命名空间使用–network选项后加container:container_name比如
docker run --name nginx --network container:t2 --volumes-from t2 -it --rm nginx #指定网络命名空间与t2容器共享,卷与t2共享
8.1.0:dockerfile
首先再生产场景我们使用的容器不可能是一个基础的镜像,我们必须要对他做更改配置,我们把配置改好再使用docker commit把他再做成一个镜像即可,但是这样非常的麻烦,我们有一个制作容器的专门工具那就是dockerfile
,
dockerfile就是一个创建容器的源码
8.1.1:dockerfile格式
docker是一个自上而下执行的,每一行都是一个镜像层
docker的第一个非注释行必须是FROM指令 ,来指定基础镜像
##########################################################################
FROM
- FROM指令是最重要的一个并且必须为dockerfile文件开头的第一个非注释行,用于为映像文件构建过程指定基准镜像,后续的指令运行基于此基准镜像所提供的运行环境,在实践中,基准镜像可以是仍和可用镜像文件,默认情况下,docker build会在docker主机上查找指定的镜像文件,在其不存在时,会从docker hub registry上拉取,如果还找不到就报错
语法格式 FROM:[: ] FROM @ #repository指定为base image的名称: #tag为可选项,默认为latest #digest为镜像id的那串hash码 例如 FROM busybox:latest FROM busybox@#ad123asdff
MAINTAINER
-
它主要用来指定作者的,但是在新的版本已经有了新的替代品LABEL
MAINTAINER "ZHR <[email protected]>"
LABEL
- 他就是设定键值对赋予建一些指我们可以完成上述MAINTAINER的定义
LABL maintainer="ZHR <[email protected]>"
COPY
- 将宿主机中的文件打包到目标镜像中(当然是同一目录或者子目录)
COPY... 或者 COPY ["src",..."dest"] 为源目录(这个源目录不能是父目录只能是同一目录或者子目录,为相对路径,支持通配符,如果这个src是目录则其内部的文件或者子目录会被递归复制,但是 目录自身不会被复制) 这个为目标目录(为绝对路径,如果指定了多个src,则dest必须是一个目录,并且必须以/结尾,如果dest不存在他会自动的创建) 例如 COPY yum.repo.d /etc/yum.repo.d/ #把yum.repo.d下所有的文件复制到/etc/yum.repo.d/下因为yum.repo.d是一个目录所以他的子文件都会被复制但是他不会被复制
ADD
- add命令类似与copy命令,add命令支持使用tar文件和url路径 ,也就是说它可以访问网络服务器下载打包到指定目录,如果要复制的源是一个tar打包压缩的文件他可以自动的展开目录,但是如果是一个通过url获得的tar打包文件他不会自动的展开
ADD http://nginx.org/download/nginx-1.15.5.tar.gz /usr/local/bin/ #他会自动的下载到这里但是不会解压 ADD nginx-1.15.5.tar.gz /usr/local/bin/ #nginx-1.15.5.tar.gz是一个本地文件他会被复制到/usr/local/bin/下并且自动的解压
WORKDIR
- 指定工作目录也就是当前目录,后面引用用.即可,也可以用…切换到上一目录
VOLUME
- 用于在image中创建一个挂载点目录,以挂载在docker host上的卷或者其他容器上的卷,但是他只能指定挂载目标(镜像中的目录),不能指定挂载源(宿主机上的待挂载卷)
VOLUME /data/mysql #指定镜像内部的目录准备让宿主机的卷挂载进来
EXPOSE
- 用于为容器打开指定要监听的端口以实现与外部通信,也就是暴露出容器内部的端口然后动态绑定到宿主机上的某一端口但是要在docker run时指定-P选项,如果不指定他会自动暴露但是不绑定宿主机的端口,但是访问这个容器的ip就会自动的访问这个端口
EXPOSE 80/tcp #暴露容器的tcp80端口
ENV
- 用于为镜像定义所需要的环境变量,并且被dockerfile文件中位于其后的其他指令(如ENV,ADD,COPY等),所调用
可以在一行定义一个或者多个变量上面我们已经用到了ENV DOC_ROOT /data/web/html/ # 这样我们可以定义一个变量 ENV DOC_ROOT=/data/web/html \ WEB_SERVER_PACKAGE="nginx-1.15.2" #这样使用多个变量 COPY index.html ${DOC_ROOT:-/data/web/html/} #当DOC_ROOT这个变量里面没有值我们就用/data/web/html/我们bash/shell中也可以这样用
RUN和CMD
-
RUN和CMD都是运行命令的但是他们运行的时间点不一样,当你基于dockerfile构成镜像的时候我们运行RUN的命令,当我们镜像启动成容器时,我们执行CMD命令和我们docker run后面都要加上的命令一样,但是CMD只能运行一个,如果dockerfile有多个CMD那么最后一个生效
RUN cd /usr/local/src && \ #他是一个shell命令,并且以/bin/sh -c来运行,也就是shell的子进程,在容器中的PID不为1,不能接受UNIX信号,因此当docker stop的时候,此进程接收不到sigtern信号,当shell进程关闭后他也会失效 tar -x nginx RUN ["httpd","-t"] # 这一种语法格式是一种json的语法格式的数组,这种命令格式和上面不一样他不会以/bin/shell来发起,当shell退出的时候他也不会退出。他的父进程是init,但是一些shell的操作比如通配符,变量替换他不能使用 CMD也支持上面2种格式
ENTRYPOINT
- 类似与CMD指令的功能,用于为容器指定默认的运行程序,从而使容器像是一个单独的可执行程序,但是与CMD不同的是由ENTRYPOINT启动的程序不会被docker run 后面的命令覆盖,但是docker run --entrypoint选项可能覆盖他,而且docker run后面跟的命令会被当成选项跟到ENTRYPOINT指定的命令后面,而且ENTRYPOINT有多个也只有最后一个生效,而且CMD的命令也会被当成参数传给ENTRYPOINT的命令
ENTRYPOINT也支持CMD,RUN的2种格式- 1
示例dockerfile
FROM nginx:1.14-alpine
LABEL maintainer="zhr <[email protected]>"
ENV NGX_ROOT="/data/web/html/"
ADD index.html ${NGX_ROOT:-/data/web/html/}
ADD entrypoint.sh /bin/
CMD ["/usr/sbin/nginx","-g","daemon off;"] #他成为了ENTRYPOINT的参数也就是/bin/entrypoint.sh的参数
ENTRYPOINT ["/bin/entrypoint.sh"]
/bin/entrypoint.sh脚本
#!/bin/bash
cat > /etc/nginx/conf.d/www.conf <8.1.2:dockerfile工作逻辑
dockerfile必须再一个特定的目录下执行,所以我们必须找一个专门的文件来放dockerfile,而且dockerfile文件首字母必须大写,而且我们dockerfile要应用打包的文件(rpm包image等等)必须要和他在一个目录或者子目录,一定不能是父目录
dockerfile的目录下有一个.dockerignore文件,这个文件是一个隐藏文件,意为我们在dockerfile在开始打包文件的时候,dockerignore里指定的文件都不打包进去
当我们的dockerfile制作完成后我们可以用docker build来制作镜像
9.0:创建docker私有镜像仓库
registry用于保护镜像,包括镜像的层次结构和元数据
用户可以自建registry,也可以使用官方的dockerhub
分类
- sponsor registry:第三方registry 供客户和docker社区使用
- mirror registry: 第三方,只让客户使用
- vendor registry: 由docker镜像的提供商提供的registry
- private registry:通过设有防火墙和额外的安全层的私有实体提供的registry
我们要搭建docker私有仓库要用到的工具就是docker-registry
9.1.0:容器安装docker-registry(docker-distribution)
9.1.1:yum安装docker-registry(docker-distribution)
我们可以先查看一下docker-distribution的包在那个源中
yum info docker-distribution
- 查看得到docker-distribution在extras中